Exploring Differences Between Tabular Enterprise Data and Public Benchmarks
Pith reviewed 2026-06-30 07:31 UTC · model grok-4.3
The pith
A model performing well on tabular benchmarks may perform poorly on real enterprise data, and vice versa.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
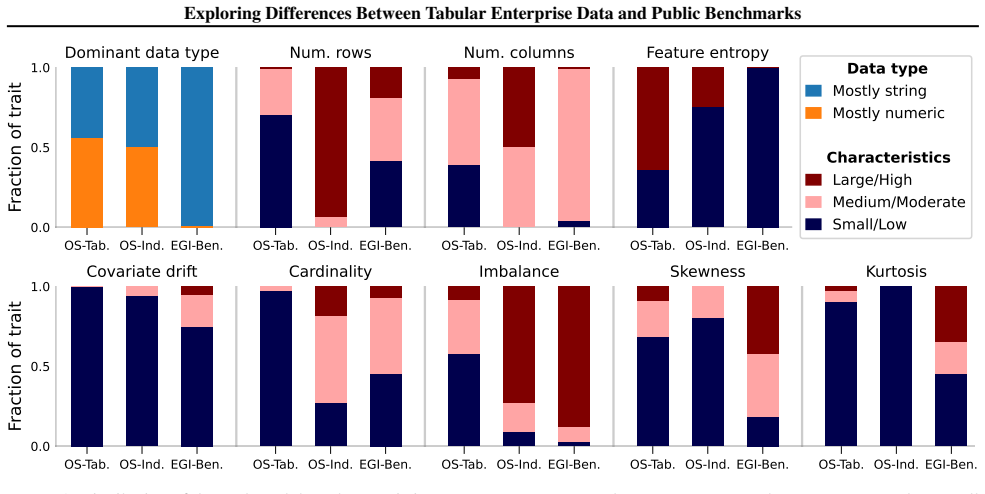
Enterprise data markedly differs from tabular benchmarks, and a tabular model that performs well on typical tabular benchmarks may perform poorly on real world enterprise data and vice versa. This lack of generalization calls for additional benchmarks with enterprise-grade characteristics.
What carries the argument
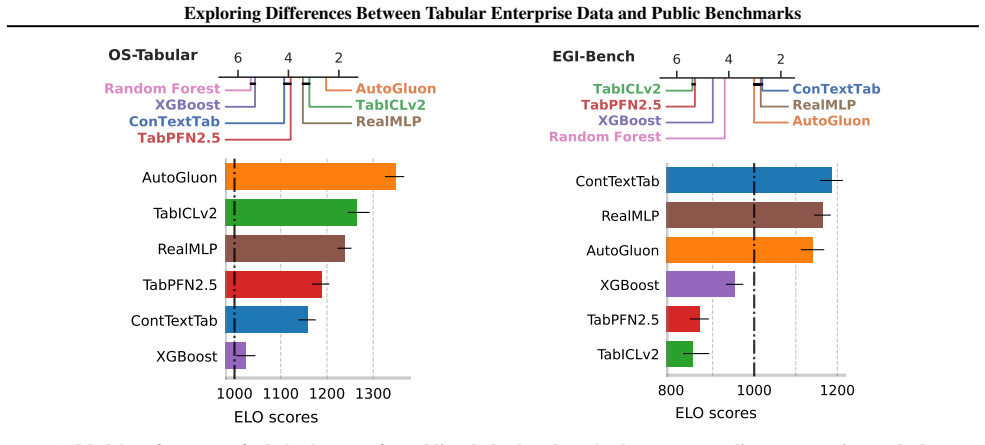
Analysis of data statistics and performance measurements of models such as TabPFN, TabICL and ConTextTab on enterprise versus benchmark data.
Load-bearing premise
The specific enterprise datasets analyzed are representative of the broader class of enterprise tabular data.
What would settle it
Demonstrating consistent model performance rankings across a wide variety of enterprise datasets and benchmarks would falsify the claimed lack of generalization.
Figures
read the original abstract
Tabular data dominate the landscape of data science, increasingly attracting innovative machine learning models and tailored benchmarks. Yet, little is known for enterprise data, where tables constitute the backbone of business operations. To broaden the benchmarking landscape for business applications, this work aims to actualize the characteristics of enterprise data by providing an analysis of data statistics and performance measurements of tabular models such as TabPFN, TabICL and ConTextTab. Through our analysis, we find enterprise data markedly differ from tabular benchmarks and we demonstrate that a tabular model that performs well on typical tabular benchmarks may perform poorly on real world enterprise data -- and vice versa. This lack of generalization underlines the need for additional benchmarks with enterprise-grade characteristics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents an empirical analysis of tabular enterprise datasets compared to public benchmarks, examining differences in data statistics and evaluating the performance of models including TabPFN, TabICL, and ConTextTab. It concludes that enterprise data differ markedly from benchmarks and that strong performance on public benchmarks does not generalize to enterprise data (and vice versa), underscoring the need for additional enterprise-grade benchmarks.
Significance. If the central findings hold after addressing dataset selection, the work would be significant for the tabular ML community by providing concrete evidence of a benchmark-reality gap and motivating more representative evaluation resources. The explicit performance comparisons on named models add value, though the impact hinges on establishing broader applicability beyond the analyzed tables.
major comments (2)
- [Data description and analysis sections] The central claim—that models performing well on typical tabular benchmarks may perform poorly on real world enterprise data—requires the analyzed enterprise tables to be representative of the broader class. The manuscript reports differences on specific enterprise datasets but does not detail the selection process, domain coverage, size distribution, or sampling criteria (see the data description section), leaving the generalization from these results to 'enterprise data' as an unverified assumption that is load-bearing for the conclusion.
- [Abstract and performance evaluation section] The abstract states the central finding but supplies no quantitative results, dataset sizes, statistical tests, or controls for confounding factors. The full manuscript should include these to allow judgment of whether the data support the performance gap claim (e.g., in the performance evaluation section).
minor comments (1)
- [Abstract] The abstract would be strengthened by including one or two key quantitative findings (e.g., average performance delta or number of tables analyzed) to convey the scale of the observed differences.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help strengthen the manuscript's claims about differences between enterprise tabular data and public benchmarks. We address each major point below and will incorporate revisions to improve clarity and rigor.
read point-by-point responses
-
Referee: [Data description and analysis sections] The central claim—that models performing well on typical tabular benchmarks may perform poorly on real world enterprise data—requires the analyzed enterprise tables to be representative of the broader class. The manuscript reports differences on specific enterprise datasets but does not detail the selection process, domain coverage, size distribution, or sampling criteria (see the data description section), leaving the generalization from these results to 'enterprise data' as an unverified assumption that is load-bearing for the conclusion.
Authors: We acknowledge the need for greater transparency on dataset selection to support generalization claims. Our enterprise tables were obtained from real business contexts across multiple industries (e.g., finance, retail, and operations), with sizes ranging from thousands to millions of rows, but we agree explicit documentation is missing. In revision, we will expand the data description section with details on sourcing, domain coverage, size distributions, and selection criteria. We note that the core contribution is demonstrating observable differences and lack of generalization on these tables, rather than claiming statistical representativeness of all enterprise data, which would require broader sampling. revision: yes
-
Referee: [Abstract and performance evaluation section] The abstract states the central finding but supplies no quantitative results, dataset sizes, statistical tests, or controls for confounding factors. The full manuscript should include these to allow judgment of whether the data support the performance gap claim (e.g., in the performance evaluation section).
Authors: We agree that quantitative support strengthens the abstract and evaluation. The manuscript already reports dataset sizes, performance metrics for TabPFN/TabICL/ConTextTab, and direct comparisons showing non-generalization, but we will revise the abstract to include key numbers (e.g., dataset counts, average performance gaps) and add statistical tests plus controls for confounders like row/column counts in the performance section. This will allow readers to better assess the evidence for the performance gap. revision: yes
Circularity Check
No circularity: purely empirical comparison
full rationale
The paper conducts an empirical study comparing data statistics and model performance (TabPFN, TabICL, ConTextTab) on selected enterprise tables versus public benchmarks. No derivations, equations, or fitted quantities are presented as predictions; the central claim follows directly from the reported measurements on the chosen datasets without any self-referential reduction or load-bearing self-citation chain. The analysis is self-contained against external benchmarks and contains no steps matching the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Spinaci, Marco and Polewczyk, Marek and Schambach, Maximilian and Thelin, Sam , journal=
-
[2]
arXiv preprint arXiv:2505.19825 , year=
Foundation Models for Tabular Data within Systemic Contexts Need Grounding , author=. arXiv preprint arXiv:2505.19825 , year=
-
[3]
Proceedings of the Twenty-First International Conference on Machine Learning , pages=
Ensemble selection from libraries of models , author=. Proceedings of the Twenty-First International Conference on Machine Learning , pages=
-
[4]
Gorishniy, Yury and Kotelnikov, Akim and Babenko, Artem , booktitle=
-
[5]
Unveiling challenges for
Bodensohn, Jan-Micha and Brackmann, Ulf and Vogel, Liane and Sanghi, Anupam and Binnig, Carsten , journal=. Unveiling challenges for. 2025 , publisher=
2025
-
[6]
International Conference on Machine Learning , year=
Qu, Jingang and Holzm. International Conference on Machine Learning , year=
-
[7]
Nature , volume=
Accurate predictions on small data with a tabular foundation model , author=. Nature , volume=. 2025 , publisher=
2025
-
[8]
TabICLv2: A better, faster, scalable, and open tabular foundation model.arXiv:2602.11139, 2026
Qu, Jingang and Holzm. arXiv preprint arXiv:2602.11139 , year=
-
[9]
Kim, Myung Jun and Grinsztajn, Leo and Varoquaux, Gael , journal=
-
[10]
arXiv preprint arXiv:2507.07829 , year=
Towards Benchmarking Foundation Models for Tabular Data With Text , author=. arXiv preprint arXiv:2507.07829 , year=
-
[11]
Advances in Neural Information Processing Systems , year=
Erickson, Nick and Purucker, Lennart and Tschalzev, Andrej and Holzm. Advances in Neural Information Processing Systems , year=
-
[12]
Liu, Si-Yang and Cai, Hao-Run and Zhou, Qi-Le and Yin, Huai-Hong and Zhou, Tao and Jiang, Jun-Peng and Ye, Han-Jia , journal=
-
[13]
TabPFN-2.5: Advancing the State of the Art in Tabular Foundation Models
Grinsztajn, L. arXiv preprint arXiv:2511.08667 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Advances in Neural Information Processing Systems , volume=
Better by default: Strong pre-tuned mlps and boosted trees on tabular data , author=. Advances in Neural Information Processing Systems , volume=
-
[15]
Journal of Machine Learning Research , volume=
Scikit-learn: Machine learning in Python , author=. Journal of Machine Learning Research , volume=
-
[16]
Prokhorenkova, Liudmila and Gusev, Gleb and Vorobev, Aleksandr and Dorogush, Anna Veronika and Gulin, Andrey , journal=
-
[17]
Erickson, Nick and Mueller, Jonas and Shirkov, Alexander and Zhang, Hang and Larroy, Pedro and Li, Mu and Smola, Alexander , journal=
-
[18]
Bischl, Bernd and Casalicchio, Giuseppe and Feurer, Matthias and Gijsbers, Pieter and Hutter, Frank and Lang, Michel and Mantovani, Rafael Gomes and van Rijn, Jan N and Vanschoren, Joaquin , booktitle=
-
[19]
Fischer, Sebastian Felix and Feurer, Matthias and Bischl, Bernd , booktitle=
-
[20]
arXiv preprint arXiv:2405.01147 (2024)
Why tabular foundation models should be a research priority , author=. arXiv preprint arXiv:2405.01147 , year=
-
[21]
Chen, Tianqi and Guestrin, Carlos , booktitle=
-
[22]
Ke, Guolin and Meng, Qi and Finley, Thomas and Wang, Taifeng and Chen, Wei and Ma, Weidong and Ye, Qiwei and Liu, Tie-Yan , journal=
-
[23]
Klein, Tassilo and Biehl, Clemens and Costa, Margarida and Sres, Andre and Kolk, Jonas and Hoffart, Johannes , journal=
-
[24]
Patterns , volume=
Bischl, Bernd and Casalicchio, Giuseppe and Das, Taniya and Feurer, Matthias and Fischer, Sebastian and Gijsbers, Pieter and Mukherjee, Subhaditya and M. Patterns , volume=. 2025 , publisher=
2025
-
[25]
Rubachev, Ivan and Kartashev, Nikolay and Gorishniy, Yury and Babenko, Artem , journal=
-
[26]
1999 , publisher=
Practical nonparametric statistics , author=. 1999 , publisher=
1999
-
[27]
Advances in Neural Information Processing Systems , volume=
Large scale transfer learning for tabular data via language modeling , author=. Advances in Neural Information Processing Systems , volume=
-
[28]
2017 , publisher=
Olson, Randal S and La Cava, William and Orzechowski, Patryk and Urbanowicz, Ryan J and Moore, Jason H , journal=. 2017 , publisher=
2017
-
[29]
Advances in Neural Information Processing Systems , volume=
Why do tree-based models still outperform deep learning on typical tabular data? , author=. Advances in Neural Information Processing Systems , volume=
-
[30]
arXiv preprint arXiv:2412.20331 , year=
Mind the data gap: Bridging llms to enterprise data integration , author=. arXiv preprint arXiv:2412.20331 , year=
-
[31]
Proceedings of the Workshop on Testing Database Systems , pages=
Get real: How benchmarks fail to represent the real world , author=. Proceedings of the Workshop on Testing Database Systems , pages=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.