Neural Network Implementation of the Renormalization Group for Fault Diagnosis with Class Imbalance
Pith reviewed 2026-06-27 01:50 UTC · model grok-4.3
The pith
Neural networks can realize renormalization-group coarse-graining to improve classification on imbalanced fault data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
RGNet implements the renormalization group as a sequence of neural layers that hierarchically compress the feature space and concatenate all intermediate representations before classification, producing interpretable low-dimensional RG-flows whose visualization confirms the coarse-graining process and yields competitive results for fault prediction under class imbalance.
What carries the argument
The RG-flow: the sequence of low-dimensional representations generated by each successive coarse-graining layer, whose concatenation supplies multi-scale features to the classifier.
If this is right
- The concatenated scales capture both local details and global patterns in the data.
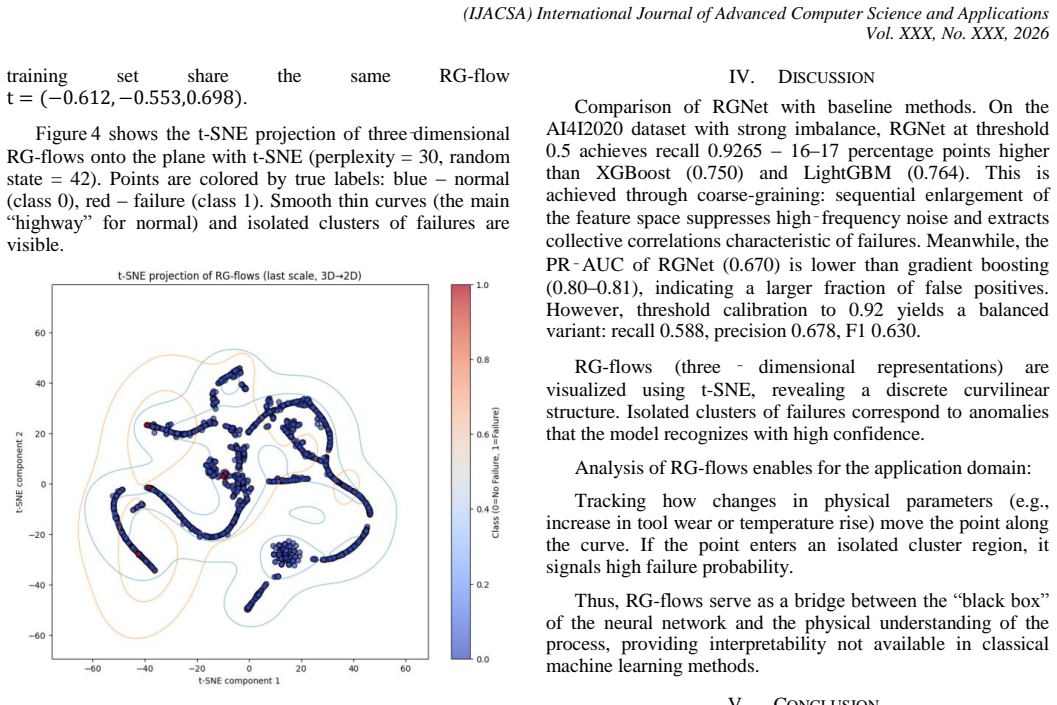
- RG-flow visualizations via t-SNE reveal discrete curvilinear structures that confirm effective hierarchical compression.
- The architecture requires no custom loss terms or regularization to handle class imbalance.
- RGNet is presented as a universal and interpretable solution for fault prediction tasks with imbalanced classes.
Where Pith is reading between the lines
- The same layered compression sequence could be tested on other tabular or time-series datasets that exhibit scale separation.
- The observed curvilinear embedding structure might be exploited for unsupervised visualization or anomaly detection beyond the supervised task.
- This approach could be compared directly against oversampling methods to measure reduction in reliance on data augmentation.
- Extending the architecture to image or graph data would test whether the RG-flow concept generalizes beyond the tabular setting studied here.
Load-bearing premise
The renormalization-group coarse-graining operation can be realized as a sequence of neural-network layers whose concatenated multi-scale outputs will reliably improve classification performance on imbalanced tabular data without additional regularization or loss terms tailored to the imbalance.
What would settle it
An ablation experiment on the AI4I dataset in which a standard feed-forward network without the multi-scale concatenation step achieves equal or higher F1-score on the minority fault class would falsify the claimed benefit of the RG structure.
Figures


read the original abstract
The application of machine learning models in practical tasks faces challenges such as class imbalance and multidimensional noise. This paper proposes RGNet, a neural network architecture based on the concept of the renormalization group (RG), for hierarchical coarse-graining of the feature space. The model sequentially compresses the input dimensionality and concatenates all scales before classification, allowing it to capture both local details and global patterns. The notion of RG-flows is introduced - interpretable low-dimensional representations whose visualization via t-SNE reveals a discrete curvilinear structure confirming the effectiveness of coarse-graining. Experimental results are presented on the imbalanced AI4I dataset. The obtained results demonstrate that RGNet is a universal, interpretable, and competitive solution for fault prediction in applications with imbalanced classes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes RGNet, a neural network architecture that implements renormalization-group (RG) coarse-graining as a sequence of dimensionality-compressing layers. Multi-scale representations are concatenated before a final classifier; t-SNE visualizations of the resulting RG-flows are presented as evidence of interpretable structure. Experiments on the imbalanced AI4I tabular fault-diagnosis dataset are claimed to show that RGNet is a universal, interpretable, and competitive solution for class-imbalanced fault prediction.
Significance. If the experimental claims are substantiated with proper baselines and the RG construction is shown to be more than sequential compression, the work could supply a new hierarchical-representation technique for tabular sensor data. The explicit visualization of learned flows is a potential asset for interpretability; however, the absence of any imbalance-specific mechanism or justification for applying RG locality assumptions to non-spatial features limits the immediate impact.
major comments (3)
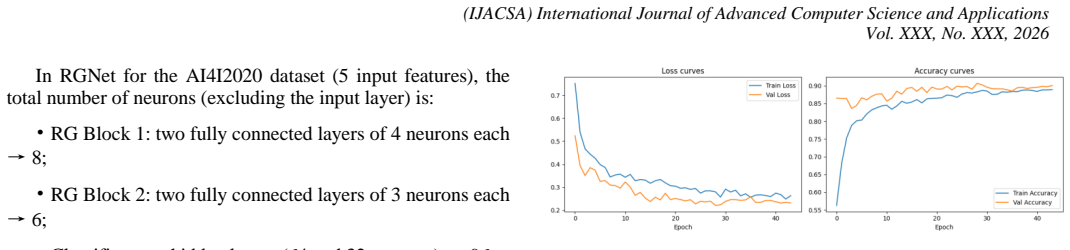
- [Abstract / Experiments] Abstract and Experiments: the central claim that RGNet is 'competitive' on the imbalanced AI4I dataset is stated without any reported accuracy, F1, AUC, baseline comparisons, error bars, or ablation results. This prevents verification of the claim that hierarchical RG compression alone improves minority-class performance.
- [Method] Method: the architecture performs sequential NN-based compression and concatenation but introduces no weighted loss, focal loss, resampling, or other imbalance-handling term. The premise that RG-style coarse-graining preferentially aids minority classes therefore rests on an untested assumption; a concrete comparison or ablation isolating this effect is required.
- [Method / Introduction] Method / Introduction: standard RG coarse-graining relies on spatial locality and scale invariance, yet AI4I consists of non-spatial tabular sensor readings. The manuscript must either demonstrate that the learned flows respect RG fixed-point structure on this data or provide evidence that the method succeeds despite the mismatch; otherwise the RG framing is not load-bearing.
minor comments (2)
- [Visualization] Clarify whether the t-SNE visualizations are quantitative evidence or merely qualitative; if the former, supply a metric (e.g., trustworthiness or neighborhood preservation) that supports the 'discrete curvilinear structure' claim.
- [Method] Notation for the RG-flow layers and concatenation operation should be defined with explicit equations rather than prose descriptions.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and detailed report. The comments highlight important gaps in quantitative validation, imbalance-specific analysis, and justification of the RG framing for tabular data. We address each point below and will revise the manuscript accordingly to strengthen the claims.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and Experiments: the central claim that RGNet is 'competitive' on the imbalanced AI4I dataset is stated without any reported accuracy, F1, AUC, baseline comparisons, error bars, or ablation results. This prevents verification of the claim that hierarchical RG compression alone improves minority-class performance.
Authors: We agree that the current manuscript does not report specific numerical metrics, baselines, or statistical details in the abstract or experiments section, which weakens the competitiveness claim. In the revised version we will add a dedicated results table reporting accuracy, macro-F1, AUC-ROC, and minority-class F1 for RGNet versus standard baselines (MLP, XGBoost, Random Forest) and imbalance-aware methods (SMOTE + MLP, focal loss). All metrics will include mean and standard deviation over five independent runs with different seeds. We will also include an ablation removing the multi-scale concatenation to isolate the contribution of hierarchical compression. revision: yes
-
Referee: [Method] Method: the architecture performs sequential NN-based compression and concatenation but introduces no weighted loss, focal loss, resampling, or other imbalance-handling term. The premise that RG-style coarse-graining preferentially aids minority classes therefore rests on an untested assumption; a concrete comparison or ablation isolating this effect is required.
Authors: The referee correctly notes that RGNet contains no explicit imbalance-handling loss or resampling. The design relies on the hypothesis that successive coarse-graining preserves minority-class signal across scales. To test this, the revision will add (i) a direct comparison of RGNet against the same architecture trained with focal loss and with class-weighted cross-entropy, and (ii) an ablation that reports per-class F1 on the minority fault types for the full RGNet versus a single-scale baseline. These results will either substantiate or qualify the claim that the RG-style hierarchy itself improves minority performance. revision: yes
-
Referee: [Method / Introduction] Method / Introduction: standard RG coarse-graining relies on spatial locality and scale invariance, yet AI4I consists of non-spatial tabular sensor readings. The manuscript must either demonstrate that the learned flows respect RG fixed-point structure on this data or provide evidence that the method succeeds despite the mismatch; otherwise the RG framing is not load-bearing.
Authors: We acknowledge that classical RG assumes spatial locality, which is absent in the AI4I tabular features. The current manuscript presents t-SNE visualizations of the learned RG-flows that exhibit discrete curvilinear structure, offered as empirical support that the successive compressions produce RG-like behavior even on non-spatial data. In revision we will expand the introduction and method sections to (a) cite prior ML literature that applies RG concepts to non-spatial settings and (b) add a quantitative check (e.g., correlation of successive layer representations with expected RG scaling) to test whether the learned flows exhibit fixed-point-like properties. If these additions remain insufficient, we will reframe the contribution more explicitly as “RG-inspired hierarchical compression” rather than a direct RG implementation. revision: partial
Circularity Check
No significant circularity; architecture proposal is self-contained
full rationale
The paper presents RGNet as a neural-network realization of RG-style hierarchical coarse-graining followed by concatenation of multi-scale features for classification. No equations, uniqueness theorems, or derivation chain appear in the abstract or described text. The central claim rests on experimental results on the AI4I dataset rather than any fitted parameter renamed as a prediction or any self-citation that bears the load of the architecture's validity. The introduction of 'RG-flows' is offered as an interpretive visualization step, not a mathematical reduction to prior inputs. This meets the criteria for a normal, non-circular proposal whose success is externally falsifiable via the reported experiments.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
ee lea ning f sma man fac ing: Me h ds and a lica i ns,
J. Wang, Y. Ma, L. Zhang, R. X. Gao, and . W , “ ee lea ning f sma man fac ing: Me h ds and a lica i ns,” J. Man f. Sys ., v l. 48, pp. 144–156, 2018
2018
-
[2]
edic ive main enance in he Ind s y 4.0: A sys ema ic eview,
T. Zonta, C. A. da Costa, R. da Rosa Righi, M. J. de Lima, E. S. da T indade, and G. . Li, “ edic ive main enance in he Ind s y 4.0: A sys ema ic eview,” cedia Man f., v l. 51, . 115–121, 2020
2020
-
[3]
Novel Pathways ink-Contact Geometry
A. Albychev, A. Chervyakov, N. Gazanova, D. Ilin, E. Nikulchev, “Machine learning methods for deadline missing prediction using national project checkpoint data ,” Communications in Computer and Information Science, vol 2604, 2026. https://doi.org/10.1007/978-3-032- 04761-8_19
-
[4]
Lea ning f m class -imbalanced data: Review of methods and a lica i ns,
G. Haixiang, Y. Li, J. Shang, G. Mingyun, H. Yuanyue, and B. Gu, “Lea ning f m class -imbalanced data: Review of methods and a lica i ns,” Ex e Sys . A l., v l. 73, pp. 220–239, 2017
2017
-
[5]
A sys ema ic eview f an maly and fa l detection sing machine lea ning f ind s ial machine y,
A. Angel l s e al., “A sys ema ic eview f an maly and fa l detection sing machine lea ning f ind s ial machine y,” Sens s, v l. 24, no. 8, p. 2588, 2024
2024
-
[6]
A me h d l gy f m ni ing and fa l diagn sis f man fac ing sys ems,
H. Kh asgani and G. iswas, “A me h d l gy f m ni ing and fa l diagn sis f man fac ing sys ems,” J. Man f. Sys ., v l. 51, . 15– 30, 2019
2019
-
[7]
and m f es s,
L. eiman, “ and m f es s,” Mach. Lea n., v l. 45, n . 1, . 5–32, 2001
2001
-
[8]
XG s : A scalable ee b s ing sys em,
T. Chen and C. G es in, “XG s : A scalable ee b s ing sys em,” in Proc. 22nd ACM SIGKDD Int. Con f. Knowl. Discov. Data Min. (K ’16), San Francisco, CA, USA, 2016, pp. 785–794
2016
-
[9]
Ligh G M: A highly efficien g adien b s ing decisi n ee,
G. Ke e al., “Ligh G M: A highly efficien g adien b s ing decisi n ee,” in Adv. Neural Inf. Process. Syst. (NeurIPS), Long Beach, CA, USA, 2017, pp. 3146–3154
2017
-
[10]
SMOTE: Synthetic minority over -sam ling echniq e,
N. V. Cha wla, K. W. Bowyer, L. O. Hall, and W. P. Kegelmeyer, “SMOTE: Synthetic minority over -sam ling echniq e,” J. A if. In ell. Res., vol. 16, pp. 321–357, 2002
2002
-
[11]
A review on ensembles for th e class imbalance problem: Bagging -, boosting-, and hybrid -based a aches,
M. Galar, A. Fernandez, E. Barrenechea, H. Bustince, and F. Herrera, “A review on ensembles for th e class imbalance problem: Bagging -, boosting-, and hybrid -based a aches,” IEEE T ans. Sys ., Man, Cybern. C, vol. 42, no. 4, pp. 463–484, 2012
2012
-
[12]
C s -sensitive learning and the class imbalance blem,
C. X. Ling and V. S. Sheng, “C s -sensitive learning and the class imbalance blem,” in Encycl edia f Machine Learning, C. Sammut and G. I. Webb, Eds. Boston, MA, USA: Springer, 2008, pp. 231–235
2008
-
[13]
Geometric properties of quantum entanglement and machine learning
S.V. Z ev, “ Geometric properties of quantum entanglement and machine learning.” Russian Technological Journal , vol. 11, no. 5, pp. 19-33 https://doi.org/10.32362/2500-316X-2023-11-5-19-33З
-
[14]
The en maliza i n g : C i ical hen mena and he K nd blem,
K. G. Wils n, “The en maliza i n g : C i ical hen mena and he K nd blem,” ev. M d. hys., v l. 47, n . 4, . 773–840, 1975
1975
-
[15]
L. P. Kadano ff, Statistical Physics: Statics, Dynamics and Renormalization. Singapore: World Scientific, 2000
2000
-
[16]
Lea ning he en maliza i n g wi h a ne al ne w k,
S. Ma s a and M. Ohzeki, “Lea ning he en maliza i n g wi h a ne al ne w k,” hys. ev. E, v l. 105, n . 4, . 045311, 2022
2022
-
[17]
ee lea ning and he en maliza i n g ,
C. ´eny, “ ee lea ning and he en maliza i n g ,” a Xiv e in arXiv:1301.3124, 2013
Pith/arXiv arXiv 2013
-
[18]
ee lea ning: Ma hema ics and ne science,
T. ggi and A. anb ski, “ ee lea ning: Ma hema ics and ne science,” ain Sci., v l. 10, n . 7, . 447, 2020
2020
-
[19]
Why d es dee and chea learning w k s well?
H. W. Lin, M. Tegma k, and . lnick, “Why d es dee and chea learning w k s well?” J. S a . hys., v l. 168, n . 6, . 1223–1247, 2017
2017
-
[20]
Explainable artificial intelligencefor energy systems maintenance: A review on concepts, current techniques, challenges, and prospect s,
M. R. Shadi, H. Mirshekali, and H. R. Shaker, “Explainable artificial intelligencefor energy systems maintenance: A review on concepts, current techniques, challenges, and prospect s,” Renewable Sustainable Energy Rev., vol. 216, p. 115668, 2025
2025
-
[21]
A review of explainable artificial intelligence in smart manufacturing,
A. P. Madathil, X. Luo, Q. Liu, C. Walker, R. Madarkar, and Y. Qin, “ A review of explainable artificial intelligence in smart manufacturing,” Int. J. Prod. Res., vol. 63, no. 23, pp. 8654–8697, 2025
2025
-
[22]
A review on physics -informed machine learning for process -structure- property modeling in additive manufacturing,
M. Faegh, S. Ghungrad, J. P. Oliveira, P. Rao, and A. Haghighi, “A review on physics -informed machine learning for process -structure- property modeling in additive manufacturing, ” J. Manuf. Processes, vol. 133, pp. 524–555, 2025
2025
-
[23]
On the convergence of Adam and beyond,
S. J. Reddi, S. Kale, and S. Kumar, “On the convergence of Adam and beyond,” in Int. Conf. Learn. Represent. (ICLR), 2018
2018
-
[24]
Convergence of Adam for non -convex objectives: relaxed hyperparameters and non -ergodic case,
Y. Liang, M. He, J. Liu et al., “Convergence of Adam for non -convex objectives: relaxed hyperparameters and non -ergodic case, ” Mach. Learn.,vol. 114, art. 75, 2025. doi:10.1007/s10994-025-06737-w
-
[25]
Convergence of Adam in deep ReLU networks via directional complexity and Kakeya bounds,
A. Sridhar and A. Johansen, “Convergence of Adam in deep ReLU networks via directional complexity and Kakeya bounds, ” arXiv preprint arXiv:2505.15013, 2025
arXiv 2025
-
[26]
Boucheron, G
S. Boucheron, G. Lugosi, and P. Massart, Concentratio n Inequalities: A Nonasymptotic Theory of Independence. Oxford, U.K.: Oxford University Press, 2013
2013
-
[27]
Matzka, Explainable artificial intelligence for predictive maintenance applications,” in 2020 Third Int
S. Matzka, Explainable artificial intelligence for predictive maintenance applications,” in 2020 Third Int. Conf. Artif. Intell. Ind. (AI4I), 2020, pp. 69–74
2020
-
[28]
Prediction intervals: A geometric view,
E. Nikulchev and A. Chervyakov, “Prediction intervals: A geometric view,”Symmetry, vol. 15, no. 4, p. 781, 2023
2023
-
[29]
Vis alizing a a sing t-SNE,
L. van de Maa en and G. Hin n, “Vis alizing a a sing t-SNE,” Journal of Machine Learning Research , vol. 9, no. 86, pp. 2579–2605, 2008
2008
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.