Dynamic Multi-Pair Trading Strategy in Cryptocurrency Markets with Deep Reinforcement Learning
Pith reviewed 2026-06-28 07:35 UTC · model grok-4.3
The pith
A PPO reinforcement learning agent with deterministic shielding outperforms a heuristic baseline for pair trading execution in cryptocurrency markets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The optimized RL policy achieved an out-of-sample performance that substantially outperformed the heuristic baseline. A stationary circular block bootstrap robustness check confirms that the agent's risk-adjusted outperformance is statistically significant at the 10 percent level. The architecture anchors the neural policy to statistically robust boundaries through deterministic shielding, thereby reducing severe divergence risks that otherwise appear when classical pair trading is applied directly to high-variance digital assets.
What carries the argument
The Proximal Policy Optimization agent with LSTM layer that makes execution decisions inside the deterministic risk boundaries of the Fixed Risk, Adaptive Mean model.
If this is right
- The hybrid system combines statistical arbitrage selection with DRL execution to manage divergence risk in volatile markets.
- Deterministic shielding around the neural policy enables safe application of reinforcement learning to trading without unbounded losses.
- The Filter-then-Rank methodology supports dynamic multi-pair selection on hourly futures data.
- Risk-adjusted gains remain detectable even under the idiosyncratic variance typical of cryptocurrency pairs.
Where Pith is reading between the lines
- The same shielding approach could be ported to other mean-reversion strategies that currently suffer from sudden regime shifts.
- Live deployment would need to monitor whether the proprietary execution model itself requires periodic recalibration as market microstructure changes.
- Extending the agent to act across multiple timeframes simultaneously might further improve capture of short-term dislocations.
Load-bearing premise
The Fixed Risk, Adaptive Mean execution model and its deterministic shielding boundaries continue to work when the statistical relationships between paired assets shift rapidly in live crypto conditions.
What would settle it
A new out-of-sample window on the same exchange or a different venue in which the RL policy no longer produces higher risk-adjusted returns than the heuristic baseline or the bootstrap test loses significance at the 10 percent level.
Figures



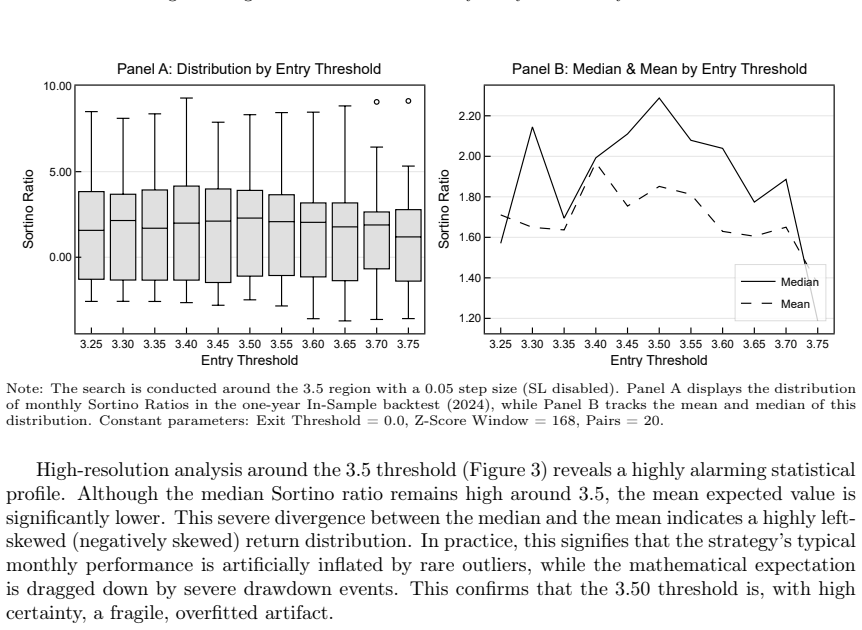


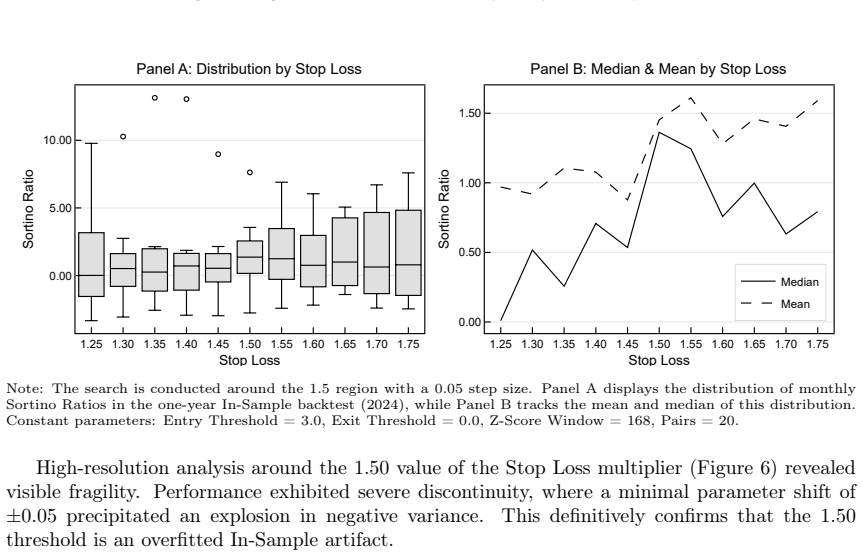






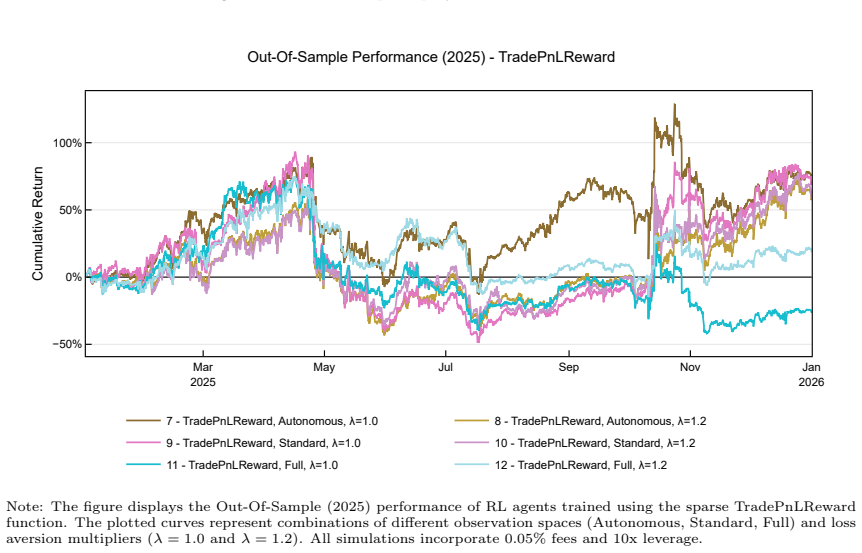

read the original abstract
This study aims to determine whether the application of Deep Reinforcement Learning (DRL) as a specialized execution overlay can enhance pair trading in highly volatile cryptocurrency markets. Although classical implementations of the strategy have proven successful in traditional equities, they frequently exhibit rigidity and suffer from severe divergence risks when applied to high-variance environments. To address this need, this research introduces novel concepts. To construct a robust system, we developed a hierarchical "Filter-then-Rank" pair selection methodology and a proprietary "Fixed Risk, Adaptive Mean" execution model. The system employs a Proximal Policy Optimization (PPO) agent with a Long Short-Term Memory (LSTM) layer to govern execution decisions within strict deterministic risk management boundaries. Evaluated on 1-hour interval data from the Binance USD-M Futures market, the optimized RL policy achieved an out-of-sample performance that substantially outperformed the heuristic baseline. A stationary circular block bootstrap robustness check confirms that the agent's risk-adjusted outperformance is statistically significant at the 10 percent level. Although falling marginally short of the stricter 5 percent threshold, this result highlights the extreme idiosyncratic variance characteristic of digital assets. Ultimately, this thesis contributes to the quantitative finance literature by introducing a hybrid architecture that combines statistical arbitrage with DRL execution policies. Furthermore, it delivers a novel framework for safe reinforcement learning via deterministic shielding, proving that anchoring a neural policy to statistically robust boundaries successfully mitigates severe divergence risks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a hybrid pair trading strategy for cryptocurrency markets that combines a hierarchical Filter-then-Rank pair selection methodology with a proprietary Fixed Risk, Adaptive Mean execution model. A PPO agent with an LSTM layer governs execution decisions inside deterministic shielding boundaries. Evaluated on 1-hour Binance USD-M Futures data, the optimized RL policy is reported to substantially outperform a heuristic baseline out-of-sample, with risk-adjusted performance statistically significant at the 10% level via a stationary circular block bootstrap robustness check. The work claims to contribute a novel safe-RL framework that mitigates divergence risks in volatile digital-asset markets.
Significance. If the empirical results and robustness claims hold after additional validation, the paper supplies a concrete example of anchoring neural policies to statistically derived boundaries for safe execution in high-variance environments. The circular-block bootstrap is a constructive element, and the hybrid statistical-arbitrage-plus-DRL architecture could interest quantitative-finance readers if the shielding mechanism is shown to remain effective under regime shifts.
major comments (3)
- [Abstract] Abstract: the central claim that deterministic shielding 'successfully mitigates severe divergence risks' rests on the untested premise that the Fixed Risk, Adaptive Mean model and shielding boundaries remain unbiased when cointegration breaks; no boundary-violation rates, regime-shift diagnostics, or LSTM behavior under violated assumptions are reported.
- [Methodology] Methodology (pair-selection and execution sections): the heuristic baseline against which outperformance is measured is not described in sufficient detail to determine whether the reported gains reflect genuine generalization or in-sample fitting; this directly affects interpretation of the 10% significance result.
- [Results] Results (bootstrap and performance evaluation): the stationary circular block bootstrap addresses serial dependence under stationarity but does not probe structural breaks or non-stationary regimes typical of crypto markets; given that the significance is already marginal (10%), this omission weakens the robustness claim.
minor comments (2)
- [Abstract] Abstract: the phrase 'novel concepts' is used without enumerating what is claimed to be novel beyond the named models; a concise list would improve clarity.
- The manuscript refers to 'proprietary' components; if the journal requires reproducibility, consider whether additional pseudocode or parameter ranges can be supplied without compromising the proprietary claim.
Simulated Author's Rebuttal
We thank the referee for their insightful comments on our manuscript. We address each major comment below and indicate where revisions will be made to improve the paper.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that deterministic shielding 'successfully mitigates severe divergence risks' rests on the untested premise that the Fixed Risk, Adaptive Mean model and shielding boundaries remain unbiased when cointegration breaks; no boundary-violation rates, regime-shift diagnostics, or LSTM behavior under violated assumptions are reported.
Authors: We acknowledge that the manuscript does not explicitly report boundary-violation rates or regime-shift diagnostics. However, the out-of-sample evaluation demonstrates the policy's performance under real market conditions, including volatility. In the revision, we will add a new subsection detailing observed boundary violations during the test period and analyze LSTM actions when assumptions may be strained. This will provide empirical support for the shielding mechanism's effectiveness. revision: yes
-
Referee: [Methodology] Methodology (pair-selection and execution sections): the heuristic baseline against which outperformance is measured is not described in sufficient detail to determine whether the reported gains reflect genuine generalization or in-sample fitting; this directly affects interpretation of the 10% significance result.
Authors: We agree that more detail on the heuristic baseline is necessary for proper interpretation. The baseline is outlined in the methodology section, but we will expand it with specific parameters, decision rules, and implementation details to allow readers to fully assess the comparison and the validity of the statistical significance. revision: yes
-
Referee: [Results] Results (bootstrap and performance evaluation): the stationary circular block bootstrap addresses serial dependence under stationarity but does not probe structural breaks or non-stationary regimes typical of crypto markets; given that the significance is already marginal (10%), this omission weakens the robustness claim.
Authors: The stationary circular block bootstrap was chosen to account for serial dependence in the returns series while maintaining the stationarity assumption appropriate for the block length selection. We recognize that it does not explicitly test for structural breaks, which is a valid concern in crypto markets. In the revised version, we will include a discussion of this limitation and perform additional robustness checks, such as performance evaluation across sub-periods to probe regime shifts where data permits. revision: partial
Circularity Check
No significant circularity detected
full rationale
The paper introduces a Filter-then-Rank pair selection and proprietary Fixed Risk, Adaptive Mean execution model, then trains a PPO-LSTM policy inside deterministic shielding boundaries on Binance futures data. Out-of-sample performance is compared to a heuristic baseline and assessed via stationary circular block bootstrap. No quoted equations, definitions, or self-citations reduce any claimed prediction or result to its own inputs by construction; the bootstrap is a standard external statistical procedure and the evaluation split is presented as independent. The derivation chain therefore remains self-contained with independent empirical content.
Axiom & Free-Parameter Ledger
free parameters (1)
- RL policy and risk-boundary parameters
axioms (1)
- domain assumption Binance USD-M futures 1-hour data is sufficiently stationary and representative for out-of-sample evaluation
invented entities (2)
-
Fixed Risk, Adaptive Mean execution model
no independent evidence
-
deterministic shielding framework for safe RL
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Safe rein- forcement learning via shielding
Alshiekh, M., Bloem, R., Ehlers, R., Könighofer, B., Niekum, S., Topcu, U., 2018. Safe rein- forcement learning via shielding. Proceedings of the AAAI Conference on Artificial Intelligence
2018
-
[2]
URL:https://doi.org/10.1609/aaai.v32i1.11797
-
[3]
Regime changes in bitcoin garch volatility dynamics
Ardia, D., Bluteau, K., Rüede, M., 2019. Regime changes in bitcoin garch volatility dynamics. Finance Research Letters 29, 266–271. URL:https://doi.org/10.1016/j.frl.2018.08. 009
-
[4]
Leverage aversion and risk parity
Asness, C., Frazzini, A., Pedersen, L., 2012. Leverage aversion and risk parity. Financial Analysts Journal 68, 47–59. URL:https://doi.org/10.2469/faj.v68.n1.1
-
[5]
Statistical arbitrage in the us equities market
Avellaneda, M., Lee, J.H., 2010. Statistical arbitrage in the us equities market. Quantitative Finance 10, 761–782. URL:https://doi.org/10.1080/14697680903124632
-
[6]
Bailey, D., Borwein, J.J., Lopez de Prado, M., Zhu, Q., 2014. Pseudo-mathematics and finan- cial charlatanism: The effects of backtest overfitting on out-of-sample performance. Notices of the American Mathematical Society 61, 458. URL:https://doi.org/10.1090/noti1105
-
[7]
Selection of a portfolio of pairs based on cointegration: A statistical arbitrage strategy
Caldeira, J.F., Moura, G.V., 2013. Selection of a portfolio of pairs based on cointegration: A statistical arbitrage strategy. Brazilian Review of Finance 11, 49–80. URL:https://doi. org/10.12660/rbfin.v11n1.2013.4785
-
[8]
Does simple pairs trading still work? Financial Analysts Journal 66, 83–95
Do, B., Faff, R., 2010. Does simple pairs trading still work? Financial Analysts Journal 66, 83–95. URL:https://doi.org/10.2469/faj.v66.n4.1
-
[9]
Dulac-Arnold, G., Levine, N., Mankowitz, D.J., Li, J., Paduraru, C., Gowal, S., Hester, T.,
-
[10]
Challenges of real- world reinforcement learning,
Challenges of real-world reinforcement learning: definitions, benchmarks and analysis. Machine Learning 110, 2419–2468. URL:https://doi.org/10.1007/s10994-021-05961-4
-
[11]
Elliott, R.J., *, J.V.D.H., Malcolm, W.P., 2005. Pairs trading. Quantitative Finance 5, 271–276. URL:https://doi.org/10.1080/14697680500149370
-
[12]
Co-integration and error correction: Representation, esti- mation, and testing
Engle, R.F., Granger, C.W.J., 1987. Co-integration and error correction: Representation, esti- mation, and testing. Econometrica 55, 251–276. URL:https://doi.org/10.2307/1913236
-
[13]
Implementation matters in deep policy gradients: A case study on ppo and trpo
Engstrom, L., Ilyas, A., Santurkar, S., Tsipras, D., Janoos, F., Rudolph, L., Madry, A., 2020. Implementation matters in deep policy gradients: A case study on ppo and trpo. URL: https://arxiv.org/abs/2005.12729,arXiv:2005.12729
arXiv 2020
-
[14]
Statistical arbitrage in cryptocurrency mar- kets
Fischer, T.G., Krauss, C., Deinert, A., 2019. Statistical arbitrage in cryptocurrency mar- kets. Journal of Risk and Financial Management 12. URL:https:/doi.org/10.3390/ jrfm12010031
2019
-
[15]
A comprehensive survey on safe reinforcement learning
García, J., Fern, o Fernández, 2015. A comprehensive survey on safe reinforcement learning. Journal of Machine Learning Research 16, 1437–1480. URL:http://jmlr.org/papers/v16/ garcia15a.html
2015
-
[16]
Pairs trading: Performance of a relative-value arbitrage rule
Gatev, E., Goetzmann, W.N., Rouwenhorst, K.G., 2006. Pairs trading: Performance of a relative-value arbitrage rule. The Review of Financial Studies 19, 797–827. URL:https: //doi.org/10.1093/rfs/hhj020
-
[17]
Deep learning statistical arbitrage
Guijarro-Ordonez, J., Pelger, M., Zanotti, G., 2022. Deep learning statistical arbitrage. URL: https://arxiv.org/abs/2106.04028,arXiv:2106.04028
arXiv 2022
-
[18]
Deep rein- forcement learning that matters
Henderson, P., Islam, R., Bachman, P., Pineau, J., Precup, D., Meger, D., 2018. Deep rein- forcement learning that matters. Proceedings of the AAAI Conference on Artificial Intelligence
2018
-
[19]
URL:https://doi.org/10.1609/aaai.v32i1.11694
-
[20]
Long short-term memory.Neural Computation, 9(8): 1735–1780, 1997
Hochreiter, S., Schmidhuber, J., 1997. Long short-term memory. Neural Computation 9, 1735–1780. URL:https://doi.org/10.1162/neco.1997.9.8.1735. 59
-
[21]
Long-term storage capacity of reservoirs
Hurst, H.E., 1951. Long-term storage capacity of reservoirs. Transactions of the American Society of Civil Engineers 116, 770–799. URL:https://doi.org/10.1061/TACEAT.0006518
-
[22]
A deep reinforcement learning framework for the financial portfolio management problem
Jiang, Z., Xu, D., Liang, J., 2017. A deep reinforcement learning framework for the financial portfolio management problem. URL:https://arxiv.org/abs/1706.10059, arXiv:1706.10059
Pith/arXiv arXiv 2017
-
[23]
Statisticalanalysisofcointegrationvectors
Johansen, S., 1988. Statisticalanalysisofcointegrationvectors. JournalofEconomicDynamics and Control 12, 231–254. URL:https://doi.org/10.1016/0165-1889(88)90041-3
-
[24]
Prospect theory: An analysis of decision under risk
Kahneman, D., Tversky, A., 1979. Prospect theory: An analysis of decision under risk. Econometrica 47, 263–291. URL:http://doi.org/10.2307/1914185
-
[25]
Kim, T., Kim, H.Y., 2019. Optimizing the pairs-trading strategy using deep reinforcement learning with trading and stop-loss boundaries. Complexity 2019. URL:https://doi.org/ 10.1155/2019/3582516
-
[26]
Korniejczuk, A., Ślepaczuk, R., 2024. Statistical arbitrage in multi-pair trading strategy based on graph clustering algorithms in us equities market. URL:https://arxiv.org/abs/2406. 10695,arXiv:2406.10695
arXiv 2024
-
[27]
Statistical arbitrage pairs trading strategies: Review and outlook
Krauss, C., 2017. Statistical arbitrage pairs trading strategies: Review and outlook. Journal of Economic Surveys 31, 513–545. URL:https://doi.org/10.1111/joes.12153
-
[28]
Optimal parameter selection and indica- tor design for technical analysis strategies by computer software: An empirical analysis of the taiwan futures market
Lin, H.Y., ChiangLin, C.Y., Tseng, H.W., 2024. Optimal parameter selection and indica- tor design for technical analysis strategies by computer software: An empirical analysis of the taiwan futures market. Engineering Proceedings 74. URL:https://doi.org/10.3390/ engproc2024074056
2024
-
[29]
Finrl: A deep reinforcement learning library for automated stock trading in quantitative finance
Liu, X.Y., Yang, H., Chen, Q., Zhang, R., Yang, L., Xiao, B., Wang, C.D., 2022. Finrl: A deep reinforcement learning library for automated stock trading in quantitative finance. URL: https://arxiv.org/abs/2011.09607,arXiv:2011.09607
arXiv 2022
-
[30]
Magdon-Ismail, M., Atiya, A.F., Pratap, A., Abu-Mostafa, Y.S., 2004. On the maximum drawdown of a brownian motion. Journal of Applied Probability 41, 147–161. URL:http: //doi.org/10.1239/jap/1077134674
-
[31]
Trading and arbitrage in cryptocurrency markets
Makarov, I., Schoar, A., 2020. Trading and arbitrage in cryptocurrency markets. Journal of Financial Economics 135, 293–319. URL:https://doi.org/10.1016/j.jfineco.2019.07. 001
-
[32]
Risk-sensitive reinforcement learning
Mihatsch, O., Neuneier, R., 2002. Risk-sensitive reinforcement learning. Machine Learning 49, 267–290. URL:https://doi.org/10.1023/A:1017940631555
-
[33]
Time limits in reinforcement learning
Pardo, F., Tavakoli, A., Levdik, V., Kormushev, P., 2022. Time limits in reinforcement learning. URL:10.48550/arXiv.1712.00378,arXiv:1712.00378
-
[34]
Politis, D.N., Romano, J.P., 1994. The stationary bootstrap. Journal of the American Statisti- cal Association 89, 1303–1313. URL:https://doi.org/10.1080/01621459.1994.10476870
-
[35]
Advances in Financial Machine Learning
López de Prado, M., 2018. Advances in Financial Machine Learning. John Wiley & Sons. URL:https://books.google.pl/books?id=v0RKDwAAQBAJ
2018
-
[36]
Stock market prediction with multiple classifiers
Qian, B., Rasheed, K., 2007. Stock market prediction with multiple classifiers. Applied Intelligence 26, 25–33. URL:https://doi.org/10.1007/s10489-006-0001-7
-
[37]
Introducing hurst ex- ponent in pair trading
Ramos-Requena, J., Trinidad-Segovia, J., Sánchez-Granero, M., 2017. Introducing hurst ex- ponent in pair trading. Physica A: Statistical Mechanics and its Applications 488, 39–45. URL:https://doi.org/10.1016/j.physa.2017.06.032
-
[38]
Proximal Policy Optimization Algorithms
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., Klimov, O., 2017. Proximal policy optimization algorithms. URL:https://doi.org/10.48550/arXiv.1707.06347, arXiv:1707.06347. 60
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1707.06347 2017
-
[39]
URLhttp://dx.doi.org/10.1086/294846
Sharpe, W.F., 1966. Mutual fund performance. The Journal of Business 39, 119–138. URL: http://doi.org/10.1086/294846
-
[40]
Performance measurement in a downside risk framework
Sortino, F.A., Price, L.N., 1994. Performance measurement in a downside risk framework. The Journal of Investing 3, 59–64. URL:https://doi.org/10.3905/joi.3.3.59
-
[41]
Reinforcement learning: An introduction
Sutton, R.S., Barto, A.G., 2018. Reinforcement learning: An introduction. Second ed., The MIT Press, Cambridge, Massachusetts. URL:http://incompleteideas.net/book/ the-book-2nd.html
2018
-
[42]
Chaper 9 - the kelly criterion in blackjack sports betting, and the stock market*
Thorp, E.O., 2008. Chaper 9 - the kelly criterion in blackjack sports betting, and the stock market*. Handbook of Asset and Liability Management 1, 385–428. URL:https://doi.org/ 10.1016/B978-044453248-0.50015-0
-
[43]
Deep reinforcement learning applied to statistical arbitrage investment strategy on cryptomarket
Vergara, G., Kristjanpoller, W., 2024. Deep reinforcement learning applied to statistical arbitrage investment strategy on cryptomarket. Applied Soft Computing 153, 111255. URL: https://doi.org/10.1016/j.asoc.2024.111255
-
[44]
Pairs Trading: Quantitative Methods and Analysis
Vidyamurthy, G., 2004. Pairs Trading: Quantitative Methods and Analysis. John Wiley & Sons
2004
-
[45]
Reinforcement learning pair trading: A dynamic scaling ap- proach
Yang, H., Malik, A., 2024. Reinforcement learning pair trading: A dynamic scaling ap- proach. Journal of Risk and Financial Management 17, 555. URL:http://doi.org/10. 3390/jrfm17120555
2024
-
[46]
Regimefolio: A regime aware ml system for sectoral portfolio optimization in dynamic markets
Zhang, Y., Goel, D., Ahmad, H., Szabo, C., 2025. Regimefolio: A regime aware ml system for sectoral portfolio optimization in dynamic markets. URL:https://doi.org/10.48550/ arXiv.2510.14986,arXiv:2510.14986. 61
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.