Learning by Shifting: Temporal View Construction for Time Series Contrastive Learning
Pith reviewed 2026-06-26 12:07 UTC · model grok-4.3
The pith
A simple deterministic temporal shift suffices to learn strong time series representations in contrastive learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
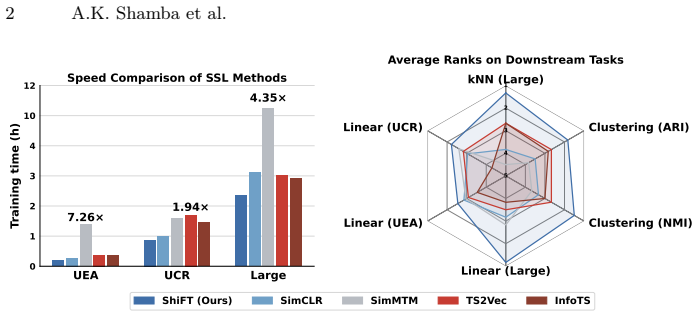
By replacing complex view-construction heuristics with a deterministic temporal shift, the ShiFT procedure produces positive pairs whose only guaranteed relation is a known time offset. Training a contrastive objective on these pairs learns representations that are invariant to such shifts and that transfer to classification tasks across diverse temporal datasets, outperforming prior self-supervised baselines while using less compute.
What carries the argument
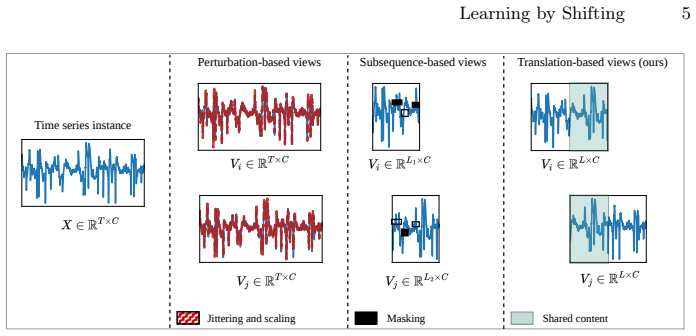
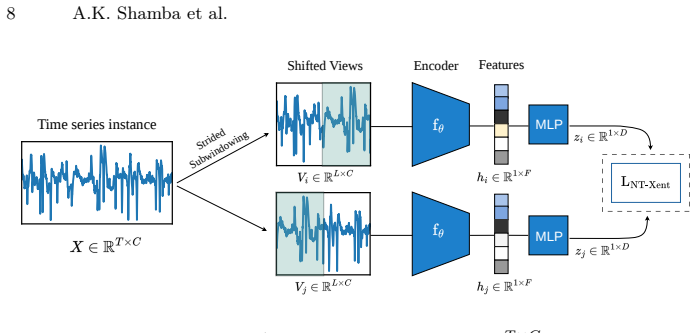
The deterministic temporal view construction inside Shift Invariant Feature Training (ShiFT), which generates each positive pair by applying a fixed time offset to the original series.
If this is right
- Representations learned this way generalize across varied temporal patterns without dataset-specific tuning.
- Training time decreases because view generation is a cheap deterministic operation rather than a stochastic augmentation pipeline.
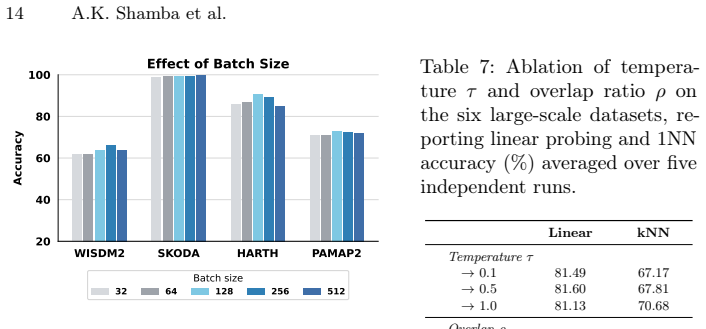
- Downstream classification performance remains stable across a range of batch sizes and negative counts, offering practical guidance for implementation.
- The same shift-based pairing can be applied to the full UCR and UEA archives and still yields state-of-the-art results.
Where Pith is reading between the lines
- Minimal, structure-preserving views may be preferable to rich but biased augmentations whenever the data possess an obvious invariance such as time translation.
- The approach could be tested on irregularly sampled or multivariate series to check whether the same deterministic shift remains sufficient.
- If the shift distance is treated as a hyper-parameter, one could measure how downstream accuracy varies with that distance to identify an optimal scale of invariance.
Load-bearing premise
Hand-crafted augmentations necessarily embed strong domain assumptions that hurt generalization, whereas a plain temporal shift introduces no new spurious correlations.
What would settle it
A controlled experiment in which ShiFT is trained and evaluated on the same six benchmarks but achieves materially lower accuracy than at least one established augmentation-based contrastive baseline.
Figures
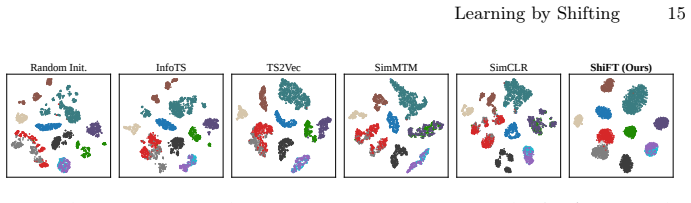
read the original abstract
Supervised learning demands large quantities of labeled data, a bottleneck that is expensive and reliant on domain-specific expertise. Self-supervised learning, particularly contrastive learning, has emerged as a compelling alternative, enabling rich representation learning directly from unlabeled data. Yet its success hinges critically on the design of positive and negative sample pairs. Existing approaches for time series rely on hand-crafted augmentations and masking heuristics that embed strong domain assumptions, often limiting generalization across diverse temporal patterns and potentially introducing spurious correlations. In this work, we challenge this paradigm by demonstrating that explicitly encoding temporal shift invariance through a simple, deterministic view construction is sufficient to learn strong representations for time series classification. By exploiting temporal structure, our method, Shift Invariant Feature Training (ShiFT), achieves state-of-the-art performance on six diverse real-world time series benchmark datasets, as well as the UCR and UEA archives, while reducing training time. Beyond empirical performance, we present a systematic analysis of contrastive learning dynamics in time series settings, examining the effects of batch size and the number of negatives on downstream performance. Our findings provide practical insights for designing efficient contrastive learning frameworks for time series representation learning. The source code is publicly available at https://github.com/sfi-norwai/ShiFT.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ShiFT (Shift Invariant Feature Training), a contrastive learning framework for time series that constructs positive pairs via a simple deterministic temporal shift to explicitly encode shift invariance. It claims this suffices to learn strong representations, achieving SOTA on six real-world benchmarks plus UCR/UEA archives, reducing training time relative to augmentation-heavy baselines, and includes analysis of batch size and negative sample count effects on downstream classification performance. Code is released publicly.
Significance. If the empirical results hold under the stated construction, the work would show that complex hand-crafted augmentations are unnecessary for effective time-series contrastive learning and that a minimal deterministic shift can avoid the domain assumptions they introduce. Public code supports reproducibility; the dynamics analysis on batch size and negatives could offer practical guidance for the field.
major comments (2)
- [Abstract] Abstract: the SOTA claim and reduced training time assertion are presented without reference to any baselines, statistical tests, ablation results, or dataset names, rendering the central empirical contribution unverifiable from the provided text and undermining assessment of the sufficiency claim.
- [Abstract] Method/Experiments (implied by abstract's contrast with existing approaches): the assertion that the deterministic shift 'avoids spurious correlations' is load-bearing for the novelty but relies on the untested premise that temporal shifts preserve downstream labels across all evaluated benchmarks; no analysis or stratification addresses non-stationary series or cases where class depends on event timing (e.g., early vs. late anomalies), as required by the central claim.
minor comments (1)
- [Abstract] Abstract: the phrase 'six diverse real-world time series benchmark datasets' is stated without enumeration, reducing clarity on the scope of the claimed generalization.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address each major comment below, indicating planned revisions to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the SOTA claim and reduced training time assertion are presented without reference to any baselines, statistical tests, ablation results, or dataset names, rendering the central empirical contribution unverifiable from the provided text and undermining assessment of the sufficiency claim.
Authors: We agree that the abstract's brevity limits immediate verifiability of the empirical claims. In the revised version we will expand the abstract to name the six real-world benchmarks, reference the UCR/UEA archives, and note that detailed baseline comparisons (including training-time measurements) appear in Section 4, while preserving conciseness. revision: yes
-
Referee: [Abstract] Method/Experiments (implied by abstract's contrast with existing approaches): the assertion that the deterministic shift 'avoids spurious correlations' is load-bearing for the novelty but relies on the untested premise that temporal shifts preserve downstream labels across all evaluated benchmarks; no analysis or stratification addresses non-stationary series or cases where class depends on event timing (e.g., early vs. late anomalies), as required by the central claim.
Authors: The empirical results across the chosen benchmarks provide supporting evidence that the deterministic shift yields strong representations without the spurious correlations introduced by more complex augmentations. Nevertheless, we acknowledge the absence of explicit stratification by non-stationarity or timing-dependent label structure. We will add a dedicated limitations paragraph in the revised manuscript that discusses this modeling assumption and identifies datasets where the approach may be less suitable. revision: yes
Circularity Check
No circularity: empirical method with independent benchmark validation
full rationale
The paper describes an empirical contrastive learning approach (ShiFT) that constructs positive pairs via deterministic temporal shifts and evaluates it on UCR/UEA and other benchmarks. No equations, derivations, or fitted parameters are presented that reduce to the inputs by construction. Central performance claims rest on external dataset comparisons rather than self-referential fitting or self-citation chains. The method is self-contained against public benchmarks and released code, satisfying the criteria for a non-circular empirical result.
Axiom & Free-Parameter Ledger
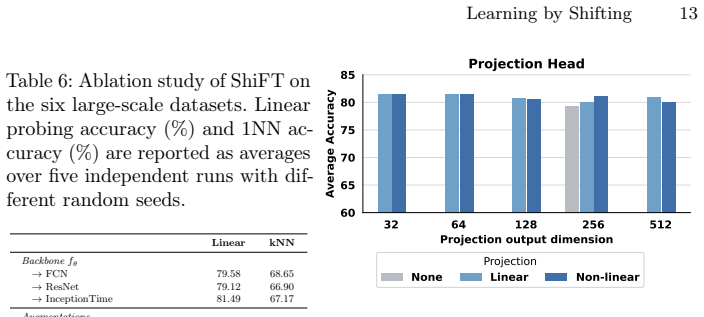
free parameters (2)
- batch size
- number of negatives
axioms (1)
- domain assumption Positive pairs created by temporal shifts are semantically similar enough for effective contrastive learning
Reference graph
Works this paper leans on
-
[1]
Bagnall, A., Dau, H.A., Lines, J., Flynn, M., Large, J., Bostrom, A., Southam, P., Keogh, E.: The uea multivariate time series classification archive, 2018 (2018), https://arxiv.org/abs/1811.00075
Pith/arXiv arXiv 2018
-
[2]
In: Proceedings of the International Conference on Computer Vision (ICCV) (2021) 16 A.K
Caron, M., Touvron, H., Misra, I., Jégou, H., Mairal, J., Bojanowski, P., Joulin, A.: Emerging properties in self-supervised vision transformers. In: Proceedings of the International Conference on Computer Vision (ICCV) (2021) 16 A.K. Shamba et al
2021
-
[3]
In: International conference on machine learning
Chen, T., Kornblith, S., Norouzi, M., Hinton, G.: A simple framework for contrastive learning of visual representations. In: International conference on machine learning. pp. 1597–1607. PMLR (2020)
2020
-
[4]
IEEE/CAA Journal of Automatica Sinica6(6), 1293–1305 (2019)
Dau, H.A., Bagnall, A., Kamgar, K., Yeh, C.C.M., Zhu, Y., Gharghabi, S., Ratanamahatana, C.A., Keogh, E.: The ucr time series archive. IEEE/CAA Journal of Automatica Sinica6(6), 1293–1305 (2019)
2019
-
[5]
Dong, J., Wu, H., Zhang, H., Zhang, L., Wang, J., Long, M.: Simmtm: A simple pre- trainingframeworkformaskedtime-seriesmodeling.AdvancesinNeuralInformation Processing Systems36, 29996–30025 (2023)
2023
-
[6]
In: The Fourteenth International Conference on Learning Representations (2026),https://openreview.net/forum?id=vTLmHAkoIW
Dou, Z., Yao, Z., Xie, Z., Wen, X., Xiao, T., Pei, D.: AutoDA-timeseries: Automated data augmentation for time series. In: The Fourteenth International Conference on Learning Representations (2026),https://openreview.net/forum?id=vTLmHAkoIW
2026
-
[7]
In: International Conference on Learning Representations (2018),https://openreview.net/forum?id=S1v4N2l0-
Gidaris, S., Singh, P., Komodakis, N.: Unsupervised representation learning by pre- dicting image rotations. In: International Conference on Learning Representations (2018),https://openreview.net/forum?id=S1v4N2l0-
2018
-
[8]
Christoph Hofer, Florian Graf, Bastian Rieck, Marc Niethammer, and Roland Kwitt
Goldberger, A., Amaral, L., Glass, L., Hausdorff, J., Ivanov, P., Mark, R., Mietus, J., Moody, G., Peng, C.K., Stanley, H.: Physiobank, physiotoolkit, and physionet : Components of a new research resource for complex physiologic signals. Circulation 101, E215–20 (07 2000).https://doi.org/10.1161/01.CIR.101.23.e215
-
[9]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
He, K., Fan, H., Wu, Y., Xie, S., Girshick, R.: Momentum contrast for unsupervised visual representation learning. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 9729–9738 (2020)
2020
-
[10]
Data Mining and Knowledge Discovery34(6), 1936–1962 (2020)
Ismail Fawaz, H., Lucas, B., Forestier, G., Pelletier, C., Schmidt, D.F., Weber, J., Webb, G.I., Idoumghar, L., Muller, P.A., Petitjean, F.: Inceptiontime: Finding alexnet for time series classification. Data Mining and Knowledge Discovery34(6), 1936–1962 (2020)
1936
-
[11]
Sensors (Basel, Switzerland) 21(23) (2021).https://doi.org/10.3390/s21237853
Logacjov, A., Bach, K., Kongsvold, A., Bårdstu, H.B., Mork, P.J.: Harth: A human activity recognition dataset for machine learning. Sensors (Basel, Switzerland) 21(23) (2021).https://doi.org/10.3390/s21237853
-
[12]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Luo, D., Cheng, W., Wang, Y., Xu, D., Ni, J., Yu, W., Zhang, X., Liu, Y., Chen, Y., Chen, H., et al.: Time series contrastive learning with information-aware augmenta- tions. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 37, pp. 4534–4542 (2023)
2023
-
[13]
In: Computers in Cardiology
Moody, G.B., Mark, R.G.: A new method for detecting atrial fibrillation using r-r intervals. In: Computers in Cardiology. pp. 227–230 (1983)
1983
-
[14]
In: European conference on computer vision
Noroozi, M., Favaro, P.: Unsupervised learning of visual representations by solving jigsaw puzzles. In: European conference on computer vision. pp. 69–84. Springer (2016)
2016
-
[15]
arXiv preprint arXiv:1807.03748 (2018)
Oord, A.v.d., Li, Y., Vinyals, O.: Representation learning with contrastive predictive coding. arXiv preprint arXiv:1807.03748 (2018)
Pith/arXiv arXiv 2018
-
[16]
In: 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
Pathak, D., Krähenbühl, P., Donahue, J., Darrell, T., Efros, A.A.: Context encoders: Feature learning by inpainting. In: 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). pp. 2536–2544 (2016).https://doi.org/10.1109/ CVPR.2016.278
2016
-
[17]
In: 2012 16th international symposium on wearable computers
Reiss, A., Stricker, D.: Introducing a new benchmarked dataset for activity moni- toring. In: 2012 16th international symposium on wearable computers. pp. 108–109. IEEE (2012)
2012
-
[18]
In: Proceedings of the European Conference on Artificial Intelligence (ECAI)
Shamba, A.K., Bach, K., Taylor, G.: Contrast all the time: Learning time series rep- resentation from temporal consistency. In: Proceedings of the European Conference on Artificial Intelligence (ECAI). Frontiers in Artificial Intelligence and Applications, vol. 413, pp. 2810–2817 (2025),https://doi.org/10.3233/FAIA251137 Learning by Shifting 17
-
[19]
In: AAAI workshop on activity context representation: tech- niques and languages
Weiss, G.M., Lockhart, J.W.: The impact of personalization on smartphone-based activity recognition. In: AAAI workshop on activity context representation: tech- niques and languages. pp. 98–104. Toronto. (2012)
2012
-
[20]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Yue, Z., Wang, Y., Duan, J., Yang, T., Huang, C., Tong, Y., Xu, B.: Ts2vec: Towards universal representation of time series. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 36, pp. 8980–8987 (2022)
2022
-
[21]
ACM Transactions on Embedded Computing Systems (TECS)11(3), 1–30 (2012)
Zappi, P., Roggen, D., Farella, E., Tröster, G., Benini, L.: Network-level power- performance trade-off in wearable activity recognition: A dynamic sensor selection approach. ACM Transactions on Embedded Computing Systems (TECS)11(3), 1–30 (2012)
2012
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.