Antaeus: Hunting Repository-Level Logic Vulnerabilities via Context-Grounded LLM Reasoning
Pith reviewed 2026-07-02 10:20 UTC · model grok-4.3
The pith
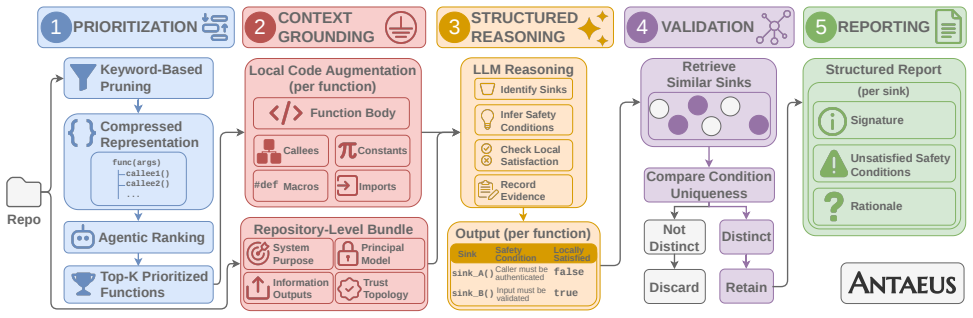
Antaeus detects logic vulnerabilities by grounding LLMs in repository-level context to infer implicit security invariants.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Antaeus follows a repository-scale pipeline combining function prioritization, context-grounded reasoning, comparative validation, and structured reporting. It ranks functions using lightweight repo-wide security signals, directs LLM analysis toward relevant code, and for each prioritized function combines local context with a repository-level view of functionality, security resources, and trust boundaries. This enables the model to identify security-sensitive sinks, derive safety conditions for safe execution, check local satisfaction of those conditions, prune findings that reflect project-wide norms, and report sinks, violated conditions, and supporting evidence.
What carries the argument
Repository-scale pipeline that supplies LLMs with both local function code and a repository-level view of functionality, security resources, and trust boundaries.
If this is right
- Detects and explains 15 vulnerabilities across the 28 evaluated repositories.
- Outperforms function-level and agentic models while using comparable token counts and cost.
- Reduces unnecessary LLM calls and triage effort through function prioritization and comparative validation.
- Produces traceable reports that list sinks, violated safety conditions, and evidence.
Where Pith is reading between the lines
- The same structured context and validation steps could be tested on semantic bugs outside the security domain.
- Prioritization and comparative filtering may prove more important than simply increasing raw context-window size.
- The pipeline suggests a general template for making LLM code reasoning respect project-wide norms rather than treating every file as independent.
Load-bearing premise
Supplying repository-level context enables frontier LLMs to reliably infer implicit, application-specific security invariants that are otherwise buried among unrelated code.
What would settle it
Running the system on the same 28 repositories and obtaining fewer than 15 detections or no improvement over function-level and agentic baselines despite the added context.
Figures
read the original abstract
LLM-based vulnerability detectors have shown promising results in identifying memory-safety bugs and vulnerability classes whose violations can often be expressed through established security properties. Logic vulnerabilities, however, pose a different challenge, as their identification requires inferring application-specific security invariants and implicit assumptions about intended behavior. Even frontier agentic models struggle because these invariants are often implicit and buried among unrelated code. Motivated by this gap, we present Antaeus, a framework for detecting logic vulnerabilities that grounds LLM reasoning in repository-level code context. Antaeus follows a repository-scale pipeline combining function prioritization, context-grounded reasoning, comparative validation, and structured reporting. It ranks functions using lightweight repo-wide security signals, directing costly LLM analysis toward relevant code and reducing calls, cost, and triage effort. For each prioritized function, Antaeus combines local code context with a repository-level view of the application's functionality, security resources, and trust boundaries. This enables reasoning about how the function is executed within the broader application rather than as an isolated snippet. Antaeus identifies security-sensitive sinks, derives safety conditions for safe execution, and checks whether they are locally satisfied. Candidate findings undergo comparative validation, pruning concerns that reflect project-wide norms rather than distinctive violations. Finally, Antaeus reports sinks, violated safety conditions, and evidence, making findings actionable and traceable. We evaluate Antaeus on 28 repositories with confirmed logic vulnerabilities and compare it against function-level and agentic models. Antaeus detects and explains 15 vulnerabilities, outperforming baselines with comparable token usage and cost.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Antaeus, a framework that combines function prioritization using repo-wide signals, context-grounded LLM reasoning over repository-level views of functionality and trust boundaries, comparative validation against project norms, and structured reporting to detect logic vulnerabilities. It evaluates the approach on 28 repositories containing confirmed logic vulnerabilities, reporting that Antaeus detects and explains 15 vulnerabilities while outperforming function-level and agentic baselines at comparable token usage and cost.
Significance. If the evaluation were strengthened with appropriate controls, the work could advance automated detection of application-specific logic vulnerabilities, a class that is difficult for both static analysis and isolated LLM prompting because it requires inferring implicit invariants. The pipeline design (prioritization to reduce LLM calls, repository-scale context, and comparative pruning) directly targets the limitations noted in the abstract for frontier models.
major comments (2)
- [Abstract] Abstract: The headline result states that Antaeus detects and explains 15 vulnerabilities across the 28 repositories, yet the abstract supplies no total count of vulnerabilities present in those repositories, no precision or recall figures, and no false-positive analysis on clean code or on repositories without known defects. These omissions make it impossible to evaluate whether the context-grounded pipeline reliably infers implicit invariants or merely surfaces already-known issues.
- [Abstract] Abstract: The 28 repositories were chosen precisely because they contain confirmed logic vulnerabilities. This design measures rediscovery performance rather than prospective detection in repositories without prior knowledge of defects, leaving the central claim—that repository-level context enables reliable inference of buried, application-specific security invariants—untested in the regime the method is intended to address.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our evaluation design and abstract. The comments highlight valid points about the scope of our results and the need for clearer reporting. We address each comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline result states that Antaeus detects and explains 15 vulnerabilities across the 28 repositories, yet the abstract supplies no total count of vulnerabilities present in those repositories, no precision or recall figures, and no false-positive analysis on clean code or on repositories without known defects. These omissions make it impossible to evaluate whether the context-grounded pipeline reliably infers implicit invariants or merely surfaces already-known issues.
Authors: We agree that the abstract would benefit from additional quantitative context. The full evaluation in Section 5 reports that Antaeus detected and explained 15 vulnerabilities across the 28 repositories, with all findings manually validated as true positives (yielding 100% precision on reported results). The total number of confirmed vulnerabilities in the repositories is provided in the evaluation setup, and recall is not reported because ground truth is limited to the known cases used for selection. We did not conduct separate experiments on clean repositories without known defects. We will revise the abstract to explicitly state these metrics and the evaluation scope, and add a limitations paragraph clarifying that the results demonstrate the pipeline's effectiveness at surfacing and explaining vulnerabilities via context rather than presupposing defect knowledge. revision: yes
-
Referee: [Abstract] Abstract: The 28 repositories were chosen precisely because they contain confirmed logic vulnerabilities. This design measures rediscovery performance rather than prospective detection in repositories without prior knowledge of defects, leaving the central claim—that repository-level context enables reliable inference of buried, application-specific security invariants—untested in the regime the method is intended to address.
Authors: We acknowledge that selecting repositories with confirmed vulnerabilities enables ground-truth comparison and measures rediscovery performance. This is a deliberate design choice common in vulnerability detection studies to rigorously assess whether the method can infer the relevant invariants from code context alone. The Antaeus pipeline has no access to vulnerability labels and operates only on repository signals, code, and LLM reasoning; the superior performance over function-level and agentic baselines supports the value of repository-scale context. We agree that prospective detection on repositories without prior defect knowledge would provide complementary evidence. We will revise the abstract and add a dedicated discussion subsection to explicitly frame the evaluation as a controlled study with ground truth and to note the challenges and limitations of prospective evaluation. revision: partial
Circularity Check
No significant circularity
full rationale
The paper describes an empirical LLM-based detection framework and reports results from running it on 28 pre-selected repositories containing known logic vulnerabilities. No equations, fitted parameters, predictions derived from subsets of data, or self-citation chains appear in the provided text. The detection count (15 vulnerabilities) is presented as a direct empirical outcome of the pipeline rather than a quantity defined by construction from the authors' inputs or prior work. The evaluation setup measures rediscovery on known cases but does not reduce any claimed result to a self-referential definition or fit.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Frontier LLMs can infer implicit application-specific security invariants when given repository-scale context
Reference graph
Works this paper leans on
-
[1]
Toward automated detection of logic vulnerabilities in web applications,
V . Felmetsger, L. Cavedon, C. Kruegel, and G. Vigna, “Toward automated detection of logic vulnerabilities in web applications,” in 19th USENIX Security Symposium (USENIX Security 10), 2010
2010
-
[2]
CWE-200: Exposure of Sensitive Information to an Unau- thorized Actor,
MITRE, “CWE-200: Exposure of Sensitive Information to an Unau- thorized Actor,” https://cwe.mitre.org/data/definitions/200.html, 2026, Common Weakness Enumeration
2026
-
[3]
CWE-284: Improper Access Control,
——, “CWE-284: Improper Access Control,” https://cwe.mitre.org/ data/definitions/284.html, 2026, Common Weakness Enumeration
2026
-
[4]
2025 CWE Top 25 Most Dangerous Software Weaknesses,
——, “2025 CWE Top 25 Most Dangerous Software Weaknesses,” https://cwe.mitre.org/top25/archive/2025/2025 cwe top25.html, 2025, Common Weakness Enumeration. Page last updated: December 15, 2025. Accessed: 2026-06-09
2025
-
[5]
CodeQL Documentation,
GitHub, “CodeQL Documentation,” https://codeql.github.com/docs/, accessed: 2026-05-18
2026
-
[6]
Semgrep Documentation,
Semgrep, “Semgrep Documentation,” https://semgrep.dev/docs/, accessed: 2026-05-18
2026
-
[7]
Logicscope: Automatic discovery of logic vul- nerabilities within web applications,
X. Li and Y . Xue, “Logicscope: Automatic discovery of logic vul- nerabilities within web applications,” inProceedings of the 8th ACM SIGSAC symposium on Information, computer and communications security, 2013, pp. 481–486
2013
-
[8]
Detecting logic vulnerabilities in e- commerce applications
F. Sun, L. Xu, and Z. Su, “Detecting logic vulnerabilities in e- commerce applications.” inNDSS, 2014
2014
-
[9]
Toward black-box detection of logic flaws in web applications
G. Pellegrino and D. Balzarotti, “Toward black-box detection of logic flaws in web applications.” inNDSS, vol. 14, 2014, pp. 23–26
2014
-
[10]
Detlogic: A black-box approach for detecting logic vulnerabilities in web applications,
G. Deepa, P. S. Thilagam, A. Praseed, and A. R. Pais, “Detlogic: A black-box approach for detecting logic vulnerabilities in web applications,”Journal of Network and Computer Applications, vol. 109, pp. 89–109, 2018
2018
-
[11]
RepoAudit: An autonomous LLM-agent for repository-level code auditing,
J. Guo, C. Wang, X. Xu, Z. Su, and X. Zhang, “Repoaudit: An autonomous llm-agent for repository-level code auditing,”arXiv preprint arXiv:2501.18160, 2025
-
[12]
Reasoning runtime behavior of a program with llm: How far are we?
J. Chen, Z. Pan, X. Hu, Z. Li, G. Li, and X. Xia, “Reasoning runtime behavior of a program with llm: How far are we?” in2025 IEEE/ACM 47th International Conference on Software Engineering (ICSE). IEEE, 2025, pp. 1869–1881
2025
-
[13]
Project Glasswing: Securing Critical Software for the AI Era,
Anthropic, “Project Glasswing: Securing Critical Software for the AI Era,” https://www.anthropic.com/project/glasswing, 2026, accessed: 2026-04
2026
-
[14]
Carlini, N
N. Carlini, N. Cheng, K. Lucas, M. Moore, M. Nasr, V . Prabhushankar, W. Xiao, H. Angulu, E. B. Asher, J. Bow, K. Bradwell, B. Buchanan, D. Forsythe, D. Freeman, A. Gaynor, X. Ge, L. Graham, K. Guru, H. Lakhani, M. McNiece, M. Mehrara, R. Nichol, A. Pirzada, S. Porter, A. Terzis, and K. Troy. Assessing claude mythos preview’s cybersecurity capabilities. [...
2026
-
[15]
Everything you wanted to know about llm-based vulnerability detec- tion but were afraid to ask,
Y . Li, X. Li, H. Wu, M. Xu, Y . Zhang, X. Cheng, F. Xu, and S. Zhong, “Everything you wanted to know about llm-based vulnerability detec- tion but were afraid to ask,”arXiv preprint arXiv:2504.13474, 2025
-
[16]
Llms cannot reliably identify and reason about security vulnera- bilities (yet?): A comprehensive evaluation, framework, and bench- marks,
S. Ullah, M. Han, S. Pujar, H. Pearce, A. Coskun, and G. Stringhini, “Llms cannot reliably identify and reason about security vulnera- bilities (yet?): A comprehensive evaluation, framework, and bench- marks,” in2024 IEEE symposium on security and privacy (SP). IEEE, 2024, pp. 862–880
2024
-
[17]
Benchmarking llms and llm-based agents in practical vulnerability detection for code repositories,
A. Yildiz, S. G. Teo, Y . Lou, Y . Feng, C. Wang, and D. M. Divakaran, “Benchmarking llms and llm-based agents in practical vulnerability detection for code repositories,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2025, pp. 30 848–30 865
2025
-
[18]
X. Zheng, A. Pesoli, M. Valleri, S. Jana, and L. Cavallaro, “Veritas: A semantically grounded agentic framework for memory corruption vulnerability detection in binaries,”arXiv preprint arXiv:2605.15097, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[19]
A. Pesoli, H. Errico, and L. Cavallaro, “Demystifying the mythos or disrupting bugonomics? from zero-day asymmetry to defender remediation throughput,”arXiv preprint arXiv:2605.24632, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[20]
Introducing claude opus 4.8,
Anthropic, “Introducing claude opus 4.8,” https://www.anthropic.co m/news/claude-opus-4-8, 2026
2026
-
[21]
Introducing gpt-5.4,
OpenAI, “Introducing gpt-5.4,” https://openai.com/index/introducing -gpt-5-4/, 2026
2026
-
[22]
Prompt-to-SQL Injections in LLM-Integrated Web Applications: Risks and Defenses ,
Y . Ding, Y . Fu, O. Ibrahim, C. Sitawarin, X. Chen, B. Alomair, D. Wagner, B. Ray, and Y . Chen, “Vulnerability detection with code language models: How far are we?” inProceedings of the IEEE/ACM 47th International Conference on Software Engineering, ser. ICSE ’25. IEEE Press, 2025, p. 1729–1741. [Online]. Available: https://doi.org/10.1109/ICSE55347.2025.00038
-
[23]
Language models don’t always say what they think: Unfaithful explanations in chain- of-thought prompting,
M. Turpin, J. Michael, E. Perez, and S. Bowman, “Language models don’t always say what they think: Unfaithful explanations in chain- of-thought prompting,”Advances in Neural Information Processing Systems, vol. 36, pp. 74 952–74 965, 2023
2023
-
[24]
Bugs as deviant behavior: a general approach to inferring errors in systems code,
D. Engler, D. Y . Chen, S. Hallem, A. Chou, and B. Chelf, “Bugs as deviant behavior: a general approach to inferring errors in systems code,” inProceedings of the Eighteenth ACM Symposium on Operating Systems Principles, ser. SOSP ’01. New York, NY , USA: Association for Computing Machinery, 2001, p. 57–72. [Online]. Available: https://doi.org/10.1145/502...
-
[25]
Chucky: exposing missing checks in source code for vulnerability discovery,
F. Yamaguchi, C. Wressnegger, H. Gascon, and K. Rieck, “Chucky: exposing missing checks in source code for vulnerability discovery,” inProceedings of the 2013 ACM SIGSAC Conference on Computer & Communications Security, ser. CCS ’13. New York, NY , USA: Association for Computing Machinery, 2013, p. 499–510. [Online]. Available: https://doi.org/10.1145/250...
-
[26]
Sok: Explainable machine learning for computer security applications,
A. Nadeem, D. V os, C. Cao, L. Pajola, S. Dieck, R. Baumgartner, and S. Verwer, “Sok: Explainable machine learning for computer security applications,” in2023 IEEE 8th European symposium on security and privacy (EuroS&P). IEEE, 2023, pp. 221–240
2023
-
[27]
Unixcoder: Unified cross-modal pre-training for code representation,
D. Guo, S. Lu, N. Duan, Y . Wang, M. Zhou, and J. Yin, “Unixcoder: Unified cross-modal pre-training for code representation,” inProceed- ings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2022, pp. 7212–7225
2022
-
[28]
Reposvul: A repository-level high-quality vulnerability dataset,
X. Wang, R. Hu, C. Gao, X.-C. Wen, Y . Chen, and Q. Liao, “Reposvul: A repository-level high-quality vulnerability dataset,” in Proceedings of the 2024 IEEE/ACM 46th International Conference on Software Engineering: Companion Proceedings, 2024, pp. 472–483
2024
-
[29]
Vul-rag: Enhancing llm-based vulnerability detection via knowledge-level rag,
X. Du, G. Zheng, K. Wang, Y . Zou, Y . Wang, W. Deng, J. Feng, M. Liu, B. Chen, X. Peng, T. Ma, and Y . Lou, “Vul-rag: Enhancing llm-based vulnerability detection via knowledge-level rag,”ACM Trans. Softw. Eng. Methodol., Feb. 2026, just Accepted. [Online]. Available: https://doi.org/10.1145/3797277
-
[30]
Llm-cloudsec: Large language model em- powered automatic and deep vulnerability analysis for intelligent clouds,
D. Cao and W. Jun, “Llm-cloudsec: Large language model em- powered automatic and deep vulnerability analysis for intelligent clouds,” inIEEE INFOCOM 2024 - IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), 2024, pp. 1–6
2024
-
[31]
Iris: Llm-assisted static analysis for detecting security vulnerabilities,
Z. Li, S. Dutta, and M. Naik, “Iris: Llm-assisted static analysis for detecting security vulnerabilities,” inInternational Conference on Learning Representations, vol. 2025, 2025, pp. 35 735–35 758
2025
-
[32]
Enhancing static analysis for practical bug detection: An llm-integrated approach,
H. Li, Y . Hao, Y . Zhai, and Z. Qian, “Enhancing static analysis for practical bug detection: An llm-integrated approach,”Proc. ACM Program. Lang., vol. 8, no. OOPSLA1, Apr. 2024. [Online]. Available: https://doi.org/10.1145/3649828
-
[33]
Interleaving static analysis and llm prompting,
P. J. Chapman, C. Rubio-Gonz ´alez, and A. V . Thakur, “Interleaving static analysis and llm prompting,” inProceedings of the 13th ACM SIGPLAN International Workshop on the State Of the Art in Program Analysis, 2024, pp. 9–17
2024
-
[34]
{LLMxCPG}:{Context-Aware}vulnerability detection through code property{Graph-Guided}large language models,
A. Lekssays, H. Mouhcine, K. Tran, T. Yu, and I. Khalil, “{LLMxCPG}:{Context-Aware}vulnerability detection through code property{Graph-Guided}large language models,” in34th USENIX Security Symposium (USENIX Security 25), 2025, pp. 489– 507
2025
-
[35]
From func- tion to repository: Towards repository-level evaluation of software vulnerability detection,
X.-C. Wen, X. Wang, Y . Chen, R. Hu, D. Lo, and C. Gao, “From func- tion to repository: Towards repository-level evaluation of software vulnerability detection,”IEEE Transactions on Software Engineering, 2026. Ethical Considerations This work focuses on the automated detection of logi- cal vulnerabilities in software repositories. Our benchmark consists e...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.