Modality Forcing for Scalable Spatial Generation
Pith reviewed 2026-06-27 06:43 UTC · model grok-4.3
The pith
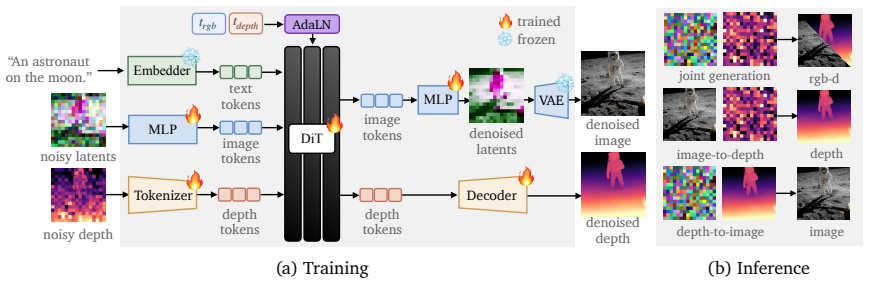
Modality Forcing assigns separate noise levels per modality so a single diffusion transformer generates images and depth jointly or conditionally from sparse data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
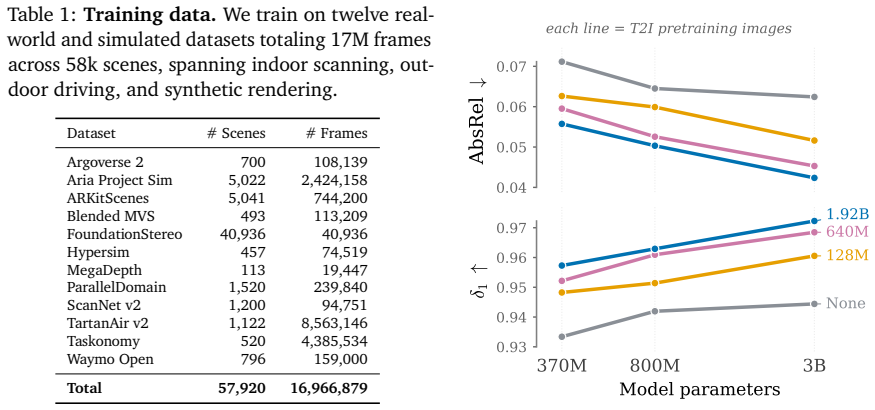
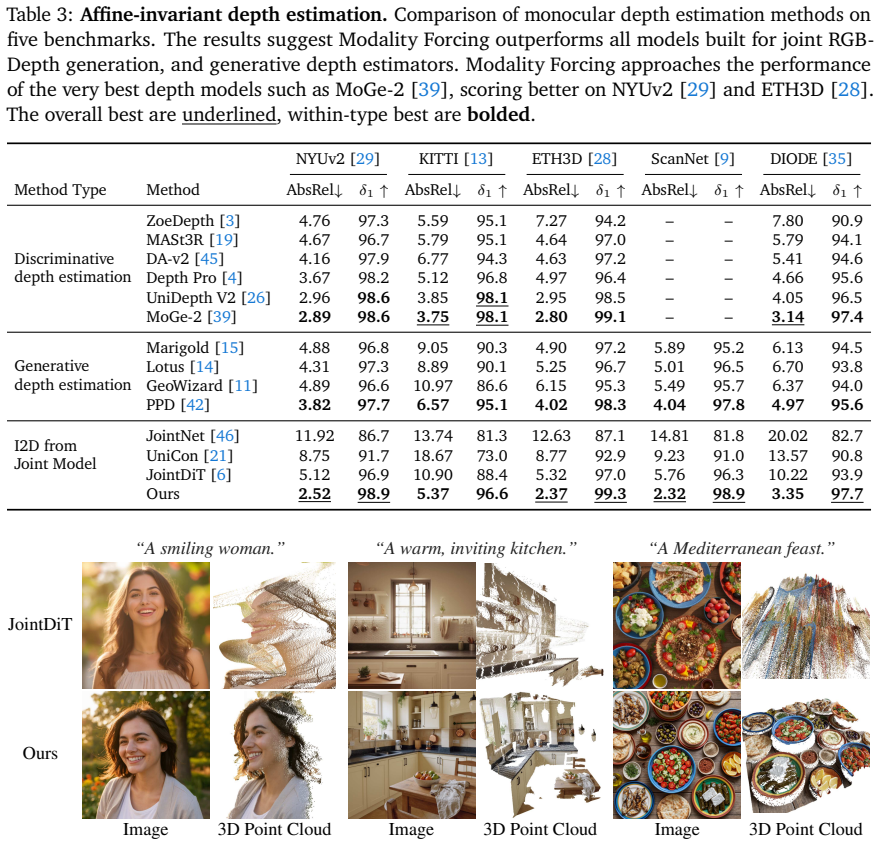
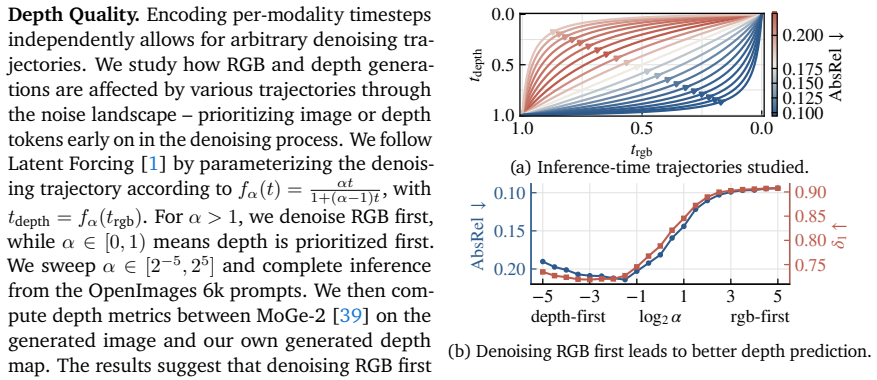
Modality Forcing enables conditional and joint generation of image and depth in any permutation by assigning separate noise levels per modality. Per-modality decoders let us train on sparse, real-world depth and achieve strong, generalizable depth prediction. We further show that Modality Forcing inherits the scalability of T2I pre-training: by training a set of T2I models from scratch (370M to 3.3B parameters), we find that larger models trained on more image data produce more accurate depth. Our strongest model is competitive with state-of-the-art monocular depth estimators and reduces AbsRel by 57% relative to existing joint image-depth generative models. These results provide strong evid
What carries the argument
Modality Forcing, which assigns separate noise levels to each modality during diffusion training and pairs them with per-modality decoders to support mixed sparse data.
If this is right
- Joint and conditional image-depth generation works in every ordering or subset without retraining.
- Training succeeds on sparse real-world depth instead of requiring dense ground truth.
- Depth accuracy rises as model capacity and image pretraining data increase.
- The resulting depth estimates reach error levels comparable to dedicated monocular estimators.
- Image generation pretraining supplies a route to generalizable spatial perception without modality-specific engineering.
Where Pith is reading between the lines
- The same separate-noise mechanism could extend to other geometric outputs such as surface normals or semantic labels using the same sparse supervision pattern.
- If the scaling trend holds, depth estimation could follow the same data and compute curves already observed in image and language models.
- Practitioners might reduce reliance on expensive dense depth capture by fine-tuning large image generators instead.
- The approach raises the question of whether other perception tasks benefit when image generation remains the dominant pretraining signal.
Load-bearing premise
Separate noise levels per modality plus dedicated decoders will let the shared model extract accurate depth from sparse measurements without introducing biases that favor one modality over the other.
What would settle it
Measure depth prediction error on held-out real scenes while scaling the same training recipe from 370M to 3.3B parameters on fixed image data; if accuracy stops improving once model size grows, the scalability claim would fail.
Figures




read the original abstract
Text-to-image (T2I) models contain rich spatial priors. Synthesizing photorealistic, cluttered scenes requires an understanding of geometry, including perspective and relative scale. Prior works adapt T2I models to leverage this prior for depth prediction, but they require dense depth data and involve complex recipes. We propose Modality Forcing, a simple, scalable post-training recipe for joint image-depth generation using a single DiT trained on sparse depth data. Modality Forcing enables conditional and joint generation of image and depth in any permutation by assigning separate noise levels per modality. Per-modality decoders let us train on sparse, real-world depth and achieve strong, generalizable depth prediction. We further show that Modality Forcing inherits the scalability of T2I pre-training: by training a set of T2I models from scratch (370M to 3.3B parameters), we find that larger models trained on more image data produce more accurate depth. Our strongest model is competitive with state-of-the-art monocular depth estimators and reduces AbsRel by 57% relative to existing joint image-depth generative models. These results provide strong evidence that image generation is a scalable pre-training objective for spatial perception. https://modality-forcing.github.io/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Modality Forcing, a post-training recipe for a single DiT that enables joint/conditional image-depth generation in any permutation via per-modality noise levels and per-modality decoders. This allows training on sparse real-world depth data. Scaling experiments train models from 370M to 3.3B parameters from scratch on image data, showing larger models yield better depth; the strongest model is competitive with monocular SOTA depth estimators and reduces AbsRel by 57% versus prior joint generative models, supporting image generation as scalable pre-training for spatial perception.
Significance. If reproducible, the approach offers a simpler alternative to prior T2I adaptations for depth that avoids dense supervision and complex recipes, while demonstrating clear scaling benefits. The reported gains over joint baselines and competitiveness with specialized monocular estimators would strengthen the case for generative pre-training in perception tasks.
major comments (2)
- [Method (implied in abstract description of noise levels and decoders)] The central claim that Modality Forcing enables accurate depth from sparse data rests on the per-modality noise schedules and decoders; without explicit equations or pseudocode showing how noise levels are sampled independently per modality during the forward process and how the decoders are conditioned, it is difficult to verify that modality-specific biases are avoided.
- [Abstract (quantitative claims)] The 57% AbsRel reduction and competitiveness with SOTA monocular estimators are load-bearing for the scalability conclusion, yet the abstract does not specify the exact test sets, number of runs, or whether the comparison models were re-trained under identical data regimes; this leaves open whether the gains are due to Modality Forcing or differences in training data scale.
minor comments (1)
- [Abstract] The project page link is useful, but all quantitative tables and scaling plots should appear in the main paper with clear captions indicating training data sources and evaluation protocols.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments below and will revise the manuscript accordingly to improve clarity and reproducibility.
read point-by-point responses
-
Referee: [Method (implied in abstract description of noise levels and decoders)] The central claim that Modality Forcing enables accurate depth from sparse data rests on the per-modality noise schedules and decoders; without explicit equations or pseudocode showing how noise levels are sampled independently per modality during the forward process and how the decoders are conditioned, it is difficult to verify that modality-specific biases are avoided.
Authors: We agree that explicit mathematical details are required for verification. The revised manuscript will add the forward-process equations showing independent per-modality noise sampling (i.e., separate t_image and t_depth drawn from the diffusion schedule) together with pseudocode for the training procedure and the conditioning of the per-modality decoders. These additions will make clear how separate noise levels and dedicated decoders avoid cross-modality bias while enabling training on sparse depth. revision: yes
-
Referee: [Abstract (quantitative claims)] The 57% AbsRel reduction and competitiveness with SOTA monocular estimators are load-bearing for the scalability conclusion, yet the abstract does not specify the exact test sets, number of runs, or whether the comparison models were re-trained under identical data regimes; this leaves open whether the gains are due to Modality Forcing or differences in training data scale.
Authors: The full paper reports results on NYUv2 and KITTI (standard monocular depth benchmarks) and states that the 57% AbsRel reduction is measured against published joint generative baselines on the same splits. Our scaling experiments train all DiT variants from scratch on identical image data, isolating model size as the variable. To address the abstract concern we will expand it to name the test sets and note that joint baselines follow their original published protocols. We cannot re-train every prior model under our exact regime, but the controlled scaling study within our framework supports that larger image-pretrained models improve depth accuracy. revision: partial
Circularity Check
No significant circularity
full rationale
The paper's central contribution is the empirical demonstration that Modality Forcing (separate per-modality noise schedules plus per-modality decoders) permits joint/conditional image-depth generation from sparse real-world depth data while inheriting T2I scaling behavior. All reported results are measured against external monocular depth SOTA baselines and prior joint generative models; no equations, fitted parameters, or self-citations are shown to define the target quantities by construction. The derivation chain therefore remains self-contained against independent benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Text-to-image models contain rich spatial priors including geometry, perspective, and relative scale.
Reference graph
Works this paper leans on
-
[1]
Latent forcing: Reordering the diffusion trajectory for pixel-space image generation,
Alan Baade, Eric Ryan Chan, Kyle Sargent, Changan Chen, Justin Johnson, Ehsan Adeli, and Li Fei-Fei. Latent forcing: Reordering the diffusion trajectory for pixel-space image generation,
-
[2]
URLhttps://arxiv.org/abs/2602.11401
-
[3]
Barron, Ben Mildenhall, Dor Verbin, Pratul P
Jonathan T. Barron, Ben Mildenhall, Dor Verbin, Pratul P. Srinivasan, and Peter Hedman. Mip-nerf 360: Unbounded anti-aliased neural radiance fields.CVPR, 2022
2022
-
[4]
Zoedepth: Zero-shot transfer by combining relative and metric depth, 2023
Shariq Farooq Bhat, Reiner Birkl, Diana Wofk, Peter Wonka, and Matthias Müller. Zoedepth: Zero-shot transfer by combining relative and metric depth, 2023. URLhttps://arxiv.org/ abs/2302.12288
Pith/arXiv arXiv 2023
-
[5]
Richter, and Vladlen Koltun
Aleksei Bochkovskii, Amaël Delaunoy, Hugo Germain, Marcel Santos, Yichao Zhou, Stephan R. Richter, and Vladlen Koltun. Depth pro: Sharp monocular metric depth in less than a second,
-
[6]
URLhttps://arxiv.org/abs/2410.02073
-
[8]
URLhttps://arxiv.org/abs/2005.14165
Pith/arXiv arXiv 2005
-
[9]
Jointdit: Enhancing rgb- depth joint modeling with diffusion transformers
Kwon Byung-Ki, Qi Dai, Lee Hyoseok, Chong Luo, and Tae-Hyun Oh. Jointdit: Enhancing rgb- depth joint modeling with diffusion transformers. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 25261–25271, October 2025
2025
-
[10]
Diffusion forcing: Next-token prediction meets full-sequence diffusion.Advances in Neural Information Processing Systems, 37:24081–24125, 2025
Boyuan Chen, Diego Martí Monsó, Yilun Du, Max Simchowitz, Russ Tedrake, and Vincent Sitzmann. Diffusion forcing: Next-token prediction meets full-sequence diffusion.Advances in Neural Information Processing Systems, 37:24081–24125, 2025
2025
-
[11]
Unimax: Fairer and more effective language sampling for large-scale multilingual pretraining, 2023
Hyung Won Chung, Noah Constant, Xavier Garcia, Adam Roberts, Yi Tay, Sharan Narang, and Orhan Firat. Unimax: Fairer and more effective language sampling for large-scale multilingual pretraining, 2023. URLhttps://arxiv.org/abs/2304.09151
arXiv 2023
-
[12]
Chang, Manolis Savva, Maciej Halber, Thomas Funkhouser, and Matthias Nießner
Angela Dai, Angel X. Chang, Manolis Savva, Maciej Halber, Thomas Funkhouser, and Matthias Nießner. Scannet: Richly-annotated 3d reconstructions of indoor scenes. InProc. Computer Vision and Pattern Recognition (CVPR), IEEE, 2017
2017
-
[13]
Scalingrectifiedflowtransformers for high-resolution image synthesis, 2024
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, Dustin Podell, Tim Dockhorn, Zion English, KyleLacey, AlexGoodwin, YannikMarek, andRobinRombach. Scalingrectifiedflowtransformers for high-resolution image synthesis, 2024. URLhttps://arxiv.org/abs/2403.03206
Pith/arXiv arXiv 2024
-
[14]
Geowizard: Unleashing the diffusion priors for 3d geometry estimation from a single image, 2024
Xiao Fu, Wei Yin, Mu Hu, Kaixuan Wang, Yuexin Ma, Ping Tan, Shaojie Shen, Dahua Lin, and Xiaoxiao Long. Geowizard: Unleashing the diffusion priors for 3d geometry estimation from a single image, 2024. URLhttps://arxiv.org/abs/2403.12013
arXiv 2024
-
[15]
Image generators are generalist vision learners.arXiv preprint arXiv:2604.20329, 2026
Valentin Gabeur, Shangbang Long, Songyou Peng, Paul Voigtlaender, Shuyang Sun, Yanan Bao, Karen Truong, Zhicheng Wang, Wenlei Zhou, Jonathan T Barron, Kyle Genova, Nithish Kannen, Sherry Ben, Yandong Li, Mandy Guo, Suhas Yogin, Yiming Gu, Huizhong Chen, Oliver Wang, Saining Xie, Howard Zhou, Kaiming He, Thomas Funkhouser, Jean-Baptiste Alayrac, and Radu S...
Pith/arXiv arXiv 2026
-
[16]
Vision meets robotics: The kitti dataset.Int
A Geiger, P Lenz, C Stiller, and R Urtasun. Vision meets robotics: The kitti dataset.Int. J. Rob. Res., 32(11):1231–1237, September 2013. ISSN 0278-3649. doi: 10.1177/0278364913491297. URLhttps://doi.org/10.1177/0278364913491297
-
[17]
Lotus: Diffusion-based visual foundation model for high-quality dense prediction, 2025
Jing He, Haodong Li, Wei Yin, Yixun Liang, Leheng Li, Kaiqiang Zhou, Hongbo Zhang, Bingbing Liu, and Ying-Cong Chen. Lotus: Diffusion-based visual foundation model for high-quality dense prediction, 2025. URLhttps://arxiv.org/abs/2409.18124
arXiv 2025
-
[18]
Repurposing diffusion-based image generators for monocular depth estimation
Bingxin Ke, Anton Obukhov, Shengyu Huang, Nando Metzger, Rodrigo Caye Daudt, and Konrad Schindler. Repurposing diffusion-based image generators for monocular depth estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[19]
Berg, Wan-Yen Lo, Piotr Dollár, and Ross Girshick
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C. Berg, Wan-Yen Lo, Piotr Dollár, and Ross Girshick. Segment anything.arXiv:2304.02643, 2023
Pith/arXiv arXiv 2023
-
[20]
Orchid: Image latent diffusion for joint appearance and geometry generation, 2025
Akshay Krishnan, Xinchen Yan, Vincent Casser, and Abhijit Kundu. Orchid: Image latent diffusion for joint appearance and geometry generation, 2025. URLhttps://arxiv.org/abs/ 2501.13087
arXiv 2025
-
[21]
FLUX.2: Frontier Visual Intelligence.https://bfl.ai/blog/flux-2, 2025
Black Forest Labs. FLUX.2: Frontier Visual Intelligence.https://bfl.ai/blog/flux-2, 2025
2025
-
[22]
Grounding image matching in 3d with mast3r, 2024
Vincent Leroy, Yohann Cabon, and Jérôme Revaud. Grounding image matching in 3d with mast3r, 2024. URLhttps://arxiv.org/abs/2406.09756. 12
arXiv 2024
-
[23]
Back to basics: Let denoising generative models denoise, 2026
Tianhong Li and Kaiming He. Back to basics: Let denoising generative models denoise, 2026. URLhttps://arxiv.org/abs/2511.13720
Pith/arXiv arXiv 2026
-
[24]
A simple approach to unifying diffusion-based conditional generation
Xirui Li, Charles Herrmann, Kelvin CK Chan, Yinxiao Li, Deqing Sun, and Ming-Hsuan Yang. A simple approach to unifying diffusion-based conditional generation. InThe Thirteenth Interna- tional Conference on Learning Representations, 2025
2025
-
[25]
Learning without forgetting, 2017
Zhizhong Li and Derek Hoiem. Learning without forgetting, 2017. URLhttps://arxiv.org/ abs/1606.09282
Pith/arXiv arXiv 2017
-
[26]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling, 2023. URLhttps://arxiv.org/abs/2210.02747
Pith/arXiv arXiv 2023
-
[27]
Dinov2: Learning robust visual features without supervision, 2024
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy Vo, Marc Szafraniec, Vasil Khali- dov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Mahmoud Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Hervé Jegou, Julien Mairal, Patrick L...
Pith/arXiv arXiv 2024
-
[28]
Scalable diffusion models with transformers, 2023
William Peebles and Saining Xie. Scalable diffusion models with transformers, 2023. URL https://arxiv.org/abs/2212.09748
Pith/arXiv arXiv 2023
-
[29]
UniDepth: Universal monocular metric depth estimation
Luigi Piccinelli, Yung-Hsu Yang, Christos Sakaridis, Mattia Segu, Siyuan Li, Luc Van Gool, and Fisher Yu. UniDepth: Universal monocular metric depth estimation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[30]
High- resolution image synthesis with latent diffusion models, 2022
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High- resolution image synthesis with latent diffusion models, 2022. URLhttps://arxiv.org/abs/ 2112.10752
Pith/arXiv arXiv 2022
-
[31]
Schönberger, Silvano Galliani, Torsten Sattler, Konrad Schindler, Marc Pollefeys, and Andreas Geiger
Thomas Schöps, Johannes L. Schönberger, Silvano Galliani, Torsten Sattler, Konrad Schindler, Marc Pollefeys, and Andreas Geiger. A multi-view stereo benchmark with high-resolution images and multi-camera videos. In2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 2538–2547, 2017. doi: 10.1109/CVPR.2017.272
-
[32]
Indoor segmentation and support inference from rgbd images
Nathan Silberman, Derek Hoiem, Pushmeet Kohli, and Rob Fergus. Indoor segmentation and support inference from rgbd images. In Andrew Fitzgibbon, Svetlana Lazebnik, Pietro Perona, Yoichi Sato, and Cordelia Schmid, editors,Computer Vision – ECCV 2012, pages 746–760, Berlin, Heidelberg, 2012. Springer Berlin Heidelberg. ISBN 978-3-642-33715-4
2012
-
[33]
Ldm3d: Latent diffusion model for 3d, 2023
Gabriela Ben Melech Stan, Diana Wofk, Scottie Fox, Alex Redden, Will Saxton, Jean Yu, Estelle Aflalo, Shao-Yen Tseng, Fabio Nonato, Matthias Muller, and Vasudev Lal. Ldm3d: Latent diffusion model for 3d, 2023. URLhttps://arxiv.org/abs/2305.10853
arXiv 2023
-
[34]
Roformer: Enhanced transformer with rotary position embedding, 2023
Jianlin Su, Yu Lu, Shengfeng Pan, Ahmed Murtadha, Bo Wen, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding, 2023. URLhttps://arxiv.org/abs/ 2104.09864
Pith/arXiv arXiv 2023
-
[35]
The bitter lesson, 2019
Richard Sutton. The bitter lesson, 2019. URLhttp://www.incompleteideas.net/IncIdeas/ BitterLesson.html
2019
-
[36]
Sam 3d: 3dfy anything in images
SAM 3D Team, Xingyu Chen, Fu-Jen Chu, Pierre Gleize, Kevin J Liang, Alexander Sax, Hao Tang, Weiyao Wang, Michelle Guo, Thibaut Hardin, Xiang Li, Aohan Lin, Jiawei Liu, Ziqi Ma, Anushka Sagar, Bowen Song, Xiaodong Wang, Jianing Yang, Bowen Zhang, Piotr Dollár, Georgia Gkioxari, Matt Feiszli, and Jitendra Malik. Sam 3d: 3dfy anything in images. 2025. URL h...
Pith/arXiv arXiv 2025
-
[37]
Z-Image Team. Z-image: An efficient image generation foundation model with single-stream diffusion transformer.arXiv preprint arXiv:2511.22699, 2025
Pith/arXiv arXiv 2025
-
[39]
URLhttp://arxiv.org/abs/1908.00463
arXiv 1908
-
[40]
Wan: Open and advanced large-scale video generative models,
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, Jianyuan Zeng, Jiayu Wang, Jingfeng Zhang, Jingren Zhou, Jinkai Wang, Jixuan Chen, Kai Zhu, Kang Zhao, Keyu Yan, Lianghua Huang, Mengyang Feng, Ningyi Zhang, Pandeng Li, Pingyu Wu, Ruihang Chu, Ruili Feng, Shiwei Zhang, Siyang Sun, Tao Fang, T...
-
[41]
URLhttps://arxiv.org/abs/2503.20314
-
[42]
Jianyuan Wang, Minghao Chen, Shangzhan Zhang, Nikita Karaev, Johannes Schönberger, Patrick Labatut, Piotr Bojanowski, David Novotny, Andrea Vedaldi, and Christian Rupprecht. Vggt-ω,
-
[43]
URLhttps://arxiv.org/abs/2605.15195
-
[44]
Moge: Unlocking accurate monocular geometry estimation for open-domain images with optimal training supervision
Ruicheng Wang, Sicheng Xu, Cassie Dai, Jianfeng Xiang, Yu Deng, Xin Tong, and Jiaolong Yang. Moge: Unlocking accurate monocular geometry estimation for open-domain images with optimal training supervision. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 5261–5271, 2025
2025
-
[45]
Moge-2: Accurate monocular geometry with metric scale and sharp details, 2025
Ruicheng Wang, Sicheng Xu, Yue Dong, Yu Deng, Jianfeng Xiang, Zelong Lv, Guangzhong Sun, Xin Tong, and Jiaolong Yang. Moge-2: Accurate monocular geometry with metric scale and sharp details, 2025. URLhttps://arxiv.org/abs/2507.02546
Pith/arXiv arXiv 2025
-
[46]
Dust3r: Geometric 3d vision made easy, 2024
Shuzhe Wang, Vincent Leroy, Yohann Cabon, Boris Chidlovskii, and Jerome Revaud. Dust3r: Geometric 3d vision made easy, 2024. URLhttps://arxiv.org/abs/2312.14132
arXiv 2024
-
[47]
Ronald J. Williams and David Zipser. A learning algorithm for continually running fully recurrent neural networks.Neural Computation, 1(2):270–280, 1989. doi: 10.1162/neco.1989.1.2.270
-
[48]
Gangwei Xu, Haotong Lin, Hongcheng Luo, Xianqi Wang, Jingfeng Yao, Lianghui Zhu, Yuechuan Pu, Cheng Chi, Haiyang Sun, Bing Wang, et al. Pixel-perfect depth with semantics-prompted diffusion transformers.arXiv preprint arXiv:2510.07316, 2025
arXiv 2025
-
[49]
Context unrolling in omni models,
Ceyuan Yang, Zhijie Lin, Yang Zhao, Fei Xiao, Hao He, Qi Zhao, Chaorui Deng, Kunchang Li, Zihan Ding, Yuwei Guo, Fuyun Wang, Fangqi Zhu, Xiaonan Nie, Shenhan Zhu, Shanchuan Lin, Hongsheng Li, Weilin Huang, Guang Shi, and Haoqi Fan. Context unrolling in omni models,
-
[50]
URLhttps://arxiv.org/abs/2604.21921
-
[51]
Depth anything: Unleashing the power of large-scale unlabeled data
Lihe Yang, Bingyi Kang, Zilong Huang, Xiaogang Xu, Jiashi Feng, and Hengshuang Zhao. Depth anything: Unleashing the power of large-scale unlabeled data. InCVPR, 2024
2024
-
[52]
Depth anything v2.arXiv:2406.09414, 2024
Lihe Yang, Bingyi Kang, Zilong Huang, Zhen Zhao, Xiaogang Xu, Jiashi Feng, and Hengshuang Zhao. Depth anything v2.arXiv:2406.09414, 2024
Pith/arXiv arXiv 2024
-
[53]
Jointnet: Extending text-to-image diffusion for dense distribution modeling, 2023
Jingyang Zhang, Shiwei Li, Yuanxun Lu, Tian Fang, David McKinnon, Yanghai Tsin, Long Quan, and Yao Yao. Jointnet: Extending text-to-image diffusion for dense distribution modeling, 2023. URLhttps://arxiv.org/abs/2310.06347. 14
arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.