ChronoLock: Protecting Videos from Unauthorized Text-to-Video Personalization
Pith reviewed 2026-06-26 14:33 UTC · model grok-4.3
The pith
ChronoLock adds bounded perturbations over temporal denoising trajectories to block unauthorized text-to-video motion imitation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
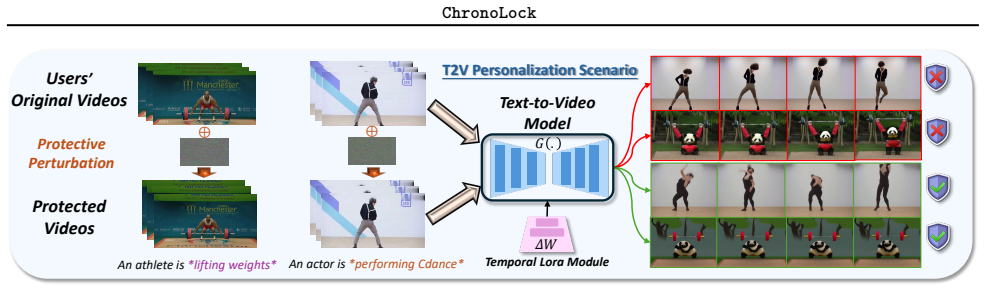
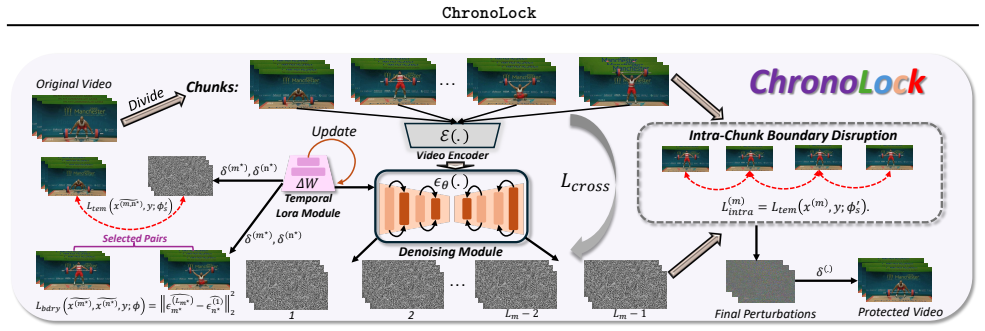
ChronoLock is the first framework that protects videos from unauthorized T2V personalization by optimizing bounded perturbations over temporal denoising trajectories. It disrupts intra-chunk temporal adaptation with a diffusion objective that combines fitting error, frame-relative denoising relations, and adjacent-frame variation, then enlarges inter-chunk boundary mismatch to weaken long-range motion continuity, using transformation-sampled updates for robustness. Experiments on UCF Sports and HMDB51 with popular T2V backbones and personalization schemes show reduced motion imitation under automatic metrics and human evaluation.
What carries the argument
Optimization of bounded perturbations over temporal denoising trajectories, which directly targets the motion-learning process in diffusion models by disrupting intra- and inter-chunk temporal relations.
If this is right
- Motion imitation success drops on standard action datasets under both automatic metrics and human raters.
- The same protection applies across multiple T2V backbones and personalization schemes.
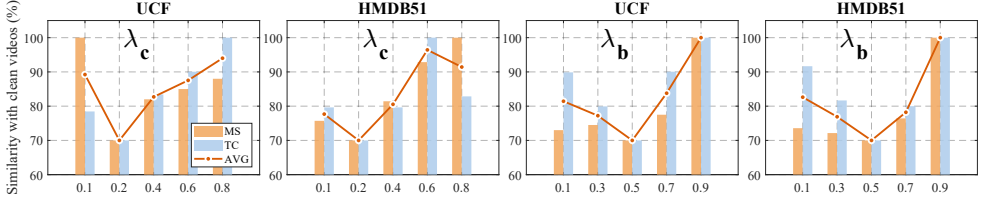
- Transformation-sampled updates increase resistance to typical video preprocessing steps.
- Disruption occurs at both short-range frame relations inside chunks and long-range continuity across chunks.
Where Pith is reading between the lines
- The same temporal-trajectory idea could be adapted to protect other time-series data from generative model misuse.
- Testing on videos longer than the chunks used in the experiments would reveal whether boundary mismatch scales.
- Layering ChronoLock with existing static-image protection methods might create combined defenses against hybrid attacks.
- The approach might generalize to non-diffusion video generators if their training also relies on sequential denoising steps.
Load-bearing premise
The perturbations optimized on temporal trajectories will remain effective against real-world T2V personalization pipelines after common preprocessing operations such as resizing or compression.
What would settle it
Fine-tuning a T2V model on ChronoLock-protected videos from UCF Sports and then measuring whether the generated outputs still achieve high motion similarity scores to the original clips under the same automatic metrics used in the paper.
Figures





read the original abstract
Text-to-video (T2V) diffusion models have made it increasingly easy to synthesize realistic and temporally coherent videos, while recent personalization techniques allow such models to imitate a specific subject, style, or motion pattern from only a few reference clips. This capability creates a new data-misuse risk: videos shared online can be collected and used for unauthorized T2V fine-tuning. Existing protective perturbations are mainly designed for image recognition or text-to-image personalization, and therefore focus on corrupting static appearance cues rather than the temporal denoising dynamics that make video personalization possible. To address this gap, we introduce ChronoLock, the first proactive protection framework that makes released videos difficult to exploit for unauthorized T2V personalization. ChronoLock targets the motion-learning process directly by optimizing bounded perturbations over temporal denoising trajectories. It first disrupts intra-chunk temporal adaptation with a diffusion objective that combines fitting error, frame-relative denoising relations, and adjacent-frame variation, and then enlarges inter-chunk boundary mismatch to weaken long-range motion continuity. Transformation-sampled updates further improve robustness to common preprocessing operations.Experiments on UCF Sports and HMDB51 with popular T2V backbones and personalization scheme show that ChronoLock effectively reduces motion imitation under automatic metrics and human evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ChronoLock, the first proactive protection framework against unauthorized text-to-video (T2V) personalization. It optimizes bounded perturbations over temporal denoising trajectories in diffusion models to disrupt motion learning: a combined diffusion objective targets intra-chunk temporal adaptation via fitting error, frame-relative denoising relations, and adjacent-frame variation, while enlarging inter-chunk boundary mismatch to weaken long-range continuity. Transformation-sampled updates are introduced to improve robustness to preprocessing. Experiments on UCF Sports and HMDB51 using popular T2V backbones and personalization schemes report reduced motion imitation under automatic metrics and human evaluation.
Significance. If the empirical results hold after addressing the robustness gap, the work is significant for addressing an emerging misuse vector in video sharing that prior image-centric protections do not target. It directly engages the temporal denoising dynamics of T2V models rather than static appearance cues, and the use of standard action datasets (UCF Sports, HMDB51) allows direct comparison to existing personalization pipelines.
major comments (1)
- [Abstract] Abstract (and Experiments section): the central claim that ChronoLock 'effectively reduces motion imitation' under real-world conditions rests on the unshown performance of transformation-sampled updates. No quantitative results are supplied on the distribution of sampled transformations, the drop in protection after resize/re-encode/frame-rate change, or post-preprocessing motion-imitation metrics on the same UCF Sports/HMDB51 splits. This assumption is load-bearing because any deployed video will undergo at least one such operation before an attacker fine-tunes.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for highlighting the importance of demonstrating robustness under realistic preprocessing. We agree that the current manuscript lacks the requested quantitative evaluation of transformation-sampled updates and will revise the paper to include these results.
read point-by-point responses
-
Referee: [Abstract] Abstract (and Experiments section): the central claim that ChronoLock 'effectively reduces motion imitation' under real-world conditions rests on the unshown performance of transformation-sampled updates. No quantitative results are supplied on the distribution of sampled transformations, the drop in protection after resize/re-encode/frame-rate change, or post-preprocessing motion-imitation metrics on the same UCF Sports/HMDB51 splits. This assumption is load-bearing because any deployed video will undergo at least one such operation before an attacker fine-tunes.
Authors: We agree that the manuscript does not currently report quantitative results on the distribution of sampled transformations or the resulting protection drop after common preprocessing steps (resize, re-encoding, frame-rate change). The transformation-sampling mechanism is described in Section 3.4, but its empirical impact is only summarized qualitatively. In the revised manuscript we will add a dedicated subsection (Experiments 4.4) that reports: (1) the empirical distribution over the sampled transformation set, (2) motion-imitation metrics (both automatic and human) on the identical UCF Sports and HMDB51 splits before and after each preprocessing operation, and (3) the corresponding drop in protection efficacy. These results will be presented in new tables and figures so that the robustness claim can be directly evaluated. revision: yes
Circularity Check
No circularity: method defines new objective without reducing to fitted inputs or self-citations
full rationale
The paper introduces ChronoLock as an optimization framework that directly defines a composite diffusion objective (fitting error + frame-relative denoising relations + adjacent-frame variation) plus inter-chunk mismatch enlargement, then applies transformation-sampled updates. These components are constructed as the protection mechanism itself rather than derived from or fitted to the claimed outcome metrics. No equations, uniqueness theorems, or predictions are presented that collapse back to the inputs by construction. Effectiveness claims rest on empirical evaluation on UCF Sports and HMDB51 rather than any self-referential derivation. The abstract and described approach contain no load-bearing self-citations or ansatzes smuggled from prior author work that would create circularity. This is the standard case of a self-contained empirical defense paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Kingma, Ben Poole, Mohammad Norouzi, David J
Jonathan Ho, William Chan, Chitwan Saharia, Jay Whang, Ruiqi Gao, Alexey Gritsenko, Diederik P. Kingma, Ben Poole, Mohammad Norouzi, David J. Fleet, and Tim Salimans. Imagen Video: High definition video generation with diffusion models.CoRR, abs/2210.02303, 2022
Pith/arXiv arXiv 2022
-
[2]
Make-A-Video: Text-to-video generation without text-video data
Uriel Singer, Adam Polyak, Thomas Hayes, Xi Yin, Jie An, Songyang Zhang, Qiyuan Hu, Harry Yang, Oron Ashual, Oran Gafni, Devi Parikh, Sonal Gupta, and Yaniv Taigman. Make-A-Video: Text-to-video generation without text-video data. InThe Eleventh International Conference on Learning Representations (ICLR). OpenReview.net, 2023
2023
-
[3]
Phenaki: Variable length video generation from open domain textual descriptions
Ruben Villegas, Mohammad Babaeizadeh, Pieter-Jan Kindermans, Hernan Moraldo, Han Zhang, Mohammad Taghi Saffar, Santiago Castro, Julius Kunze, and Dumitru Erhan. Phenaki: Variable length video generation from open domain textual descriptions. InThe Eleventh International Conference on Learning Representations (ICLR). OpenReview.net, 2023
2023
-
[4]
VideoCrafter1: Open diffusion models for high-quality video generation.CoRR, abs/2310.19512, 2023
Haoxin Chen, Menghan Xia, Yingqing He, Yong Zhang, Xiaodong Cun, Shaoshu Yang, Jinbo Xing, Yaofang Liu, Qifeng Chen, Xintao Wang, Chao Weng, and Ying Shan. VideoCrafter1: Open diffusion models for high-quality video generation.CoRR, abs/2310.19512, 2023
Pith/arXiv arXiv 2023
-
[5]
Tune-A-Video: One-shot tuning of image diffusion models for text-to-video generation
Jay Zhangjie Wu, Yixiao Ge, Xintao Wang, Stan Weixian Lei, Yuchao Gu, Yufei Shi, Wynne Hsu, Ying Shan, Xiaohu Qie, and Mike Zheng Shou. Tune-A-Video: One-shot tuning of image diffusion models for text-to-video generation. In2023 IEEE/CVF International Conference on Computer Vision (ICCV), pages 7589–7599. IEEE, 2023. 10 ChronoLock
2023
-
[6]
AnimateDiff: Animate your personalized text-to-image diffusion models without specific tuning
Yuwei Guo, Ceyuan Yang, Anyi Rao, Zhengyang Liang, Yaohui Wang, Yu Qiao, Maneesh Agrawala, Dahua Lin, and Bo Dai. AnimateDiff: Animate your personalized text-to-image diffusion models without specific tuning. InThe Twelfth International Conference on Learning Representations (ICLR). OpenReview.net, 2024
2024
-
[7]
Motiondirector: Motion customization of text-to-video diffusion models
Rui Zhao, Yuchao Gu, Jay Zhangjie Wu, David Junhao Zhang, Jia-Wei Liu, Weijia Wu, Jussi Keppo, and Mike Zheng Shou. Motiondirector: Motion customization of text-to-video diffusion models. InEuropean Conference on Computer Vision, pages 273–290. Springer, 2024
2024
-
[8]
Bermano, Gal Chechik, and Daniel Cohen-Or
Rinon Gal, Yuval Alaluf, Yuval Atzmon, Or Patashnik, Amit H. Bermano, Gal Chechik, and Daniel Cohen-Or. An image is worth one word: Personalizing text-to-image generation using textual inversion.CoRR, abs/2208.01618, 2022
Pith/arXiv arXiv 2022
-
[9]
Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein, and Kfir Aberman. DreamBooth: Fine tuning text-to-image diffusion models for subject-driven generation.CoRR, abs/2208.12242, 2023
arXiv 2023
-
[10]
Unlearnable examples: Making personal data unexploitable.CoRR, abs/2101.04898, 2021
Hanxun Huang, Xingjun Ma, Sarah Monazam Erfani, James Bailey, and Yisen Wang. Unlearnable examples: Making personal data unexploitable.CoRR, abs/2101.04898, 2021
arXiv 2021
-
[11]
A survey on unlearnable data.arXiv preprint arXiv:2503.23536, 2025
Jiahao Li, Yiqiang Chen, Yunbing Xing, Yang Gu, and Xiangyuan Lan. A survey on unlearnable data.arXiv preprint arXiv:2503.23536, 2025
arXiv 2025
-
[12]
Detecting and corrupting convolution-based unlearnable examples
Minghui Li, Xianlong Wang, Zhifei Yu, Shengshan Hu, Ziqi Zhou, Longling Zhang, and Leo Yu Zhang. Detecting and corrupting convolution-based unlearnable examples. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 18403–18411, 2025
2025
-
[13]
Yifan Zhu, Yibo Miao, Yinpeng Dong, and Xiao-Shan Gao. Why do unlearnable examples work: A novel perspective of mutual information.arXiv preprint arXiv:2603.03725, 2026
arXiv 2026
-
[14]
Unlearnable 3d point clouds: Class-wise transformation is all you need.Advances in Neural Information Processing Systems, 37:99404–99432, 2024
Xianlong Wang, Minghui Li, Wei Liu, Hangtao Zhang, Shengshan Hu, Yechao Zhang, Ziqi Zhou, and Hai Jin. Unlearnable 3d point clouds: Class-wise transformation is all you need.Advances in Neural Information Processing Systems, 37:99404–99432, 2024
2024
-
[15]
William Xu, Yiwei Lu, Yihan Wang, Matthew YR Yang, Zuoqiu Liu, Gautam Kamath, and Yaoliang Yu. Not all samples are equal: Quantifying instance-level difficulty in targeted data poisoning.arXiv preprint arXiv:2509.06896, 2025
Pith/arXiv arXiv 2025
-
[16]
Shawn Shan, Emily Wenger, Jiayun Zhang, Huiying Li, Haitao Zheng, and Ben Y. Zhao. Fawkes: Protecting privacy against unauthorized deep learning models.CoRR, abs/2002.08327, 2020
arXiv 2002
-
[17]
Dickerson, Gavin Taylor, and Tom Goldstein
Valeriia Cherepanova, Micah Goldblum, Harrison Foley, Shiyuan Duan, John P. Dickerson, Gavin Taylor, and Tom Goldstein. LowKey: Leveraging adversarial attacks to protect social media users from facial recognition. In9th International Conference on Learning Representations (ICLR). OpenReview.net, 2021
2021
-
[18]
Shawn Shan, Jenna Cryan, Emily Wenger, Haitao Zheng, Rana Hanocka, and Ben Y. Zhao. Glaze: Protecting artists from style mimicry by text-to-image models.CoRR, abs/2302.04222, 2023
arXiv 2023
-
[19]
Tran, and Anh Tran
Thanh Van Le, Hao Phung, Thuan Hoang Nguyen, Quan Dao, Ngoc N. Tran, and Anh Tran. Anti-DreamBooth: Protecting users from personalized text-to-image synthesis. In2023 IEEE/CVF International Conference on Computer Vision (ICCV), pages 2116–2127. IEEE, 2023
2023
-
[20]
Shawn Shan, Wenxin Ding, Josephine Passananti, Stanley Wu, Haitao Zheng, and Ben Y. Zhao. Nightshade: Prompt-specific poisoning attacks on text-to-image generative models. In2024 IEEE Symposium on Security and Privacy (SP), pages 807–825. IEEE, 2024
2024
-
[21]
Disrupting diffusion: Token-level attention erasure attack against diffusion-based customization
Yisu Liu, Jinyang An, Wanqian Zhang, Dayan Wu, Jingzi Gu, Zheng Lin, and Weiping Wang. Disrupting diffusion: Token-level attention erasure attack against diffusion-based customization. In Proceedings of the 32nd ACM International Conference on Multimedia, pages 3587–3596. ACM, 2024. 11 ChronoLock
2024
-
[22]
MetaCloak: Pre- venting unauthorized subject-driven text-to-image diffusion-based synthesis via meta-learning
Yixin Liu, Chenrui Fan, Yutong Dai, Xun Chen, Pan Zhou, and Lichao Sun. MetaCloak: Pre- venting unauthorized subject-driven text-to-image diffusion-based synthesis via meta-learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 24219–24228, 2024
2024
-
[23]
Videorefer suite: Advancing spatial-temporal object understanding with video llm
Yuqian Yuan, Hang Zhang, Wentong Li, Zesen Cheng, Boqiang Zhang, Long Li, Xin Li, Deli Zhao, Wenqiao Zhang, Yueting Zhuang, et al. Videorefer suite: Advancing spatial-temporal object understanding with video llm. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 18970–18980, 2025
2025
-
[24]
Timerefine: Temporal grounding with time refining video llm
Xizi Wang, Feng Cheng, Ziyang Wang, Huiyu Wang, Md Mohaiminul Islam, Lorenzo Torresani, Mohit Bansal, Gedas Bertasius, and David Crandall. Timerefine: Temporal grounding with time refining video llm. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 5067–5078, 2026
2026
-
[25]
Star: Spatial-temporal augmentation with text-to-video models for real-world video super-resolution
Rui Xie, Yinhong Liu, Penghao Zhou, Chen Zhao, Jun Zhou, Kai Zhang, Zhenyu Zhang, Jian Yang, Zhenheng Yang, and Ying Tai. Star: Spatial-temporal augmentation with text-to-video models for real-world video super-resolution. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 17108–17118, 2025
2025
-
[26]
Shira Schiber, Ofir Lindenbaum, and Idan Schwartz. Tempocontrol: Temporal attention guidance for text-to-video models.arXiv preprint arXiv:2510.02226, 2025
arXiv 2025
-
[27]
TEAR: Temporal-aware automated red-teaming for text-to-video models
Jiaming He, Guanyu Hou, Hongwei Li, Zhicong Huang, Kangjie Chen, Yi Yu, Wenbo Jiang, Guowen Xu, and Tianwei Zhang. TEAR: Temporal-aware automated red-teaming for text-to-video models. CoRR, abs/2511.21145, 2026
arXiv 2026
-
[28]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models.CoRR, abs/2106.09685, 2021
Pith/arXiv arXiv 2021
-
[29]
Towards deep learning models resistant to adversarial attacks
Aleksander Madry, Aleksandar Makelov, Ludwig Schmidt, Dimitris Tsipras, and Adrian Vladu. Towards deep learning models resistant to adversarial attacks. In6th International Conference on Learning Representations (ICLR). OpenReview.net, 2018
2018
-
[30]
Action mach a spatio-temporal maximum average correlation height filter for action recognition
Mikel D Rodriguez, Javed Ahmed, and Mubarak Shah. Action mach a spatio-temporal maximum average correlation height filter for action recognition. In2008 IEEE conference on computer vision and pattern recognition, pages 1–8. IEEE, 2008
2008
-
[31]
Hmdb: A large video database for human motion recognition
Hilde Kuehne, Hueihan Jhuang, Estíbaliz Garrote, Tomaso Poggio, and Thomas Serre. Hmdb: A large video database for human motion recognition. InProceedings of the IEEE International Conference on Computer Vision (ICCV), pages 2556–2563, 2011
2011
-
[32]
Zeroscope.https://huggingface.co/cerspense/zeroscope_v2_576w, 2023
Spencer Sterling. Zeroscope.https://huggingface.co/cerspense/zeroscope_v2_576w, 2023
2023
-
[33]
Mod- elscope text-to-video technical report.arXiv preprint arXiv:2308.06571, 2023
Jiuniu Wang, Hangjie Yuan, Dayou Chen, Yingya Zhang, Xiang Wang, and Shiwei Zhang. Mod- elscope text-to-video technical report.arXiv preprint arXiv:2308.06571, 2023
Pith/arXiv arXiv 2023
-
[34]
Vbench: Comprehensive benchmark suite for video generative models
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, et al. Vbench: Comprehensive benchmark suite for video generative models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21807–21818, 2024
2024
-
[35]
a woman is dancing
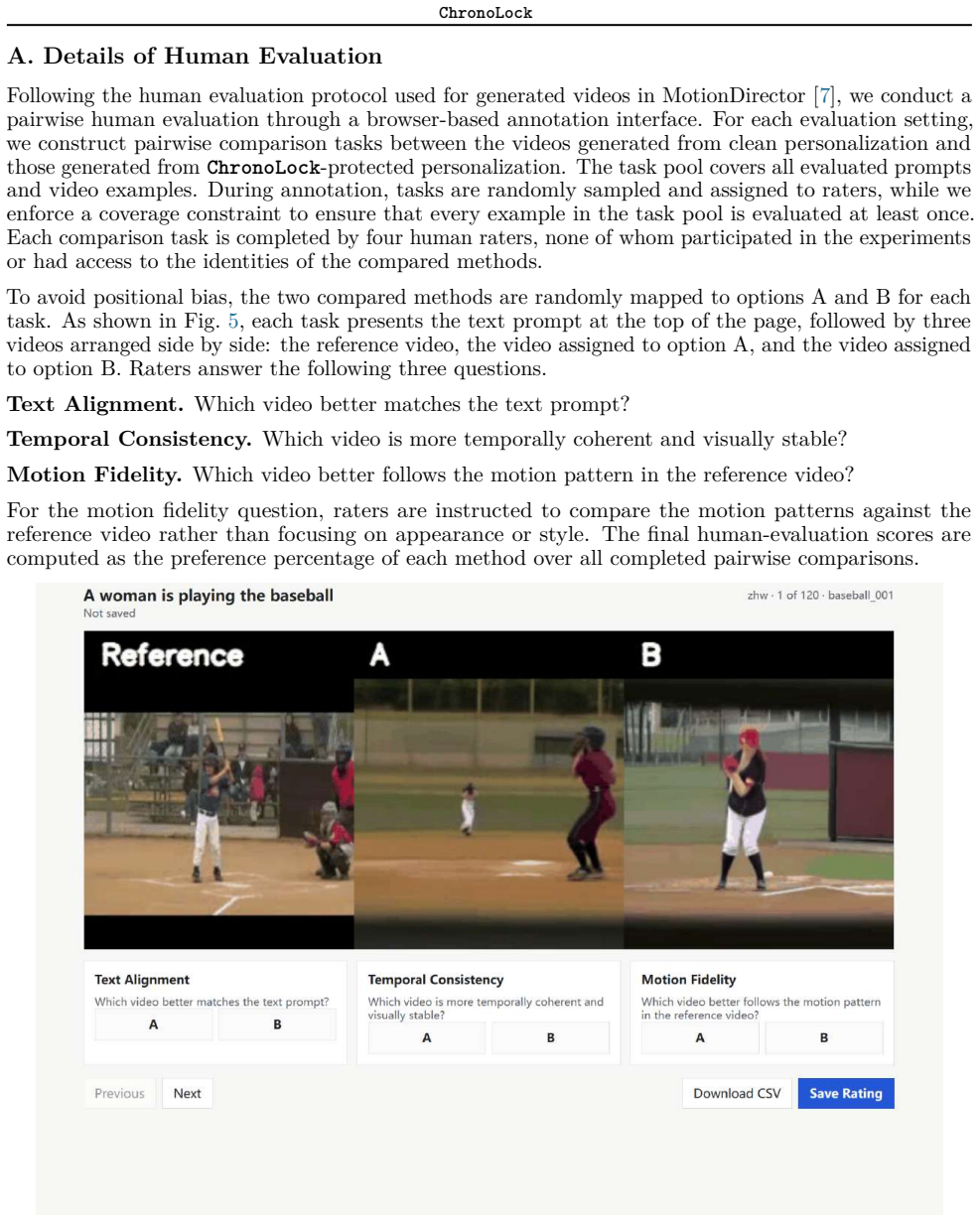
Hui Han, Siyuan Li, Jiaqi Chen, Yiwen Yuan, Yuling Wu, Yufan Deng, Chak Tou Leong, Hanwen Du, Junchen Fu, Youhua Li, et al. Video-bench: Human-aligned video generation benchmark. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 18858–18868, 2025. 12 ChronoLock A. Details of Human Evaluation Following the human evaluation pro...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.