PRISM: Prioritized Channel Importance with Semi-supervised Domain Adaptation for Cross-Subject EEG Emotion Recognition
Pith reviewed 2026-07-02 16:43 UTC · model grok-4.3
The pith
PRISM weights EEG channels dynamically and uses filtered pseudo-labels from unlabeled data to improve cross-subject emotion recognition with limited labels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
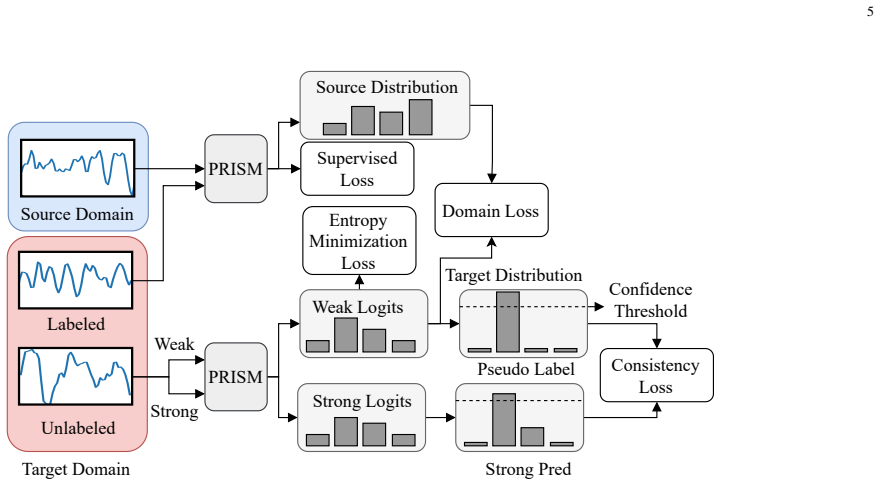
PRISM enables label-efficient cross-subject emotion decoding by assigning differentiable, data-dependent channel weights via a lightweight expert ensemble and leveraging unlabeled data through confidence-filtered pseudo-labels to drive consistency regularization and domain alignment.
What carries the argument
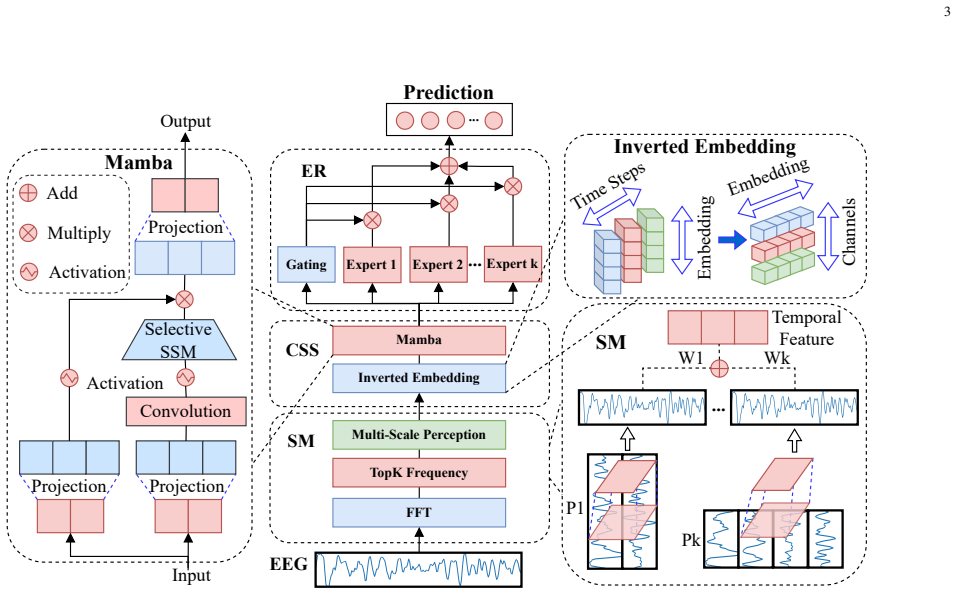
The PRISM framework that combines prioritized channel importance through expert-ensemble weighting with semi-supervised domain adaptation driven by confidence-filtered pseudo-labels.
If this is right
- Cross-subject generalization improves when only a small fraction of target-subject examples are labeled.
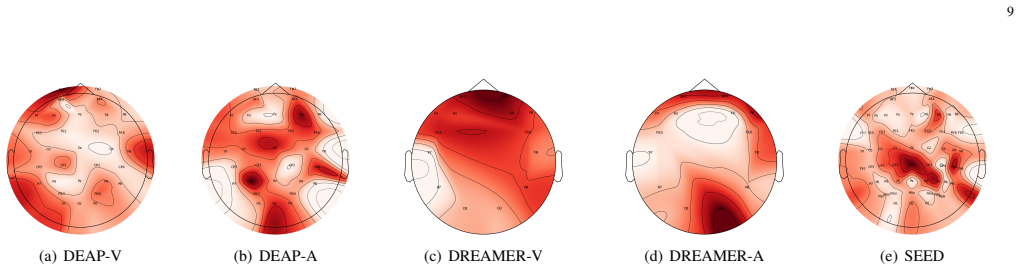
- Redundant or noisy EEG channels receive lower weights and therefore exert less influence on the final prediction.
- Consistency regularization across augmented views of the same unlabeled sample helps stabilize predictions under subject variability.
Where Pith is reading between the lines
- The same channel-weighting and pseudo-label pipeline could be tested on other biosignal tasks such as motor imagery or sleep staging.
- Performance may degrade if the source and target distributions differ more sharply than the three public datasets used here.
- An adaptive confidence threshold that changes with the amount of unlabeled data might further reduce label noise.
Load-bearing premise
The confidence-filtered pseudo-labels drawn from unlabeled target-subject data are accurate enough to support reliable domain alignment and consistency regularization.
What would settle it
An ablation that replaces the generated pseudo-labels with random or low-confidence labels and measures whether the reported gains over fully supervised baselines disappear.
Figures
read the original abstract
Electroencephalogram (EEG) captures endogenous brain activity with high temporal fidelity and holds substantial promise for precise emotion decoding. However, channel redundancy and pronounced inter-subject variability remain key obstacles to scalable generalization. To address these limitations, we propose a novel framework termed PRioritized channel Importance with Semi-supervised doMain adaptation (PRISM), enabling label-efficient cross-subject emotion decoding. On the channel side, PRISM assigns differentiable, data-dependent channel weights via a lightweight expert ensemble, amplifying reliable electrodes while suppressing distractors. On the domain side, PRISM leverages unlabeled data through confidence-filtered pseudo-labels to drive consistency regularization and domain alignment, mitigating subject-specific heterogeneity. Extensive experiments show that PRISM surpasses state-of-the-art methods on DEAP, DREAMER, and SEED datasets, achieving robust cross-subject generalization given limited annotations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes PRISM, a framework for label-efficient cross-subject EEG emotion recognition. It combines a lightweight expert ensemble to compute differentiable, data-dependent channel weights that prioritize reliable electrodes and suppress distractors, with a semi-supervised domain adaptation module that generates confidence-filtered pseudo-labels from unlabeled target-subject data to enforce consistency regularization and domain alignment. Experiments on DEAP, DREAMER, and SEED are reported to show that PRISM outperforms prior state-of-the-art methods under limited annotation regimes.
Significance. If the pseudo-label accuracy and experimental controls hold, the work would offer a practical route to reducing annotation burden in EEG emotion decoding while addressing channel redundancy and inter-subject shift. The expert-ensemble channel weighting is a potentially reusable idea, but the semi-supervised component's contribution cannot be assessed without direct evidence on label quality.
major comments (3)
- [§3.2] §3.2 (Domain Adaptation Module): The central claim that confidence-filtered pseudo-labels 'drive consistency regularization and domain alignment' is load-bearing, yet no accuracy of these pseudo-labels versus ground-truth target labels is reported, nor is there an ablation on the confidence threshold or analysis of label-noise propagation under inter-subject variability. If pseudo-label error exceeds typical 15-20% thresholds, the semi-supervised terms can degrade rather than improve generalization.
- [§4] §4 (Experiments): No details are provided on the cross-validation procedure (e.g., leave-one-subject-out splits, number of folds), statistical significance testing of the reported gains, or whether hyper-parameters were tuned on the same target data used for evaluation. These omissions prevent verification that the headline improvements survive proper controls and are not inflated by post-hoc choices.
- [Table 2] Table 2 / Results: The comparison tables do not include an ablation isolating the contribution of the pseudo-label component versus a fully supervised baseline with the same channel-weighting module, making it impossible to attribute performance gains specifically to the semi-supervised adaptation.
minor comments (2)
- [§3.1] Notation for the expert ensemble weights (Eq. 3) is introduced without an explicit statement of how the ensemble is trained or whether its parameters are shared across subjects.
- [Abstract] The abstract states 'limited annotations' but does not quantify the exact fraction of labeled target samples used in the reported runs.
Simulated Author's Rebuttal
Thank you for the constructive feedback on our manuscript. We address each of the major comments below and will incorporate revisions to strengthen the paper.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Domain Adaptation Module): The central claim that confidence-filtered pseudo-labels 'drive consistency regularization and domain alignment' is load-bearing, yet no accuracy of these pseudo-labels versus ground-truth target labels is reported, nor is there an ablation on the confidence threshold or analysis of label-noise propagation under inter-subject variability. If pseudo-label error exceeds typical 15-20% thresholds, the semi-supervised terms can degrade rather than improve generalization.
Authors: We agree that reporting the accuracy of the confidence-filtered pseudo-labels is crucial for validating the semi-supervised component. In the revised manuscript, we will add an evaluation of pseudo-label accuracy against ground-truth target labels. We will also include an ablation study varying the confidence threshold and discuss or analyze the effects of label noise propagation due to inter-subject variability. revision: yes
-
Referee: [§4] §4 (Experiments): No details are provided on the cross-validation procedure (e.g., leave-one-subject-out splits, number of folds), statistical significance testing of the reported gains, or whether hyper-parameters were tuned on the same target data used for evaluation. These omissions prevent verification that the headline improvements survive proper controls and are not inflated by post-hoc choices.
Authors: We will revise Section 4 to provide full details on the cross-validation procedure, including the use of leave-one-subject-out splits and the number of folds. Statistical significance testing will be added for the reported performance improvements. We will also clarify that hyper-parameters were tuned using validation data disjoint from the evaluation target subjects. revision: yes
-
Referee: [Table 2] Table 2 / Results: The comparison tables do not include an ablation isolating the contribution of the pseudo-label component versus a fully supervised baseline with the same channel-weighting module, making it impossible to attribute performance gains specifically to the semi-supervised adaptation.
Authors: We will add a new ablation experiment in the revised manuscript that compares the full PRISM model against a supervised baseline using only the channel-weighting module (without the semi-supervised pseudo-label adaptation). This will help isolate the contribution of the domain adaptation component. revision: yes
Circularity Check
Empirical ML framework with no derivation chain reducing to inputs
full rationale
The paper presents an empirical framework (PRISM) combining channel weighting via expert ensemble and semi-supervised domain adaptation via pseudo-labels, evaluated on DEAP/DREAMER/SEED. No equations, first-principles derivations, or predictions are claimed that could reduce by construction to fitted parameters or self-citations. Performance results are externally falsifiable via standard benchmarks; the pseudo-label mechanism is a modeling choice whose validity is tested experimentally rather than assumed by definition. No load-bearing self-citations, uniqueness theorems, or renamings of known results appear in the abstract or method description.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Matt: A manifold attention network for eeg decoding,
Y .-T. Pan, J.-L. Chou, and C.-S. Wei, “Matt: A manifold attention network for eeg decoding,”Advances in Neural Information Processing Systems, vol. 35, pp. 31 116–31 129, 2022
2022
-
[2]
Spd domain- specific batch normalization to crack interpretable unsupervised domain adaptation in eeg,
R. Kobler, J.-i. Hirayama, Q. Zhao, and M. Kawanabe, “Spd domain- specific batch normalization to crack interpretable unsupervised domain adaptation in eeg,”Advances in Neural Information Processing Systems, vol. 35, pp. 6219–6235, 2022
2022
-
[3]
Frontal eeg asymmetry as a moderator and mediator of emotion,
J. A. Coan and J. J. Allen, “Frontal eeg asymmetry as a moderator and mediator of emotion,”Biological psychology, vol. 67, no. 1-2, pp. 7–50, 2004
2004
-
[4]
Astdf-net: attention- based spatial-temporal dual-stream fusion network for eeg-based emo- tion recognition,
P. Gong, Z. Jia, P. Wang, Y . Zhou, and D. Zhang, “Astdf-net: attention- based spatial-temporal dual-stream fusion network for eeg-based emo- tion recognition,” inProceedings of the 31st ACM international confer- ence on multimedia, 2023, pp. 883–892
2023
-
[5]
Multi- view domain-adaptive representation learning for eeg-based emotion recognition,
C. Li, N. Bian, Z. Zhao, H. Wang, and B. W. Schuller, “Multi- view domain-adaptive representation learning for eeg-based emotion recognition,”Information Fusion, vol. 104, p. 102156, 2024
2024
-
[6]
Seeg emotion recognition based on transformer network with channel selection and explainability,
Z. Yang, X. Si, W. Jin, D. Huang, Y . Zang, S. Yin, and D. Ming, “Seeg emotion recognition based on transformer network with channel selection and explainability,”IEEE Journal of Biomedical and Health Informatics, 2025
2025
-
[7]
mimamba: Eeg-based emotion recognition with multi-scale inverted mamba models,
X. Zhou, D. Huang, X. Peng, and L. Yin, “mimamba: Eeg-based emotion recognition with multi-scale inverted mamba models,”IEEE Transactions on Affective Computing, 2025
2025
-
[8]
Eeg- based emotion recognition via channel-wise attention and self attention,
W. Tao, C. Li, R. Song, J. Cheng, Y . Liu, F. Wan, and X. Chen, “Eeg- based emotion recognition via channel-wise attention and self attention,” IEEE Transactions on Affective Computing, vol. 14, no. 1, pp. 382–393, 2020
2020
-
[9]
Eeg emotion recog- nition using improved graph neural network with channel selection,
X. Lin, J. Chen, W. Ma, W. Tang, and Y . Wang, “Eeg emotion recog- nition using improved graph neural network with channel selection,” Computer Methods and Programs in Biomedicine, vol. 231, p. 107380, 2023
2023
-
[10]
Automatically extracting and utilizing eeg channel importance based on graph convolutional network for emotion recognition,
K. Yang, Z. Yao, K. Zhang, J. Xu, L. Zhu, S. Cheng, and J. Zhang, “Automatically extracting and utilizing eeg channel importance based on graph convolutional network for emotion recognition,”IEEE Journal of Biomedical and Health Informatics, vol. 28, no. 8, pp. 4588–4598, 2024
2024
-
[11]
Eegmatch: Learning with incomplete labels for semisupervised eeg-based cross-subject emotion recognition,
R. Zhou, W. Ye, Z. Zhang, Y . Luo, L. Zhang, L. Li, G. Huang, Y . Dong, Y .-T. Zhang, and Z. Liang, “Eegmatch: Learning with incomplete labels for semisupervised eeg-based cross-subject emotion recognition,”IEEE Transactions on Neural Networks and Learning Systems, 2024
2024
-
[12]
Multi-modal cross-subject emotion feature alignment and recognition with eeg and eye movements,
Q. Zhu, T. Zhu, L. Fei, C. Zheng, W. Shao, D. Zhang, and D. Zhang, “Multi-modal cross-subject emotion feature alignment and recognition with eeg and eye movements,”IEEE Transactions on Affective Comput- ing, 2025
2025
-
[13]
Gusa: Graph-based unsuper- vised subdomain adaptation for cross-subject eeg emotion recognition,
X. Li, C. P. Chen, B. Chen, and T. Zhang, “Gusa: Graph-based unsuper- vised subdomain adaptation for cross-subject eeg emotion recognition,” IEEE Transactions on Affective Computing, vol. 15, no. 3, pp. 1451– 1462, 2024
2024
-
[14]
Domain adversarial neural network with reliable pseudo-labels iteration for cross-subject eeg emotion recognition,
X. Ju, J. Su, S. Dai, X. Wu, M. Li, and D. Hu, “Domain adversarial neural network with reliable pseudo-labels iteration for cross-subject eeg emotion recognition,”Knowledge-Based Systems, vol. 316, p. 113368, 2025
2025
-
[15]
Semi-supervised dual-stream self-attentive adversarial graph contrastive learning for cross-subject eeg-based emotion recognition,
W. Ye, Z. Zhang, F. Teng, M. Zhang, J. Wang, D. Ni, F. Li, P. Xu, and Z. Liang, “Semi-supervised dual-stream self-attentive adversarial graph contrastive learning for cross-subject eeg-based emotion recognition,” IEEE Transactions on Affective Computing, 2024
2024
-
[16]
Unsupervised time-aware sampling network with deep reinforcement learning for eeg-based emotion recognition,
Y . Zhang, Y . Pan, Y . Zhang, M. Zhang, L. Li, L. Zhang, G. Huang, L. Su, H. Liu, Z. Lianget al., “Unsupervised time-aware sampling network with deep reinforcement learning for eeg-based emotion recognition,” IEEE Transactions on Affective Computing, vol. 15, no. 3, pp. 1090– 1103, 2023
2023
-
[17]
Brainuicl: An unsupervised individual continual learning framework for eeg applications,
Y . Zhou, S. Zhao, J. Wang, H. Jiang, S. Li, T. Li, and G. Pan, “Brainuicl: An unsupervised individual continual learning framework for eeg applications,” inThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[18]
Learning Factored Representations in a Deep Mixture of Experts
D. Eigen, M. Ranzato, and I. Sutskever, “Learning factored represen- tations in a deep mixture of experts,”arXiv preprint arXiv:1312.4314, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[19]
Adamatch: A unified approach to semi-supervised learning and domain adaptation,
D. Berthelot, R. Roelofs, K. Sohn, N. Carlini, and A. Kurakin, “Adamatch: A unified approach to semi-supervised learning and domain adaptation,”arXiv preprint arXiv:2106.04732, 2021
-
[20]
Emt: A novel transformer for generalized cross-subject eeg emotion 11 recognition,
Y . Ding, C. Tong, S. Zhang, M. Jiang, Y . Li, K. J. Lim, and C. Guan, “Emt: A novel transformer for generalized cross-subject eeg emotion 11 recognition,”IEEE Transactions on Neural Networks and Learning Systems, 2025
2025
-
[21]
Eeg emotion recognition using attention-based convolutional transformer neural network,
L. Gong, M. Li, T. Zhang, and W. Chen, “Eeg emotion recognition using attention-based convolutional transformer neural network,”Biomedical Signal Processing and Control, vol. 84, p. 104835, 2023
2023
-
[22]
Convolutional gated recurrent unit-driven mul- tidimensional dynamic graph neural network for subject-independent emotion recognition,
W. Guo and Y . Wang, “Convolutional gated recurrent unit-driven mul- tidimensional dynamic graph neural network for subject-independent emotion recognition,”Expert Systems with Applications, vol. 238, p. 121889, 2024
2024
-
[23]
Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity,
W. Fedus, B. Zoph, and N. Shazeer, “Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity,”Journal of Machine Learning Research, vol. 23, no. 120, pp. 1–39, 2022
2022
-
[24]
GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding
D. Lepikhin, H. Lee, Y . Xu, D. Chen, O. Firat, Y . Huang, M. Krikun, N. Shazeer, and Z. Chen, “Gshard: Scaling giant models with conditional computation and automatic sharding,”arXiv preprint arXiv:2006.16668, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[25]
Scaling vision with sparse mixture of experts,
C. Riquelme, J. Puigcerver, B. Mustafa, M. Neumann, R. Jenatton, A. Susano Pinto, D. Keysers, and N. Houlsby, “Scaling vision with sparse mixture of experts,”Advances in Neural Information Processing Systems, vol. 34, pp. 8583–8595, 2021
2021
-
[26]
Variational mixture-of-experts autoen- coders for multi-modal deep generative models,
Y . Shi, B. Paige, P. Torret al., “Variational mixture-of-experts autoen- coders for multi-modal deep generative models,”Advances in neural information processing systems, vol. 32, 2019
2019
-
[27]
Pathformer: Multi-scale transformers with adaptive pathways for time series forecasting,
P. Chen, Y . Zhang, Y . Cheng, Y . Shu, Y . Wang, Q. Wen, B. Yang, and C. Guo, “Pathformer: Multi-scale transformers with adaptive pathways for time series forecasting,”arXiv preprint arXiv:2402.05956, 2024
-
[28]
Time-MoE: Billion-scale time series foundation models with mixture of experts
X. Shi, S. Wang, Y . Nie, D. Li, Z. Ye, Q. Wen, and M. Jin, “Time-moe: Billion-scale time series foundation models with mixture of experts,” arXiv preprint arXiv:2409.16040, 2024
-
[29]
Shedding light on time series classification using interpretability gated networks,
Y . Wen, T. Ma, R. Luss, D. Bhattacharjya, A. Fokoue, and A. A. Julius, “Shedding light on time series classification using interpretability gated networks,” inThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[30]
Learning soft sparse shapes for efficient time-series classification,
Z. Liu, Y . Luo, B. Li, E. Eldele, M. Wu, and Q. Ma, “Learning soft sparse shapes for efficient time-series classification,”arXiv preprint arXiv:2505.06892, 2025
-
[31]
Mixmatch: A holistic approach to semi-supervised learning,
D. Berthelot, N. Carlini, I. Goodfellow, N. Papernot, A. Oliver, and C. A. Raffel, “Mixmatch: A holistic approach to semi-supervised learning,” Advances in neural information processing systems, vol. 32, 2019
2019
-
[32]
mixup: Beyond Empirical Risk Minimization
H. Zhang, M. Cisse, Y . N. Dauphin, and D. Lopez-Paz, “mixup: Beyond empirical risk minimization,”arXiv preprint arXiv:1710.09412, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[33]
Fixmatch: Simplifying semi- supervised learning with consistency and confidence,
K. Sohn, D. Berthelot, N. Carlini, Z. Zhang, H. Zhang, C. A. Raffel, E. D. Cubuk, A. Kurakin, and C.-L. Li, “Fixmatch: Simplifying semi- supervised learning with consistency and confidence,”Advances in neural information processing systems, vol. 33, pp. 596–608, 2020
2020
-
[34]
Flexmatch: Boosting semi-supervised learning with curriculum pseudo labeling,
B. Zhang, Y . Wang, W. Hou, H. Wu, J. Wang, M. Okumura, and T. Shi- nozaki, “Flexmatch: Boosting semi-supervised learning with curriculum pseudo labeling,”Advances in neural information processing systems, vol. 34, pp. 18 408–18 419, 2021
2021
-
[35]
arXiv preprint arXiv:2205.07246 , year=
Y . Wang, H. Chen, Q. Heng, W. Hou, Y . Fan, Z. Wu, J. Wang, M. Sav- vides, T. Shinozaki, B. Rajet al., “Freematch: Self-adaptive thresholding for semi-supervised learning,”arXiv preprint arXiv:2205.07246, 2022
-
[36]
Softmatch: Addressing the quantity-quality trade-off in semi-supervised learning,
H. Chen, R. Tao, Y . Fan, Y . Wang, J. Wang, B. Schiele, X. Xie, B. Raj, and M. Savvides, “Softmatch: Addressing the quantity-quality trade-off in semi-supervised learning,”arXiv preprint arXiv:2301.10921, 2023
-
[37]
Allmatch: exploiting all unlabeled data for semi- supervised learning,
Z. Wu and J. Cui, “Allmatch: exploiting all unlabeled data for semi- supervised learning,”arXiv preprint arXiv:2406.15763, 2024
-
[38]
Boosting semi-supervised learning by exploiting all unlabeled data,
Y . Chen, X. Tan, B. Zhao, Z. Chen, R. Song, J. Liang, and X. Lu, “Boosting semi-supervised learning by exploiting all unlabeled data,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 7548–7557
2023
-
[39]
TimesNet: Temporal 2D-Variation Modeling for General Time Series Analysis
H. Wu, T. Hu, Y . Liu, H. Zhou, J. Wang, and M. Long, “Timesnet: Temporal 2d-variation modeling for general time series analysis,”arXiv preprint arXiv:2210.02186, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[40]
Fedformer: Frequency enhanced decomposed transformer for long-term series fore- casting,
T. Zhou, Z. Ma, Q. Wen, X. Wang, L. Sun, and R. Jin, “Fedformer: Frequency enhanced decomposed transformer for long-term series fore- casting,” inInternational conference on machine learning. PMLR, 2022, pp. 27 268–27 286
2022
-
[41]
iTransformer: Inverted Transformers Are Effective for Time Series Forecasting
Y . Liu, T. Hu, H. Zhang, H. Wu, S. Wang, L. Ma, and M. Long, “itrans- former: Inverted transformers are effective for time series forecasting,” arXiv preprint arXiv:2310.06625, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[42]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
A. Gu and T. Dao, “Mamba: Linear-time sequence modeling with selective state spaces,”arXiv preprint arXiv:2312.00752, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[43]
Deap: A database for emotion analysis; using physiological signals,
S. Koelstra, C. Muhl, M. Soleymani, J.-S. Lee, A. Yazdani, T. Ebrahimi, T. Pun, A. Nijholt, and I. Patras, “Deap: A database for emotion analysis; using physiological signals,”IEEE transactions on affective computing, vol. 3, no. 1, pp. 18–31, 2011
2011
-
[44]
Dreamer: A database for emotion recognition through eeg and ecg signals from wireless low-cost off- the-shelf devices,
S. Katsigiannis and N. Ramzan, “Dreamer: A database for emotion recognition through eeg and ecg signals from wireless low-cost off- the-shelf devices,”IEEE journal of biomedical and health informatics, vol. 22, no. 1, pp. 98–107, 2017
2017
-
[45]
Investigating critical frequency bands and channels for eeg-based emotion recognition with deep neural networks,
W.-L. Zheng and B.-L. Lu, “Investigating critical frequency bands and channels for eeg-based emotion recognition with deep neural networks,” IEEE Transactions on autonomous mental development, vol. 7, no. 3, pp. 162–175, 2015
2015
-
[46]
Are transformers effective for time series forecasting?
A. Zeng, M. Chen, L. Zhang, and Q. Xu, “Are transformers effective for time series forecasting?” inProceedings of the AAAI conference on artificial intelligence, vol. 37, no. 9, 2023, pp. 11 121–11 128
2023
-
[47]
Non-stationary transformers: Exploring the stationarity in time series forecasting,
Y . Liu, H. Wu, J. Wang, and M. Long, “Non-stationary transformers: Exploring the stationarity in time series forecasting,”Advances in neural information processing systems, vol. 35, pp. 9881–9893, 2022
2022
-
[48]
Informer: Beyond efficient transformer for long sequence time-series forecasting,
H. Zhou, S. Zhang, J. Peng, S. Zhang, J. Li, H. Xiong, and W. Zhang, “Informer: Beyond efficient transformer for long sequence time-series forecasting,” inProceedings of the AAAI conference on artificial intel- ligence, vol. 35, no. 12, 2021, pp. 11 106–11 115
2021
-
[49]
An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling
S. Bai, J. Z. Kolter, and V . Koltun, “An empirical evaluation of generic convolutional and recurrent networks for sequence modeling,”arXiv preprint arXiv:1803.01271, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[50]
A novel transformer autoencoder for multi-modal emotion recognition with incomplete data,
C. Cheng, W. Liu, Z. Fan, L. Feng, and Z. Jia, “A novel transformer autoencoder for multi-modal emotion recognition with incomplete data,” Neural Networks, vol. 172, p. 106111, 2024
2024
-
[51]
Dynamic stream selection network for subject-independent eeg-based emotion recognition,
W. Li, J. Dong, S. Liu, L. Fan, and S. Wang, “Dynamic stream selection network for subject-independent eeg-based emotion recognition,”IEEE Sensors Journal, vol. 24, no. 12, pp. 19 336–19 343, 2024
2024
-
[52]
Cascaded self-supervised learning for subject-independent eeg-based emotion recognition,
H. Wang, T. Chen, and L. Song, “Cascaded self-supervised learning for subject-independent eeg-based emotion recognition,”arXiv preprint arXiv:2403.04041, 2024
-
[53]
Gddn: Graph domain disen- tanglement network for generalizable eeg emotion recognition,
B. Chen, C. P. Chen, and T. Zhang, “Gddn: Graph domain disen- tanglement network for generalizable eeg emotion recognition,”IEEE Transactions on Affective Computing, vol. 15, no. 3, pp. 1739–1753, 2024
2024
-
[54]
Subject independent emotion recognition using eeg signals employing attention driven neural net- works,
A. S. Rajpoot, M. R. Panickeret al., “Subject independent emotion recognition using eeg signals employing attention driven neural net- works,”Biomedical Signal Processing and Control, vol. 75, p. 103547, 2022
2022
-
[55]
Alpha-band oscillations, attention, and controlled access to stored information,
W. Klimesch, “Alpha-band oscillations, attention, and controlled access to stored information,”Trends in cognitive sciences, vol. 16, no. 12, pp. 606–617, 2012
2012
-
[56]
How brains beware: neural mechanisms of emotional attention,
P. Vuilleumier, “How brains beware: neural mechanisms of emotional attention,”Trends in cognitive sciences, vol. 9, no. 12, pp. 585–594, 2005
2005
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.