Towards Data-free and Training-free Compression for Speech Foundation Models Using Parameter Clustering
Pith reviewed 2026-06-27 08:22 UTC · model grok-4.3
The pith
Channel-wise k-means clustering enables data-free compression of speech models that outperforms magnitude-based pruning on HuBERT and Whisper.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Channel-wise k-means clustering on model parameters produces pruned speech foundation models whose downstream word error rates on LibriSpeech are substantially lower than those obtained by magnitude-based pruning at the same sparsity levels, while remaining within a small margin of the original uncompressed models.
What carries the argument
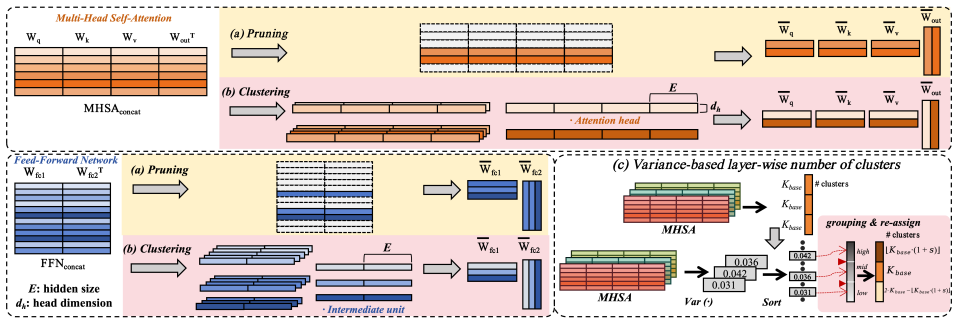
Channelwise k-means clustering that groups parameters within each channel to decide which to retain or remove, with the option to use a different number of clusters per layer for mixed sparsity.
If this is right
- The same clustering procedure can be applied to other speech foundation models to obtain compressed versions without data access.
- Varying the number of clusters per layer allows precise control over the final model size while preserving accuracy better than uniform pruning.
- Only a few epochs of fine-tuning are needed to bring the pruned model close to the original performance.
- The method works at both high (50 percent) and low (10 percent) sparsity targets on different model scales.
Where Pith is reading between the lines
- The clustering may capture redundancy patterns that are common across transformer-based audio models, suggesting the approach could transfer to other sequence models.
- Because no data is required, the technique could be used on proprietary or regulated speech models where training data cannot be shared.
- Combining the pruning step with post-training quantization might produce even smaller models while retaining the observed accuracy advantage.
Load-bearing premise
That channel-wise k-means clustering on model parameters can be performed without any data or training while still producing a compressed model whose downstream performance is meaningfully better than magnitude-based pruning.
What would settle it
A head-to-head measurement of word error rate on LibriSpeech test-clean and test-other for HuBERT-large at exactly 50 percent sparsity using the k-means method versus magnitude pruning, reported both before any fine-tuning and after three epochs.
Figures
read the original abstract
This paper presents a novel data-free and training-free compression approach for speech foundation models using channelwise clustering via k-means. More fine-grained, mixed sparsity pruning by layer-level varying number of parameter clusters is also explored. Experiments conducted on the LibriSpeech dataset suggest that when operating with pruning sparsity of 50% on HuBERT-large, consistent WER reductions of 27.73%/18.61% absolute (34.37%/21.91% relative) over the magnitude-based pruning were obtained on the test-clean and test-other subsets before fine-tuning and 0.19%/0.79% absolute (3.36%/4.62% relative) after fine-tuning with only 3 epochs. Similar WER reductions of 2.86%/5.02% absolute (59.21%/55.29% relative) were observed against magnitudebased pruning on Whisper-large-v3 at 10% sparsity, all with no significant WER increase relative to the uncompressed baseline.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce a data-free and training-free compression technique for speech foundation models via channel-wise k-means clustering of parameters, enabling mixed per-layer sparsity by varying the number of retained clusters. On LibriSpeech, it reports large absolute WER reductions versus magnitude-based pruning (27.73%/18.61% on HuBERT-large at 50% sparsity before fine-tuning; 2.86%/5.02% on Whisper-large-v3 at 10% sparsity), with post-fine-tuning gains and no significant degradation from the uncompressed baseline.
Significance. If the central claim holds, the approach would be significant for enabling practical compression of large speech models without access to data or additional training compute, particularly given the reported pre-fine-tuning gains at high sparsity.
major comments (2)
- [Method] The mapping from channel-wise k-means clusters to the final pruned parameter set at a fixed target sparsity is not specified. It is unclear whether clusters are pruned by centroid magnitude, by retaining a variable number of clusters per channel to meet the sparsity budget, or by another rule; without this, the source of the reported gains over magnitude pruning cannot be isolated from the mixed sparsity schedule itself.
- [Method] No details are provided on k-means initialization, distance metric, convergence criteria, or the exact procedure for choosing the per-layer number of clusters to achieve the stated sparsity levels. These omissions make the method non-reproducible and undermine evaluation of whether the clustering itself drives the WER improvements.
minor comments (2)
- [Abstract] Abstract contains the typo 'magnitudebased' (should be 'magnitude-based').
- [Abstract] The abstract reports specific WER numbers but does not indicate whether results are from single runs or averaged, nor whether statistical significance testing was performed.
Simulated Author's Rebuttal
We thank the referee for the careful review and constructive feedback. We address the two major comments below and will revise the manuscript accordingly to improve clarity and reproducibility.
read point-by-point responses
-
Referee: [Method] The mapping from channel-wise k-means clusters to the final pruned parameter set at a fixed target sparsity is not specified. It is unclear whether clusters are pruned by centroid magnitude, by retaining a variable number of clusters per channel to meet the sparsity budget, or by another rule; without this, the source of the reported gains over magnitude pruning cannot be isolated from the mixed sparsity schedule itself.
Authors: We agree that the exact mapping procedure requires explicit description. The manuscript states that mixed sparsity is achieved by varying the number of retained clusters per layer, but does not detail the within-channel selection rule or how the per-layer cluster counts are computed to hit the exact target sparsity. The revised version will add a dedicated paragraph (or subsection) specifying this mapping, including the selection criterion and allocation strategy, along with an ablation isolating the clustering contribution from the mixed-sparsity schedule. revision: yes
-
Referee: [Method] No details are provided on k-means initialization, distance metric, convergence criteria, or the exact procedure for choosing the per-layer number of clusters to achieve the stated sparsity levels. These omissions make the method non-reproducible and undermine evaluation of whether the clustering itself drives the WER improvements.
Authors: We concur that these hyperparameters and algorithmic choices must be stated for reproducibility. The revised manuscript will document the k-means settings (initialization, distance metric, convergence criteria) and the precise rule used to select the number of clusters per layer from the target sparsity. These additions will enable independent verification of the results and clearer attribution of performance gains to the clustering method. revision: yes
Circularity Check
No significant circularity; empirical compression method benchmarked on external test sets
full rationale
The paper proposes a data-free, training-free pruning method via channel-wise k-means clustering with per-layer cluster counts chosen to meet target sparsity, then reports measured WER on LibriSpeech test-clean/test-other against magnitude pruning. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text; the central claims are empirical deltas on held-out data, not reductions to inputs by construction. This is the normal non-circular outcome for an algorithmic method paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Introduction Recent advances in speech technology have been driven by speech foundation models, including self-supervised learn- ing (SSL) models such as wav2vec2.0 [1], HuBERT [2] and WavLM [3], as well as the supervised learning models such as Whisper [4], all of which significantly boost automatic speech recognition (ASR) performance. Despite these adv...
-
[2]
Neglecting the similarity between parameters.Exist- ing importance-based pruning methods [26, 28, 29] evaluate the importance of each component in isolation. Consequently, even when two high-importance weights are functionally redundant, these methods fail to prune either of them.2) Heavy reliance on raw data and fine-tuning.This reliance can evolve into ...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
Ar- chitecturally, HuBERT comprises a CNN feature extractor, a Transformer encoder, a projection layer, and a code embed- ding layer
HuBERT and Whisper Speech Models Self-supervised learning (SSL) speech models such as Hu- BERT [2] and WavLM [3], alongside the weakly-supervised, multi-lingual Whisper [4], rely on Transformer backbones that account for the vast majority of their total parameters. Ar- chitecturally, HuBERT comprises a CNN feature extractor, a Transformer encoder, a proje...
-
[4]
Magnitude-based Pruning Magnitude-based pruning removes parameters based on the principle that those with smaller magnitudes contribute less to the model’s performance. When applying it tostructured units like attention heads or intermediate units, their importance is evaluated by thesum ofL 2-magnitudes(hereinafter referred to as theL2-norm), where∥·∥ 2 ...
-
[5]
Parameter Clustering 4.1. Structured compression using parameter clustering Unlike pruning, which permanently discards parameters,pa- rameter clusteringreduces the model size by merging simi- lar structured units within Attention and FFN modules. A key advantage of our approach is itsdata-free and training-free nature. For each module, thetarget countK= r...
-
[6]
Experiments 5.1. Experimental setup Uncompressed baselines and data.For HuBERT-large, we fine-tuned HuBERT-large-ll60k2 for 20 epochs as our baseline, with other setups consistent with those inPost-clustering fine- tuning. For Whisper-large, we downloaded Whisper-large-v33 as our baseline. All systems are evaluated on the LibriSpeech dev and test datasets...
-
[7]
1, for HuBERT-largeat uniform sparsity of 30% or higher, our method outperforms MP on all subsets (e.g., ID 11 vs
Comparison with Magnitude-based Pruning (MP):As shown in Tab. 1, for HuBERT-largeat uniform sparsity of 30% or higher, our method outperforms MP on all subsets (e.g., ID 11 vs. ID 9). An average absolute reduction in WER on all subsets of 23.50% is observed against MP at 50% sparsity (ID 19 vs. ID 17). For Whisper-large-v3shown in Tab. 2, our method signi...
-
[8]
1, the mixed sparsity strategy improves the performance of the compressed model across the sparsity range from 10% to 50% (e.g., ID 10 vs
Comparison between uniform and mixed sparsity: Furthermore, for HuBERT-largeshown in Tab. 1, the mixed sparsity strategy improves the performance of the compressed model across the sparsity range from 10% to 50% (e.g., ID 10 vs. ID 9; ID 12 vs. ID 11). However, a performance degrada- tion is observed at 60% sparsity for both MP and our method. We hypothes...
-
[9]
Comparison with magnitude-based pruning (MP):As shown in Tab. 1, at sparsity of 50% or higher, fine-tuned HuBERT-largewith our method significantly outperforms MP on the twoothersubsets, while performing on par with or better than MP on the twocleansubsets (e.g., ID 23 vs. ID 21; ID 24 vs. ID 22). Our method achieves absolute WER reductions of up to 0.19%...
-
[10]
Comparison between uniform and mixed sparsity: For HuBERT-largein Tab. 1, at sparsity of 20% or higher, the models with mixed sparsity consistently outperform their uni- form sparsity counterparts at all sparsity levels after fine-tuning, regardless of whether our method or MP is used (e.g., ID 22 vs. Table 1:WER (↓) Comparison between parameter clusterin...
-
[11]
A variance-based strategy to re-assign layer-wise sparsity is also explored
Conclusion We introduce a novel compression method for speech founda- tion models that utilizes parameter clustering as a data-free and training-free alternative to pruning. A variance-based strategy to re-assign layer-wise sparsity is also explored. Experimen- tal results demonstrate that our method outperforms magnitude- based pruning and achieves resul...
-
[12]
These tools were not used to generate core scientific ideas, experimental data, or technical contributions
Generative AI Use Disclosure During the preparation of this manuscript, the authors used generative AI tools solely to edit the language and polish the manuscript for better readability. These tools were not used to generate core scientific ideas, experimental data, or technical contributions. All authors have thoroughly reviewed and ap- proved the final ...
-
[13]
14200021 and 14200324
Acknowledgements This research is supported by Hong Kong RGC GRF grant No. 14200021 and 14200324
-
[14]
wav2vec 2.0: A framework for self-supervised learning of speech representa- tions,
A. Baevski, Y . Zhou, A. Mohamed, and M. Auli, “wav2vec 2.0: A framework for self-supervised learning of speech representa- tions,” inNeurIPS, 2020
2020
-
[15]
HuBERT: Self-supervised speech representation learning by masked prediction of hidden units,
W.-N. Hsu, B. Bolte, Y .-H. H. Tsai, K. Lakhotia, R. Salakhut- dinov, and A. Mohamed, “HuBERT: Self-supervised speech representation learning by masked prediction of hidden units,” IEEE/ACM T-ASLP, vol. 29, pp. 3451–3460, 2021
2021
-
[16]
WavLM: Large-scale self- supervised pre-training for full stack speech processing,
S. Chen, C. Wang, Z. Chen, Y . Wu, S. Liu, Z. Chen, J. Li, N. Kanda, T. Yoshioka, X. Xiaoet al., “WavLM: Large-scale self- supervised pre-training for full stack speech processing,”IEEE J-STSP, vol. 16, no. 6, pp. 1505–1518, 2022
2022
-
[17]
Robust speech recognition via large-scale weak su- pervision,
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust speech recognition via large-scale weak su- pervision,” inICML, 2023
2023
-
[18]
2-bit conformer quantization for automatic speech recog- nition,
O. Rybakov, P. Meadowlark, S. Ding, D. Qiu, J. Li, D. Rim, and Y . He, “2-bit conformer quantization for automatic speech recog- nition,” inInterspeech, 2023
2023
-
[19]
4-bit conformer with native quantization aware training for speech recognition,
S. Ding, P. Meadowlark, Y . He, L. Lew, S. Agrawal, and O. Ry- bakov, “4-bit conformer with native quantization aware training for speech recognition,” inInterspeech, 2022
2022
-
[20]
I- bert: Integer-only bert quantization,
S. Kim, A. Gholami, Z. Yao, M. W. Mahoney, and K. Keutzer, “I- bert: Integer-only bert quantization,” inInternational conference on machine learning. PMLR, 2021, pp. 5506–5518
2021
-
[21]
Effective and efficient mixed precision quantization of speech foundation models,
H. Xu, Z. Li, Z. Jin, H. Wang, Y . Chen, G. Li, M. Geng, S. Hu, J. Deng, and X. Liu, “Effective and efficient mixed precision quantization of speech foundation models,” inICASSP 2025 - 2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2025, pp. 1–5
2025
-
[22]
A model for every user and budget: Label-free and personalized mixed-precision quantiza- tion,
E. Fish, U. Michieli, and M. Ozay, “A model for every user and budget: Label-free and personalized mixed-precision quantiza- tion,” inInterspeech, 2023
2023
-
[23]
Towards One-bit ASR: Extremely Low-bit Conformer Quantization Using Co-training and Stochastic Preci- sion,
Z. Li, H. Xu, Z. Jin, L. Meng, T. Wang, H. Wang, Y . Chen, M. Cui, S. Hu, and X. Liu, “Towards One-bit ASR: Extremely Low-bit Conformer Quantization Using Co-training and Stochastic Preci- sion,” inInterspeech 2025, 2025, pp. 1973–1977
2025
-
[24]
Efficient conformer-based speech recognition with linear attention,
S. Li, M. Xu, and X.-L. Zhang, “Efficient conformer-based speech recognition with linear attention,” inAPSIPA ASC, 2021
2021
-
[25]
Lossless 4-bit quantization of architecture compressed conformer asr systems on the 300-hr switchboard corpus,
Z. Li, T. Wang, J. Deng, J. Xu, S. Hu, and X. Liu, “Lossless 4-bit quantization of architecture compressed conformer asr systems on the 300-hr switchboard corpus,” inInterspeech, 2023
2023
-
[26]
Unstructured pruning and low rank factorisation of self-supervised pre-trained speech models,
H. Wang and W.-Q. Zhang, “Unstructured pruning and low rank factorisation of self-supervised pre-trained speech models,”IEEE Journal of Selected Topics in Signal Processing, 2024
2024
-
[27]
DistillW2V2: A small and streaming wav2vec 2.0 based ASR model,
Y . Fu, Y . Kang, S. Cao, and L. Ma, “DistillW2V2: A small and streaming wav2vec 2.0 based asr model,”arXiv preprint arXiv:2303.09278, 2023
-
[28]
DistilHuBERT: Speech representation learning by layer-wise distillation of hidden-unit bert,
H.-J. Chang, S.-w. Yang, and H.-y. Lee, “DistilHuBERT: Speech representation learning by layer-wise distillation of hidden-unit bert,” inICASSP, 2022
2022
-
[29]
LightHuBERT: Lightweight and configurable speech representation learning with once-for-all hidden-unit bert,
R. Wang, Q. Bai, J. Ao, L. Zhou, Z. Xiong, Z. Wei, Y . Zhang, T. Ko, and H. Li, “LightHuBERT: Lightweight and configurable speech representation learning with once-for-all hidden-unit bert,” inInterspeech, 2022
2022
-
[30]
Deep ver- sus wide: An analysis of student architectures for task-agnostic knowledge distillation of self-supervised speech models,
T. Ashihara, T. Moriya, K. Matsuura, and T. Tanaka, “Deep ver- sus wide: An analysis of student architectures for task-agnostic knowledge distillation of self-supervised speech models,” inIn- terspeech, 2022
2022
-
[31]
FitHuBERT: Go- ing thinner and deeper for knowledge distillation of speech self- supervised learning,
Y . Lee, K. Jang, J. Goo, Y . Jung, and H. Kim, “FitHuBERT: Go- ing thinner and deeper for knowledge distillation of speech self- supervised learning,” inInterspeech, 2022
2022
-
[32]
One-pass multiple conformer and founda- tion speech systems compression and quantization using an all-in- one neural model,
Z. Li, H. Xu, T. Wang, S. Hu, Z. Jin, S. Hu, J. Deng, M. Cui, M. Geng, and X. Liu, “One-pass multiple conformer and founda- tion speech systems compression and quantization using an all-in- one neural model,” inInterspeech 2024, 2024, pp. 4503–4507
2024
-
[33]
Dy- namic sparsity neural networks for automatic speech recognition,
Z. Wu, D. Zhao, Q. Liang, J. Yu, A. Gulati, and R. Pang, “Dy- namic sparsity neural networks for automatic speech recognition,” inICASSP, 2021
2021
-
[34]
Layer pruning on demand with intermediate ctc,
J. Lee, J. Kang, and S. Watanabe, “Layer pruning on demand with intermediate ctc,” inInterspeech, 2021
2021
-
[35]
Sparsewav: Fast and ac- curate one-shot unstructured pruning for large speech foundation models,
T. Gu, B. Liu, H. Shao, and Y . Qian, “Sparsewav: Fast and ac- curate one-shot unstructured pruning for large speech foundation models,” inProc. Interspeech 2024, 2024, pp. 4498–4502
2024
-
[36]
Task- agnostic structured pruning of speech representation models,
H. Wang, S. Wang, W.-Q. Zhang, S. Hongbin, and Y . Wan, “Task- agnostic structured pruning of speech representation models,” in Interspeech 2023, 2023, pp. 231–235
2023
-
[37]
Accurate and structured pruning for efficient automatic speech recognition,
H. Jiang, L. L. Zhang, Y . Li, Y . Wu, S. Cao, T. Cao, Y . Yang, J. Li, M. Yang, and L. Qiu, “Accurate and structured pruning for efficient automatic speech recognition,” inInterspeech, 2023
2023
-
[38]
PADA: Pruning assisted domain adaptation for self-supervised speech representations,
V . S. Lodagala, S. Ghosh, and S. Umesh, “PADA: Pruning assisted domain adaptation for self-supervised speech representations,” in IEEE SLT, 2023
2023
-
[39]
Structured pruning of self-supervised pre-trained models for speech recogni- tion and understanding,
Y . Peng, K. Kim, F. Wu, P. Sridhar, and S. Watanabe, “Structured pruning of self-supervised pre-trained models for speech recogni- tion and understanding,” inICASSP, 2023
2023
-
[40]
Unfolding A Few Structures for The Many: Memory-Efficient Compression of Conformer and Speech Foundation Models ,
Z. Li, H. Xu, X. Xie, Z. Jin, T. Wang, and X. Liu, “Unfolding A Few Structures for The Many: Memory-Efficient Compression of Conformer and Speech Foundation Models ,” inInterspeech 2025, 2025, pp. 1978–1982
2025
-
[41]
Effective and Efficient One-pass Compression of Speech Foundation Models Using Sparsity-aware Self-pinching Gates,
H. Xu, Z. Li, Y . Chen, H. Wang, G. Li, M. Geng, C. Deng, and X. Liu, “Effective and Efficient One-pass Compression of Speech Foundation Models Using Sparsity-aware Self-pinching Gates,” inInterspeech 2025, 2025, pp. 1983–1987
2025
-
[42]
DPHuBERT: Joint distillation and pruning of self-supervised speech models,
Y . Peng, Y . Sudo, S. Muhammad, and S. Watanabe, “DPHuBERT: Joint distillation and pruning of self-supervised speech models,” inInterspeech, 2023
2023
-
[43]
Efficient pruning for large-scale seq2seq speech models without back-propagation,
T. Gu, B. Liu, and Y . Qian, “Efficient pruning for large-scale seq2seq speech models without back-propagation,” inICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2025, pp. 1–5
2025
-
[44]
Lib- riSpeech: an asr corpus based on public domain audio books,
V . Panayotov, G. Chen, D. Povey, and S. Khudanpur, “Lib- riSpeech: an asr corpus based on public domain audio books,” inICASSP, 2015
2015
-
[45]
Learning both weights and connections for efficient neural network,
S. Han, J. Pool, J. Tran, and W. Dally, “Learning both weights and connections for efficient neural network,”Advances in neural information processing systems, vol. 28, 2015
2015
-
[46]
Some statistical issues in the comparison of speech recognition algorithms,
L. Gillick and S. J. Cox, “Some statistical issues in the comparison of speech recognition algorithms,” inICASSP, 1989
1989
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.