RaysUp: Ultra-light Universal Feature Upsampling via Geometry-Aware Ray Representation
Pith reviewed 2026-06-26 09:10 UTC · model grok-4.3
The pith
Feature upsampling from vision foundation models can be made ultra-lightweight and resolution-flexible by operating in a geometry-aware ray domain.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
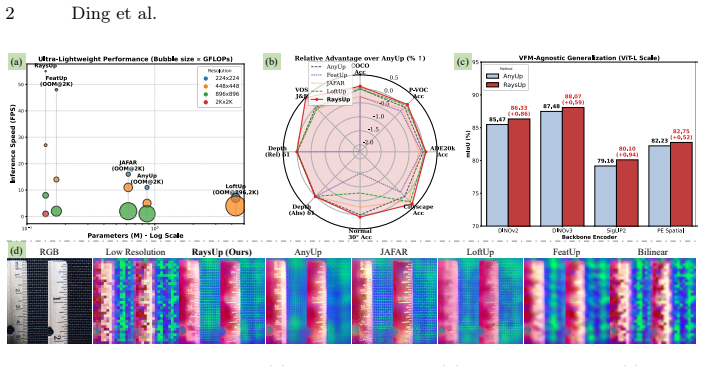
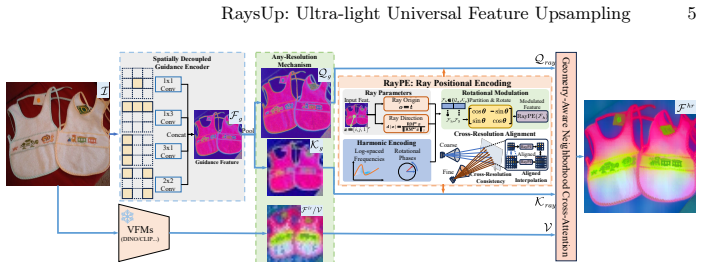
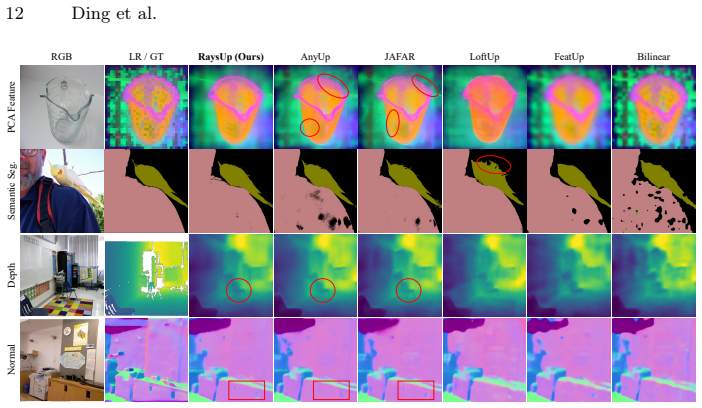
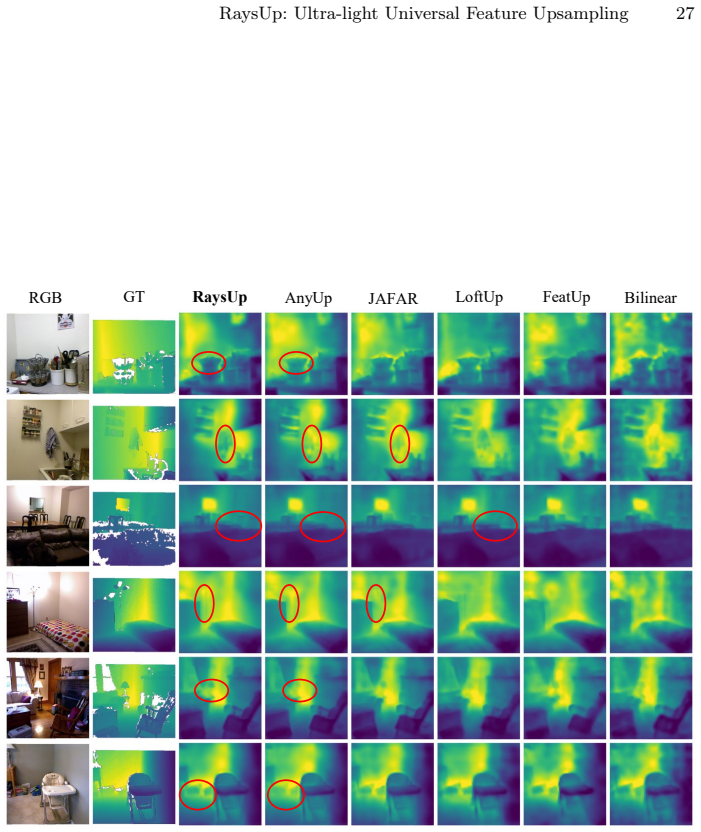
RaysUp is an ultra-lightweight, task-agnostic and VFM-agnostic framework that reconstructs high-resolution feature maps at arbitrary resolutions by lifting feature reconstruction into a geometry-aware ray domain. It introduces Ray Positional Encoding with 6D Plucker ray coordinates to inject implicit 3D geometric priors, a Spatially Decoupled Guidance Encoder for direction-aware guidance, Any-Resolution Cross-Attention for resolution-flexible reconstruction, and a Geometry-Aware Neighborhood Attention module for content-adaptive bilateral aggregation while preserving geometric consistency. Extensive experiments demonstrate that this yields state-of-the-art performance while using only 16% of
What carries the argument
Geometry-aware ray representation that encodes features via 6D Plucker ray coordinates to inject 3D geometric priors into the upsampling process.
If this is right
- Arbitrary-resolution feature maps can be produced without retraining the underlying vision foundation model.
- Semantic fidelity is maintained across multiple dense prediction tasks using a single set of weights.
- Parameter count and inference time drop substantially relative to prior universal upsamplers while accuracy improves.
- The same architecture works for any VFM output without architecture-specific adjustments.
Where Pith is reading between the lines
- The explicit 3D priors in the ray domain could reduce the need for learned positional encodings in other 2D vision modules.
- Lightweight ray-based reconstruction may enable on-device high-resolution inference for mobile dense prediction pipelines.
- The decoupled guidance and neighborhood attention patterns could be adapted to video or multi-view feature fusion.
Load-bearing premise
The ray-domain components deliver content-adaptive reconstruction that preserves semantic fidelity without VFM-specific retraining or task-dependent tuning.
What would settle it
Applying RaysUp to a previously unseen VFM on a dense prediction task and measuring whether semantic fidelity drops below that of a retrained baseline in fine-grained regions.
Figures






read the original abstract
Pre-trained Vision Foundation Models (VFMs) have become central to modern computer vision due to their powerful semantic representations and strong generalization ability. However, their patchified or pooled outputs are inherently low-resolution, limiting their effectiveness in tasks requiring fine-grained, pixel-level reasoning. Existing feature upsampling approaches either degrade semantic fidelity or rely on VFM-specific retraining and heavy architectures, hindering efficiency and scalability. To address these challenges, we propose RaysUp, an ultra-lightweight, task-agnostic, and VFM-agnostic feature upsampling framework that reconstructs high-resolution feature maps at arbitrary resolutions. Unlike conventional 2D interpolation or attention-based schemes, RaysUp lifts feature reconstruction into a geometry-aware ray domain. Specifically, we introduce a Spatially Decoupled Guidance Encoder for direction-aware guidance encoding, an Any-Resolution Cross-Attention mechanism for resolution-flexible reconstruction, and a novel Ray Positional Encoding (RayPE) that injects implicit 3D geometric priors via 6D Plucker ray coordinates. Finally, a Geometry-Aware Neighborhood Attention module further ensures content-adaptive bilateral aggregation while preserving geometric consistency. Extensive experiments across diverse dense prediction tasks demonstrate that RaysUp achieves state-of-the-art performance while using only 16% of the parameters of AnyUp and delivering approximately 7x faster inference. These results highlight a substantially improved accuracy-efficiency trade-off and establish RaysUp as a practical and scalable solution for universal feature upsampling. Code is available at https://github.com/MAP-RaysUp/RaysUp.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces RaysUp, an ultra-lightweight feature upsampling framework for pre-trained Vision Foundation Models (VFMs). It lifts low-resolution VFM outputs into a geometry-aware ray domain using a novel Ray Positional Encoding (RayPE) based on 6D Plucker coordinates, a Spatially Decoupled Guidance Encoder, Any-Resolution Cross-Attention, and Geometry-Aware Neighborhood Attention. The central claim is that this yields state-of-the-art accuracy-efficiency trade-offs across dense prediction tasks while using only 16% of AnyUp's parameters and running approximately 7x faster, all in a task- and VFM-agnostic manner without retraining.
Significance. If the performance claims and universality hold, RaysUp would offer a practical, scalable solution for high-resolution feature reconstruction in dense prediction, improving the accuracy-efficiency frontier without VFM-specific tuning. The introduction of ray-domain geometric priors is a potentially novel direction, though its independence from fitted parameters is not yet demonstrated.
major comments (1)
- [Abstract / RayPE description] Abstract and RayPE section: The 6D Plucker coordinates (direction d and moment m = o × d) in RayPE presuppose known camera intrinsics K and poses to compute normalized directions and moments from pixel coordinates. No mechanism is described for obtaining K or poses from arbitrary VFM feature maps alone, which directly contradicts the VFM-agnostic and task-agnostic claims; if the method silently assumes calibration or falls back to 2D approximations, the geometry-aware prior is not actually realized.
minor comments (1)
- [Abstract] The abstract asserts SOTA performance, 16% parameter count, and 7x speedup, but the provided text contains no quantitative tables, ablation studies, error bars, or dataset details, preventing direct evaluation of the central claims.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for identifying this point on the geometric encoding. We respond to the major comment below.
read point-by-point responses
-
Referee: [Abstract / RayPE description] Abstract and RayPE section: The 6D Plucker coordinates (direction d and moment m = o × d) in RayPE presuppose known camera intrinsics K and poses to compute normalized directions and moments from pixel coordinates. No mechanism is described for obtaining K or poses from arbitrary VFM feature maps alone, which directly contradicts the VFM-agnostic and task-agnostic claims; if the method silently assumes calibration or falls back to 2D approximations, the geometry-aware prior is not actually realized.
Authors: We agree that the manuscript should more explicitly state how camera parameters are obtained. RaysUp is applied to the original input images that accompany every VFM feature map in the evaluated dense-prediction benchmarks; camera intrinsics K and poses are taken from the dataset metadata (or estimated via standard calibration when absent) to compute the 6D Plucker rays before feature upsampling. This preprocessing step is independent of the VFM weights, preserving the VFM-agnostic property. In the revised manuscript we will expand the RayPE section with the explicit computation pipeline, pseudocode, and a short discussion of the assumption, thereby removing any ambiguity while leaving the core claims unchanged. revision: yes
Circularity Check
No significant circularity; architectural modules are independent contributions
full rationale
The paper presents RaysUp as a new framework with novel components (RayPE via 6D Plucker coordinates, Spatially Decoupled Guidance Encoder, Any-Resolution Cross-Attention, Geometry-Aware Neighborhood Attention) introduced as independent design choices for lifting feature reconstruction into a ray domain. No equations, predictions, or central claims in the abstract or described architecture reduce by construction to fitted parameters, self-citations, or renamed inputs. The derivation chain for task-agnostic upsampling relies on these explicitly defined modules without self-definitional loops or load-bearing self-citations. The method is self-contained against external benchmarks as a proposed architecture rather than a derived result from prior fitted values.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Plucker ray coordinates inject implicit 3D geometric priors suitable for 2D feature map reconstruction
invented entities (1)
-
Ray Positional Encoding (RayPE)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
In: CVPR
Asim, M., Wewer, C., Wimmer, T., Schiele, B., Lenssen, J.E.: MEt3R: Measuring Multi-View Consistency in Generated Images. In: CVPR. pp. 6034–6044 (2025)
2025
-
[2]
In: ICCV (2021)
Bae, G., Budvytis, I., Cipolla, R.: Estimating and Exploiting the Aleatoric Uncer- tainty in Surface Normal Estimation. In: ICCV (2021)
2021
-
[3]
In: ICCV
Barsellotti,L.,Bianchi,L.,Messina,N.,Carrara,F.,Cornia,M.,Baraldi,L.,Falchi, F., Cucchiara, R.: Talking to DINO: Bridging Self-Supervised Vision Backbones with Language for Open-Vocabulary Segmentation. In: ICCV. pp. 22025–22035 (2025)
2025
-
[4]
In: CVPR (2020)
Bhat, S.F., Alhashim, I., Wonka, P.: AdaBins: Depth Estimation Using Adaptive Bins. In: CVPR (2020)
2020
-
[5]
Perception Encoder: The best visual embeddings are not at the output of the network
Bolya, D., Huang, P.Y., Sun, P., Cho, J.H., Madotto, A., Wei, C., Ma, T., Zhi, J., Rajasegaran, J., Rasheed, H., et al.: Perception Encoder: The Best Visual Em- beddings Are Not at the Output of the Network. arXiv preprint arXiv:2504.13181 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
In: CVPR
Caesar, H., Uijlings, J., Ferrari, V.: COCO-Stuff: Thing and Stuff Classes in Con- text. In: CVPR. pp. 1209–1218 (2018)
2018
-
[7]
In: ICCV
Caron, M., Touvron, H., Misra, I., Jégou, H., Mairal, J., Bojanowski, P., Joulin, A.: Emerging Properties in Self-Supervised Vision Transformers. In: ICCV. pp. 9650–9660 (2021) 16 Ding et al
2021
-
[8]
In: CVPR
Chen, S., Guo, H., Zhu, S., Zhang, F., Huang, Z., Feng, J., Kang, B.: Video Depth Anything: Consistent Depth Estimation for Super-Long Videos. In: CVPR. pp. 22831–22840 (2025)
2025
-
[9]
In: NeurIPS (2025)
Chuang, Y.S., Li, Y., Wang, D., Yeh, C.F., Lyu, K., Raghavendra, R., Glass, J.R., HUANG, L., Weston, J.E., Zettlemoyer, L., Chen, X., Liu, Z., Xie, S., tau Yih, W., Li, S.W., Xu, H.: Meta CLIP 2: A Worldwide Scaling Recipe. In: NeurIPS (2025)
2025
-
[10]
In: CVPR
Cordts, M., Omran, M., Ramos, S., Rehfeld, T., Enzweiler, M., Benenson, R., Franke, U., Roth, S., Schiele, B.: The Cityscapes Dataset for Semantic Urban Scene Understanding. In: CVPR. pp. 3213–3223 (2016)
2016
-
[11]
In: NeurIPS (2025)
Couairon, P., Chambon, L., Serrano, L., HAUGEARD, J.E., Cord, M., THOME, N.: JAFAR: Jack up Any Feature at Any Resolution. In: NeurIPS (2025)
2025
-
[12]
In: CVPR
Dai, Y., Lu, H., Shen, C.: Learning Affinity-Aware Upsampling for Deep Image Matting. In: CVPR. pp. 6841–6850 (2021)
2021
-
[13]
In: CVPR
Deng, J., Dong, W., Socher, R., Li, L.J., Li, K., Fei-Fei, L.: ImageNet: A Large- Scale Hierarchical Image Database. In: CVPR. pp. 248–255 (2009)
2009
-
[14]
In: ICCV
Ding, X., Guo, Y., Ding, G., Han, J.: ACNet: Strengthening the Kernel Skeletons for Powerful CNN via Asymmetric Convolution Blocks. In: ICCV. pp. 1911–1920 (2019)
1911
-
[15]
In: CVPR
Ding, X., Zhang, X., Ma, N., Han, J., Ding, G., Sun, J.: RepVGG: Making VGG- style ConvNets Great Again. In: CVPR. pp. 13733–13742 (2021)
2021
-
[16]
Journal of Applied Meteorology18(8), 1016–1022 (1979)
Duchon, C.E.: Lanczos Filtering in One and Two Dimensions. Journal of Applied Meteorology18(8), 1016–1022 (1979)
1979
-
[17]
In: CVPR
El Banani, M., Raj, A., Maninis, K.K., Kar, A., Li, Y., Rubinstein, M., Sun, D., Guibas, L., Johnson, J., Jampani, V.: Probing the 3D Awareness of Visual Foundation Models. In: CVPR. pp. 21795–21806 (2024)
2024
-
[18]
Neural Networks107, 3–11 (2018)
Elfwing, S., Uchibe, E., Doya, K.: Sigmoid-Weighted Linear Units for Neural Net- work Function Approximation in Reinforcement Learning. Neural Networks107, 3–11 (2018)
2018
-
[19]
IJCV111(1), 98–136 (2015)
Everingham, M., Eslami, S.M., Gool, L., Williams, C.K., Winn, J., Zisserman, A.: The Pascal Visual Object Classes Challenge: A Retrospective. IJCV111(1), 98–136 (2015)
2015
-
[20]
In: ICLR (2024)
Fu, S., Hamilton, M., Brandt, L.E., Feldmann, A., Zhang, Z., Freeman, W.T.: FeatUp: A Model-Agnostic Framework for Features at Any Resolution. In: ICLR (2024)
2024
-
[21]
In: CVPR
Hassani,A.,Walton,S.,Li,J.,Li,S.,Shi,H.:NeighborhoodAttentionTransformer. In: CVPR. pp. 6185–6194 (2023)
2023
-
[22]
In: CVPR
He, K., Chen, X., Xie, S., Li, Y., Dollár, P., Girshick, R.: Masked Autoencoders Are Scalable Vision Learners. In: CVPR. pp. 16000–16009 (2022)
2022
-
[23]
In: ICCV (2025)
Huang, H., Chen, A., Havrylov, V., Geiger, A., Zhang, D.: LoftUp: Learning a Coordinate-Based Feature Upsampler for Vision Foundation Models. In: ICCV (2025)
2025
-
[24]
In: CVPR
Jose, C., Moutakanni, T., Kang, D., Baldassarre, F., Darcet, T., Xu, H., Li, D., Szafraniec, M., Ramamonjisoa, M., Oquab, M., et al.: DINOv2 Meets Text: A Unified Framework for Image- and Pixel-Level Vision-Language Alignment. In: CVPR. pp. 24905–24916 (2025)
2025
-
[25]
Splat: Directly Referring 3D Gaussian Splatting via Direct Language Embedding Regis- tration
Jun-Seong, K., Kim, G., Yu-Ji, K., Wang, Y.C.F., Choe, J., Oh, T.H.: Dr. Splat: Directly Referring 3D Gaussian Splatting via Direct Language Embedding Regis- tration. In: CVPR. pp. 14137–14146 (2025)
2025
-
[26]
In: ICCV
Kerr, J., Kim, C.M., Goldberg, K., Kanazawa, A., Tancik, M.: LERF: Language Embedded Radiance Fields. In: ICCV. pp. 19729–19739 (2023) RaysUp: Ultra-light Universal Feature Upsampling 17
2023
-
[27]
In: ICCV
Kirillov, A., Mintun, E., Ravi, N., Mao, H., Rolland, C., Gustafson, L., Xiao, T., Whitehead, S., Berg, A.C., Lo, W.Y., et al.: Segment Anything. In: ICCV. pp. 4015–4026 (2023)
2023
-
[28]
ACM Trans
Kopf, J., Cohen, M.F., Lischinski, D., Uyttendaele, M.: Joint Bilateral Upsampling. ACM Trans. Graph.26(3), 96 (2007)
2007
-
[29]
In: ECCV
Lan, M., Chen, C., Ke, Y., Wang, X., Feng, L., Zhang, W.: ProxyCLIP: Proxy Attention Improves CLIP for Open-Vocabulary Segmentation. In: ECCV. pp. 70– 88 (2024)
2024
-
[30]
In: ACM MM
Li, L., Zhang, L., Wang, Z., Shen, Y.: GS3LAM: Gaussian Semantic Splatting SLAM. In: ACM MM. p. 3019–3027 (2024)
2024
-
[31]
AAAI39(23), 24458–24466 (2025)
Li, L., Zhang, L., Wang, Z., Zhang, F., Li, Z., Shen, Y.: Representing sounds as neural amplitude fields: A benchmark of coordinate-mlps and a fourier kolmogorov- arnold framework. AAAI39(23), 24458–24466 (2025)
2025
-
[32]
In: ICLR (2026)
Lin, H., Chen, S., Liew, J.H., Chen, D.Y., Li, Z., Zhao, Y., Peng, S., Guo, H., Zhou, X., Shi, G., Feng, J., Kang, B.: Depth Anything 3: Recovering the Visual Space from Any Views. In: ICLR (2026)
2026
-
[33]
In: ICLR (2019)
Loshchilov, I., Hutter, F.: Decoupled Weight Decay Regularization. In: ICLR (2019)
2019
-
[34]
IEEE TPAMI44(1), 242–255 (2022)
Lu, H., Dai, Y., Shen, C., Xu, S.: Index Networks. IEEE TPAMI44(1), 242–255 (2022)
2022
-
[35]
In: ECCV
Lu, H., Liu, W., Fu, H., Cao, Z.: FADE: Fusing the Assets of Decoder and Encoder for Task-Agnostic Upsampling. In: ECCV. pp. 231–247 (2022)
2022
-
[36]
In: NeurIPS (2022)
Lu, H., Liu, W., Ye, Z., Fu, H., Liu, Y., Cao, Z.: SAPA: Similarity-Aware Point Affiliation for Feature Upsampling. In: NeurIPS (2022)
2022
-
[37]
College of the Redwoods 45(1), 1049–1060 (1998)
McKinley, S., Levine, M.: Cubic Spline Interpolation. College of the Redwoods 45(1), 1049–1060 (1998)
1998
-
[38]
In: ECCV
Mildenhall, B., Srinivasan, P.P., Tancik, M., Barron, J.T., Ramamoorthi, R., Ng, R.: NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis. In: ECCV. pp. 405–421 (2020)
2020
-
[39]
TMLR (2024)
Oquab, M., Darcet, T., Moutakanni, T., Vo, H.V., Szafraniec, M., Khalidov, V., Fernandez, P., Haziza, D., Massa, F., El-Nouby, A., Assran, M., Ballas, N., Galuba, W., Howes, R., Huang, P., Li, S., Misra, I., Rabbat, M., Sharma, V., Synnaeve, G., Xu, H., Jégou, H., Mairal, J., Labatut, P., Joulin, A., Bojanowski, P.: DINOv2: Learning Robust Visual Features...
2024
-
[40]
The 2017 DAVIS Challenge on Video Object Segmentation
Pont-Tuset, J., Perazzi, F., Caelles, S., Arbeláez, P., Sorkine-Hornung, A., Van Gool, L.: The 2017 DAVIS Challenge on Video Object Segmentation. arXiv preprint arXiv:1704.00675 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[41]
In: CVPR
Qin, M., Li, W., Zhou, J., Wang, H., Pfister, H.: LangSplat: 3D Language Gaussian Splatting. In: CVPR. pp. 20051–20060 (2024)
2024
-
[42]
In: ICML
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., Sutskever, I.: Learning Transfer- able Visual Models from Natural Language Supervision. In: ICML. pp. 8748–8763 (2021)
2021
-
[43]
In: ICLR (2021)
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., Sutskever, I.: Learning transferable visual models from natural language supervision. In: ICLR (2021)
2021
-
[44]
In: ICCV (2021)
Ranftl, R., Bochkovskiy, A., Koltun, V.: Vision Transformers for Dense Prediction. In: ICCV (2021)
2021
-
[45]
NeurIPS37, 9153–9177 (2024) 18 Ding et al
Shin, H., Kim, C., Hong, S., Cho, S., Arnab, A., Seo, P.H., Kim, S.: Towards Open-Vocabulary Semantic Segmentation Without Semantic Labels. NeurIPS37, 9153–9177 (2024) 18 Ding et al
2024
-
[46]
In: ECCV
Silberman, N., Hoiem, D., Kohli, P., Fergus, R.: Indoor Segmentation and Support Inference from RGBD Images. In: ECCV. pp. 746–760 (2012)
2012
-
[47]
Siméoni, O., Vo, H.V., Seitzer, M., Baldassarre, F., Oquab, M., Jose, C., Khalidov, V., Szafraniec, M., Yi, S., Ramamonjisoa, M., Massa, F., Haziza, D., Wehrstedt, L., Wang, J., Darcet, T., Moutakanni, T., Sentana, L., Roberts, C., Vedaldi, A., Tolan, J., Brandt, J., Couprie, C., Mairal, J., Jégou, H., Labatut, P., Bojanowski, P.: DINOv3. arXiv preprint a...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
Neurocomputing568, 127063 (2024)
Su, J., Ahmed, M., Lu, Y., Pan, S., Bo, W., Liu, Y.: RoFormer: Enhanced Trans- former with Rotary Position Embedding. Neurocomputing568, 127063 (2024)
2024
-
[49]
In: ICML (2024)
Sun, C., Yuan, Z., Xu, K., Mai, L., N, S., Chen, S., Marina, M.K.: Learning High- Frequency Functions Made Easy with Sinusoidal Positional Encoding. In: ICML (2024)
2024
-
[50]
In: ECCV
Suri, S., Walmer, M., Gupta, K., Shrivastava, A.: LiFT: A Surprisingly Simple Lightweight Feature Transform for Dense ViT Descriptors. In: ECCV. pp. 110–128 (2024)
2024
-
[51]
Tschannen, M., Gritsenko, A., Wang, X., Naeem, M.F., Alabdulmohsin, I., Parthasarathy, N., Evans, T., Beyer, L., Xia, Y., Mustafa, B., et al.: SigLIP 2: Multilingual Vision-Language Encoders with Improved Semantic Understanding, Localization, and Dense Features. arXiv preprint arXiv:2502.14786 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[52]
In: ICCV
Wang, J., Chen, K., Xu, R., Liu, Z., Loy, C.C., Lin, D.: CARAFE: Content-Aware ReAssembly of FEatures. In: ICCV. pp. 3007–3016 (2019)
2019
-
[53]
In: CVPR (2018)
Wang, X., Yu, K., Dong, C., Loy, C.C.: Recovering Realistic Texture in Image Super-Resolution by Deep Spatial Feature Transform. In: CVPR (2018)
2018
-
[54]
In: ICLR (2026)
Wimmer, T., Truong, P., Rakotosaona, M.J., Oechsle, M., Tombari, F., Schiele, B., Lenssen, J.E.: AnyUp: Universal Feature Upsampling. In: ICLR (2026)
2026
-
[55]
In: ECCV
Wu, Y., He, K.: Group Normalization. In: ECCV. pp. 3–19 (2018)
2018
-
[56]
In: ECCV
Wysoczańska, M., Siméoni, O., Ramamonjisoa, M., Bursuc, A., Trzciński, T., Pérez,P.:CLIP-DINOiser:TeachingCLIPafewDINOTricksforOpen-Vocabulary Semantic Segmentation. In: ECCV. pp. 320–337 (2024)
2024
-
[57]
In: ICCV
Xie, X., Lessen, J.E., Pons-Moll, G.: MVGBench: A Comprehensive Benchmark for Multi-view Generation Models. In: ICCV. pp. 8207–8218 (2025)
2025
-
[58]
Xu, H., Xie, S., Tan, X.E., Huang, P.Y., Howes, R., Sharma, V., Li, S.W., Ghosh, G., Zettlemoyer, L., Feichtenhofer, C.: Demystifying CLIP Data. arXiv preprint arXiv:2309.16671 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[59]
In: CVPR
Yang, L., Kang, B., Huang, Z., Xu, X., Feng, J., Zhao, H.: Depth Anything: Un- leashing the Power of Large-Scale Unlabeled Data. In: CVPR. pp. 10371–10381 (2024)
2024
-
[60]
NeurIPS37, 21875–21911 (2024)
Yang,L.,Kang,B.,Huang,Z.,Zhao,Z.,Xu,X.,Feng,J.,Zhao,H.:DepthAnything V2. NeurIPS37, 21875–21911 (2024)
2024
-
[61]
In: ICCV
Zhai, X., Mustafa, B., Kolesnikov, A., Beyer, L.: Sigmoid Loss for Language Image Pre-Training. In: ICCV. pp. 11941–11952 (2023)
2023
-
[62]
a photo of a {label name}
Zhou, B., Zhao, H., Puig, X., Xiao, T., Fidler, S., Barriuso, A., Torralba, A.: Semantic Understanding of Scenes through the ADE20K Dataset. IJCV127(3), 302–321 (2019) RaysUp: Ultra-light Universal Feature Upsampling 19 RaysUp: Ultra-light Universal Feature Upsampling via Geometry-Aware Ray Representation — Supplementary Material — A Motivation of Spatial...
2019
-
[63]
5 demonstrated consistent performance improvements, further validating the effectiveness and scalability of the proposed model
(18) With approximately 4 hours of training, the results in Tab. 5 demonstrated consistent performance improvements, further validating the effectiveness and scalability of the proposed model. D.3 Upsampling from Any to Any Resolution. Following our semantic segmentation configurations, we evaluated the general- ization capability of each model for upsamp...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.