Cross-Modal Masking for Robust Silent Speech Synthesis Using sEMG and Lipreading
Pith reviewed 2026-06-27 14:52 UTC · model grok-4.3
The pith
Cross-modal masking during training lets sEMG and lipreading signals combine for robust silent speech synthesis even under modality loss.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
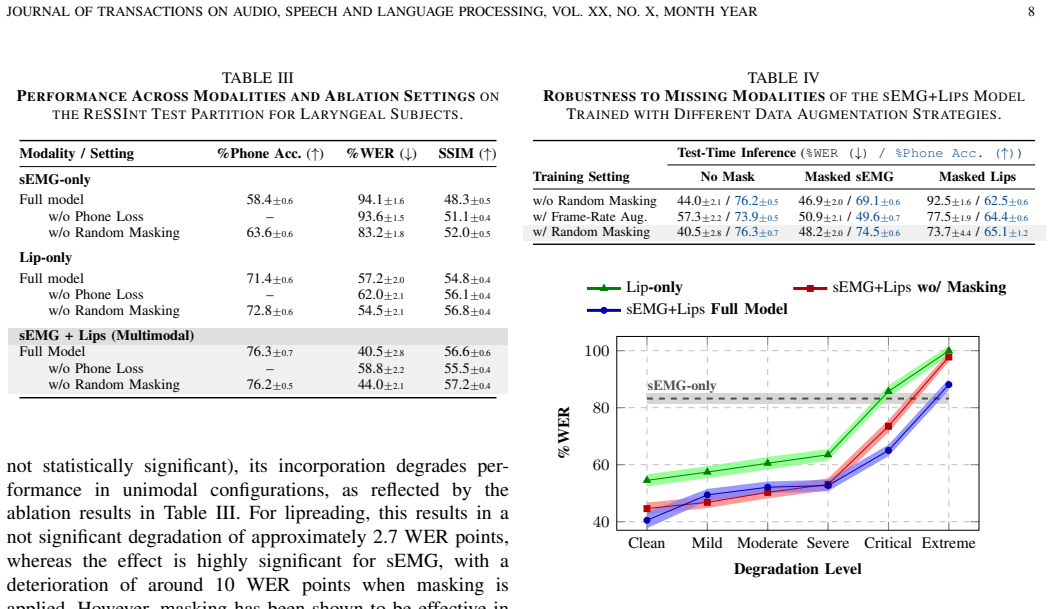
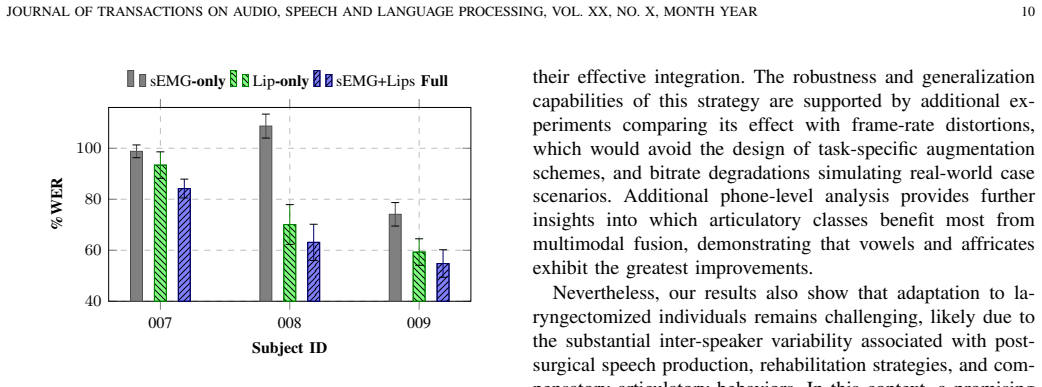
A masked multimodal speech synthesis framework jointly leverages sEMG and lipreading signals through modality masking during training. Under multispeaker settings, the proposed approach reduces word error rate by up to 14 absolute percentage points compared to the strongest unimodal baseline. Masking strategies are critical for these performance gains and robustness under low-bitrate conditions and generalize better than degradation-specific data augmentations in the presence of modality absence conditions. Phone-level analyses further reveal complementary contributions across modalities, with particularly strong benefits for vowels and for specific consonant groups.
What carries the argument
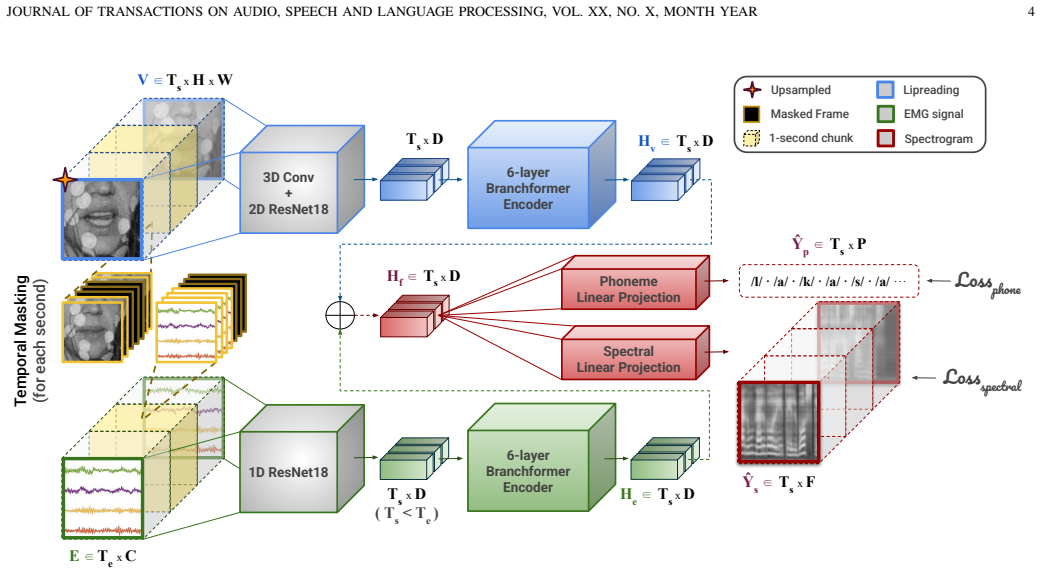
Cross-modal masking applied to sEMG and lipreading inputs during training, which randomly occludes one modality to encourage the model to extract usable information from the remaining one.
If this is right
- Word error rates drop substantially in multispeaker silent speech synthesis compared with single-modality baselines.
- The model maintains accuracy under low-bitrate conditions without additional degradation-specific training.
- Performance under full modality absence exceeds that obtained from targeted data augmentations.
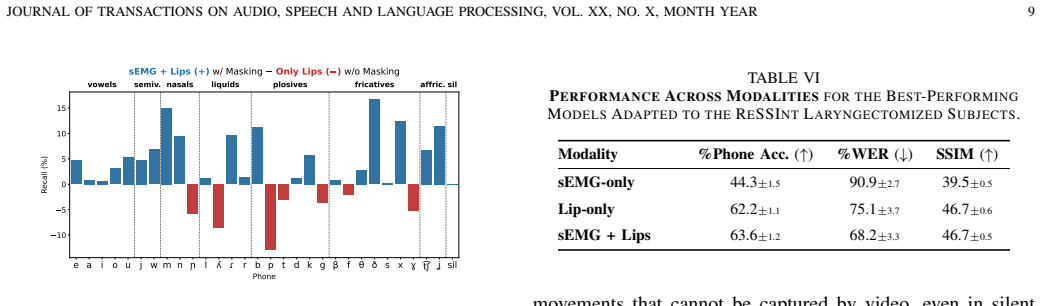
- Complementary gains appear for vowels and selected consonant classes, indicating the two signals cover different articulatory features.
Where Pith is reading between the lines
- The same masking procedure could be applied to other pairs of non-invasive signals such as ultrasound and EMG to test whether the robustness pattern holds.
- Real-time implementation in wearable devices would require checking whether the trained model still functions when both modalities arrive with variable latency.
- Once tested on actual patient populations the framework might reduce the need for speaker-specific retraining in clinical settings.
Load-bearing premise
The multispeaker experimental data and masking procedure will produce comparable robustness when one modality is truly absent or degraded in target users such as laryngectomized speakers.
What would settle it
Word error rate measured on laryngectomized speaker recordings when one entire modality is removed at test time.
Figures


read the original abstract
Speech restoration through silent speech interfaces (SSIs) has emerged as a promising assistive technology for individuals with impaired or absent laryngeal voice production. Among non-invasive SSI modalities, surface electromyography (sEMG) and video-based lipreading provide complementary articulatory information, yet their integration for continuous speech synthesis remains underexplored. Moreover, existing multimodal approaches rarely address robustness to modality degradation or temporary sensor failure, limiting their applicability in realistic scenarios. In this work, we propose a masked multimodal speech synthesis framework that jointly leverages sEMG and lipreading signals through modality masking during training. Under multispeaker settings, the proposed approach reduces word error rate by up to 14 absolute percentage points compared to the strongest unimodal baseline. Experimental results not only show that masking strategies are critical for these performance gains and robustness under low-bitrate conditions, but also that they generalize better than degradation-specific data augmentations in the presence of modality absence conditions. Phone-level analyses further reveal complementary contributions across modalities, with particularly strong benefits for vowels and for specific consonant groups. Overall, these findings demonstrate the effectiveness and robustness of masked multimodal integration for silent speech synthesis, although adaptation to laryngectomized speakers remains an open research challenge.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a cross-modal masking framework for multimodal silent speech synthesis that integrates sEMG and lipreading signals. It reports that, in multispeaker experiments, the approach yields up to a 14 absolute percentage point WER reduction versus the strongest unimodal baseline, that masking is essential for these gains and for robustness under low-bitrate and modality-absence conditions, and that the strategy generalizes better than degradation-specific augmentations. Phone-level analyses indicate complementary contributions, especially for vowels and selected consonants. The abstract notes that adaptation to laryngectomized speakers remains an open challenge.
Significance. If the reported WER reductions and robustness gains are reproducible, the work would represent a meaningful advance in practical multimodal silent-speech interfaces by showing that modality masking can improve handling of sensor failure without task-specific augmentations. The emphasis on complementary modality contributions also supplies useful diagnostic insight. However, because all quantitative results derive from simulated degradation on healthy multispeaker data, the practical significance for the stated target population is not yet established.
major comments (1)
- [Abstract] Abstract: the central claim that the method delivers 'robustness under low-bitrate conditions' and 'generalize[s] better than degradation-specific data augmentations in the presence of modality absence conditions' rests on experiments that simulate absence on healthy speakers; the manuscript itself states that 'adaptation to laryngectomized speakers remains an open research challenge,' so the practical robustness claim for the intended clinical users is an extrapolation whose validity is untested.
minor comments (1)
- [Abstract] Abstract: quantitative claims (14 pp WER reduction, comparisons to baselines) are stated without accompanying dataset sizes, number of speakers, error bars, or statistical tests; these details belong in the abstract or a dedicated results paragraph for immediate assessment.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the concern about the scope of the robustness claims in the abstract below and agree that clarification is warranted.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the method delivers 'robustness under low-bitrate conditions' and 'generalize[s] better than degradation-specific data augmentations in the presence of modality absence conditions' rests on experiments that simulate absence on healthy speakers; the manuscript itself states that 'adaptation to laryngectomized speakers remains an open research challenge,' so the practical robustness claim for the intended clinical users is an extrapolation whose validity is untested.
Authors: We agree that all reported results use simulated modality degradation and absence on healthy multispeaker data, and that direct evaluation on laryngectomized speakers is untested and remains an open challenge (as already stated in the abstract). The abstract claims refer specifically to performance gains and robustness observed under these controlled simulation conditions. To prevent any over-extrapolation, we will revise the abstract to explicitly qualify the robustness and generalization statements as applying to simulated low-bitrate and modality-absence conditions on healthy speakers. revision: yes
Circularity Check
No circularity: purely empirical results with no derivations or self-referential fits
full rationale
The paper presents an empirical study of a masked multimodal speech synthesis model evaluated on multispeaker sEMG + lipreading data. All load-bearing claims (WER reductions up to 14 pp, superiority of masking over augmentations, robustness under simulated modality absence) are stated as direct experimental measurements. No equations, first-principles derivations, parameter-fitting steps, or uniqueness theorems appear in the provided text. The abstract explicitly flags the clinical population gap as an open challenge rather than claiming it has been solved. Because there is no derivation chain at all, none of the enumerated circularity patterns can apply.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption sEMG and lipreading signals supply complementary articulatory information for continuous speech synthesis
Reference graph
Works this paper leans on
-
[1]
Social Withdrawal After Laryngectomy,
H. Danker, D. Wollbr ¨uck, S. Singer, M. Fuchs, E. Br¨ahler, and A. Meyer, “Social Withdrawal After Laryngectomy,”European Archives of Oto- Rhino-Laryngology, vol. 267, no. 4, pp. 593–600, 2010
2010
-
[2]
Depression Fol- lowing Laryngectomy: A Pilot Study,
A. Byrne, M. Walsh, M. Farrelly, and K. O’Driscoll, “Depression Fol- lowing Laryngectomy: A Pilot Study,”The British Journal of Psychiatry, vol. 163, no. 2, pp. 173–176, 1993
1993
-
[3]
Aphasia as Identity Theft: Theory and Practice,
B. Shadden, “Aphasia as Identity Theft: Theory and Practice,”Aphasi- ology, vol. 19, no. 3-5, pp. 211–223, 2005
2005
-
[4]
Acoustic and Perceptual Char- acteristics of Esophageal and Tracheoesophageal Speech Production,
T. Most, Y . Tobin, and R. C. Mimran, “Acoustic and Perceptual Char- acteristics of Esophageal and Tracheoesophageal Speech Production,” Journal of Communication Disorders, vol. 33, no. 2, pp. 165–181, 2000
2000
-
[5]
V oice Restoration After Total Laryn- gectomy,
C. G. Tang and C. F. Sinclair, “V oice Restoration After Total Laryn- gectomy,”Otolaryngologic Clinics of North America, vol. 48, no. 4, pp. 687–702, 2015
2015
-
[6]
Silent Speech Interfaces for Speech Restoration: A Review,
J. A. Gonz ´alez-L´opez, A. G ´omez-Alan´ıs, J. M. Mart ´ın Do˜nas, J. L. P´erez-C´ordoba, and A. M. G ´omez, “Silent Speech Interfaces for Speech Restoration: A Review,”IEEE Access, vol. 8, pp. 177 995–178 021, 2020
2020
-
[7]
How Silent Are Silent Speech Interfaces? Speech Reconstruction From Whispered and Silent Ultrasound Tongue Images,
G. Gosztolya, I. Ibrahimov, and C. Zaink ´o, “How Silent Are Silent Speech Interfaces? Speech Reconstruction From Whispered and Silent Ultrasound Tongue Images,” inProc. SSW, 2025, pp. 157–162
2025
-
[8]
Articulatory V owel Distinctiveness in Spanish,
K. Teplansky, E. Rangel, M. LaValley, J. Kwon, B. Cao, and J. Wang, “Articulatory V owel Distinctiveness in Spanish,” inProc. of Interspeech, 2025, pp. 5593–5597
2025
-
[9]
Silent Speech Recognition as an Alternative Communication Device for Persons With Laryngectomy,
G. S. Meltzner, J. T. Heaton, Y . Deng, G. De Luca, S. H. Roy, and J. C. Kline, “Silent Speech Recognition as an Alternative Communication Device for Persons With Laryngectomy,”IEEE/ACM TASLP, vol. 25, no. 12, pp. 2386–2398, 2017
2017
-
[10]
V oicing Silent Speech,
D. M. Gaddy, “V oicing Silent Speech,” Ph.D. dissertation, University of California, Berkeley, 2022
2022
-
[11]
Personalized One-Shot Lipreading for an ALS Patient,
B. Sen, A. Agarwal, R. Mukhopadhyay, V . Namboodiri, and C. V . Jawahar, “Personalized One-Shot Lipreading for an ALS Patient,” in Proc. of BMVC, 2021
2021
-
[12]
Two-Stage Visual Speech Recognition for Intensive Care Patients,
H. Laux, A. Hallawa, J. C. S. Assis, A. Schmeink, L. Martin, and A. Peine, “Two-Stage Visual Speech Recognition for Intensive Care Patients,”Scientific Reports, vol. 13, no. 1, p. 928, 2023
2023
-
[13]
Digital V oicing of Silent Speech,
D. Gaddy and D. Klein, “Digital V oicing of Silent Speech,” inProc. of EMNLP, 2020, pp. 5521–5530
2020
-
[14]
Visual Speech Recognition for Multiple Languages in the Wild,
P. Ma, S. Petridis, and M. Pantic, “Visual Speech Recognition for Multiple Languages in the Wild,”Nature Machine Intelligence, vol. 4, no. 11, pp. 930–939, 2022
2022
-
[15]
Electrode Setup for Electromyography-Based Silent Speech Interfaces: A Pilot Study,
I. Salomons, E. Del Blanco, E. Navas, and I. Hern ´aez, “Electrode Setup for Electromyography-Based Silent Speech Interfaces: A Pilot Study,” Sensors, vol. 25, no. 3, p. 781, 2025
2025
-
[16]
Watch or Listen: Robust Audio-Visual Speech Recognition with Visual Corruption Modeling and Reliability Scoring,
J. Hong, M. Kim, J. Choi, and Y . M. Ro, “Watch or Listen: Robust Audio-Visual Speech Recognition with Visual Corruption Modeling and Reliability Scoring,” inProc. of IEEE/CVF CVPR, 2023, pp. 18 783– 18 794
2023
-
[17]
Visual-Only Recognition of Normal, Whispered and Silent Speech,
S. Petridis, J. Shen, D. Cetin, and M. Pantic, “Visual-Only Recognition of Normal, Whispered and Silent Speech,” inProc. of ICASSP. IEEE, 2018, pp. 6219–6223
2018
-
[18]
Development of a Silent Speech Interface Driven by Ul- trasound and Optical Images of the Tongue and Lips,
T. Hueber, E.-L. Benaroya, G. Chollet, B. Denby, G. Dreyfus, and M. Stone, “Development of a Silent Speech Interface Driven by Ul- trasound and Optical Images of the Tongue and Lips,”Speech Commu- nication, vol. 52, no. 4, pp. 288–300, 2010
2010
-
[19]
A VE Speech: A Comprehensive Multimodal Dataset for Speech Recognition Integrat- ing Audio, Visual, and Electromyographic Signals,
D. Zhou, Y . Zhang, J. Wu, X. Zhang, L. Xie, and E. Yin, “A VE Speech: A Comprehensive Multimodal Dataset for Speech Recognition Integrat- ing Audio, Visual, and Electromyographic Signals,”IEEE Transactions on Human-Machine Systems, vol. 55, no. 4, pp. 559–568, 2025
2025
-
[20]
SpecAugment on Large Scale Datasets,
D. S. Park, Y . Zhang, C.-C. Chiu, Y . Chen, B. Li, W. Chan, Q. V . Le, and Y . Wu, “SpecAugment on Large Scale Datasets,” inICASSP, 2020, pp. 6879–6883
2020
-
[21]
Learning Audio- Visual Speech Representation by Masked Multimodal Cluster Predic- tion,
B. Shi, W. N. Hsu, K. Lakhotia, and A. Mohamed, “Learning Audio- Visual Speech Representation by Masked Multimodal Cluster Predic- tion,”arXiv preprint arXiv:2201.02184, 2022
-
[22]
Tailored Design of Audio-Visual Speech Recognition Models Using Branchformers,
D. Gimeno-G ´omez and C. D. Martinez-Hinarejos, “Tailored Design of Audio-Visual Speech Recognition Models Using Branchformers,” Computer Speech & Language, p. 101811, 2025
2025
-
[23]
Silent Speech Interfaces,
B. Denby, T. Schultz, K. Honda, T. Hueber, J. M. Gilbert, and J. S. Brumberg, “Silent Speech Interfaces,”Speech Communication, vol. 52, no. 4, pp. 270–287, 2010
2010
-
[24]
Conversion from Facial Myoelectric Signals to Speech: A Unit Selection Approach,
M. Zahner, M. Janke, M. Wand, and T. Schultz, “Conversion from Facial Myoelectric Signals to Speech: A Unit Selection Approach,” in INTERSPEECH, 2014, pp. 1184–1188
2014
-
[25]
EMG-to-Speech: Direct Generation of Speech from Facial Electromyographic Signals,
M. Janke and L. Diener, “EMG-to-Speech: Direct Generation of Speech from Facial Electromyographic Signals,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 25, no. 12, pp. 2375– 2385, 2017
2017
-
[26]
A Comparison of EMG- to-Speech Conversion for Isolated and Continuous Speech,
L. Diener, S. Bredehoeft, and T. Schultz, “A Comparison of EMG- to-Speech Conversion for Isolated and Continuous Speech,” inSpeech Communication; 13th ITG-Symposium. VDE, 2018, pp. 1–5
2018
-
[27]
Confidence- Based Self-Training for EMG-to-Speech: Leveraging Synthetic EMG for Robust Modeling,
X. Chen, X. Gao, M. Quoy, A. Pitti, and N. F. Chen, “Confidence- Based Self-Training for EMG-to-Speech: Leveraging Synthetic EMG for Robust Modeling,”arXiv preprint arXiv:2506.11862, 2025
-
[28]
Diff-ets: Learning a diffusion probabilistic model for electromyography-to-speech conversion,
Z. Ren, K. Scheck, Q. Hou, S. van Gogh, M. Wand, and T. Schultz, “Diff-ets: Learning a diffusion probabilistic model for electromyography-to-speech conversion,” in2024 46th Annual Interna- tional Conference of the IEEE Engineering in Medicine and Biology Society (EMBC). IEEE, 2024, pp. 1–4
2024
-
[29]
Multi-Speaker Speech Synthesis from Electromyographic Signals by Soft Speech Unit Prediction,
K. Scheck and T. Schultz, “Multi-Speaker Speech Synthesis from Electromyographic Signals by Soft Speech Unit Prediction,” inICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2023, pp. 1–5
2023
-
[30]
Cross-Speaker Training and Adaptation for Electromyography-to-Speech Conversion,
K. Scheck, Z. Ren, T. Dombeck, J. Sonnert, S. van Gogh, Q. Hou, M. Wand, and T. Schultz, “Cross-Speaker Training and Adaptation for Electromyography-to-Speech Conversion,” in2024 46th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC). IEEE, 2024, pp. 1–4
2024
-
[31]
Silent Speech Interface with V ocal Speaker Assistance Based on Convolution-Augmented Transformer,
H. Li, Y . Liang, H. Gao, L. Liu, Y . Wang, D. Chen, Z. Luo, and G. Li, “Silent Speech Interface with V ocal Speaker Assistance Based on Convolution-Augmented Transformer,”IEEE Transactions on Instru- mentation and Measurement, vol. 72, pp. 1–11, 2023
2023
-
[32]
Lip2Audspec: Speech Reconstruction from Silent Lip Movements Video,
H. Akbari, H. Arora, L. Cao, and N. Mesgarani, “Lip2Audspec: Speech Reconstruction from Silent Lip Movements Video,” inProc. of ICASSP, 2018, pp. 2516–2520
2018
-
[33]
Learning Individual Speaking Styles for Accurate Lip to Speech Synthesis,
K. Prajwal, R. Mukhopadhyay, V . P. Namboodiri, and C. Jawahar, “Learning Individual Speaking Styles for Accurate Lip to Speech Synthesis,” inCVPR, 2020, pp. 13 796–13 805
2020
-
[34]
SVTS: Scalable Video-to-Speech Synthesis,
R. Schoburg Carrillo de Mira, A. Haliassos, S. Petridis, B. W. Schuller, and M. Pantic, “SVTS: Scalable Video-to-Speech Synthesis,” inInter- speech 2022, 2022, pp. 1836–1840
2022
-
[35]
Conformer: Convolution- augmented Transformer for Speech Recognition,
A. Gulati, J. Qin, C. C. Chiu, N. Parmar, Y . Zhang, J. Yu, W. Han, S. Wang, Z. Zhang, Y . Wu, and R. Pang, “Conformer: Convolution- augmented Transformer for Speech Recognition,” inProc. Interspeech, 2020, pp. 5036–5040
2020
-
[36]
Lip-to-Speech Synthesis in the wild with Multi-Task Learning,
M. Kim, J. Hong, and Y . M. Ro, “Lip-to-Speech Synthesis in the wild with Multi-Task Learning,” inICASSP. IEEE, 2023, pp. 1–5
2023
-
[37]
Lipdiffuser: Lip-to-Speech Generation with Conditional Diffusion Models,
J. Richter, D. de Oliveira, T. Peer, and T. Gerkmann, “Lipdiffuser: Lip-to-Speech Generation with Conditional Diffusion Models,”arXiv preprint arXiv:2505.11391, 2025
-
[38]
The Challenge of Multispeaker Lip-Reading,
S. J. Cox, R. W. Harvey, Y . Lan, J. L. Newman, and B.-J. Theobald, “The Challenge of Multispeaker Lip-Reading,” inAVSP, 2008, pp. 179–184
2008
-
[39]
Comparing Speaker Adaptation Methods for Visual Speech Recognition for Continuous Spanish,
D. Gimeno-G ´omez and C.-D. Mart ´ınez-Hinarejos, “Comparing Speaker Adaptation Methods for Visual Speech Recognition for Continuous Spanish,”Applied Sciences, vol. 13, no. 11, 2023
2023
-
[40]
Development of Speechreading Supplements Based on Automatic Speech Recognition,
P. Duchnowski, D. S. Lum, J. C. Krause, M. G. Sexton, M. S. Bratakos, and L. D. Braida, “Development of Speechreading Supplements Based on Automatic Speech Recognition,”IEEE Trans. on Biomedical Engi- neering, vol. 47, no. 4, pp. 487–496, 2000
2000
-
[41]
Multimodal Deep Learning,
J. Ngiam, A. Khosla, M. Kim, J. Nam, H. Lee, and A. Ng, “Multimodal Deep Learning,” inProc. of the 28th ICML, 01 2011, pp. 689–696
2011
-
[42]
En- hancing Multimodal Silent Speech Interfaces with Feature Selection,
J. Freitas, A. Ferreira, M. Figueiredo, A. Teixeira, and M. S. Dias, “En- hancing Multimodal Silent Speech Interfaces with Feature Selection,” in Interspeech, 2014, pp. 1169–1173
2014
-
[43]
Multimodal Corpora for Silent Speech Interaction,
J. Freitas, A. Teixeira, and M. Dias, “Multimodal Corpora for Silent Speech Interaction,” inLREC, 2014, pp. 4507–4511
2014
-
[44]
A Comprehensive Multimodal Dataset for Contactless Lip Reading and Acoustic Analysis,
Y . Ge, C. Tang, H. Li, Z. Chen, J. Wang, W. Li, J. Cooper, K. Chetty, D. Faccio, M. Imran, and Q. H. Abbasi, “A Comprehensive Multimodal Dataset for Contactless Lip Reading and Acoustic Analysis,”Scientific Data, vol. 10, no. 1, p. 895, 2023
2023
-
[45]
Hybrid Silent Speech Interface Through Fusion of Electroencephalography and Electromyography,
H. Li, M. Wang, H. Gao, S. Zhao, G. Li, and Y . Wang, “Hybrid Silent Speech Interface Through Fusion of Electroencephalography and Electromyography,” inInterspeech, 2023, pp. 1184–1188
2023
-
[46]
Optimizing Phoneme-to-Viseme Mapping for Continuous Lip-Reading in Spanish,
A. Fern ´andez-L´opez and F. Sukno, “Optimizing Phoneme-to-Viseme Mapping for Continuous Lip-Reading in Spanish,” inVISIGRAPP. Springer, 2017, pp. 305–328
2017
-
[47]
Deep Audio-Visual Speech Recognition,
T. Afouras, J. S. Chung, A. Senior, O. Vinyals, and A. Zisserman, “Deep Audio-Visual Speech Recognition,”Transactions on PAMI, vol. 44, no. 12, pp. 8717–8727, 2018. JOURNAL OF TRANSACTIONS ON AUDIO, SPEECH AND LANGUAGE PROCESSING, VOL. XX, NO. X, MONTH YEAR 12
2018
-
[48]
Auto-A VSR: Audio-Visual Speech Recognition with Auto- matic Labels,
P. Ma, A. Haliassos, A. Fernandez-Lopez, H. Chen, S. Petridis, and M. Pantic, “Auto-A VSR: Audio-Visual Speech Recognition with Auto- matic Labels,” inICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2023, pp. 1–5
2023
-
[49]
End-To-End Audio-Visual Speech Recognition with Conformers,
P. Ma, S. Petridis, and M. Pantic, “End-To-End Audio-Visual Speech Recognition with Conformers,” inICASSP 2021 - 2021 IEEE In- ternational Conference on Acoustics, Speech and Signal Processing (ICASSP), 2021, pp. 7613–7617
2021
-
[50]
Deep Residual Learning for Image Recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep Residual Learning for Image Recognition,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770–778
2016
-
[51]
Branchformer: Parallel MLP-Attention Architectures to Capture Local and Global Context for Speech Recognition and Understanding,
Y . Peng, S. Dalmia, I. Lane, and S. Watanabe, “Branchformer: Parallel MLP-Attention Architectures to Capture Local and Global Context for Speech Recognition and Understanding,” inICML, vol. 162, 2022, pp. 17 627–17 643
2022
-
[52]
Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context,
Z. Dai, Z. Yang, Y . Yang, J. Carbonell, Q. Le, and R. Salakhutdinov, “Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context,” inACL, 2019, pp. 2978–2988
2019
-
[53]
Attention is All You Need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, “Attention is All You Need,”Advances in Neural Information Processing Systems, vol. 30, pp. 6000–6010, 2017
2017
-
[54]
MLP-Based Architecture with Variable Length Input for Automatic Speech Recognition,
J.Sakuma, T. Komatsu, and R. Scheibler, “MLP-Based Architecture with Variable Length Input for Automatic Speech Recognition,” 2022. [Online]. Available: https://openreview.net/forum?id=RA-zVvZLYIy
2022
-
[55]
Comparative Analysis of Mono-speaker and Multi-speaker Models for EMG-to-Speech Conversion,
E. del Blanco, I. Salomons, V . Garc ´ıa, E. Navas, and I. Hern ´aez, “Comparative Analysis of Mono-speaker and Multi-speaker Models for EMG-to-Speech Conversion,” inProc. of IberSPEECH, 2024, pp. 81– 85
2024
-
[56]
Y . A. Li, C. Han, X. Jiang, and N. Mesgarani, “HiFTNet: A Fast High- Quality Neural V ocoder with Harmonic-Plus-Noise Filter and Inverse Short Time Fourier Transform,”arXiv preprint arXiv:2309.09493, 2023
-
[57]
Resolution Limits on Visual Speech Recognition,
H. Bear, R. Harvey, B. Theobald, and Y . Lan, “Resolution Limits on Visual Speech Recognition,” inProc. of ICIP. IEEE, 2014, pp. 1371– 1375
2014
-
[58]
Continuous Lipread- ing Based on Acoustic Temporal Alignments,
D. Gimeno-G ´omez and C.-D. Mart´ınez-Hinarejos, “Continuous Lipread- ing Based on Acoustic Temporal Alignments,”EURASIP Journal on Audio, Speech, and Music Processing, vol. 2024, no. 1, p. 25, 2024
2024
-
[59]
Montreal Forced Aligner: Trainable Text-Speech Alignment Using Kaldi,
M. McAuliffe, M. Socolof, S. Mihuc, M. Wagner, and M. Sonderegger, “Montreal Forced Aligner: Trainable Text-Speech Alignment Using Kaldi,” inInterspeech, vol. 2017, 2017, pp. 498–502
2017
-
[60]
RetinaFace: Single-Shot Multi-Level Face Localisation in the Wild,
J. Deng, J. Guo, E. Ververas, I. Kotsia, and S. Zafeiriou, “RetinaFace: Single-Shot Multi-Level Face Localisation in the Wild,” inCVPR, 2020, pp. 5202–5211
2020
-
[61]
How Far are We from Solving the 2D & 3D Face Alignment Problem? (and a Dataset of 230,000 3D Facial Landmarks),
A. Bulat and G. Tzimiropoulos, “How Far are We from Solving the 2D & 3D Face Alignment Problem? (and a Dataset of 230,000 3D Facial Landmarks),” inICCV, 2017, pp. 1021–1030
2017
-
[62]
Dynamic Time Warping,
M. M ¨uller, “Dynamic Time Warping,”Information Retrieval for Music and Motion, pp. 69–84, 2007
2007
-
[63]
Robust Speech Recognition via Large-Scale Weak Supervision,
A. Radford, J. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust Speech Recognition via Large-Scale Weak Supervision,” in ICML. PMLR, 2023, pp. 28 492–28 518
2023
-
[64]
Bootstrap Estimates for Confidence Intervals in ASR Performance Evaluation,
M. Bisani and H. Ney, “Bootstrap Estimates for Confidence Intervals in ASR Performance Evaluation,” inICASSP, vol. 1, 2004, pp. 409–412
2004
-
[65]
Automatic Viseme V ocabulary Construction to Enhance Continuous Lip-Reading,
A. Fernandez-Lopez and F. M. Sukno, “Automatic Viseme V ocabulary Construction to Enhance Continuous Lip-Reading,” inInternational Conference on Computer Vision Theory and Applications, vol. 6. SCITEPRESS, 2017, pp. 52–63
2017
-
[66]
Visual-Only Recognition of Normal, Whispered and Silent Speech,
S. Petridis, J. Shen, D. Cetin, and M. Pantic, “Visual-Only Recognition of Normal, Whispered and Silent Speech,” inICASSP, 2018, pp. 6219– 6223
2018
-
[67]
DiffMV-ETS: Diffusion-based Multi-V oice Electromyography-to- Speech Conversion using Speaker-Independent Speech Training Targets,
K. Scheck, T. Dombeck, Z. Ren, P. Wu, M. Wand, and T. Schultz, “DiffMV-ETS: Diffusion-based Multi-V oice Electromyography-to- Speech Conversion using Speaker-Independent Speech Training Targets,” inInterspeech, 2025, pp. 5573–5577
2025
-
[68]
LiRA: Learning Visual Speech Representations from Audio Through Self-Supervision,
P. Ma, R. Mira, S. Petridis, B. Schuller, and M. Pantic, “LiRA: Learning Visual Speech Representations from Audio Through Self-Supervision,” inProc. of Interspeech, 2021, pp. 3011–3015
2021
-
[69]
Cross-Modal Diffusion for Region-Aligned V ocal Tract MRI Synthesis,
P. A. Perez-Toro, T. Arias-Vergara, L. Buess, J. Hutter, J. Woo, and A. Maier, “Cross-Modal Diffusion for Region-Aligned V ocal Tract MRI Synthesis,” inMedical Imaging 2026: Imaging Informatics, vol. 13930. SPIE, 2026, pp. 239–246. Eder del Blancoreceived the B.Sc. degree in Telecommunication Technology (2015) and the M.Sc. degree in Telecommunication Eng...
2026
-
[70]
She received the Telecommunication Engi- neering and Ph.D. degrees from the Department of Electronics and Tele-communications, University of the Basque Country, Bilbao, Spain, in 1996 and 2003, respectively.,She is currently a Researcher with the Aholab Signal Processing Laboratory, De- partment of Communications Engineering, Univer- sity of the Basque Co...
1996
-
[71]
Her research interests include signal processing and all aspects related to speech processing
She is currently a Full Professor with the De- partment of Communications Engineering, Faculty of Engineering, University of the Basque Country, where she is involved in the area of signal theory and communications, and the Founding Member and Director of the Aholab Signal Processing Labora- tory. Her research interests include signal processing and all a...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.