SaluNet: Enabling Total Plasticity in Normalization-Free Deep Networks
Pith reviewed 2026-06-28 14:42 UTC · model grok-4.3
The pith
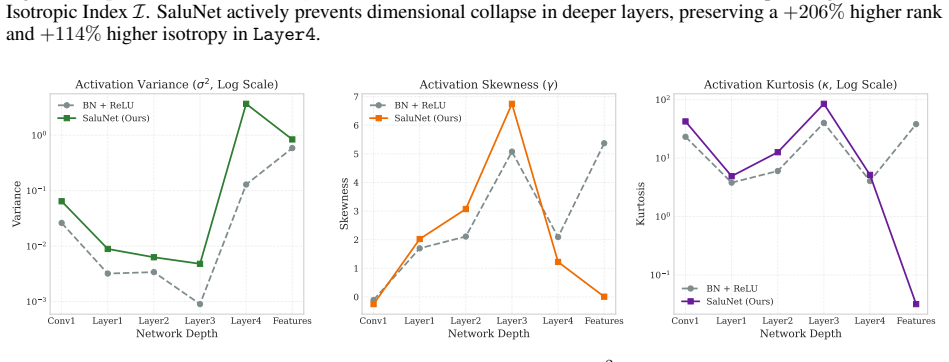
Normalization layers suppress total plasticity in deep networks, which a bounded learnable activation called SALU can replace entirely.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
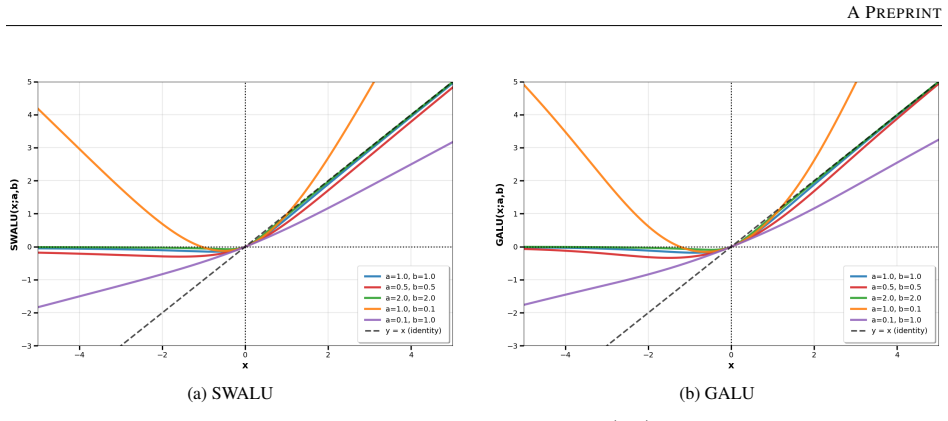
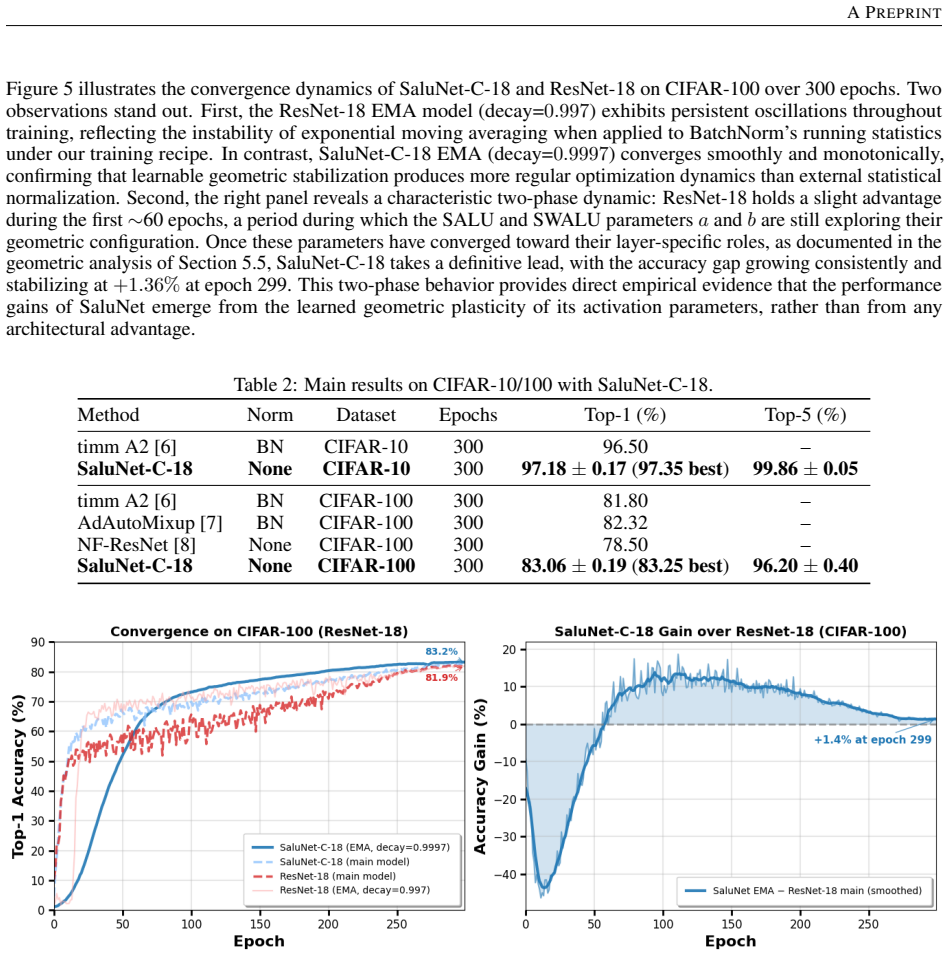
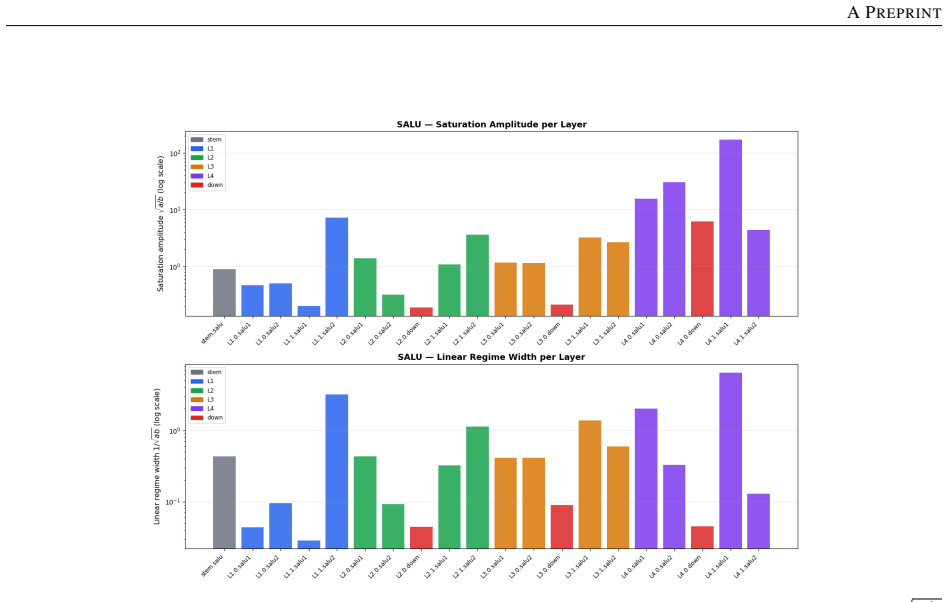
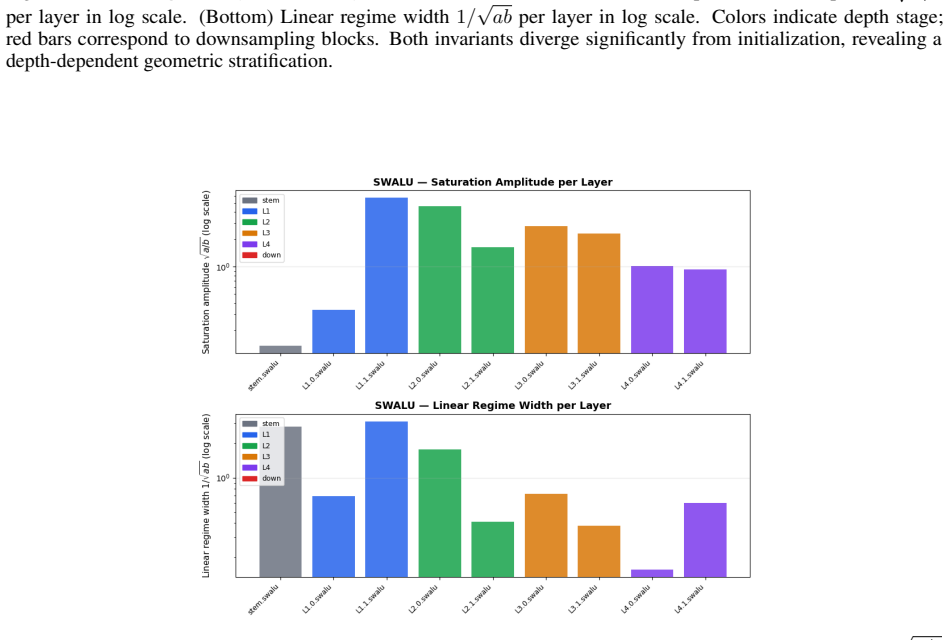
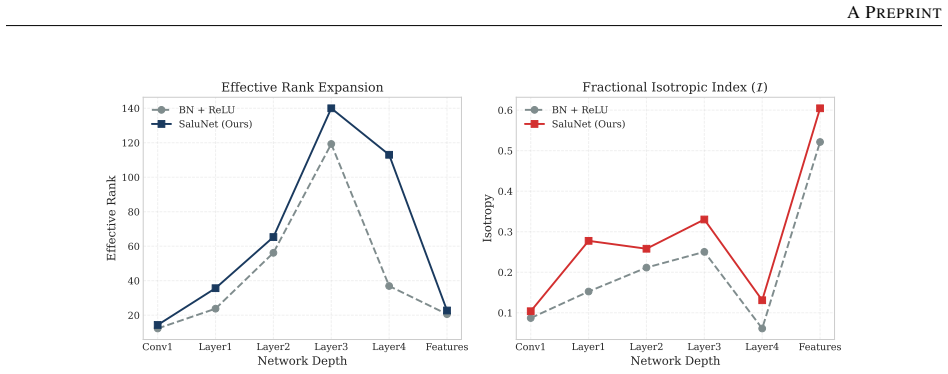
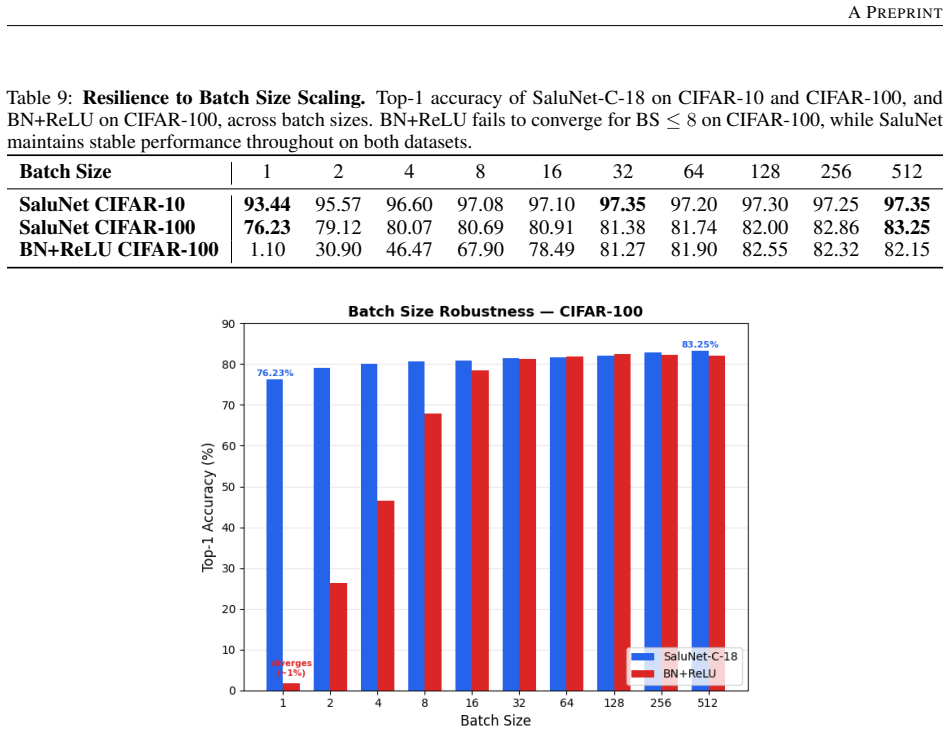
Normalization layers induce a plasticity suppression effect that limits adaptability in deep networks. Replacing them with SALU, a saturated adaptive linear unit that provides intrinsic signal stabilization, enables total plasticity. SaluNet built this way reaches 97.35% on CIFAR-10 with ResNet-18, 83.25% on CIFAR-100, 78.67% Top-1 on ImageNet-1K, and holds accuracy at batch size 1; transformer variants also improve over LayerNorm baselines.
What carries the argument
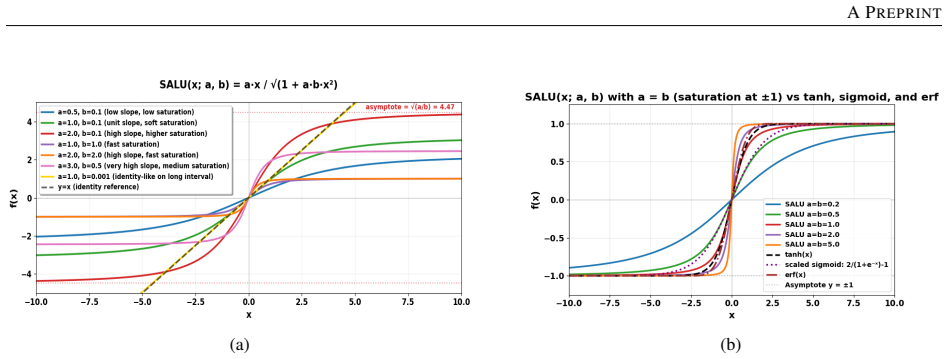
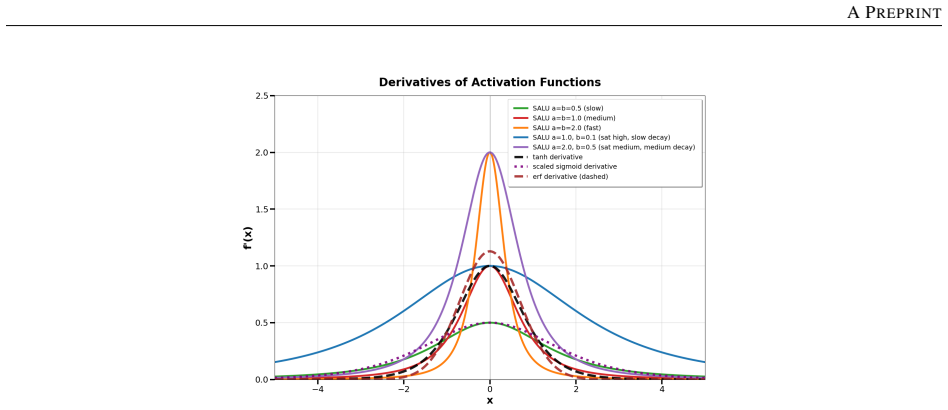
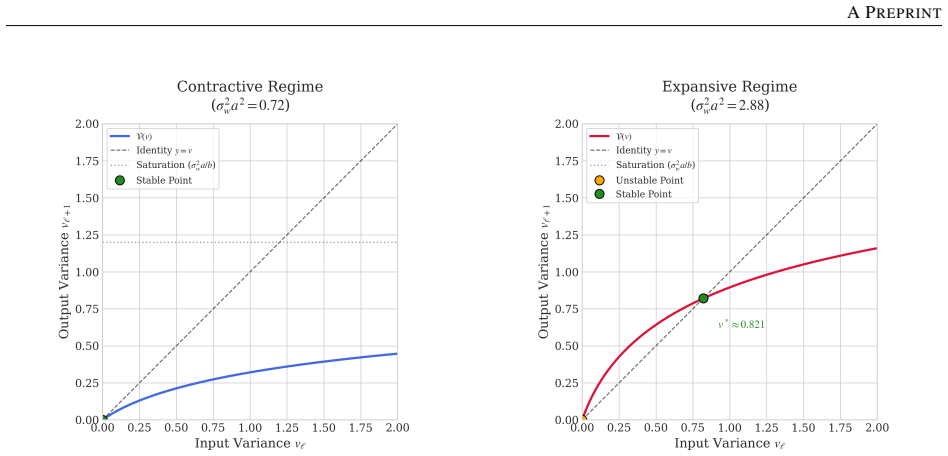
SALU, the Saturated Adaptive Linear Unit, a bounded learnable activation that provides intrinsic signal stabilization without batch statistics or external affine parameters.
If this is right
- SaluNet-C-18 reaches 97.35% on CIFAR-10 and 93.44% at batch size 1 without normalization.
- SaluNet-C-50 reaches 78.67% Top-1 on ImageNet-1K at 224x224 resolution.
- Transformer variants using SaluNet improve from 90.92% to 91.01% on CIFAR-10 over LayerNorm-GELU.
- Performance holds on CIFAR-100 at 83.25% for the ResNet-18 variant without normalization.
- Normalization is not required once total plasticity is restored through the replacement activation.
Where Pith is reading between the lines
- The approach may simplify deployment by removing the need to track running statistics or tune normalization hyperparameters.
- Total plasticity could improve robustness in settings with varying batch sizes or continual learning scenarios.
- Applying SALU to other architectures beyond ResNet and transformers might reveal whether the plasticity effect generalizes.
- The suppression mechanism could be tested by measuring parameter adaptability directly during training with and without normalization.
Load-bearing premise
The performance differences arise specifically from removing normalization layers rather than from choices in optimizer, data augmentation, or other training details.
What would settle it
Train the exact same SaluNet architecture both with and without added normalization layers under identical optimizer and augmentation settings, then check whether accuracy drops when normalization is present.
Figures
read the original abstract
Normalization layers such as BatchNorm and LayerNorm have long been considered essential for stable training in deep networks. This work demonstrates that they can be fully replaced by a single learnable activation mechanism. We identify a plasticity suppression effect induced by standard normalization: learnable activation parameters rapidly lose adaptability when paired with normalization layers. Motivated by this observation, we introduce SALU (Saturated Adaptive Linear Unit), \[ \operatorname{SALU}(x;a,b) = \frac{a x}{\sqrt{1 + a b x^2}},\quad a>0,\; b>0 \] a bounded, learnable activation that provides intrinsic signal stabilization without relying on batch statistics or external affine parameters. Building on SALU, we propose SaluNet, a paradigm grounded in total plasticity: SALU replaces normalization layers, while SWALU and GALU replace standard activations. With ResNet-18, SaluNet-C-18 achieves 97.35\% on CIFAR-10 and 83.25\% on CIFAR-100 without normalization, maintaining 93.44\% and 76.23\% at batch size 1 where normalized architectures fail. For transformers, SaluNet-T improves over LayerNorm-GELU from 90.92\% to 91.01\% on CIFAR-10 and from 66.54\% to 68.10\% on CIFAR-100. SaluNet-C-50 reaches 78.67\% Top-1 on ImageNet-1K at $224\times224$, and $79.23\%$ at $288\times288$. These results suggest normalization layers suppress total plasticity, a property biological neurons inherently possess, enabling deep networks to learn effectively.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that normalization layers (BatchNorm, LayerNorm) induce a plasticity suppression effect on learnable activation parameters, introduces the SALU activation SALU(x;a,b) = a x / sqrt(1 + a b x^2) (a>0, b>0) as a bounded, learnable replacement providing intrinsic stabilization, and presents SaluNet architectures (with SWALU/GALU) that achieve 97.35% on CIFAR-10, 83.25% on CIFAR-100, and 78.67% Top-1 on ImageNet-1K without any normalization layers while maintaining performance at batch size 1.
Significance. If the reported accuracies are reproducible and the performance gains can be causally attributed to removal of normalization via controlled ablations, the work would be significant for challenging the assumed necessity of normalization layers and for proposing a normalization-free paradigm based on total plasticity in learnable activations.
major comments (2)
- [Abstract] Abstract: the central claim that normalization induces a plasticity suppression effect (learnable activation parameters lose adaptability) is presented as an observational identification but is not supported by any ablation, training curve, or independent metric that holds optimizer, data augmentation, LR schedule, initialization, and other training details fixed while toggling only normalization versus SALU.
- [Abstract] Abstract: the performance numbers (97.35% CIFAR-10 with ResNet-18, 78.67% ImageNet-1K with ResNet-50) are attributed to the plasticity mechanism, yet no evidence isolates this from possible differences in the overall training recipe, undermining the causal link required for the total-plasticity paradigm.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the need for explicit evidence supporting the plasticity suppression claim and the causal attribution of results. We address each point below and will revise the manuscript to incorporate additional controlled experiments.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that normalization induces a plasticity suppression effect (learnable activation parameters lose adaptability) is presented as an observational identification but is not supported by any ablation, training curve, or independent metric that holds optimizer, data augmentation, LR schedule, initialization, and other training details fixed while toggling only normalization versus SALU.
Authors: We agree that the abstract presents the identification without referencing supporting experiments. The manuscript contains comparative training dynamics and parameter adaptation observations, but these do not constitute the fully controlled ablations requested. We will add a dedicated subsection with experiments that toggle only the presence of normalization layers versus SALU while holding all other factors fixed, including a new figure showing parameter adaptability metrics over training. revision: yes
-
Referee: [Abstract] Abstract: the performance numbers (97.35% CIFAR-10 with ResNet-18, 78.67% ImageNet-1K with ResNet-50) are attributed to the plasticity mechanism, yet no evidence isolates this from possible differences in the overall training recipe, undermining the causal link required for the total-plasticity paradigm.
Authors: The reported accuracies were obtained using standard training recipes for each dataset and architecture, with the primary modification being the substitution of normalization and activation layers. We acknowledge that this does not fully isolate the contribution of the plasticity mechanism from any incidental recipe differences. In revision we will include explicit ablation tables that vary only the normalization/activation components under identical training settings to strengthen the causal link. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper identifies an observational effect (plasticity suppression) and introduces the SALU activation formula as a replacement for normalization, then reports empirical performance on standard external benchmarks (CIFAR-10, CIFAR-100, ImageNet-1K). No mathematical derivation chain exists that reduces a claimed prediction or first-principles result to its own inputs by construction. The SALU definition is an explicit ansatz, not smuggled via self-citation. No self-citations, uniqueness theorems, or fitted parameters renamed as predictions appear in the abstract or described text. The performance numbers are externally falsifiable on public datasets and do not rely on internal redefinitions. This is a standard case of an empirical architecture paper whose central claims rest on reported results rather than tautological reduction.
Axiom & Free-Parameter Ledger
free parameters (1)
- a, b in SALU
invented entities (2)
-
SALU activation
no independent evidence
-
total plasticity
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Batch normalization: Accelerating deep network training by reducing internal covariate shift
Sergey Ioffe and Christian Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. InProceedings of the 32nd International Conference on Machine Learning (ICML), pages 448–456, 2015
2015
-
[2]
Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E. Hinton. Layer normalization.arXiv preprint arXiv:1607.06450, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[3]
Rectified linear units improve restricted boltzmann machines
Vinod Nair and Geoffrey Hinton. Rectified linear units improve restricted boltzmann machines. InProceedings of the International Conference on Machine Learning (ICML), 2010
2010
-
[4]
Gaussian Error Linear Units (GELUs)
Dan Hendrycks and Kevin Gimpel. Gaussian error linear units (GELU).arXiv preprint arXiv:1606.08415, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[5]
Delving deep into rectifiers: Surpassing human-level performance on ImageNet classification
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Delving deep into rectifiers: Surpassing human-level performance on ImageNet classification. InProceedings of the IEEE International Conference on Computer Vision (ICCV), pages 1026–1034, 2015
2015
-
[6]
ResNet strikes back: An improved training procedure in timm
Ross Wightman, Hugo Touvron, and Hervé Jégou. ResNet strikes back: An improved training procedure in timm. arXiv preprint arXiv:2110.00476, 2021
- [7]
-
[8]
Smith, and Karen Simonyan
Andrew Brock, Soham De, Samuel L. Smith, and Karen Simonyan. High-performance large-scale image recognition without normalization. InProceedings of the 38th International Conference on Machine Learning (ICML), pages 1000–1010, 2021
2021
-
[9]
Andrew Brock, Soham De, and Samuel L. Smith. Characterizing signal propagation to close the performance gap in unnormalized ResNets.International Conference on Learning Representations (ICLR), 2021
2021
-
[10]
Root mean square layer normalization
Biao Zhang and Rico Sennrich. Root mean square layer normalization. InAdvances in Neural Information Processing Systems (NeurIPS), 2019
2019
-
[11]
Group normalization
Yuxin Wu and Kaiming He. Group normalization. InProceedings of the European Conference on Computer Vision (ECCV), pages 3–19, 2018
2018
-
[12]
Transformers without normalization, 2025
Jiachen Zhu, Xinlei Chen, Kaiming He, Yann LeCun, and Zhuang Liu. Transformers without normalization, 2025
2025
-
[13]
Stronger normalization-free transformers, 2025
Mingzhi Chen, Taiming Lu, Jiachen Zhu, Mingjie Sun, and Zhuang Liu. Stronger normalization-free transformers, 2025
2025
-
[14]
Prajit Ramachandran, Barret Zoph, and Quoc V . Le. Searching for activation functions.arXiv preprint arXiv:1710.05941, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[15]
Vision transformer (ViT) implementation for CIFAR-10 and CIFAR-100
Omihub777. Vision transformer (ViT) implementation for CIFAR-10 and CIFAR-100. https://github.com/ omihub777/ViT-CIFAR, 2021. Accessed: 2026-04-29
2021
-
[16]
Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour
Priya Goyal, Piotr Dollár, Ross Girshick, Pieter Noordhuis, Lukasz Wesolowski, Aapo Kyrola, Andrew Tulloch, Yangqing Jia, and Kaiming He. Accurate, large minibatch SGD: Training ImageNet in 1 hour.arXiv preprint arXiv:1706.02677, 2017. 26 A PREPRINT
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[17]
Extremely Large Minibatch SGD: Training ResNet-50 on ImageNet in 15 Minutes
Takuya Akiba, Shuji Suzuki, Keisuke Fukuda, Satoshi Kobayashi, Yuichi Suzuki, and Kohei Komuro. Extremely large minibatch SGD: Training ResNet-50 on ImageNet in 15 minutes.arXiv preprint arXiv:1711.04325, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[18]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 770–778, 2016
2016
-
[19]
The effective rank: A measure of effective dimensionality
Olivier Roy and Martin Vetterli. The effective rank: A measure of effective dimensionality. InEuropean Signal Processing Conference (EUSIPCO), pages 606–610, 2007
2007
-
[20]
Prevalence of neural collapse during the terminal phase of deep learning training.Proceedings of the National Academy of Sciences, 117(40):24652–24663, 2020
Vardan Papyan, XY Han, and David L Donoho. Prevalence of neural collapse during the terminal phase of deep learning training.Proceedings of the National Academy of Sciences, 117(40):24652–24663, 2020
2020
-
[21]
Tim Salimans and Diederik P. Kingma. Weight normalization: A simple reparameterization to accelerate training of deep neural networks. InAdvances in Neural Information Processing Systems (NeurIPS), pages 901–909, 2016
2016
-
[22]
Filter response normalization layer: Eliminating batch dependence in the training of deep neural networks
Saurabh Singh and Shankar Krishnan. Filter response normalization layer: Eliminating batch dependence in the training of deep neural networks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020
2020
-
[23]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in Neural Information Processing Systems (NeurIPS), pages 5998–6008, 2017
2017
-
[24]
David Balduzzi, Marcus Frean, Lennox Leary, J. P. Lewis, Kurt Wan-Duo Ma, and Brian McWilliams. The shattered gradients problem: If ResNets are the answer, then what is the question? InProceedings of the 34th International Conference on Machine Learning, pages 342–350, 2017
2017
-
[25]
Dauphin, and Tengyu Ma
Hongyi Zhang, Yann N. Dauphin, and Tengyu Ma. Fixup initialization: Residual learning without normalization. International Conference on Learning Representations (ICLR), 2019
2019
-
[26]
Bertsekas, Nikunj Saunshi, and Kannan Ramchandran
Shibani Santurkar, Dimitri P. Bertsekas, Nikunj Saunshi, and Kannan Ramchandran. How does batch normalization help optimization?Advances in Neural Information Processing Systems (NeurIPS), pages 2483–2493, 2018
2018
-
[27]
On the nonlinearity of layer normalization
Yunhao Ni, Yuxin Guo, Junlong Jia, and Lei Huang. On the nonlinearity of layer normalization. InProceedings of the International Conference on Machine Learning (ICML), volume 235 ofProceedings of Machine Learning Research (PMLR), pages 37957–37998, 2024
2024
-
[28]
Cottrell, and Julian McAuley
Thomas Bachlechner, Bodhisattwa Majumder, Huanru Henry Mao, Garrison W. Cottrell, and Julian McAuley. ReZero is all you need: Fast convergence at large depth. InInternational Conference on Learning Representations (ICLR), 2021
2021
-
[29]
Self-normalizing neural networks
Günter Klambauer, Thomas Unterthiner, Andreas Mayr, and Sepp Hochreiter. Self-normalizing neural networks. Advances in Neural Information Processing Systems (NeurIPS), pages 971–980, 2017
2017
-
[30]
Hanxiao Liu, Andrew Brock, Karen Simonyan, and Quoc V . Le. Evolving normalization-activation layers. In Advances in Neural Information Processing Systems (NeurIPS), volume 33, pages 13539–13550, 2020
2020
-
[31]
SReLU: SeLU-style rectified linear unit activations
Bin Liu, Yihui He, Hao Li, Guangrun Wang, Xiaodong Li, and Jianping Shi. SReLU: SeLU-style rectified linear unit activations. InProceedings of the European Conference on Computer Vision (ECCV), pages 841–856, 2018
2018
-
[32]
Zorro: Shape-controlled parametric activations.arXiv preprint arXiv:2403.12345, 2024
Luke Rood, Vincent van der Sar, et al. Zorro: Shape-controlled parametric activations.arXiv preprint arXiv:2403.12345, 2024
-
[33]
Exponential expressivity in deep neural networks through transient chaos.Advances in Neural Information Processing Systems (NeurIPS), pages 3360–3368, 2016
Benjamin Poole, Subhaneil Lahiri, Maithra Raghu, Jascha Sohl-Dickstein, and Surya Ganguli. Exponential expressivity in deep neural networks through transient chaos.Advances in Neural Information Processing Systems (NeurIPS), pages 3360–3368, 2016
2016
-
[34]
Schoenholz, Justin Gilmer, Surya Ganguli, and Jascha Sohl-Dickstein
Samuel S. Schoenholz, Justin Gilmer, Surya Ganguli, and Jascha Sohl-Dickstein. Deep information propagation. International Conference on Learning Representations (ICLR), 2017
2017
-
[35]
Jens Behrmann, Will Grathwohl, Ricky T. Q. Chen, David Duvenaud, and Jörn-Hendrik Jacobsen. On the invariance, stability and consistency of deep neural network representations.Advances in Neural Information Processing Systems (NeurIPS), pages 4505–4515, 2020
2020
-
[36]
Fast learning in networks of locally-tuned processing units
John Moody. Fast learning in networks of locally-tuned processing units. InAdvances in Neural Information Processing Systems (NeurIPS), pages 131–139, 1989
1989
-
[37]
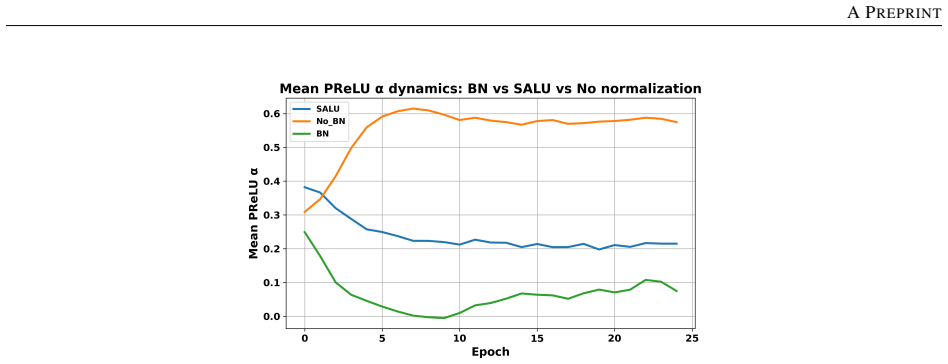
Ling Zhang and Paul B. Luh. Wavelet neural networks for function learning.IEEE Transactions on Signal Processing, 43(6):1485–1497, 1995. 27 A PREPRINT A PReLU Plasticity Experiment (Figure 1) We train a simple 4-layer CNN on CIFAR-10: • Architecture: Conv(32)-Conv(64)-FC(128)-FC(10) with PReLU activations. • Batch Normalization: applied before each PReLU ...
1995
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.