An Information Theoretic Framework for Graph Novelty Generation via Latent Mixture Modeling
Pith reviewed 2026-06-26 18:21 UTC · model grok-4.3
The pith
A latent-space mixture model with minimum description length conditions generates novel graphs while driving misclassification probabilities to zero at explicit rates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By embedding graphs into a latent space, modeling the latent distribution with finite mixtures, and imposing explicit novelty and reliability conditions formulated via description length, the method generates novel graphs such that, with appropriate threshold choices, the probabilities of misclassifying non-novel or unreliable samples converge to zero with explicit rates.
What carries the argument
Finite mixture modeling of latent graph embeddings together with minimum description length conditions that separately penalize poor component fit (novelty) and large total-model impact (reliability).
If this is right
- Novel graph generation acquires explicit, quantifiable bounds on the risk of including non-novel or structurally disruptive samples.
- The same description-length machinery simultaneously controls distinctness from existing patterns and preservation of global mixture structure.
- The convergence rates supply concrete guidance on how to set thresholds for any given mixture model size.
- The framework applies directly to both synthetic graphs and real-world benchmark collections without requiring task-specific loss functions.
Where Pith is reading between the lines
- The same latent-mixture-plus-MDL construction could be tested on non-graph structured data such as molecules or point clouds if comparable embeddings exist.
- Because the method separates novelty from reliability via two independent length penalties, it offers a tunable knob between exploration of new regions and stability of the learned distribution.
- The explicit rates open the possibility of deriving sample-complexity bounds for related information-theoretic generative tasks.
Load-bearing premise
Embedding graphs into a latent space allows their distribution to be accurately captured by finite mixture models so that description length can enforce both novelty and reliability at once.
What would settle it
A dataset where, even after threshold tuning, the empirical rate at which non-novel samples are accepted does not approach zero as sample size grows.
Figures
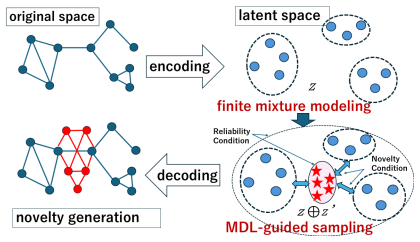
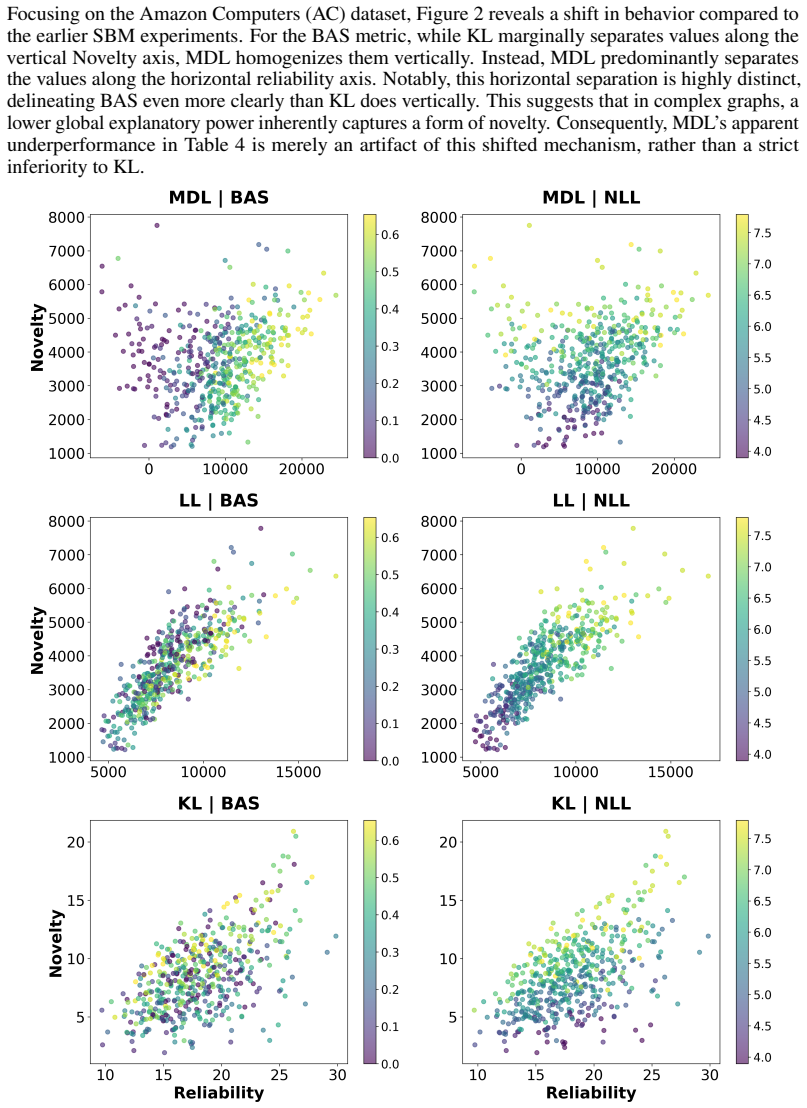
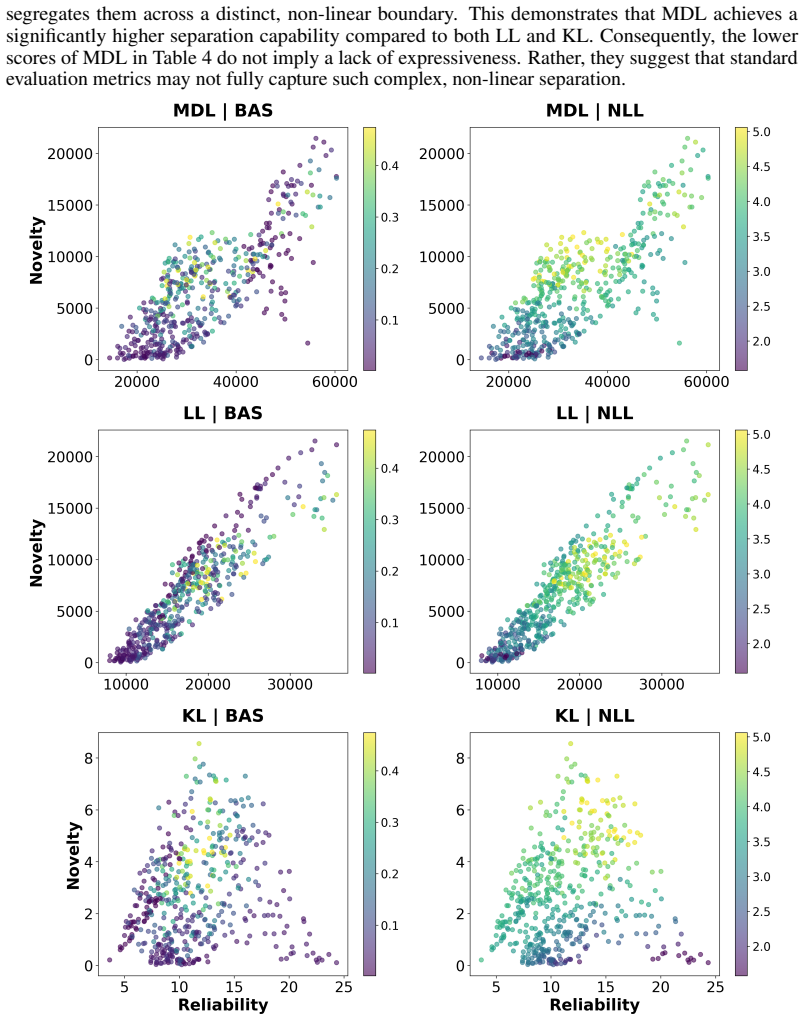
read the original abstract
We propose an information-theoretic framework for graph novelty generation, which aims to generate data that are distinct from existing patterns while preserving global structural consistency. Our approach embeds data into a latent space, models the latent distribution using finite mixture models, and generates novel samples by imposing explicit novelty and reliability conditions formulated in terms of description length. Specifically, novelty is enforced by requiring generated samples to be poorly explained by all existing mixture components, while reliability constrains their impact on the overall mixture structure under the Minimum Description Length (MDL) principle. We provide a theoretical analysis showing that, with appropriate threshold choices, the probabilities of misclassifying non-novel or unreliable samples converge to zero with explicit rates. Experiments on synthetic and benchmark graph datasets demonstrate that the proposed method enables principled novelty generation with quantifiable risk.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes an information-theoretic framework for graph novelty generation. Graphs are embedded into a latent space and modeled via finite mixture models; novelty is enforced by requiring poor fit (high description length) to all existing components, while reliability constrains the generated sample's impact on the overall mixture under the MDL principle. The central theoretical claim is that, with suitable threshold choices, the probabilities of misclassifying non-novel or unreliable samples converge to zero at explicit rates. Experiments on synthetic and benchmark graph datasets are reported to illustrate the approach.
Significance. If the convergence rates are rigorously established, the work supplies a quantifiable, MDL-based criterion for novelty generation that simultaneously addresses distinctness and structural consistency—an advance over purely heuristic graph generators. The explicit rates constitute a strength when the modeling assumptions hold.
major comments (2)
- [§3, main convergence theorem] §3 (Theoretical Analysis), main convergence theorem: the explicit rates are derived under the assumption that the latent distribution is exactly captured by a finite mixture whose component-wise description lengths serve as faithful proxies for both novelty and reliability. For graph embeddings, which routinely exhibit heavy tails, discrete topology changes, and size-dependent statistics, this finite-mixture approximation leaves residual mass that directly perturbs the thresholds and can void the claimed rates. This assumption is load-bearing for the central claim.
- [Theoretical section, threshold definitions] Definition of novelty/reliability thresholds (Eqs. (X)–(Y) in the theoretical section): both thresholds are free parameters whose selection re-uses quantities from the fitted mixture. The manuscript does not demonstrate that these thresholds can be set independently of the fit or provide a data-driven procedure that avoids circular dependence between the generation criterion and the model quantities used to evaluate it.
minor comments (2)
- [Experiments] Experiments section: report the number of mixture components selected, the embedding method (e.g., specific GNN architecture), and the precise description-length estimator used; these details are needed to assess reproducibility.
- [Notation throughout] Notation: ensure the symbol for description length is defined once and used consistently; several passages employ both DL(·) and I(·) without explicit cross-reference.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major comment below, clarifying the scope of our theoretical results and proposing revisions to improve the presentation.
read point-by-point responses
-
Referee: [§3, main convergence theorem] §3 (Theoretical Analysis), main convergence theorem: the explicit rates are derived under the assumption that the latent distribution is exactly captured by a finite mixture whose component-wise description lengths serve as faithful proxies for both novelty and reliability. For graph embeddings, which routinely exhibit heavy tails, discrete topology changes, and size-dependent statistics, this finite-mixture approximation leaves residual mass that directly perturbs the thresholds and can void the claimed rates. This assumption is load-bearing for the central claim.
Authors: The convergence rates in the main theorem of §3 are derived under the modeling assumption that the latent distribution is exactly represented by the finite mixture; this is explicitly stated as the setting in which the probabilities of misclassification converge at the given rates. The MDL-based novelty and reliability criteria remain well-defined even when the approximation is imperfect, though the explicit rates would then serve as a reference rather than a strict guarantee. We will revise §3 to add a dedicated remark on this assumption, its implications for graph embeddings with heavy tails or discrete changes, and a brief discussion of how residual mass affects threshold stability in practice. revision: partial
-
Referee: [Theoretical section, threshold definitions] Definition of novelty/reliability thresholds (Eqs. (X)–(Y) in the theoretical section): both thresholds are free parameters whose selection re-uses quantities from the fitted mixture. The manuscript does not demonstrate that these thresholds can be set independently of the fit or provide a data-driven procedure that avoids circular dependence between the generation criterion and the model quantities used to evaluate it.
Authors: The thresholds are computed from the fitted mixture via the MDL principle applied to the observed data; once the model is fixed, the criterion for a new candidate sample evaluates its description length against this fixed model and is therefore not circular for the generation step itself. Nevertheless, to strengthen the presentation we will add an explicit data-driven procedure (e.g., bootstrap resampling of the training embeddings to select thresholds that control empirical misclassification rates on held-out validation samples) and will include pseudocode for this selection in the revised theoretical section. revision: yes
Circularity Check
No significant circularity; derivation uses MDL definitions to derive independent convergence rates
full rationale
The paper defines novelty via poor fit to existing mixture components and reliability via bounded MDL impact on the overall structure, then derives explicit convergence rates for misclassification probabilities under chosen thresholds. This is a standard theoretical step from the stated assumptions to the rates and does not reduce any claimed prediction to the inputs by construction, nor rely on self-citation chains or fitted parameters renamed as predictions. The latent mixture modeling is an explicit modeling choice whose validity is separate from the rate derivation itself.
Axiom & Free-Parameter Ledger
free parameters (2)
- novelty threshold
- reliability threshold
axioms (2)
- domain assumption Finite mixture models suffice to represent the latent distribution of embedded graphs
- domain assumption Minimum Description Length principle can be used to quantify reliability of new samples
Reference graph
Works this paper leans on
-
[1]
Computation of modified Bessel functions and their ratios.Mathematics of Computa- tion, 28(125):239–251, 1974
Amos, D. Computation of modified Bessel functions and their ratios.Mathematics of Computa- tion, 28(125):239–251, 1974
1974
-
[2]
Towards data augmentation in graph neural network: An overview and evaluation.Computer Science Review, 47:100527, 2023
Adjeisah, M., Zhu, X., Xu, H., and Ayal, T. Towards data augmentation in graph neural network: An overview and evaluation.Computer Science Review, 47:100527, 2023
2023
-
[3]
A theory of independent mechanisms for extrapolation in generative models
Besserve, M., Sun, R., Janzing, D., and Schölkopf, B. A theory of independent mechanisms for extrapolation in generative models. InProceedings of AAAI, pp. 6761–6749, 2021
2021
-
[4]
Learning community embedding with community detection and node embedding on graphs
Cavallari, S., Zheng, V ., Cai, H., Chang, K., and Cambria, E. Learning community embedding with community detection and node embedding on graphs. InProceedings of CIKM, pp. 377– 386, 2017
2017
-
[5]
Deep extrapolation for attribute-enhanced generation
Chan, A., Madani, A., Krause, B., and Naik, N. Deep extrapolation for attribute-enhanced generation. InProceedings of NeurIPS, 2021
2021
-
[6]
and Yeung, D
Cheung, T. and Yeung, D. MODALS: Modality-agnostic automated data augmentation in the latent space. InProceedings of ICLR, 2021
2021
-
[7]
and Nichol, A
Dhariwal, P. and Nichol, A. Diffusion models beat GANs on image synthesis. InProceedings of NeurIPS, pp. 8780–8794, 2021
2021
-
[8]
Data augmentation for deep graph learning: A survey
Ding, K., Xu, Z., Tong, H., and Liu, H. Data augmentation for deep graph learning: A survey. ACM SIGKDD Explorations Newsletter, 24:61–77, 2022
2022
-
[9]
Principled knowledge extrapolation with GANs
Feng, R., Xiao, J., Zheng, K., Zhao, D., Zhou, J., Sun, Q., and Zha, Z. Principled knowledge extrapolation with GANs. InProceedings of ICML, pp. 6447–6464, 2022
2022
-
[10]
and Yamanishi, K
Fukushima, S. and Yamanishi, K. Graph community augmentation with GMM-based modeling in latent space. InProceedings of ICDM, pp. 111–120, 2024
2024
-
[11]
DINO as a von Mises-Fisher mixture model
Govindarajan, H., Sidén, P., Rol, J., and Lindsten, F. DINO as a von Mises-Fisher mixture model. InProceedings of ICLR, 2023
2023
-
[12]
MIT Press, 2007
Grünwald, P.The Minimum Description Length Principle. MIT Press, 2007
2007
-
[13]
X., Niu, D., Chen, H., Lai, K., He, Y ., and Xu, Y
Han, F. X., Niu, D., Chen, H., Lai, K., He, Y ., and Xu, Y . A deep generative approach to search extrapolation and recommendation. InProceedings of KDD, pp. 1771–1779, 2019
2019
-
[14]
Hendrycks, D. and Gimpel, K. A baseline for detecting misclassified and out-of-distribution examples in neural networks.arXiv preprint arXiv:1610.02136, 2016
Pith/arXiv arXiv 2016
-
[15]
and Yamanishi, K
Hirai, S. and Yamanishi, K. Correction to efficient computation of normalized maximum likeli- hood codes for Gaussian mixture models with its applications to clustering.IEEE Transactions on Information Theory, 65(10):6827–6828, 2019
2019
-
[16]
Denoising diffusion probabilistic models
Ho, J., Jain, A., and Abbeel, P. Denoising diffusion probabilistic models. InProceedings of NeurIPS, pp. 6840–6851, 2020
2020
-
[17]
GraphGDP: Generative diffusion processes for permutation invariant graph generation
Huang, H., Sun, L., Du, B., Fu, Y ., and Lv, W. GraphGDP: Generative diffusion processes for permutation invariant graph generation. InProceedings of ICDM, pp. 201–210, 2022
2022
-
[18]
Collaborative graph convolutional networks: Unsupervised learning meets semi-supervised learning
Hui, B., Zhu, P., and Hu, Q. Collaborative graph convolutional networks: Unsupervised learning meets semi-supervised learning. InProceedings of AAAI, pp. 4215–4222, 2020
2020
-
[19]
Khodadadeh, S., Zehtabian, S., Vahidian, S., and Wang, W. Unsupervised meta-learning through latent-space interpolation in generative models.arXiv preprint arXiv:2006.10236, 2020. 10
arXiv 2006
-
[20]
and Myllymäki, P
Kontkanen, P. and Myllymäki, P. A linear-time algorithm for computing the multinomial stochastic complexity.Information Processing Letters, 103(6):227–233, 2007
2007
-
[21]
A simple unified framework for detecting out-of- distribution samples and adversarial attacks
Lee, K., Lee, K., Lee, H., and Shin, J. A simple unified framework for detecting out-of- distribution samples and adversarial attacks. InProceedings of NeurIPS, 2018
2018
-
[22]
GMMDA: Gaussian mixture modeling of graph in latent space for graph data augmentation.Knowledge and Information Systems, 66(12):7667–7695, 2024
Li, Y ., Xu, L., and Yamanishi, K. GMMDA: Gaussian mixture modeling of graph in latent space for graph data augmentation.Knowledge and Information Systems, 66(12):7667–7695, 2024
2024
-
[23]
Local augmentation for graph neural networks
Liu, S., Ying, R., Dong, H., Li, L., Xu, T., Rong, Y ., Zhao, P., Huang, J., and Wu, D. Local augmentation for graph neural networks. InProceedings of ICML, 2022
2022
-
[24]
Data augmentation via latent space interpolation for image classification
Liu, X., Zou, Y ., Kong, L., Diao, Z., Yan, J., Wang, J., Li, S., Jia, P., and You, J. Data augmentation via latent space interpolation for image classification. InProceedings of ICLR, 2018
2018
-
[25]
Oxford University Press, 2018
Newman, M.Networks. Oxford University Press, 2018
2018
-
[26]
Neal, R. M. and Hinton, G. E. A view of the EM algorithm that justifies incremental, sparse, and other variants. InLearning in Graphical Models, pp. 355–368. Springer, 1998
1998
-
[27]
Everything is there in latent space: Attribute editing and attribute style manipulation by StyleGAN latent space exploration
Parihar, R., Dhiman, A., Karmali, T., and Babu, R. Everything is there in latent space: Attribute editing and attribute style manipulation by StyleGAN latent space exploration. InProceedings of ACM Multimedia, 2022
2022
-
[28]
Efficient out-of- distribution detection using latent space of β-V AE for cyber-physical systems.ACM Transac- tions on Cyber-Physical Systems, 6(15):1–3, 2022
Ramakrishna, S., Rahiminasab, Z., Karsai, G., Easwaran, A., and Dubey, A. Efficient out-of- distribution detection using latent space of β-V AE for cyber-physical systems.ACM Transac- tions on Cyber-Physical Systems, 6(15):1–3, 2022
2022
-
[29]
Modeling by shortest data description.Automatica, 14(5):465–471, 1978
Rissanen, J. Modeling by shortest data description.Automatica, 14(5):465–471, 1978
1978
-
[30]
Cambridge University Press, 2020
Rissanen, J.Optimal Estimation of Parameters. Cambridge University Press, 2020
2020
-
[31]
Pitfalls of graph neural network evaluation.arXiv preprint arXiv:1811.05868, 2018
Shchur, O., Mumme, M., Bojchevski, A., and Günnemann, S. Pitfalls of graph neural network evaluation.arXiv preprint arXiv:1811.05868, 2018
Pith/arXiv arXiv 2018
-
[32]
Snijders, T. A. B. Estimation and prediction for stochastic blockmodels for graphs with latent block structure.Journal of Classification, 14:75–100, 1997
1997
-
[33]
LatentAugment: Data augmentation via guided manipulation of GAN’s latent space.IEEE Transactions on Pattern Analysis and Machine Intelligence, 47(12):11519–11533, 2025
Tronchin, L., Vu, M., Soda, P., and Löfstedt, T. LatentAugment: Data augmentation via guided manipulation of GAN’s latent space.IEEE Transactions on Pattern Analysis and Machine Intelligence, 47(12):11519–11533, 2025
2025
-
[34]
and Figueiredo, A
Veale, T. and Figueiredo, A. C. (eds.).Computational Creativity. Springer, 2019
2019
-
[35]
DiGress: Discrete denoising diffusion for graph generation
Vignac, C., Krawczuk, I., Siraudin, A., Wang, B., Cevher, V ., and Frossard, P. DiGress: Discrete denoising diffusion for graph generation. InProceedings of ICLR, 2023
2023
-
[36]
Springer, 2023
Yamanishi, K.Learning with the Minimum Description Length Principle. Springer, 2023
2023
-
[37]
The decomposed normalized maximum likelihood code-length criterion for selecting hierarchical latent variable models.Data Mining and Knowledge Discovery, 33(4):1017–1058, 2019
Yamanishi, K., Wu, T., Sugawara, S., and Okada, M. The decomposed normalized maximum likelihood code-length criterion for selecting hierarchical latent variable models.Data Mining and Knowledge Discovery, 33(4):1017–1058, 2019
2019
-
[38]
M., Li, J., and Fang, J
Yang, L., Cheung, N. M., Li, J., and Fang, J. Deep clustering by Gaussian mixture variational autoencoders with graph embedding. InProceedings of ICCV, pp. 6440–6449, 2019
2019
-
[39]
When interpretability meets generalization: Delta-GAM for robust extrapolation in out-of-distribution settings
Yang, L., Wang, W., Chen, Q., Zeng, Z., and Sun, L. When interpretability meets generalization: Delta-GAM for robust extrapolation in out-of-distribution settings. InProceedings of KDD, pp. 3507–3517, 2025
2025
-
[40]
Graph augmentation learning
Yu, S., Huang, H., Dao, M., and Xia, F. Graph augmentation learning. InProceedings of The Web Conference, pp. 1063–1072, 2022. 11
2022
-
[41]
Graph data augmentation for graph machine learning: A survey.arXiv preprint arXiv:2202.08871, 2022
Zhao, T., Jin, W., Liu, Y ., Wang, Y ., Liu, G., Günnemann, S., Shah, N., and Jiang, M. Graph data augmentation for graph machine learning: A survey.arXiv preprint arXiv:2202.08871, 2022
arXiv 2022
-
[42]
Data augmentation for graph neural networks
Zhao, T., Liu, Y ., Neves, L., Woodford, O., Jiang, M., and Shah, N. Data augmentation for graph neural networks. InProceedings of AAAI, pp. 11015–11023, 2021
2021
-
[43]
Data augmentation on graphs: A survey
Zhou, J., Xie, C., Wen, Z., Zhao, X., and Xuan, Q. Data augmentation on graphs: A survey. arXiv preprint arXiv:2212.09970, 2022. 12 A Proof of Proposition 4.1 Proof. According to [30, 12, 36], the parametric complexity can be approximated as follows: Letting dbe the number of parameters andθbe a real-valued parameter vector, for sufficiently largen, Cn = ...
arXiv 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.