Robust and sparse support vector machine via hybrid truncated loss for supervised classification
Pith reviewed 2026-06-28 02:40 UTC · model grok-4.3
The pith
A hybrid truncated loss function produces support vector machines that are simultaneously sparse, bounded against outliers, and solvable to global optimality via ADMM.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
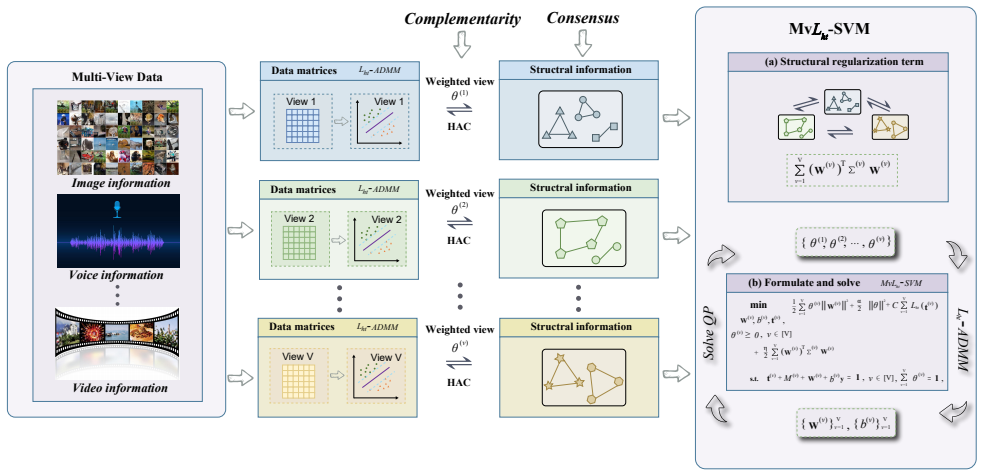
The L_ht loss is both sparse and bounded; the associated L_ht-SVM problem admits first-order necessary and sufficient optimality conditions at its P-stationary points; an ADMM algorithm with working-set strategy converges globally to a P-stationary point; and the same loss, augmented with view weights and structural regularization, yields an MvL_ht-SVM model that respects both consensus and complementarity principles.
What carries the argument
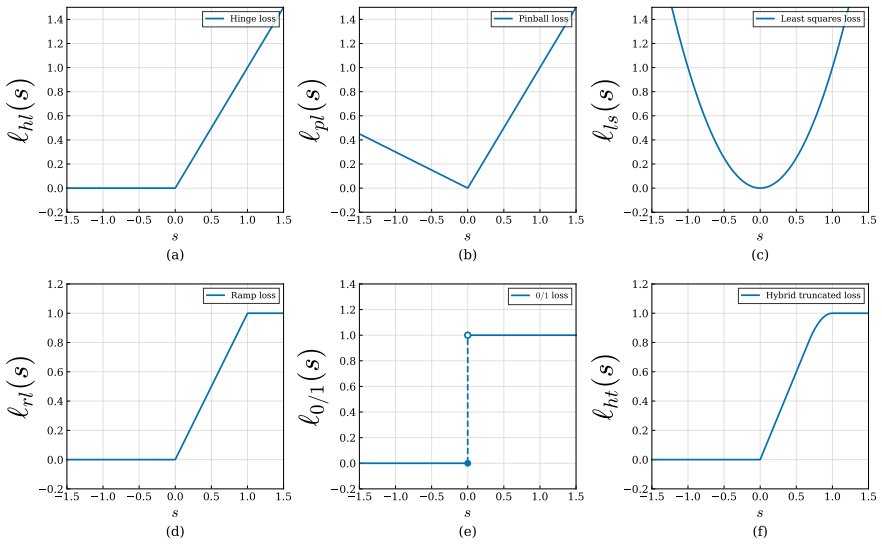
The hybrid truncated loss L_ht, which enforces sparsity through truncation while remaining bounded, together with the P-stationary point that certifies optimality for the non-convex program.
If this is right
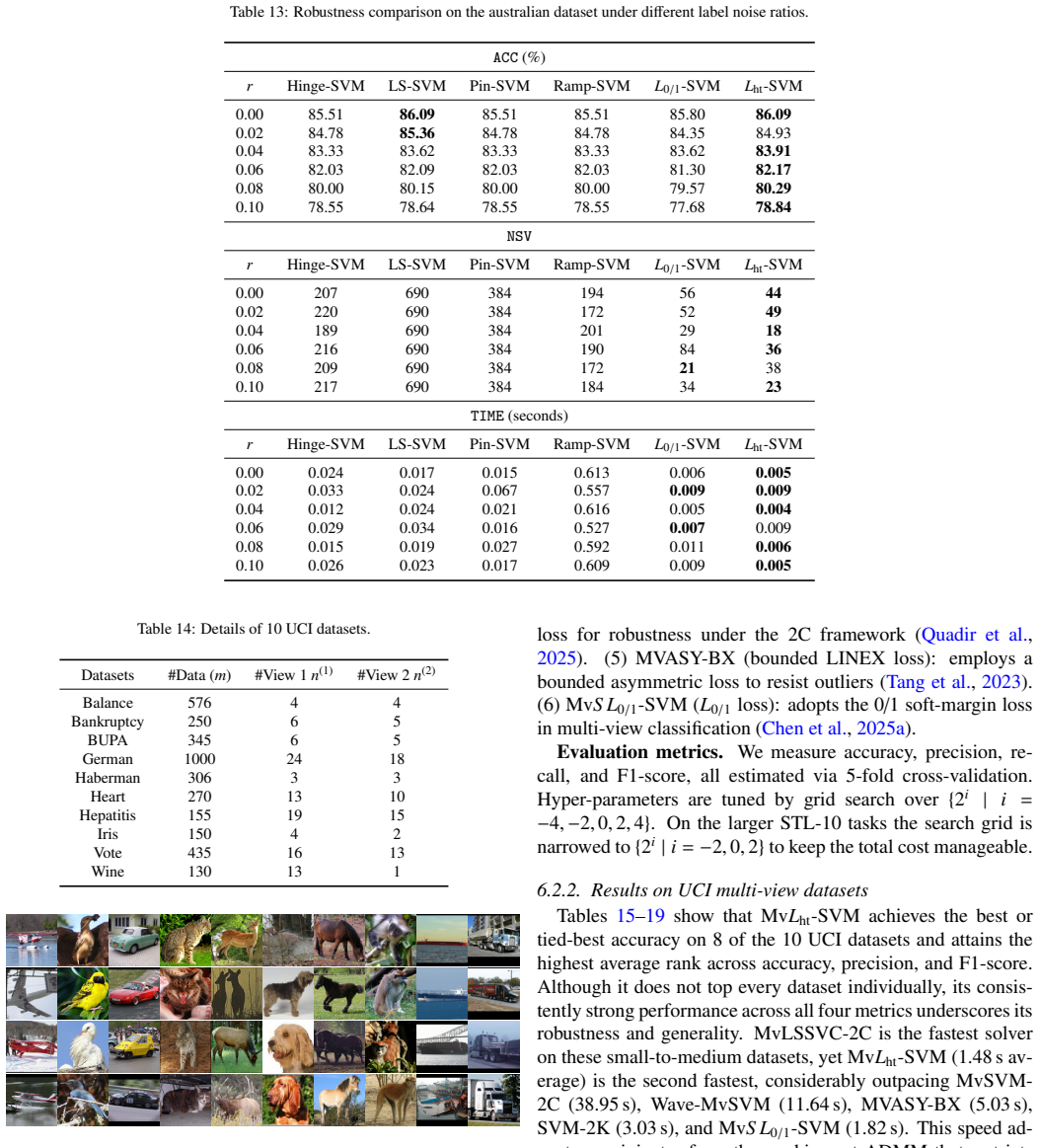
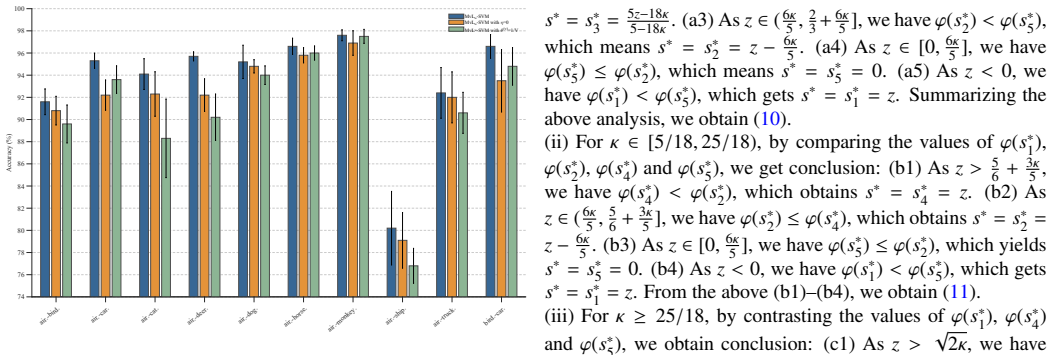
- L_ht-SVM reports higher classification accuracy than five single-view baselines while returning fewer support vectors.
- The same model exhibits improved robustness to label noise compared with convex-loss SVMs.
- MvL_ht-SVM improves accuracy, precision, recall, and F1-score over six existing multi-view classifiers on real and image data.
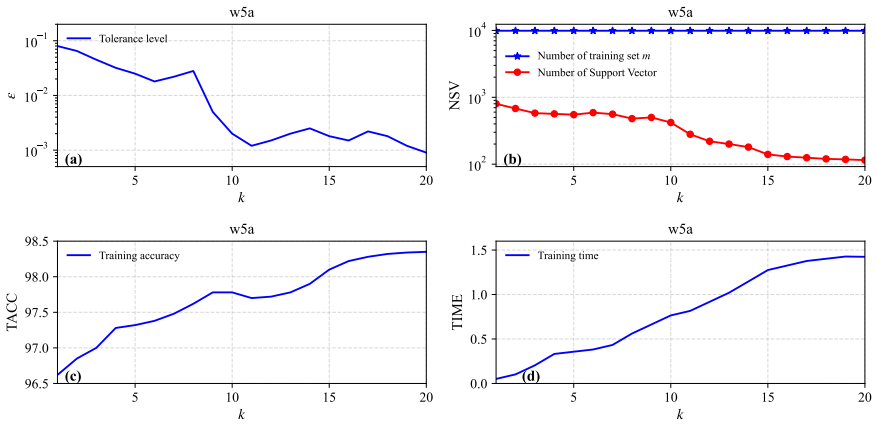
- The ADMM procedure reduces per-iteration cost through the working-set strategy while retaining global convergence.
Where Pith is reading between the lines
- The same loss construction could be inserted into other margin-based or kernel methods whose current losses are either unbounded or fully convex.
- Because the optimality certificate is first-order and stationary-point based, the framework may extend to additional non-convex regularizers without requiring second-order information.
- View-weight learning inside MvL_ht-SVM suggests a route for automatic down-weighting of noisy views in larger multi-modal pipelines.
Load-bearing premise
The P-stationary point supplies both necessary and sufficient first-order optimality conditions for the non-convex problem, and the ADMM algorithm with working-set strategy converges globally to such a point.
What would settle it
A dataset and initialization where the ADMM iterates fail to reach a point satisfying the P-stationary conditions, or where L_ht-SVM accuracy falls below that of hinge-loss SVM under identical training conditions.
Figures
read the original abstract
The support vector machine (SVM) is a widely used classifier, but choosing an appropriate loss function remains difficult. Convex losses such as the hinge loss and least-squares loss are sensitive to outliers, while bounded non-convex losses often lead to high computational cost. To address this, we propose a hybrid truncated loss function ($L_{\mathrm{ht}}$) that is both sparse and bounded, and build the $L_{\mathrm{ht}}$-SVM model for single-view classification. We introduce the P-stationary point and use it to establish the first-order necessary and sufficient optimality conditions. Based on these conditions, we design an alternating direction method of multipliers with a working-set strategy that reduces computational cost and achieves global convergence. We further extend $L_{\mathrm{ht}}$-SVM to multi-view learning by adding structural information and view weights, resulting in Mv$L_{\mathrm{ht}}$-SVM, which follows both the consensus and complementarity principles. Experiments on synthetic, real-world, and image datasets show that $L_{\mathrm{ht}}$-SVM achieves higher accuracy with fewer support vectors and better noise robustness than five single-view methods, while Mv$L_{\mathrm{ht}}$-SVM outperforms six multi-view methods in accuracy, precision, recall, and F1-score.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a hybrid truncated loss L_ht that is both sparse and bounded, constructs the single-view L_ht-SVM classifier, introduces the notion of a P-stationary point to obtain first-order necessary and sufficient optimality conditions for the resulting non-convex problem, and develops an ADMM solver augmented with a working-set strategy that is claimed to converge globally to such a point. The formulation is extended to the multi-view setting as MvL_ht-SVM by incorporating view weights and structural information that respect consensus and complementarity. Experiments on synthetic, real-world, and image data are reported to show higher accuracy, fewer support vectors, and improved noise robustness relative to five single-view baselines and six multi-view baselines.
Significance. If the stationarity characterization and global convergence result hold, the work supplies a theoretically grounded non-convex SVM variant that simultaneously achieves outlier robustness and sparsity while remaining computationally tractable via the working-set reduction. The multi-view extension provides a concrete mechanism for combining views that could be useful in applications where both agreement and complementarity matter. The empirical claims, if substantiated with proper controls, would indicate practical gains over existing hinge, ramp, and truncated losses.
minor comments (3)
- The definition of the hybrid truncated loss L_ht (piecewise expression and the role of the two truncation parameters) should be stated explicitly in the main text before the optimality analysis, rather than deferred to an appendix or figure.
- The experimental section should report the precise values of the regularization parameter C, the truncation thresholds, and the number of random train/test splits together with standard deviations; the current description leaves the statistical significance of the reported accuracy gains unclear.
- Notation for the multi-view objective (view weights, consensus term, and complementarity regularizer) should be introduced with a single consistent equation block rather than scattered across paragraphs.
Simulated Author's Rebuttal
We thank the referee for the positive summary of our contributions, the significance assessment, and the recommendation of minor revision. No specific major comments were provided in the report.
Circularity Check
No significant circularity; derivation self-contained
full rationale
The paper defines a new hybrid truncated loss L_ht from first principles, then derives P-stationary-point optimality conditions directly from its subdifferential and constructs an ADMM+working-set solver whose convergence follows from the alternating-direction scheme and active-set reduction. These steps are internally consistent with the loss definition and do not reduce by construction to fitted quantities, prior self-citations, or renamed empirical patterns. The multi-view extension adds structural terms without circular dependence on the single-view results. Experimental performance claims lie outside the derivation chain and are not invoked to justify the optimality conditions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
IEEE Transactions on Pattern Analysis & Machine Intelligence 47, 149–160
Roboss: A robust, bounded, sparse, and smooth loss function for supervised learning. IEEE Transactions on Pattern Analysis & Machine Intelligence 47, 149–160. https://doi.org/10.1109/TPAMI.2024.3465535. Alkhodhairy, G., Saleem, K.,
-
[2]
Alexandria Engineering Journal 128, 153–165
Machine learning algorithm for detecting suspicious email messages using natural language processing nlp. Alexandria Engineering Journal 128, 153–165. https://doi.org/10.1016/j.aej.2025.04.067. Allen-Zhu, Z.,
-
[3]
Katyusha: the first direct acceleration of stochastic gradient methods, in: Proceedings of the 49th Annual ACM SIGACT Symposium on Theory of Computing, Association for Computing Machinery. pp. 1200–1205. https://doi.org/10.1145/3055399.3055448. Belkin, M., Niyogi, P., Sindhwani, V .,
- [4]
-
[5]
An efficient primal simplex method for solving large-scale support vector machines. Neurocomputing 599, 128109. https://doi.org/10.1016/j.neucom.2024.128109. Chen, C., Liu, Q., Xu, R., Zhang, Y ., Wang, H., Yu, Q., 2025a. Multi-view support vector machine classifier via l0/1 soft-margin loss with structural information. Information Fusion 115, 102733. htt...
-
[6]
Trading convexity for scalability, in: Proceedings of the 23rd International Conference on Machine Learning, Association for Computing Machinery. pp. 201–208. https://doi.org/10.1145/1143844.1143870. Cortes, C., Vapnik, V .,
-
[7]
Support-vector networks. Mach. Learn. 20, 273–297. https://doi.org/10.1023/A:1022627411411. Dai, Y ., Zhang, Y ., Wu, Q.,
-
[8]
Over-relaxed multi-block admm algorithms for doubly regularized support vector machines. Neurocomputing 530, 188–204. https://doi.org/10.1016/j.neucom.2023.01.082. Farquhar, J., Hardoon, D., Meng, H., Shawe-taylor, J., Szedmák, S.,
-
[9]
Support matrix machine with pinball loss for classification. Neural Comput. Appl. 34, 18643–18661. https://doi.org/10.1007/s00521-022-07460-6. He, X., Pang, X., Ji, Z.,
-
[10]
Expert Systems with Applications 299, 130097
A new multi-view support vector machine with v-property. Expert Systems with Applications 299, 130097. https://doi.org/10.1016/j.eswa.2025.130097. 26 Huang, X., Shi, L., Suykens, J.A.K.,
-
[11]
IEEE Transactions on Pattern Analysis and Machine Intelligence 36, 984–997
Support vector machine classifier with pinball loss. IEEE Transactions on Pattern Analysis and Machine Intelligence 36, 984–997. https://doi.org/10.1109/TPAMI.2013.178. Huang, X., Shi, L., Suykens, J.A.K.,
-
[12]
IEEE Transactions on Neural Networks and Learning Systems 28, 1584–1593
Solution path for pin-svm classifiers with positive and negative tau values. IEEE Transactions on Neural Networks and Learning Systems 28, 1584–1593. https://doi.org/10.1109/TNNLS.2016.2547324. Jia, S., Liang, S., Mo, Z., Liu, C., Wang, H., Chen, C.,
-
[13]
Expert Systems with Applications 298, 129406
Deep multi-view least squares support vector machine with consistency and complementarity principle based on cross-output knowledge transfer. Expert Systems with Applications 298, 129406. https://doi.org/10.1016/j.eswa.2025.129406. Liu, L., Li, P., Chu, M., Zhai, Z.,
-
[14]
Applied Soft Computing 126, 109125
L2-loss nonparallel bounded support vector machine for robust classification and its dcd-type solver. Applied Soft Computing 126, 109125. https://doi.org/10.1016/j.asoc.2022.109125. Liu, M.Z., Shao, Y .H., Li, C.N., Chen, W.J.,
-
[15]
Applied Soft Computing 98, 106840
Smooth pinball loss nonparallel support vector machine for robust classification. Applied Soft Computing 98, 106840. https://doi.org/10.1016/j.asoc.2020.106840. Liu, Q., Chen, C., Huang, T., Meng, Y ., Wang, H.,
-
[16]
Expert Systems with Applications 265, 125814
Multi-view structural twin support vector machine with the consensus and complementarity principles and its safe screening rules. Expert Systems with Applications 265, 125814. https://doi.org/10.1016/j.eswa.2024.125814. Maggioni, F., Spinelli, A.,
-
[17]
European Journal of Operational Research 322, 237–253
A novel robust optimization model for nonlinear support vector machine. European Journal of Operational Research 322, 237–253. https://doi.org/10.1016/j.ejor.2024.12.014. Mason, L., Baxter, J., Bartlett, P., Frean, M.,
-
[18]
Enhancing multiview synergy: Robust learning by exploiting the wave loss function with consensus and complementarity principles. Neural Networks 188, 107433. https://doi.org/10.1016/j.neunet.2025.107433. Rockafellar, R., Wets, M., Wets, R.,
-
[19]
Machine Learning: Science and Technology 5, 015040
Quantum machine learning for image classification. Machine Learning: Science and Technology 5, 015040. https://doi.org/10.1088/2632-2153/ad2aef. Shen, X., Niu, L., Qi, Z., Tian, Y .,
-
[20]
Pattern Recognition 68, 199–210
Support vector machine classifier with truncated pinball loss. Pattern Recognition 68, 199–210. https://doi.org/10.1016/j.patcog.2017.03.011. Suykens, J.A.K., Vandewalle, J.,
-
[21]
Least squares support vector machine classifiers. Neural Process. Lett. 9, 293–300. https://doi.org/10.1023/A:1018628609742. Taha, K.,
-
[22]
Tang, J., He, H., Fu, S., Tian, Y ., Kou, G., Xu, S.,
https://doi.org/10.1186/s40537-025-01108-7. Tang, J., He, H., Fu, S., Tian, Y ., Kou, G., Xu, S.,
-
[23]
Robust multi-view learning with the bounded linex loss. Neurocomputing 518, 384–400. https://doi.org/10.1016/j.neucom.2022.10.078. Wang, H., Hu, D.,
-
[24]
Comparison of svm and ls-svm for regression, in: Proceedings of 2005 International Conference on Neural Networks and Brain Proceedings, ICNNB’05, pp. 279–283. https://doi.org/10.1109/ICNNB.2005.1614615. Wang, H., Li, G., Wang, Z.,
-
[25]
Information Sciences 642, 119136
Fast svm classifier for large-scale classification problems. Information Sciences 642, 119136. https://doi.org/10.1016/j.ins.2023.119136. Wang, H., Li, W., Shao, Y ., Zhang, H.,
-
[26]
Sparse and robust alternating direction method of multipliers for large-scale classification learning. Neurocomputing 652, 130893. https://doi.org/10.1016/j.neucom.2025.130893. Wang, H., Shao, Y .,
-
[27]
Pattern Recognition 146, 109987
Fast generalized ramp loss support vector machine for pattern classification. Pattern Recognition 146, 109987. https://doi.org/10.1016/j.patcog.2023.109987. Wang, H., Shao, Y ., Zhou, S., Zhang, C., Xiu, N.,
-
[28]
IEEE Transactions on Pattern Analysis & Machine Intelligence 44, 7253–7265
Support vector machine classifier via l0/1 soft-margin loss. IEEE Transactions on Pattern Analysis & Machine Intelligence 44, 7253–7265. https://doi.org/10.1109/TPAMI.2021.3092177. Wang, H., Xu, Y ., Zhou, Z.,
-
[29]
Twin-parametric margin support vector machine with truncated pinball loss. Neural Comput. Appl. 33, 3781–3798. https://doi.org/10.1007/s00521-020-05225-7. Wang, H., Zhang, H., Li, W., 2024a. Sparse and robust support vector machine with capped squared loss for large-scale pattern classification. Pattern Recognition 153, 110544. https://doi.org/10.1016/j.p...
-
[30]
https://doi.org/10.1016/j.aei.2023.102050. Xie, X., Sun, S.,
-
[31]
Multi-view twin support vector machines. Intell. Data Anal. 19, 701–712. https://doi.org/10.3233/IDA-150740. Xie, X., Sun, S.,
-
[32]
IEEE Transactions on Knowledge and Data Engineering 32, 2401–2413
Multi-view support vector machines with the consensus and complementarity information. IEEE Transactions on Knowledge and Data Engineering 32, 2401–2413. https://doi.org/10.1109/TKDE.2019.2933511. Xu, G., Cao, Z., Hu, B.G., Principe, J.C.,
-
[33]
Pattern Recognition 63, 139–148
Robust support vector machines based on the rescaled hinge loss function. Pattern Recognition 63, 139–148. https://doi.org/10.1016/j.patcog.2016.09.045. Xu, R., Wang, H.,
-
[34]
Expert Systems with Applications 206, 117787
Multi-view learning with privileged weighted twin support vector machine. Expert Systems with Applications 206, 117787. https://doi.org/10.1016/j.eswa.2022.117787. Ye, G., Chen, Y ., Xie, X.,
-
[35]
Multi-view least squares support vector classifiers with the principles of complementarity and consensus. Neurocomputing 657, 131647. https://doi.org/10.1016/j.neucom.2025.131647. 28
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.