Venice-H1: Failure-Aware Query Re-Ranking with Multi-Scale Grid Signatures for Referring Image Segmentation
Pith reviewed 2026-06-26 11:20 UTC · model grok-4.3
The pith
Venice-H1 uses multi-scale grid signatures and a failure gate to re-rank candidate masks and close the 3-11% mIoU gap left by argmax selection in referring image segmentation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that encoding each candidate mask through multi-scale grid signatures and routing them to a Transformer re-ranker controlled by a Failure Gate (ROC-AUC 0.78-0.82) enables selective correction of argmax failures, producing consistent mIoU gains on the failure subset, strictly positive 95 percent confidence intervals on all 16 split-backbone combinations, and harmful-switch rates below 0.53 percent, with zero-shot gains observed on medical referring segmentation tasks.
What carries the argument
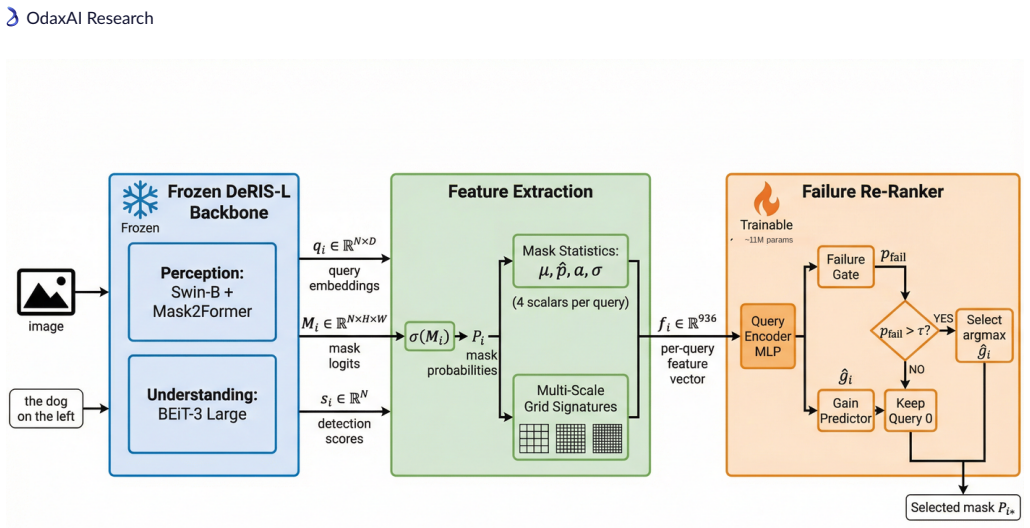
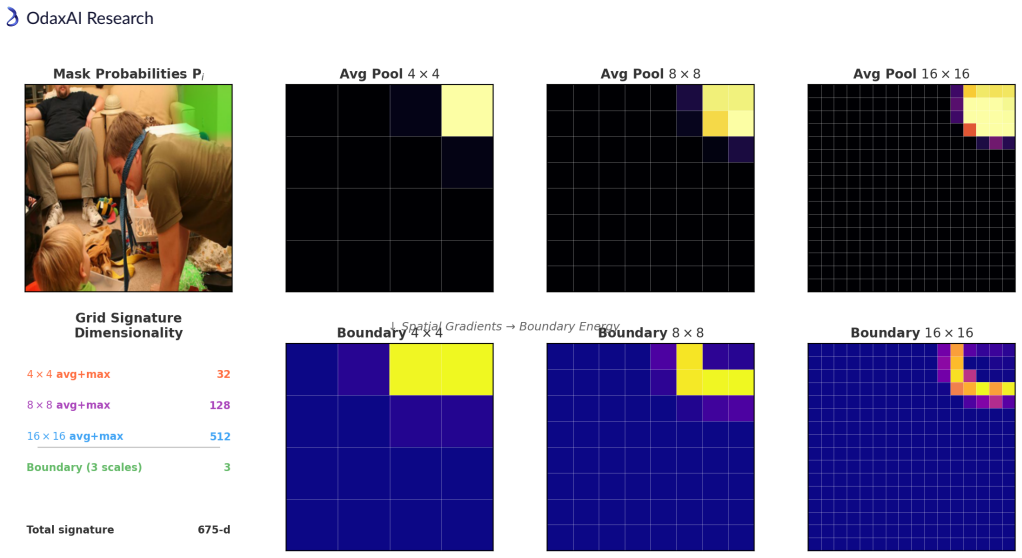
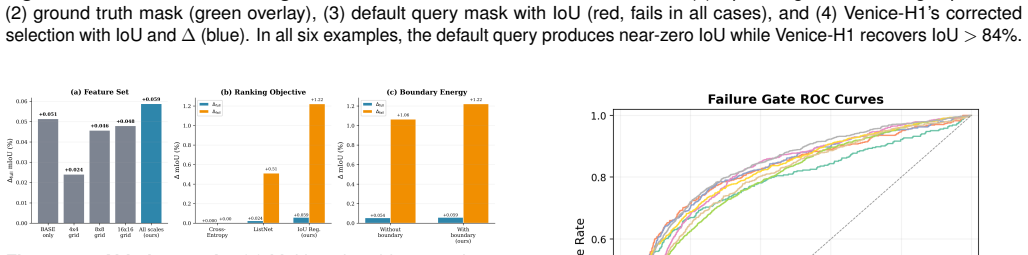
Multi-scale grid signatures—compact spatial descriptors pooled onto 4x4, 8x8, and 16x16 grids—fed to a Transformer-based re-ranker with an attached Failure Gate that decides whether to override the default argmax selection.
If this is right
- Failure-case mIoU rises by 1.40 points on DeRIS-L and 0.89 points on DeRIS-B across all evaluated splits and backbones.
- Harmful-switch rate stays below 0.53 percent while the gate intervenes only on predicted suboptimal cases.
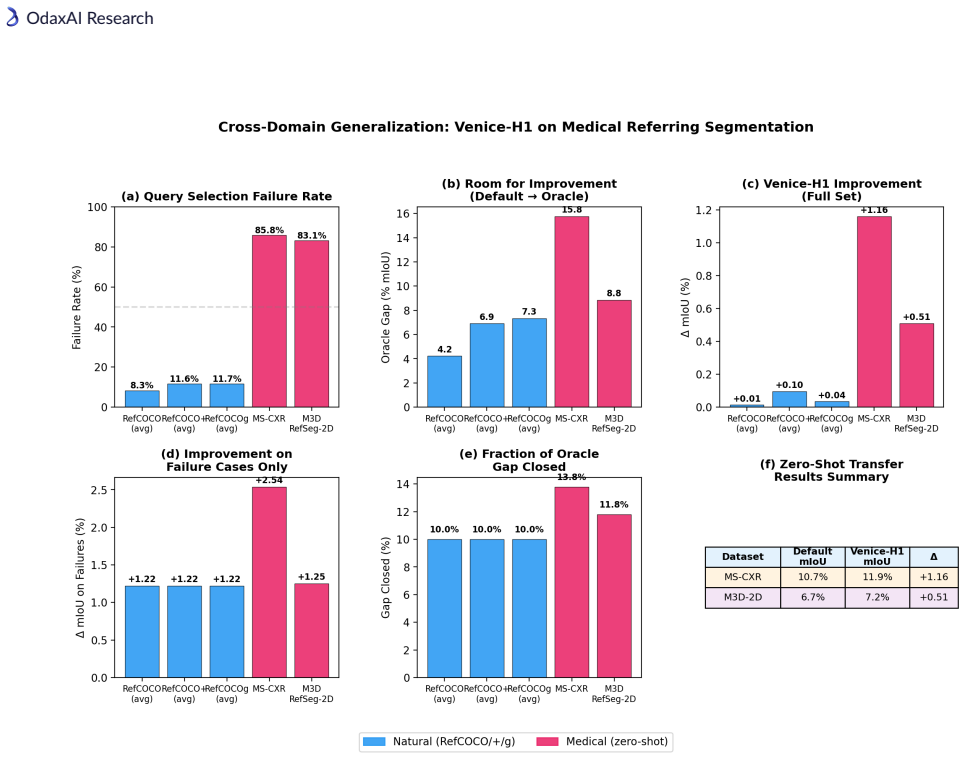
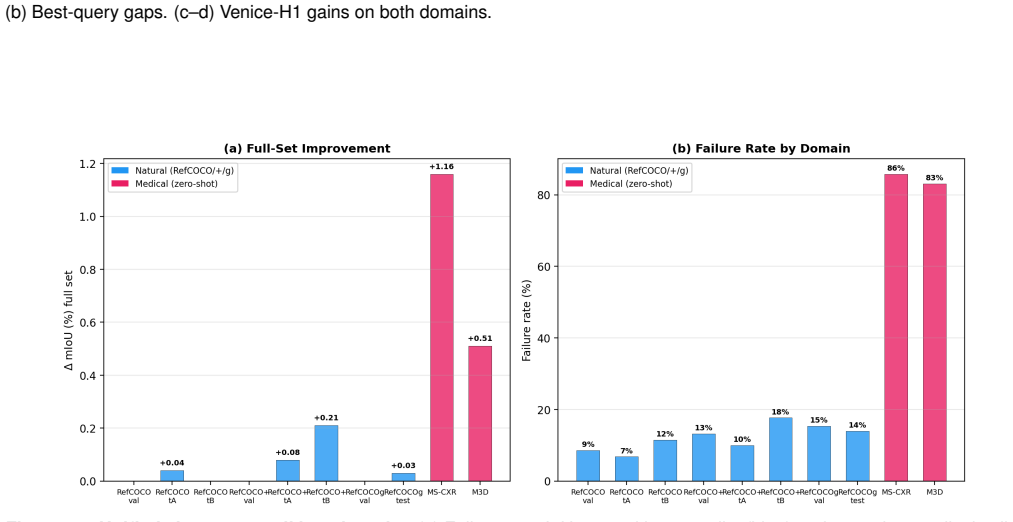
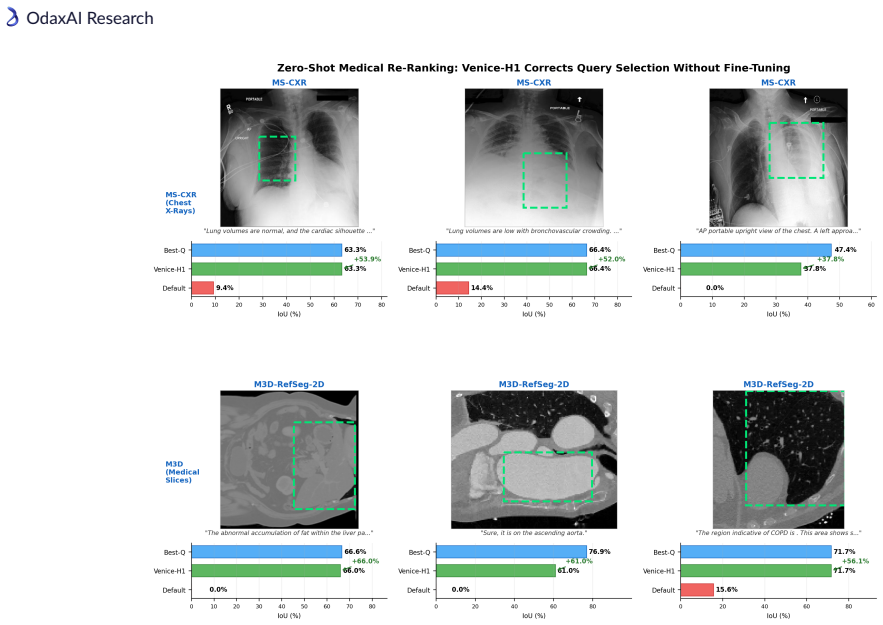
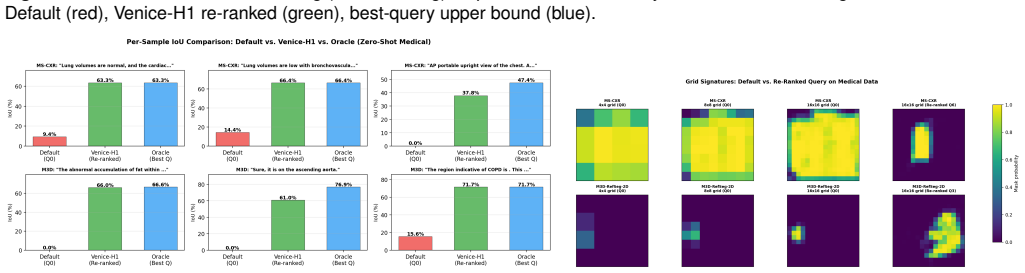
- Zero-shot transfer produces +1.16 mIoU on MS-CXR and +0.51 mIoU on M3D-RefSeg-2D without any RIS backbone fine-tuning.
- The module adds about 11.3 million parameters and less than 1 ms of inference latency.
Where Pith is reading between the lines
- The same grid-signature representation could be tested on other tasks that produce multiple spatial outputs, such as referring video segmentation or multi-object tracking.
- Because the gate is trained only on observed failure patterns, its reliability on entirely new query distributions remains an open measurement.
- If the signatures prove sufficient to distinguish correct from incorrect masks, they might replace heavier learned re-rankers in resource-constrained settings.
Load-bearing premise
The multi-scale grid signatures together with the trained Failure Gate can detect when the default argmax mask is suboptimal and can generalize that detection to unseen samples without introducing many harmful switches.
What would settle it
A new test set in which the Failure Gate triggers on more than 0.53 percent of samples that were originally correct under argmax, or where the net mIoU change on the failure subset falls to zero or negative with a 95 percent confidence interval that includes zero.
Figures




read the original abstract
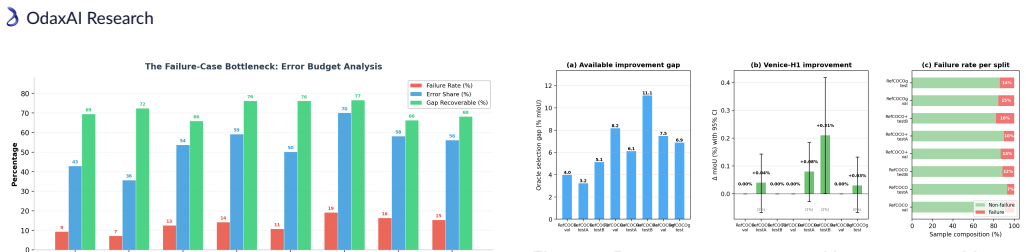
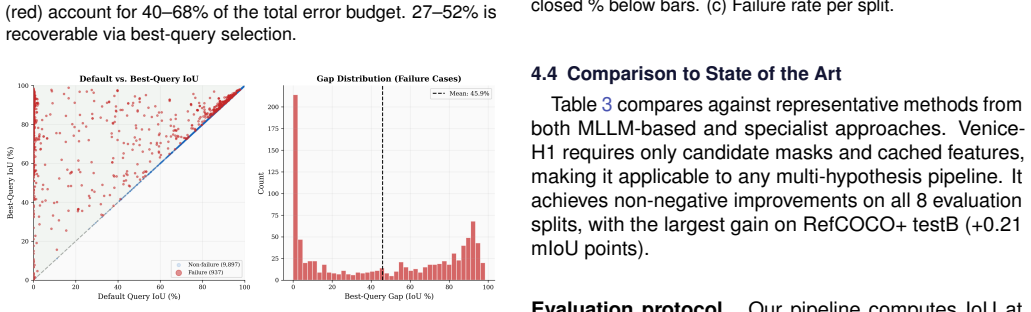
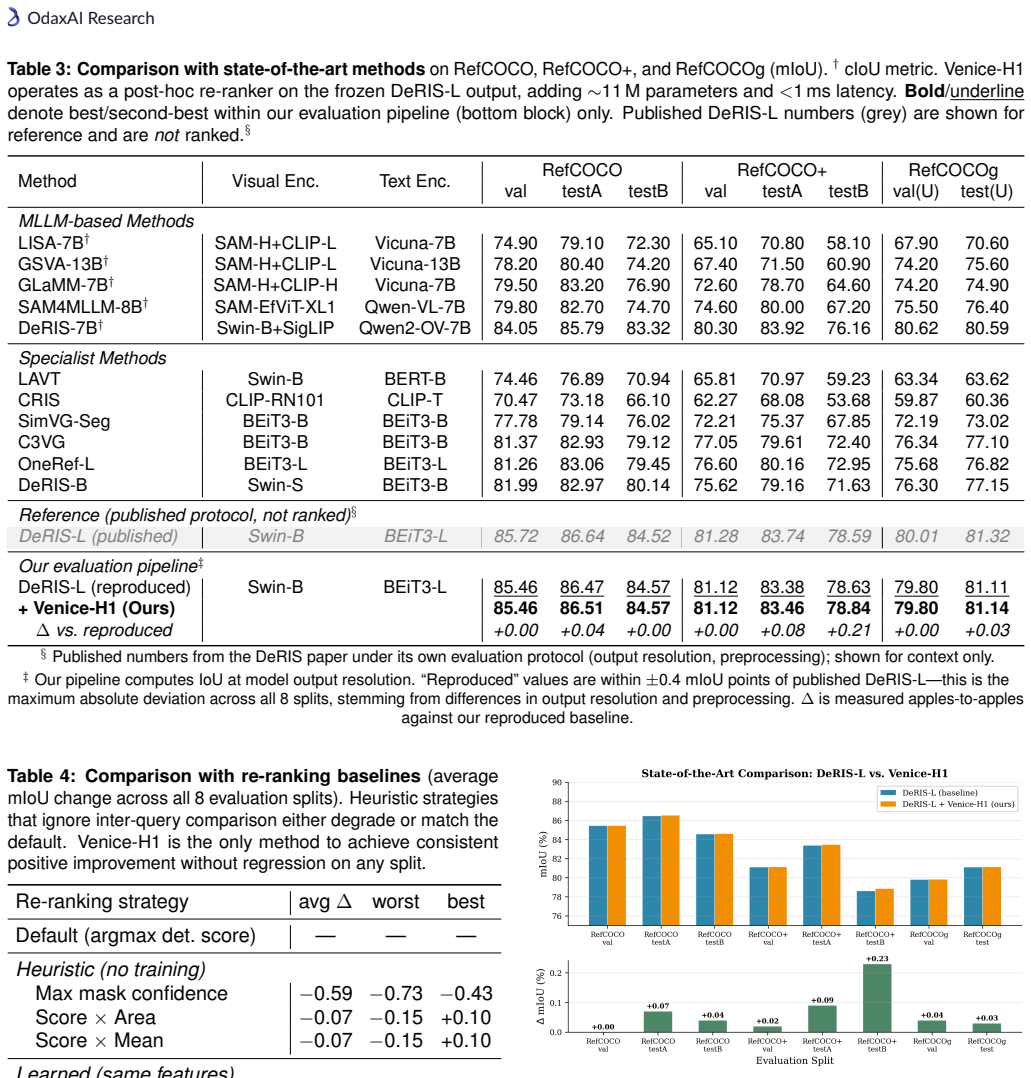
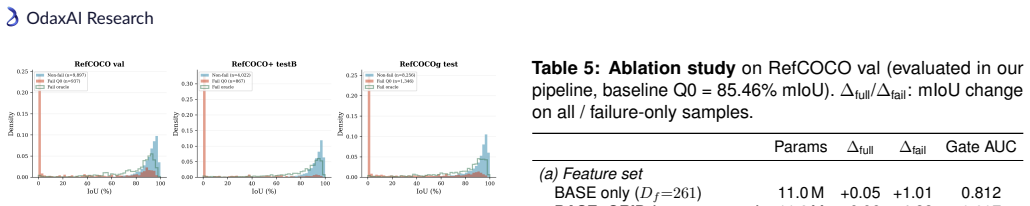
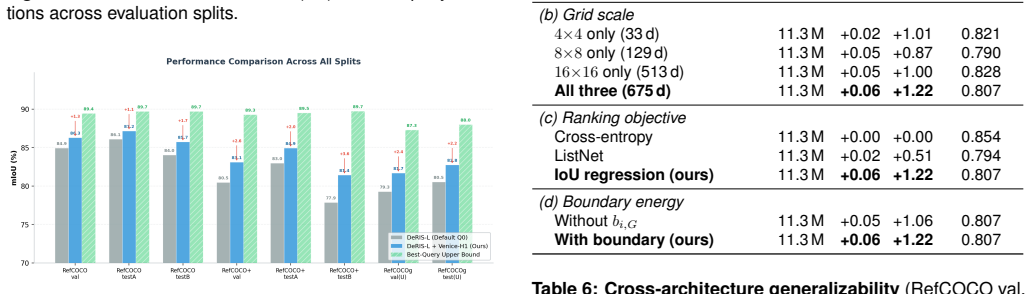
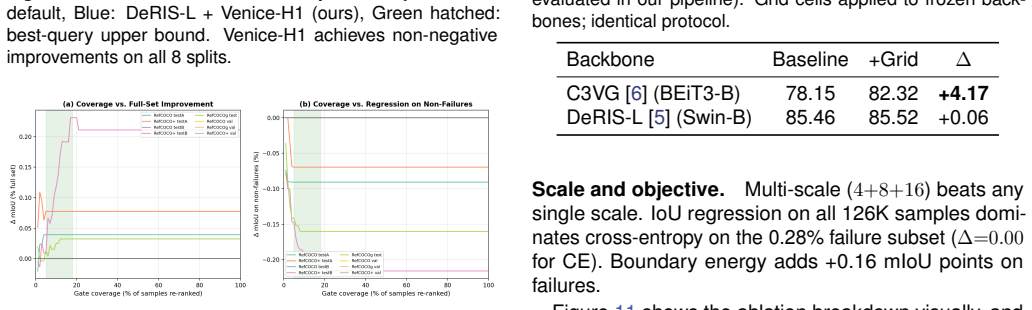
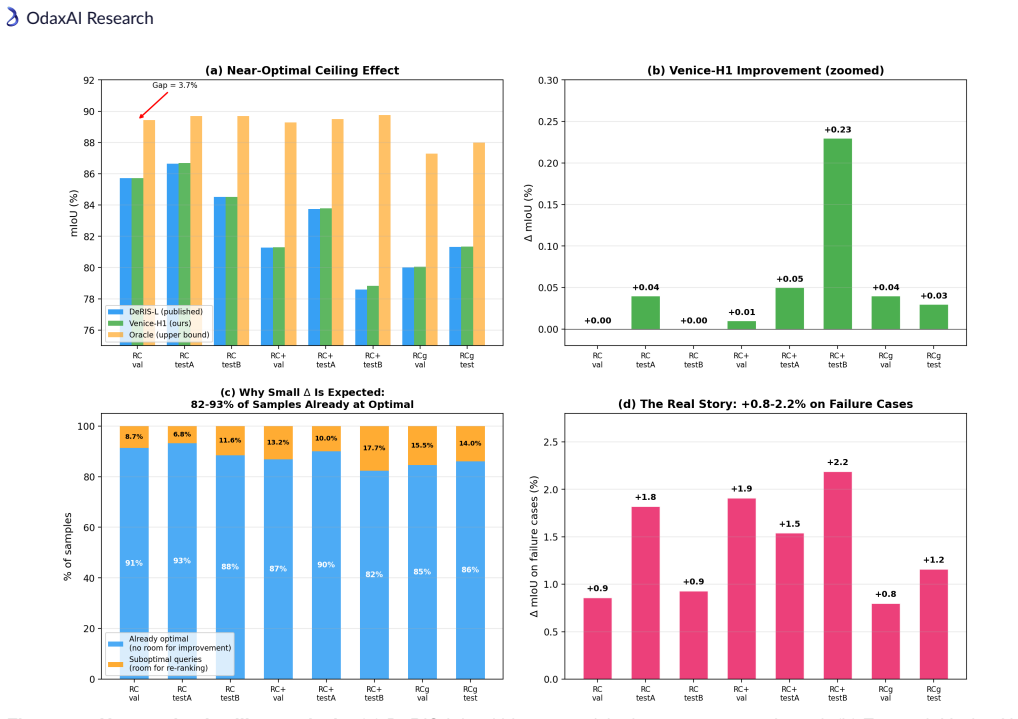
Modern Referring Image Segmentation (RIS) systems generate multiple candidate masks per expression but rely on a simple heuristic--typically the argmax detection score--to select the final output. We identify query selection as a failure-case bottleneck: although heuristic selection succeeds on 82-93% of samples, the residual 7-18% of failures dominate the error budget, leaving a best-query selection gap of 3-11% mIoU. We introduce Venice-H1, a lightweight, backbone-decoupled post-hoc re-ranking module that encodes each candidate through multi-scale grid signatures--compact spatial descriptors pooled onto 4x4, 8x8, and 16x16 grids--and feeds them to a Transformer-based re-ranker with a Failure Gate (ROCAUC 0.78-0.82) that intervenes only when the default choice is likely suboptimal. Instantiated on DeRIS-L and DeRIS-B, Venice-H1 achieves delta_fail of +1.40 and +0.89 mIoU with strictly positive 95% CIs on all 16/16 (split, backbone) pairs and harmful-switch rates below 0.53%. Zero-shot transfer to medical referring segmentation (MS-CXR, M3D-RefSeg-2D) yields +1.16 and +0.51 mIoU without RIS-backbone fine-tuning. The module adds approximately 11.3M parameters and under 1 ms latency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Venice-H1, a lightweight backbone-decoupled post-hoc re-ranking module for referring image segmentation (RIS). It encodes multiple candidate masks via multi-scale grid signatures (pooled on 4x4, 8x8, 16x16 grids) and feeds them to a Transformer re-ranker controlled by a Failure Gate (ROCAUC 0.78-0.82) that intervenes only when the default argmax is likely suboptimal. On DeRIS-L and DeRIS-B it reports delta_fail gains of +1.40 and +0.89 mIoU with strictly positive 95% CIs on all 16/16 (split, backbone) pairs, harmful-switch rates below 0.53%, and zero-shot transfer gains of +1.16 and +0.51 mIoU on MS-CXR and M3D-RefSeg-2D without RIS fine-tuning, at a cost of ~11.3M parameters and <1 ms latency.
Significance. If the reported gains and low harmful-switch rates hold under scrutiny, the work offers a practical, low-overhead solution to the query-selection bottleneck that dominates error in current RIS systems (7-18% failure cases). The consistent positive CIs across 16 evaluation settings and the zero-shot medical transfer without backbone retraining would indicate a generalizable failure-detection mechanism that is decoupled from the underlying RIS model.
major comments (1)
- [Abstract] Abstract: The central claims of delta_fail gains and harmful-switch rates <0.53% rest on the Failure Gate (ROCAUC 0.78-0.82) generalizing beyond the training distribution of argmax-vs-oracle mismatches. The moderate ROCAUC leaves limited headroom for distribution shift in query phrasing or mask failure modes; without explicit ablations on out-of-distribution failure cases or cross-dataset gate training details, the strictly positive CIs on all 16/16 pairs and the medical zero-shot results could reflect in-distribution behavior rather than robust detection.
minor comments (2)
- [Abstract] Abstract: The precise definitions of 'delta_fail' and 'harmful-switch rate' are not stated; a one-sentence definition or pointer to the evaluation protocol would aid immediate comprehension.
- [Abstract] Abstract: Grid resolutions are listed as 4x4/8x8/16x16 but the exact pooling operation, feature dimensionality, and how signatures are concatenated before the Transformer are not specified.
Simulated Author's Rebuttal
We thank the referee for highlighting the importance of verifying the Failure Gate's generalization. We address this concern directly below, drawing on the existing zero-shot transfer results as primary evidence.
read point-by-point responses
-
Referee: The central claims of delta_fail gains and harmful-switch rates <0.53% rest on the Failure Gate (ROCAUC 0.78-0.82) generalizing beyond the training distribution of argmax-vs-oracle mismatches. The moderate ROCAUC leaves limited headroom for distribution shift in query phrasing or mask failure modes; without explicit ablations on out-of-distribution failure cases or cross-dataset gate training details, the strictly positive CIs on all 16/16 pairs and the medical zero-shot results could reflect in-distribution behavior rather than robust detection.
Authors: We acknowledge that an ROCAUC of 0.78-0.82 is moderate and that explicit OOD ablations on failure-case distributions would strengthen the claims. However, the zero-shot transfer experiments on MS-CXR and M3D-RefSeg-2D constitute direct evidence of cross-domain generalization: these datasets use different imaging modalities, query phrasing, and mask failure patterns from the natural-image RIS training distribution, yet the module (including the gate) is applied without any RIS-backbone or re-ranker fine-tuning and still yields +1.16 and +0.51 mIoU gains. The strictly positive 95% CIs across all 16/16 (split, backbone) pairs further indicate that the observed improvements are not artifacts of a single distribution. We will revise the manuscript to (i) explicitly state that the gate was trained only on the source RIS argmax-vs-oracle mismatches and applied zero-shot to the medical sets, and (ii) add a short discussion of why the medical transfer serves as an OOD test for the gate. No new controlled OOD ablation experiments will be added, as the existing cross-domain results already address the core concern. revision: partial
Circularity Check
No circularity: empirical results on held-out data
full rationale
The paper introduces a post-hoc re-ranking module (multi-scale grid signatures + Transformer re-ranker + Failure Gate) and reports its performance via direct empirical measurements (mIoU deltas, harmful-switch rates, ROCAUC) on held-out test splits across 16/16 (split, backbone) pairs plus zero-shot medical transfer. No load-bearing derivation, equation, or prediction reduces to its own inputs by construction; the central claims rest on measured generalization rather than self-definition, fitted-input renaming, or self-citation chains. The moderate ROCAUC and generalization assumption are empirical risks, not circularity.
Axiom & Free-Parameter Ledger
free parameters (2)
- Grid resolutions
- Failure Gate operating point
axioms (1)
- domain assumption Default argmax selection succeeds on only 82-93% of samples, leaving a 7-18% failure set that dominates error.
Reference graph
Works this paper leans on
-
[1]
Andrea Banino, Caswell Barry, Benigno Uria, Charles Blundell, Timothy Lillicrap, Dharshan Kumaran, Eleanor Maguire, and Demis Hassabis. Vector-based navigation using grid-like representations in artificial agents.Nature, 557:429–433, 2018. doi:10.1038/s41586-018-0102-6
-
[2]
Navaneeth Bodla, Bharat Singh, Rama Chellappa, and Larry S. Davis. Soft-NMS – improving object detection with one line of code. InICCV, 2017. doi:10.1109/ICCV.2017.593
-
[3]
Castro, Anton Schwaighofer, Stephanie Hyland, Maria Wetscherek, Tristan Naumann, Aditya Nori, Javier Alvarez-Valle, Hoifung Poon, and Ozan Oktay
Benedikt Boecking, Naoto Usuyama, Shruthi Bannur, Daniel C. Castro, Anton Schwaighofer, Stephanie Hyland, Maria Wetscherek, Tristan Naumann, Aditya Nori, Javier Alvarez-Valle, Hoifung Poon, and Ozan Oktay. MS-CXR: Making the most of text semantics to improve biomed- ical vision–language processing. InComputer Vision – ECCV 2022, LNCS vol. 13696, pages 1–2...
2022
-
[4]
doi:10.1007/978-3-031-20059-5_1
-
[5]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition
Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, and Rohit Girdhar. Masked-attention mask transformer for universal image segmentation. In CVPR, 2022. doi:10.1109/CVPR52688.2022.00135
-
[6]
Ming Dai, Wenxuan Cheng, Jiang-jiang Liu, Sen Y ang, Wenxiao Cai, Y anpeng Sun, and Wankou Y ang. DeRIS: Decoupling perception and cognition for enhanced refer- ring image segmentation through loopback synergy.arXiv preprint arXiv:2507.01738, 2025. arXiv:2507.01738
arXiv 2025
-
[7]
C 3VG: Multi-task visual grounding with coarse-to-fine consistency constraints
Ming Dai, Jian Li, Jiedong Zhuang, Xian Zhang, and Wankou Y ang. C 3VG: Multi-task visual grounding with coarse-to-fine consistency constraints. InProceedings of the AAAI Conference on Artificial Intelligence (AAAI),
-
[8]
arXiv preprint arXiv:2404.00578 (2024)
Fan Bai, Yuxin Du, Tiejun Huang, Max Q.-H. Meng, and Bo Zhao. M3D: Advancing 3D medical image analysis with multi-modal large language models.arXiv preprint arXiv:2404.00578, 2024. doi:10.48550/arXiv.2404.00578
-
[9]
Guang Feng, Zhiwei Hu, Lihe Zhang, and Huchuan Lu. Encoder fusion network with co-attention embed- ding for referring image segmentation. InCVPR, 2021. doi:10.1109/CVPR46437.2021.01525
-
[10]
Selective classifica- tion for deep neural networks
Y onatan Geifman and Ran El-Y aniv. Selective classifica- tion for deep neural networks. InNeurIPS, 2017. NeurIPS Proceedings 2017 (Paper 7073)
2017
-
[11]
SelectiveNet: A deep neural network with an integrated reject option
Y onatan Geifman and Ran El-Y aniv. SelectiveNet: A deep neural network with an integrated reject option. InICML,
-
[12]
Francisco Eiras, Kemal Oksuz, Adel Bibi, Philip H. S. Torr, and Puneet K. Dokania. Segment, select, cor- rect: A framework for weakly-supervised referring seg- mentation.arXiv preprint arXiv:2310.13479, 2023. Ac- 13arXiv:2606.22546 OdaxAI Research cepted to ECCV’24 Workshop (Instance-Level Recogni- tion). doi:10.48550/arXiv.2310.13479
-
[13]
Torkel Hafting, Marianne Fyhn, Sturla Molden, May-Britt Moser, and Edvard I. Moser. Microstructure of a spatial map in the entorhinal cortex.Nature, 436:801–806, 2005. doi:10.1038/nature03721
-
[15]
Learning non-maximum suppression
Jan Hosang, Rodrigo Benenson, and Bernt Schiele. Learning non-maximum suppression. InCVPR, 2017. doi:10.1109/CVPR.2017.701
-
[16]
In: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp
Shaofei Huang, Tianrui Hui, Si Liu, Guanbin Li, Yunchao Wei, Jizhong Han, Luoqi Liu, and Bo Li. Referring image segmentation via cross-modal progressive comprehension. InCVPR, 2020. doi:10.1109/CVPR42600.2020.01050
-
[17]
Zhaojin Huang, Lichao Huang, Y ongchao Gong, Chang Huang, and Xinggang Wang. Mask scoring R-CNN. In CVPR, 2019. doi:10.1109/CVPR.2019.00657
-
[18]
Linguistic structure guided context modeling for referring image segmentation
Tianrui Hui, Si Liu, Shaofei Huang, Guanbin Li, Sansi Yu, Faxi Zhang, and Jizhong Han. Linguistic structure guided context modeling for referring image segmentation. In ECCV, 2020. doi:10.1007/978-3-030-58545-7_4
-
[19]
Borui Jiang, Ruixuan Luo, Jiayuan Mao, Tete Xiao, and Yuning Jiang. Acquisition of localization confidence for ac- curate object detection. InECCV, 2018. doi:10.1007/978- 3-030-01264-9_48
-
[20]
In: IEEE/CVF International Conference on Computer Vision
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C. Berg, Wan-Y en Lo, Piotr Dol- lár, and Ross Girshick. Segment anything. InICCV, 2023. doi:10.1109/ICCV51070.2023.00371
-
[21]
Focal loss for dense object detection
Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Dollár. Focal loss for dense object detection. InICCV,
-
[22]
doi:10.1109/ICCV.2017.324
-
[23]
Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windows. In ICCV, 2021. doi:10.1109/ICCV48922.2021.00986
-
[24]
Multi-scale representation learning for spatial feature distributions using grid cells (Space2Vec)
Gengchen Mai, Krzysztof Janowicz, Bo Y an, Rui Zhu, Ling Cai, and Ni Lao. Multi-scale representation learning for spatial feature distributions using grid cells (Space2Vec). InICLR, 2020. OpenReview ICLR 2020
2020
-
[25]
Generation and comprehension of unambiguous object descriptions
Junhua Mao, Jonathan Huang, Alexander Toshev, Oana Camburu, Alan Yuille, and Kevin Murphy. Generation and comprehension of unambiguous object descriptions. In CVPR, 2016. doi:10.1109/CVPR.2016.329
-
[26]
Edvard I. Moser, Y asser Roudi, Menno P . Witter, Clifford Kentros, Tobias Bonhoeffer, and May-Britt Moser. Grid cells and cortical representation.Nature Reviews Neuro- science, 15(7):466–481, July 2014. doi:10.1038/nrn3766. PMID: 24917300
-
[27]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. InICML, 2021. PMLR vol. 139
2021
-
[28]
Rylan Schaeffer, Mikail Khona, Tzuhsuan Ma, Cristóbal Eyzaguirre, Sanmi Koyejo, and Ila R. Fiete. Self- supervised learning of representations for space gener- ates multi-modular grid cells. InNeurIPS, 2023. NeurIPS Proceedings 2023
2023
-
[29]
Dataset condensation with distribution matching
Wenhui Wang, Hangbo Bao, Li Dong, Johan Bjorck, Zhil- iang Peng, Qiang Liu, Kriti Aggarwal, Owais Khan Mo- hammed, Saksham Singhal, Subhojit Som, and Furu Wei. BEiT-3: Image as a foreign language: BEiT pretraining for vision and vision-language tasks. InCVPR, 2023. doi:10.1109/CVPR56688.2023.01838
-
[30]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition
Zhaoqing Wang, Yu Lu, Qiang Li, Xunqiang Tao, Y andong Guo, Mingming Gong, and Tongliang Liu. CRIS: CLIP- driven referring image segmentation. InCVPR, 2022. doi:10.1109/CVPR52688.2022.02101
-
[31]
OneRef: Unified one-tower ex- pression grounding and segmentation with mask referring modeling
Linhui Xiao, Dunliang Kuang, Siyuan Huang, Shiguang Shan, and Xilin Chen. OneRef: Unified one-tower ex- pression grounding and segmentation with mask referring modeling. InNeurIPS, 2024. NeurIPS Proceedings 2024
2024
-
[32]
Zhao Y ang, Jiaqi Wang, Y ansong Tang, Kai Chen, Heng- shuang Zhao, and Philip H. S. Torr. LAVT: Language- aware vision transformer for referring image segmentation. InCVPR, 2022. doi:10.1109/CVPR52688.2022.01738
-
[33]
Licheng Yu, Patrick Poirson, Shan Y ang, Alexander C. Berg, and Tamara L. Berg. Modeling context in referring expressions. InComputer Vision – ECCV 2016, LNCS vol. 9906, pages 69–84. Springer, 2016. doi:10.1007/978-3- 319-46475-6_5. 14arXiv:2606.22546 OdaxAI Research A Extended Qualitative Results Figure 16:Top-12 failure cases on RefCOCO val. Each cell: ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1007/978-3- 2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.