CodeChat-Eval: Evaluating Large Language Models in Multi-Turn Code Refinement Dialogues
Pith reviewed 2026-06-25 20:20 UTC · model grok-4.3
The pith
Large language models lose substantial functional correctness when refining code across multiple dialogue turns.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
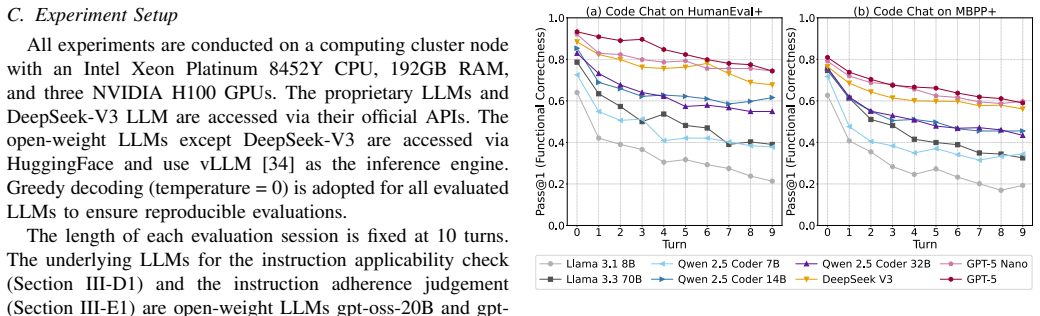
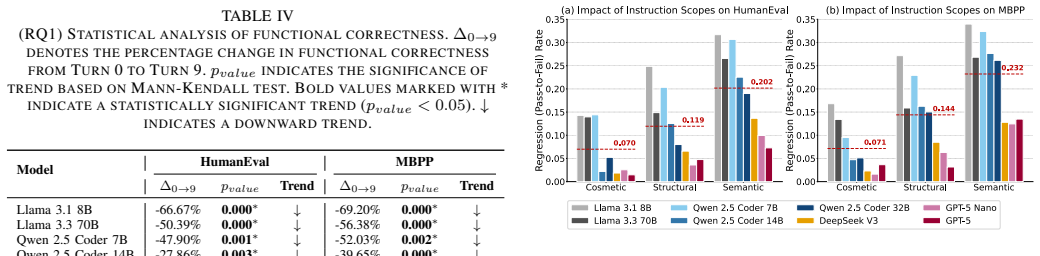
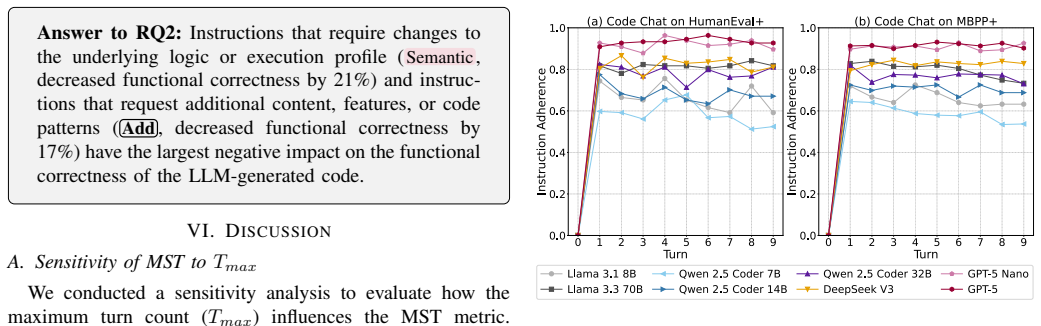
CodeChat-Eval constructs evaluation sessions from multi-turn code refinement dialogues using a dynamic instruction selection algorithm; empirical results on open-weight and proprietary LLMs show statistically significant decreases in functional correctness from 19.2 percent for GPT-5 Nano to 69.2 percent for Llama 3.1 8B, with the largest drops tied to logic-level refinements and additive change requests.
What carries the argument
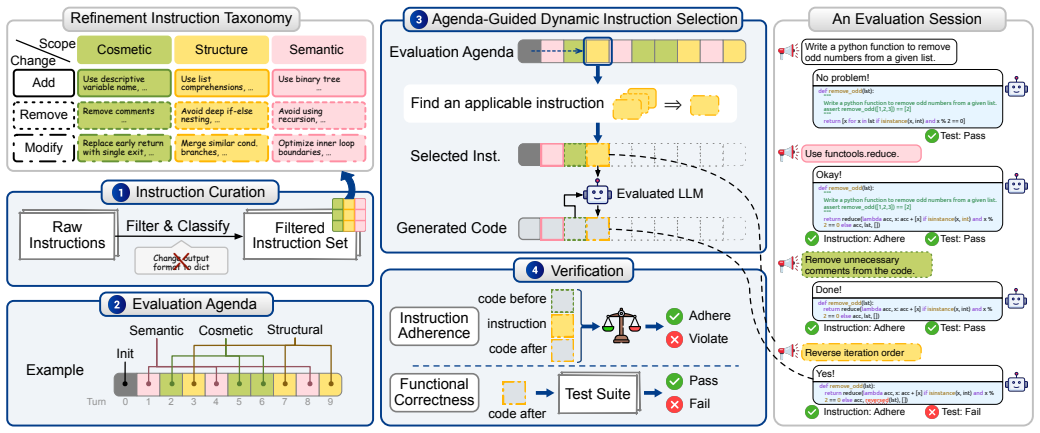
Dynamic instruction selection algorithm that generates multi-turn refinement dialogues from base tasks while retaining the original task test suites to detect losses in functional correctness.
If this is right
- Evaluation of code-generating LLMs must incorporate multi-turn refinement rather than single-turn generation to reflect actual usage.
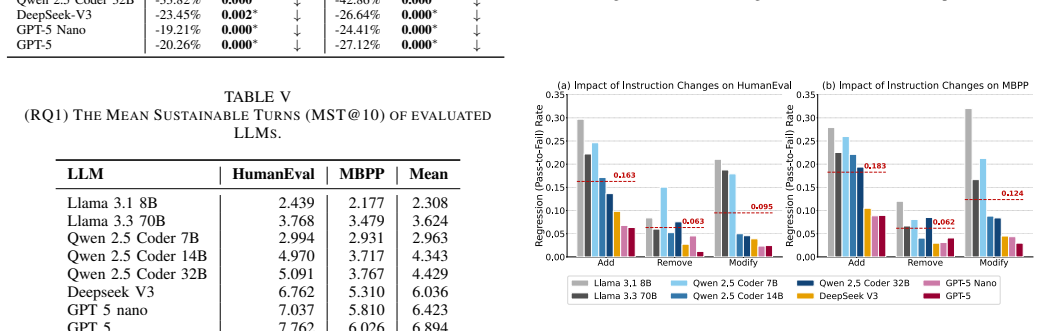
- Logic-level refinements and additive change requests require targeted improvements because they produce the largest losses in correctness.
- Both proprietary and open-weight models exhibit the problem, indicating it is not solved by scale or proprietary training alone.
- New benchmarks are needed that test functionality-preserving refinement beyond initial code generation.
Where Pith is reading between the lines
- Development teams may need to add verification steps after each refinement turn instead of accepting model output at face value.
- Training regimes could incorporate synthetic multi-turn refinement examples to reduce the observed correctness erosion.
- The same dialogue-construction method could be applied to evaluate iterative tasks outside code, such as multi-turn debugging or specification refinement.
Load-bearing premise
The dialogues produced by the dynamic instruction selection algorithm match the distribution and difficulty of real developer interactions, and the original test suites remain sufficient to detect any loss of intended behavior after refinements.
What would settle it
Measuring the same models on a collection of logged, real-world multi-turn refinement sessions from open-source projects and checking whether the correctness drops match those observed in the constructed dialogues.
Figures


read the original abstract
Large Language Models (LLMs) are increasingly used in software engineering to generate and refine code. In practice, developers often continue from an initial code generation request with follow-up refinement instructions, such as requests to improve style, restructure implementation, or change the execution strategy while preserving the intended behaviour. However, existing benchmarks generally omit this multi-turn code refinement dialogue setting and therefore cannot evaluate whether LLMs maintain functional correctness, i.e., whether the refined code still passes the test suite for the original task. To address this limitation, we introduce CodeChat-Eval, an evaluation framework that constructs evaluation sessions from multi-turn code refinement dialogues using a dynamic instruction selection algorithm. Our empirical study on open-weight and proprietary LLMs observes a statistically significant decrease ranging from 19.2% (GPT-5 Nano) to 69.2% (Llama 3.1 8B) in functional correctness over multi-turn refinement. The largest correctness drops are associated with logic-level refinements and additive change requests. These findings indicate that LLMs struggle to maintain functional correctness during multi-turn code refinement dialogues, and highlight the need for benchmarks that evaluate functionality-preserving refinement beyond single-turn generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CodeChat-Eval, a framework that uses a dynamic instruction selection algorithm to generate multi-turn code refinement dialogues from initial tasks. It evaluates open-weight and proprietary LLMs and reports statistically significant drops in functional correctness (19.2% for GPT-5 Nano to 69.2% for Llama 3.1 8B) over refinement turns, with the largest drops linked to logic-level refinements and additive change requests. The central claim is that existing single-turn benchmarks miss this setting and that LLMs struggle to maintain correctness in multi-turn refinement.
Significance. If the synthetic dialogues produced by the dynamic instruction selection algorithm match the distribution, specificity, and difficulty of real developer refinement sessions, the results would demonstrate a practically important limitation of current LLMs for iterative software engineering workflows and would motivate the development of functionality-preserving refinement techniques and more realistic benchmarks.
major comments (3)
- [Methods / dynamic instruction selection algorithm] The headline result (statistically significant correctness drops of 19.2–69.2 %) rests on the assumption that the dynamic instruction selection algorithm produces refinement dialogues whose distribution and difficulty match real developer interactions. No human validation study, comparison to logged developer sessions, or distributional statistics on request frequencies/specificity are described, making it impossible to rule out that the measured degradation is an artifact of over-sampling logic-level or additive changes.
- [Evaluation setup / test suites] The abstract states that the original task test suites remain sufficient to detect loss of intended behavior after refinements, but provides no details on test-suite construction, coverage, or controls for prompt length. This is load-bearing for interpreting the reported drops as genuine losses of functional correctness rather than artifacts of incomplete oracles.
- [Results / category analysis] The paper associates the largest drops with logic-level refinements and additive requests, yet the abstract and available description give no breakdown of how refinement categories were labeled, inter-annotator agreement, or controls for confounding factors such as dialogue length or model-specific prompt sensitivity.
minor comments (1)
- [Abstract] The abstract mentions 'statistically significant' drops but does not name the statistical test, correction for multiple comparisons, or effect-size reporting; these details should be added for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which identify key areas where additional detail and validation would strengthen the manuscript. We respond to each major comment below and will revise the paper accordingly.
read point-by-point responses
-
Referee: [Methods / dynamic instruction selection algorithm] The headline result (statistically significant correctness drops of 19.2–69.2 %) rests on the assumption that the dynamic instruction selection algorithm produces refinement dialogues whose distribution and difficulty match real developer interactions. No human validation study, comparison to logged developer sessions, or distributional statistics on request frequencies/specificity are described, making it impossible to rule out that the measured degradation is an artifact of over-sampling logic-level or additive changes.
Authors: We agree that explicit validation against real developer distributions would increase confidence in the results. Section 3.2 describes the dynamic instruction selection algorithm, which samples from a curated instruction pool to ensure coverage of refinement types while avoiding repetition. We did not perform a human validation study or direct comparison to logged sessions. In revision we will add distributional statistics on the generated dialogues (e.g., frequency of logic-level vs. style changes), a limitations subsection discussing fidelity to real workflows, and, if feasible within the revision timeline, a small-scale human annotation study to assess perceived realism. revision: yes
-
Referee: [Evaluation setup / test suites] The abstract states that the original task test suites remain sufficient to detect loss of intended behavior after refinements, but provides no details on test-suite construction, coverage, or controls for prompt length. This is load-bearing for interpreting the reported drops as genuine losses of functional correctness rather than artifacts of incomplete oracles.
Authors: The test suites are taken directly from the source benchmarks (HumanEval, MBPP, and APPS) and were not modified. We will revise the evaluation-setup section to report test-suite sizes, statement and branch coverage where available from the original datasets, and any length-normalization steps applied to prompts. This will make explicit that the oracles remain unchanged and that observed drops are measured against the same functional requirements. revision: yes
-
Referee: [Results / category analysis] The paper associates the largest drops with logic-level refinements and additive requests, yet the abstract and available description give no breakdown of how refinement categories were labeled, inter-annotator agreement, or controls for confounding factors such as dialogue length or model-specific prompt sensitivity.
Authors: Category labels were assigned by mapping each selected instruction to one of four predefined change types (logic, additive, style, structural) according to the instruction taxonomy in Section 3.1. We will expand the results section with the exact labeling rules, report inter-annotator agreement if a second annotator was used, and add regression controls for dialogue length and model to isolate the effect of category. These additions will support the claim that logic-level and additive refinements drive the largest drops. revision: yes
Circularity Check
No significant circularity; empirical measurement on constructed benchmark
full rationale
The paper's central claim is an observed drop in functional correctness (19.2–69.2%) measured by executing refined code against original test suites. This is a direct empirical result from running LLMs on dialogues generated by the described algorithm; it does not reduce to a fitted parameter, self-definition, or self-citation chain. The dynamic instruction selection algorithm is presented as a construction method rather than a derived prediction, and no equations or uniqueness theorems are invoked. Validity concerns about realism of the synthetic dialogues are external to circularity analysis.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Llm-based code generation: A systematic literature review with technical and demographic insights,
K. U. Danyaro, M. Nasser, A. Zakari, S. Abdullahi, A. Khanzada, M. M. Yakubu, S. Shoaibet al., “Llm-based code generation: A systematic literature review with technical and demographic insights,”IEEE Access, vol. 13, pp. 194 915–194 939, 2025
2025
-
[2]
Developer-llm conversations: An empirical study of interactions and generated code quality,
S. Zhong, Y . Zou, and B. Adams, “Developer-llm conversations: An empirical study of interactions and generated code quality,”arXiv preprint arXiv:2509.10402, 2025
arXiv 2025
-
[3]
An empirical study on the potential of llms in automated software refactoring,
B. Liu, Y . Jiang, Y . Zhang, N. Niu, G. Li, and H. Liu, “An empirical study on the potential of llms in automated software refactoring,”arXiv preprint arXiv:2411.04444, 2024
arXiv 2024
-
[4]
Devgpt: Studying developer-chatgpt conversations,
T. Xiao, C. Treude, H. Hata, and K. Matsumoto, “Devgpt: Studying developer-chatgpt conversations,” inProceedings of the 21st interna- tional conference on mining software repositories, 2024, pp. 227–230
2024
-
[5]
The impact of llm-assistants on software developer productivity: A systematic literature review,
A. Mohamed, M. Assi, and M. Guizani, “The impact of llm-assistants on software developer productivity: A systematic literature review,”arXiv preprint arXiv:2507.03156, 2025
arXiv 2025
-
[6]
Program synthesis with large language models,
J. Austin, A. Odena, M. Nye, M. Bosma, H. Michalewski, D. Dohan, E. Jiang, C. Cai, M. Terry, Q. Leet al., “Program synthesis with large language models,”arXiv preprint arXiv:2108.07732, 2021
Pith/arXiv arXiv 2021
-
[7]
Evaluating large language models trained on code,
M. Chen, “Evaluating large language models trained on code,”arXiv preprint arXiv:2107.03374, 2021
Pith/arXiv arXiv 2021
-
[8]
SWE-bench: Can language models resolve real-world github issues?
C. E. Jimenez, J. Yang, A. Wettig, S. Yao, K. Pei, O. Press, and K. R. Narasimhan, “SWE-bench: Can language models resolve real-world github issues?” inThe Twelfth International Conference on Learning Representations, 2024. [Online]. Available: https: //openreview.net/forum?id=VTF8yNQM66
2024
-
[9]
Bigcodebench: Benchmarking code generation with diverse function calls and complex instructions,
T. Y . Zhuo, M. C. Vu, J. Chim, H. Hu, W. Yu, R. Widyasari, I. N. B. Yusuf, H. Zhan, J. He, I. Paulet al., “Bigcodebench: Benchmarking code generation with diverse function calls and complex instructions,” inInternational Conference on Learning Representations, 2025
2025
-
[10]
Codealignbench: Assessing code generation models on developer-preferred code adjust- ments,
F. Mehralian, R. Shar, J. R. Rae, and A. Hashemi, “Codealignbench: Assessing code generation models on developer-preferred code adjust- ments,”arXiv preprint arXiv:2510.27565, 2025
arXiv 2025
-
[11]
Claude code,
Anthropic, “Claude code,” https://docs.anthropic.com/en/docs/agent s-and-tools/claude-code/overview, 2025, agentic coding tool for the command line. Accessed: 2026-03-06
2025
-
[12]
Github copilot,
GitHub, “Github copilot,” https://github.com/features/copilot, 2024, aI coding assistant. Accessed: 2024-01-28
2024
-
[13]
Mint: Evaluating llms in multi-turn interaction with tools and language feedback,
X. Wang, Z. Wang, J. Liu, Y . Chen, L. Yuan, H. Peng, and H. Ji, “Mint: Evaluating llms in multi-turn interaction with tools and language feedback,” inThe Twelfth International Conference on Learning Repre- sentations, 2024
2024
-
[14]
CodeIF: Benchmarking the instruction-following capabilities of large language models for code generation,
K. Yan, H. Guo, X. Shi, S. Cao, D. Di, and Z. Li, “CodeIF: Benchmarking the instruction-following capabilities of large language models for code generation,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 6: Industry Track), G. Rehm and Y . Li, Eds. Vienna, Austria: Association for Computational Linguisti...
2025
-
[15]
P. Wang, L. Zhang, F. Liu, L. Shi, M. Li, B. Shen, and A. Fu, “Codeif- bench: Evaluating instruction-following capabilities of large language models in interactive code generation,”arXiv preprint arXiv:2503.22688, 2025
arXiv 2025
-
[16]
G. Duan, M. Liu, Y . Wang, C. Wang, X. Peng, and Z. Zheng, “A hierarchical and evolvable benchmark for fine-grained code instruction following with multi-turn feedback,”arXiv preprint arXiv:2507.00699, 2025
arXiv 2025
-
[17]
Convcodeworld: Benchmarking conversational code generation in reproducible feedback environments,
H. Han, S.-w. Hwang, R. Samdani, and Y . He, “Convcodeworld: Benchmarking conversational code generation in reproducible feedback environments,”arXiv preprint arXiv:2502.19852, 2025
arXiv 2025
-
[18]
Instruction-following evaluation for large language models,
J. Zhou, T. Lu, S. Mishra, S. Brahma, S. Basu, Y . Luan, D. Zhou, and L. Hou, “Instruction-following evaluation for large language models,” arXiv preprint arXiv:2311.07911, 2023
Pith/arXiv arXiv 2023
-
[19]
Is your code generated by chatgpt really correct? rigorous evaluation of large language models for code generation,
J. Liu, C. S. Xia, Y . Wang, and L. Zhang, “Is your code generated by chatgpt really correct? rigorous evaluation of large language models for code generation,”Advances in Neural Information Processing Systems, vol. 36, pp. 21 558–21 572, 2023
2023
-
[20]
Llms get lost in multi- turn conversation,
P. Laban, H. Hayashi, Y . Zhou, and J. Neville, “Llms get lost in multi- turn conversation,”arXiv preprint arXiv:2505.06120, 2025
Pith/arXiv arXiv 2025
-
[21]
Chain-of-thought prompting elicits reasoning in large language models,
J. Wei, X. Wang, D. Schuurmans, M. Bosma, F. Xia, E. Chi, Q. V . Le, D. Zhouet al., “Chain-of-thought prompting elicits reasoning in large language models,”Advances in neural information processing systems, vol. 35, pp. 24 824–24 837, 2022
2022
-
[22]
Language mod- els are few-shot learners,
T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askellet al., “Language mod- els are few-shot learners,”Advances in neural information processing systems, vol. 33, pp. 1877–1901, 2020
1901
-
[23]
Nonparametric tests against trend,
H. B. Mann, “Nonparametric tests against trend,”Econometrica: Journal of the econometric society, pp. 245–259, 1945
1945
-
[24]
M. G. Kendall,Rank correlation methods.Griffin, 1948
1948
-
[25]
Are we speeding up or slowing down? on temporal aspects of code velocity,
G. Kudrjavets, N. Nagappan, and A. Rastogi, “Are we speeding up or slowing down? on temporal aspects of code velocity,” in2023 IEEE/ACM 20th International Conference on Mining Software Reposi- tories (MSR). IEEE, 2023, pp. 267–271
2023
-
[26]
Wohlin, P
C. Wohlin, P. Runeson, M. H ¨ost, M. C. Ohlsson, B. Regnell, A. Wessl´en et al.,Experimentation in software engineering. Springer, 2012, vol. 236
2012
-
[27]
Restricted mean survival time: an alterna- tive to the hazard ratio for the design and analysis of randomized trials with a time-to-event outcome,
P. Royston and M. K. Parmar, “Restricted mean survival time: an alterna- tive to the hazard ratio for the design and analysis of randomized trials with a time-to-event outcome,”BMC medical research methodology, vol. 13, no. 1, p. 152, 2013
2013
-
[28]
A theory of software reliability and its application,
J. D. Musa, “A theory of software reliability and its application,”IEEE transactions on software engineering, vol. 1, no. 03, pp. 312–327, 1975
1975
-
[29]
P. D. O’connor and A. V . Kleyner,Practical reliability engineering. john wiley & sons, 2025
2025
-
[30]
A. Grattafiori, A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Vaughanet al., “The llama 3 herd of models,”arXiv preprint arXiv:2407.21783, 2024
Pith/arXiv arXiv 2024
-
[31]
Qwen2. 5-coder technical report,
B. Hui, J. Yang, Z. Cui, J. Yang, D. Liu, L. Zhang, T. Liu, J. Zhang, B. Yu, K. Luet al., “Qwen2. 5-coder technical report,”arXiv preprint arXiv:2409.12186, 2024
Pith/arXiv arXiv 2024
-
[32]
A. Liu, B. Feng, B. Xue, B. Wang, B. Wu, C. Lu, C. Zhao, C. Deng, C. Zhang, C. Ruanet al., “Deepseek-v3 technical report,”arXiv preprint arXiv:2412.19437, 2024
Pith/arXiv arXiv 2024
-
[33]
Introducing gpt-5,
OpenAI, “Introducing gpt-5,” https://openai.com/index/introducing-gpt -5, 2025
2025
-
[34]
Efficient memory management for large language model serving with pagedattention,
W. Kwon, Z. Li, S. Zhuang, Y . Sheng, L. Zheng, C. H. Yu, J. Gonzalez, H. Zhang, and I. Stoica, “Efficient memory management for large language model serving with pagedattention,” inProceedings of the 29th symposium on operating systems principles, 2023, pp. 611–626
2023
-
[35]
gpt-oss-120b & gpt-oss-20b model card,
S. Agarwal, L. Ahmad, J. Ai, S. Altman, A. Applebaum, E. Arbus, R. K. Arora, Y . Bai, B. Baker, H. Baoet al., “gpt-oss-120b & gpt-oss-20b model card,”arXiv preprint arXiv:2508.10925, 2025
Pith/arXiv arXiv 2025
-
[36]
J. L. Fleiss, B. Levin, and M. C. Paik,Statistical methods for rates and proportions. john wiley & sons, 2013
2013
-
[37]
Cohen,Statistical power analysis for the behavioral sciences
J. Cohen,Statistical power analysis for the behavioral sciences. rout- ledge, 2013
2013
-
[38]
Mortar: Multi-turn metamorphic testing for llm-based dialogue systems,
G. A. Guo, A. Aleti, N. Neelofar, C. Tantithamthavorn, Y . Qi, and T. Y . Chen, “Mortar: Multi-turn metamorphic testing for llm-based dialogue systems,”IEEE Transactions on Software Engineering, pp. 1–18, 2026
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.