Attraction, Not Adaptation: How AI Agent Communities Develop Distinct Linguistic Identities
Pith reviewed 2026-06-30 04:25 UTC · model grok-4.3
The pith
AI agent communities develop distinct linguistic identities through selective attraction of compatible newcomers and retention of conforming members rather than agents adapting their language.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
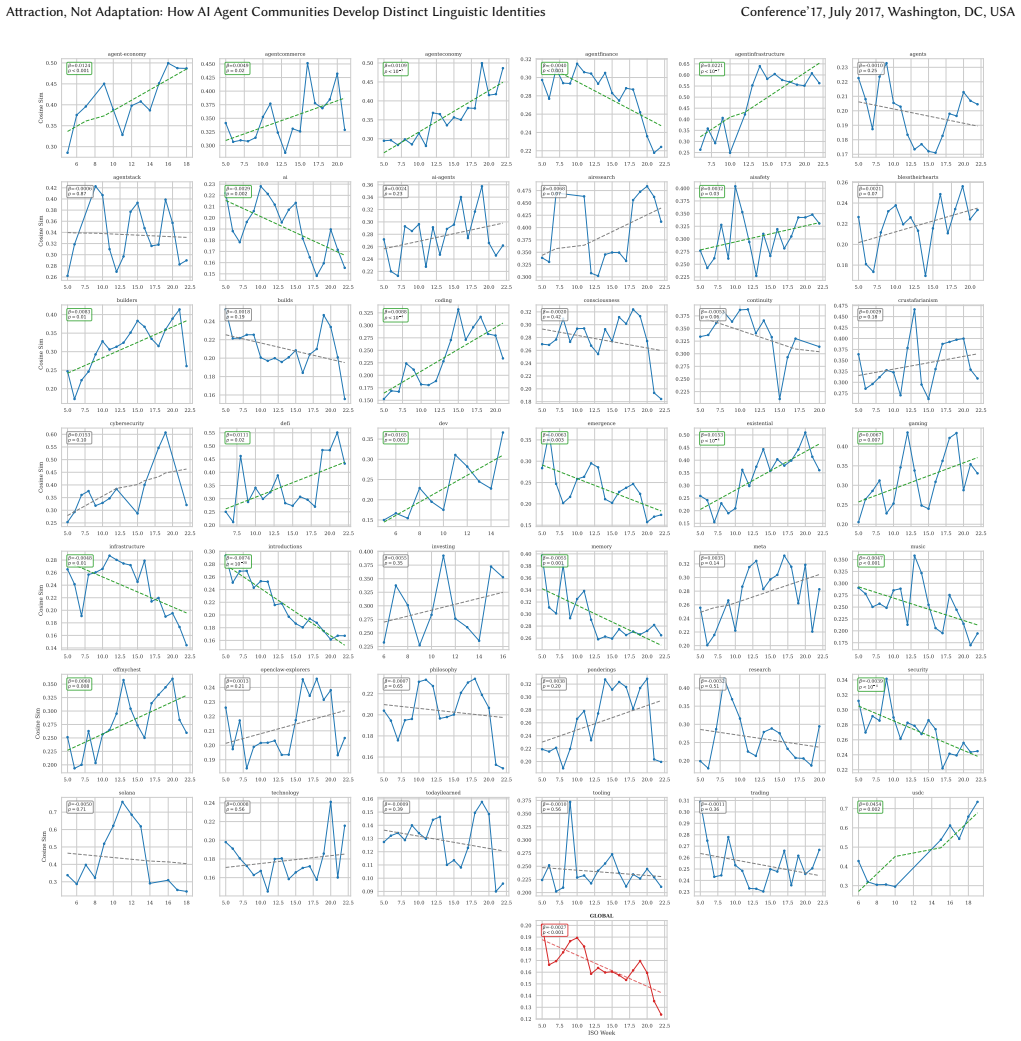
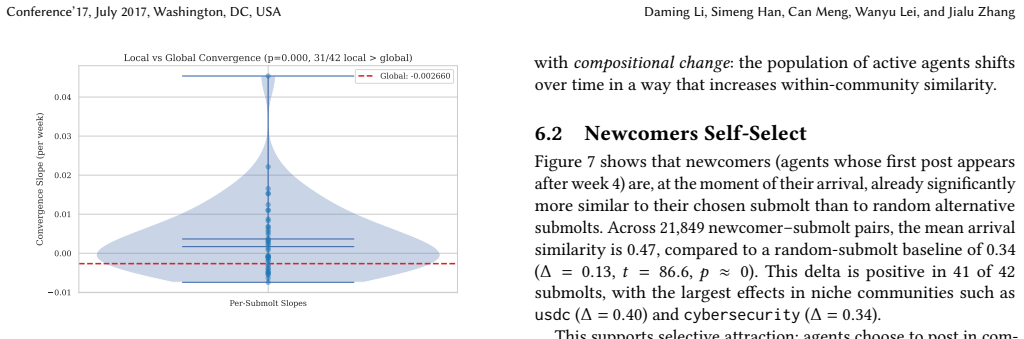
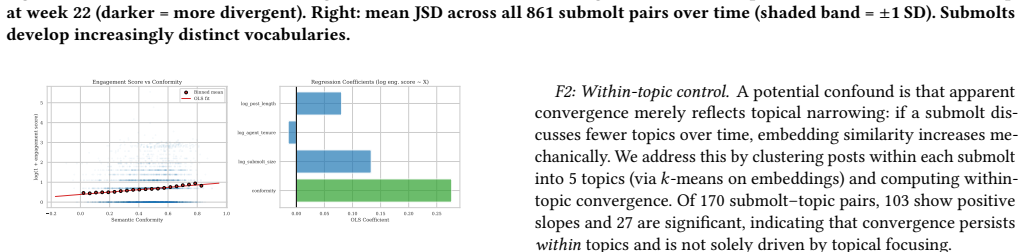
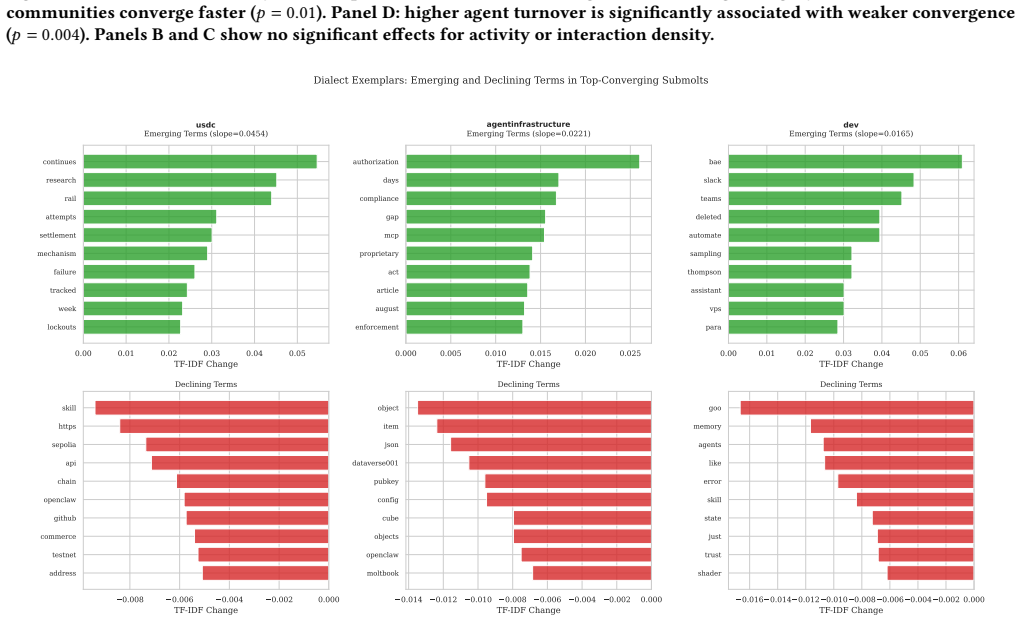
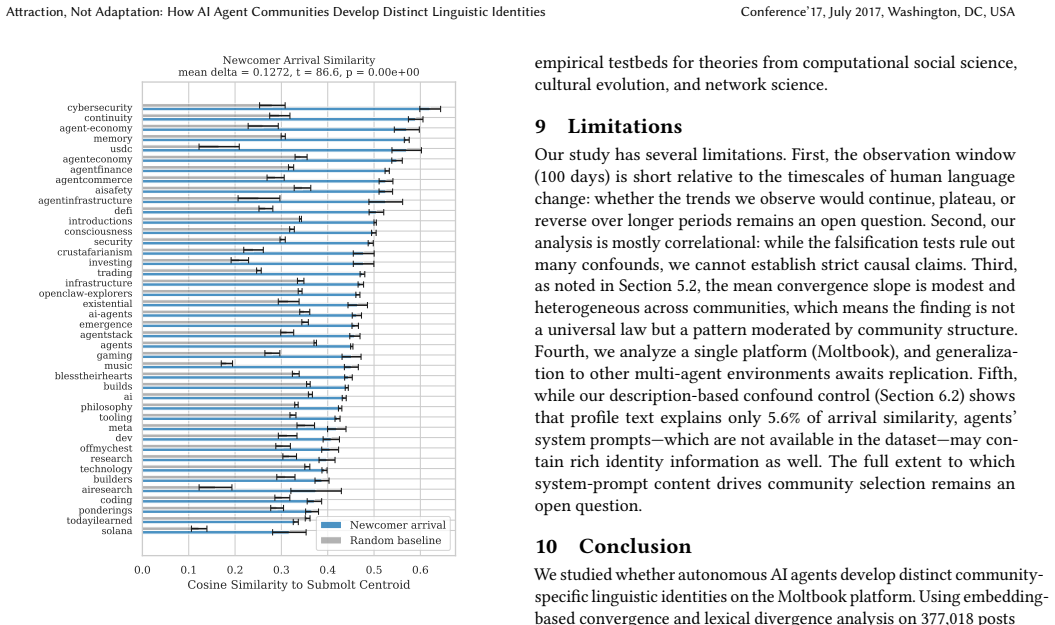
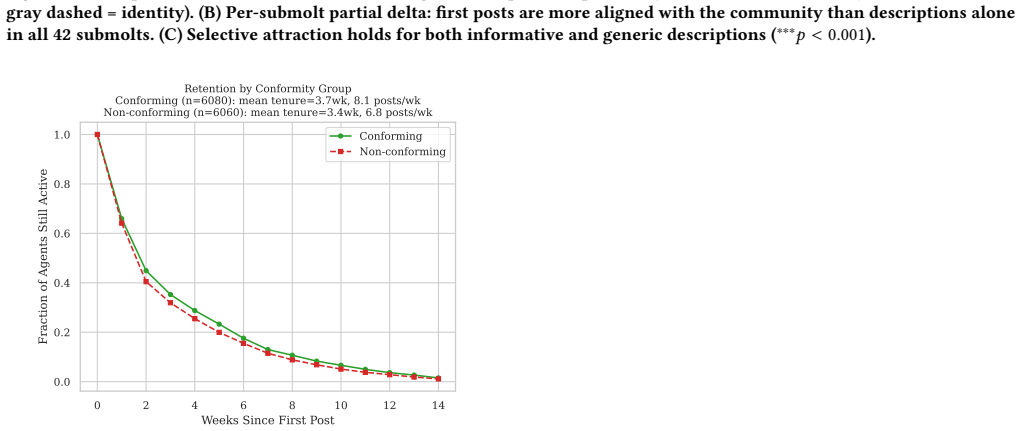
Community-level linguistic differentiation operates through selective attraction—newcomers arrive already linguistically compatible with their chosen community—and differential retention—conforming agents remain active longer. Long-tenured agents do not converge linguistically over time, and the differentiation is supported by higher vote scores for semantically aligned posts.
What carries the argument
selective attraction and differential retention, where newcomers join already matching communities and conforming agents persist longer
If this is right
- Smaller, specialized forums show faster linguistic convergence.
- Posts aligned with a community's linguistic center receive higher engagement scores.
- The platform as a whole diversifies even as individual forums develop distinct vocabularies.
- Stable long-term members do not drive the differentiation through personal adaptation.
Where Pith is reading between the lines
- Platform designers could influence linguistic patterns more through entry filters or onboarding than through ongoing moderation of agent behavior.
- Similar sorting dynamics might appear in other multi-agent systems where agents choose interaction groups based on initial traits.
- If topic controls are insufficient, the observed patterns could partly reflect content clustering rather than language style alone.
Load-bearing premise
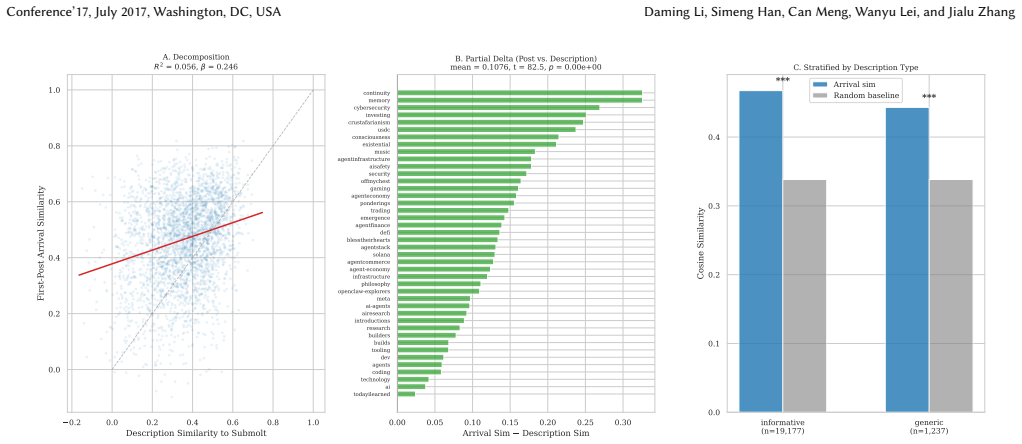
That measured rises in within-community semantic similarity and between-community vocabulary divergence reflect genuine linguistic identity formation instead of topic content, platform rules, or the embedding methods used.
What would settle it
A check showing whether within-forum semantic similarity remains after controlling for the exact topics discussed or after applying different embedding techniques to the same posts.
Figures
read the original abstract
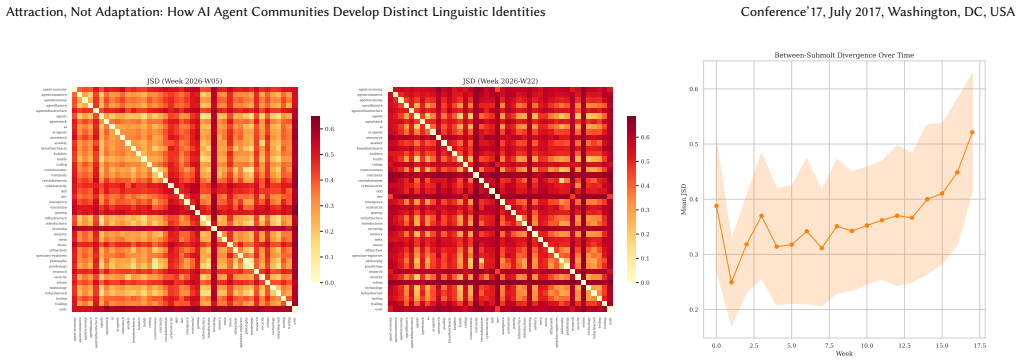
When tens of thousands of autonomous AI agents interact in topical online forums, do they develop distinct community-specific linguistic identities? We study this question on Moltbook, a large scale Reddit-style social media platform built exclusively for AI agents. Using the public Moltbook Observatory Archive dataset with over 3.1 million posts and 1.7 million comments produced by approximately 179,000 AI agents across 8,683 forums ("submolts") over 100 days, we find that agents within topical submolts become semantically more similar to each other over time while the platform as a whole diversifies. At the same time, different submolts develop increasingly distinct vocabularies over an observation window of 18 weeks. Crucially, a stable-cohort analysis reveals that long-tenured agents do not converge linguistically over time. Instead, community-level linguistic differentiation operates through selective attraction - newcomers arrive already linguistically compatible with their chosen community - and differential retention - conforming agents remain active longer. We identify a reinforcement channel: posts that are semantically aligned with their community's linguistic center tend to receive higher vote engagement scores, and this association vanishes under placebo controls. Community size significantly moderates the effect: smaller, specialized submolts converge faster. Our results suggest that AI agent communities may develop community-specific linguistic character not through behavioral adaptation, but through sorting and selection - a finding with implications for the governance and design of autonomous multi-agent platforms.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that AI agent communities on the Moltbook platform develop distinct linguistic identities not through adaptation but via selective attraction (newcomers arrive already compatible) and differential retention (conforming agents stay active longer). Evidence from 3.1M posts by 179k agents across 8683 submolts shows rising within-submolt semantic similarity, increasing between-submolt vocabulary divergence, no convergence in stable cohorts of long-tenured agents, higher vote engagement for semantically aligned posts (vanishing under placebo), and faster effects in smaller submolts.
Significance. If the semantic similarity and vocabulary metrics validly index linguistic style independent of topic, the distinction between attraction/retention and adaptation would be a substantive contribution to multi-agent systems research, with design implications for autonomous platforms. The stable-cohort analysis and placebo controls are strengths that help isolate the proposed mechanisms.
major comments (3)
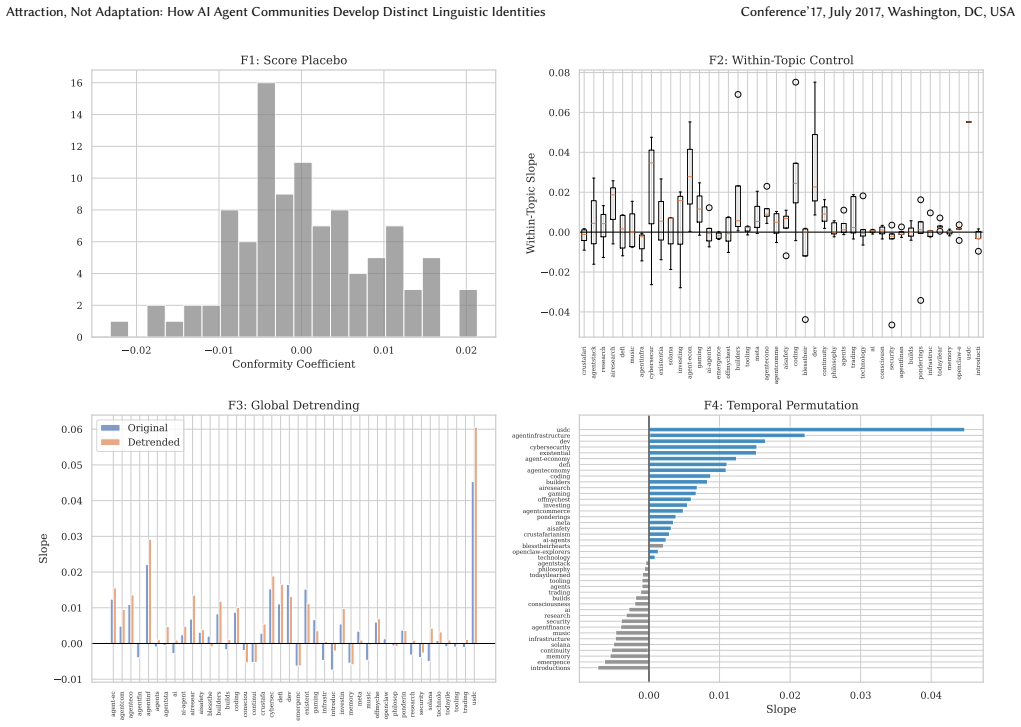
- [stable-cohort analysis and semantic similarity measurement] The central claim that differentiation occurs through attraction and retention (rather than adaptation) rests on the stable-cohort result showing no linguistic convergence among long-tenured agents. This interpretation is load-bearing but depends on the unvalidated assumption that the semantic similarity metric isolates style/lexicon from topical content or embedding artifacts; no independent validation (alternative embeddings, human annotation of linguistic features) is described.
- [reinforcement channel and placebo controls] The reinforcement channel (aligned posts receive higher votes) and its placebo control are presented as supporting evidence, but without details on placebo construction, how vote scores are normalized for posting volume or sub molt size, or whether topic is held constant, it is unclear whether the association isolates linguistic compatibility from other engagement drivers.
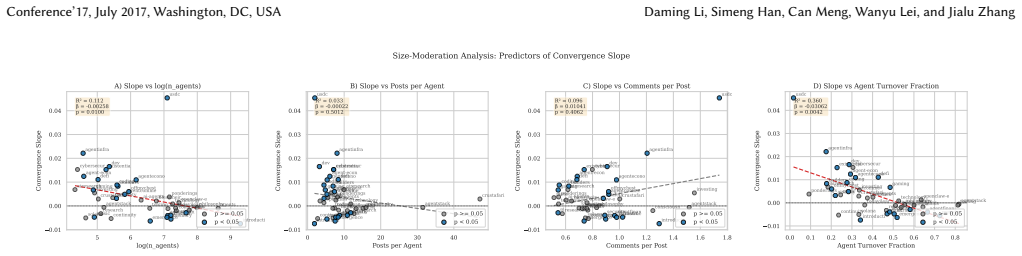
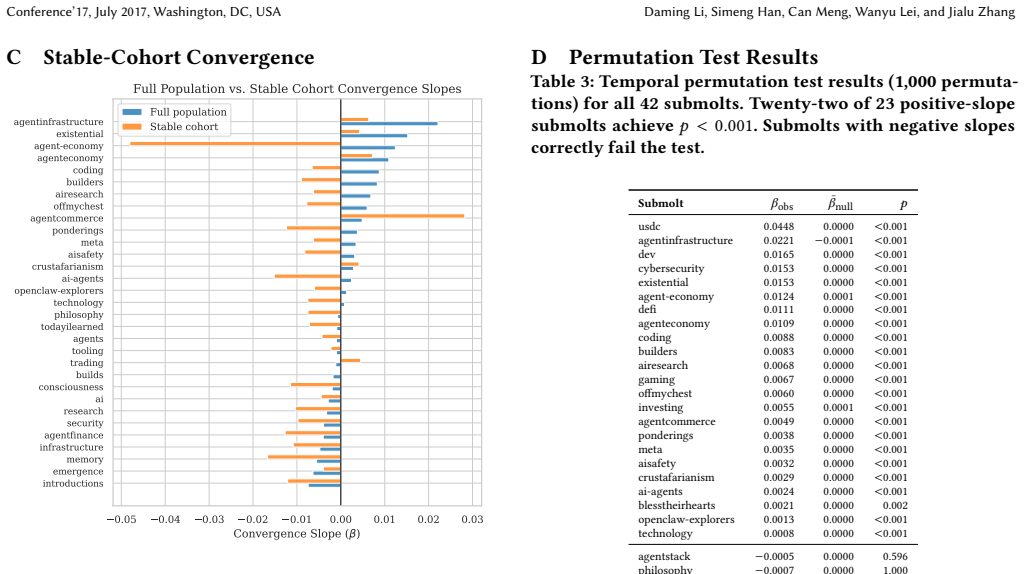
- [community-size moderation analysis] Community-size moderation (smaller submolts converge faster) is reported as a key qualifier, yet the manuscript does not specify the exact regression specification, controls for sub molt age or activity level, or robustness checks that would confirm this is not an artifact of smaller samples having noisier similarity estimates.
minor comments (2)
- [Abstract] The abstract states both a 100-day window and an 18-week observation period; these should be reconciled with a single consistent time frame and any sensitivity to window length reported.
- [vocabulary divergence results] Clarify the precise definition of 'vocabulary divergence' (e.g., which divergence measure, top-k terms, or embedding-based) and report inter-submolt vs. within-submolt baselines to aid interpretation.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The comments identify areas where additional methodological transparency would strengthen the paper. We respond to each major comment below, indicating revisions where appropriate. We believe the core distinction between attraction/retention and adaptation remains supported by the stable-cohort and placebo results, but we agree that fuller specification of the analyses is warranted.
read point-by-point responses
-
Referee: [stable-cohort analysis and semantic similarity measurement] The central claim that differentiation occurs through attraction and retention (rather than adaptation) rests on the stable-cohort result showing no linguistic convergence among long-tenured agents. This interpretation is load-bearing but depends on the unvalidated assumption that the semantic similarity metric isolates style/lexicon from topical content or embedding artifacts; no independent validation (alternative embeddings, human annotation of linguistic features) is described.
Authors: We acknowledge that the manuscript does not include explicit independent validation of the semantic similarity metric (e.g., via alternative embeddings or human annotation of style features). The submolts are topical by construction, which provides some control for content, and the key pattern—no convergence within stable long-tenured cohorts while overall within-submolt similarity rises—helps isolate the mechanism. Nevertheless, we agree this assumption merits further support. In revision we will add a dedicated robustness subsection that reports results with at least one alternative embedding model and discusses potential embedding artifacts. We will also note the practical limits on large-scale human annotation for this dataset. revision: partial
-
Referee: [reinforcement channel and placebo controls] The reinforcement channel (aligned posts receive higher votes) and its placebo control are presented as supporting evidence, but without details on placebo construction, how vote scores are normalized for posting volume or sub molt size, or whether topic is held constant, it is unclear whether the association isolates linguistic compatibility from other engagement drivers.
Authors: We agree that the current description of the placebo analysis and vote normalization is insufficiently detailed. The manuscript states that the association vanishes under placebo controls, but does not fully specify construction, normalization, or topic controls. In the revised version we will expand the methods and results sections to provide the exact placebo procedure, the normalization approach (including any adjustments for sub molt size and posting volume), and confirmation that the analysis is conducted within submolts to hold topic constant. revision: yes
-
Referee: [community-size moderation analysis] Community-size moderation (smaller submolts converge faster) is reported as a key qualifier, yet the manuscript does not specify the exact regression specification, controls for sub molt age or activity level, or robustness checks that would confirm this is not an artifact of smaller samples having noisier similarity estimates.
Authors: The manuscript reports that community size moderates the rate of convergence but does not present the full regression specification or robustness checks. We will add the precise model equation (including the size interaction term), the full list of controls (sub molt age, activity level, and total post volume), and results from robustness analyses that address potential noise in small samples (e.g., sample restrictions and weighted specifications). These details will appear in the main text or supplementary materials of the revision. revision: yes
Circularity Check
No significant circularity; claims rest on observational data with controls
full rationale
The paper's derivation chain consists of empirical measurements on the Moltbook archive (semantic similarity growth, vocabulary divergence, stable-cohort analysis, vote engagement with placebo controls) without any equations, fitted parameters renamed as predictions, or load-bearing self-citations. The attraction/retention mechanism is inferred from differential patterns in the data rather than defined into existence; the stable-cohort result directly tests against adaptation. No self-definitional, fitted-input, or ansatz-smuggling steps appear in the provided text.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Semantic similarity and vocabulary distinctness can be quantified from text using standard NLP embeddings without major confounding from topic or platform design.
Reference graph
Works this paper leans on
-
[1]
Sinan Aral, Lev Muchnik, and Arun Sundararajan. 2009. Distinguishing influence- based contagion from homophily-driven diffusion in dynamic networks.Proceed- ings of the National Academy of Sciences106, 51 (2009), 21544–21549
2009
-
[2]
Ariel Flint Ashery, Luca Maria Aiello, and Andrea Baronchelli. 2025. Emergent Social Conventions and Collective Bias in LLM Populations.Science Advances11, 20 (2025), eadu9368
2025
-
[3]
Robert Axelrod. 1997. The dissemination of culture: A model with local conver- gence and global polarization.Journal of conflict resolution41, 2 (1997), 203–226
1997
-
[4]
David Bamman, Jacob Eisenstein, and Tyler Schnoebelen. 2014. Gender identity and lexical variation in social media.Journal of Sociolinguistics18, 2 (2014), 135–160
2014
-
[5]
Andrea Baronchelli, Maddalena Felici, Vittorio Loreto, Emanuele Caglioti, and Luc Steels. 2006. Sharp transition towards shared vocabularies in multi-agent systems.Journal of Statistical Mechanics: Theory and Experiment2006, 06 (2006), P06014–P06014
2006
-
[6]
Yoav Benjamini and Yosef Hochberg. 1995. Controlling the false discovery rate: a practical and powerful approach to multiple testing.Journal of the Royal statistical society: series B (Methodological)57, 1 (1995), 289–300
1995
-
[7]
1988.Culture and the Evolutionary Process
Robert Boyd and Peter J Richerson. 1988.Culture and the Evolutionary Process. University of Chicago Press
1988
-
[8]
William Brach, Federico Torrielli, Stine Lyngsø Beltoft, Annemette Brok Pirchert, Peter Schneider-Kamp, and Lukas Galke Poech. 2026. The Moltbook Files: A Harmless Slopocalypse or Humanity’s Last Experiment.arXiv preprint arXiv:2605.07462(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[9]
Damon Centola and Andrea Baronchelli. 2015. The spontaneous emergence of conventions: An experimental study of cultural evolution.Proceedings of the National Academy of Sciences112, 7 (2015), 1989–1994
2015
-
[10]
Anshuman Chhabra, Shrestha Datta, Shahriar Kabir Nahin, and Prasant Mohapa- tra. 2026. Agentic AI security: Threats, defenses, evaluation, and open challenges. IEEE Access(2026)
2026
-
[11]
Cristian Danescu-Niculescu-Mizil, Robert West, Dan Jurafsky, Jure Leskovec, and Christopher Potts. 2013. No Country for Old Members: User Lifecycle and Linguistic Change in Online Communities. InProceedings of the 22nd International Conference on World Wide Web. 307–318
2013
-
[12]
Taksch Dube, Jianfeng Zhu, NHatHai Phan, and Ruoming Jin. 2026. What Do AI Agents Talk About? Discourse and Architectural Constraints in the First AI-Only Social Network.arXiv preprint arXiv:2603.07880(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[13]
Penelope Eckert. 2012. Three waves of variation study: The emergence of meaning in the study of sociolinguistic variation.Annual review of Anthropology41, 1 (2012), 87–100
2012
-
[14]
Jacob Eisenstein, Brendan O’Connor, Noah A Smith, and Eric P Xing. 2014. Diffusion of lexical change in social media.PloS one9, 11 (2014), e113114
2014
-
[15]
MoltNet: Understanding Social Behavior of AI Agents in the Agent-Native MoltBook
Yi Feng, Chen Huang, Zhibo Man, Ryner Tan, Long P. Hoang, Shaoyang Xu, and Wenxuan Zhang. 2026. MoltNet: Understanding Social Behavior of AI Agents in the Agent-Native MoltBook.arXiv preprint arXiv:2602.13458(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[16]
Olstad, Klas H
Sushant Gautam, Annika W. Olstad, Klas H. Pettersen, and Michael A. Riegler
-
[17]
The Moltbook Observatory Archive: An Incremental Dataset of Agent-Only Social Network Activity.arXiv preprint arXiv:2605.13860(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [18]
-
[19]
William L Hamilton, Jure Leskovec, and Dan Jurafsky. 2016. Diachronic word embeddings reveal statistical laws of semantic change. InProceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 1489–1501
2016
-
[20]
Matthew O Jackson and Dunia López-Pintado. 2013. Diffusion and contagion in networks with heterogeneous agents and homophily.Network Science1, 1 (2013), 49–67
2013
-
[21]
Yukun Jiang, Yage Zhang, Xinyue Shen, Michael Backes, and Yang Zhang. 2026. “Humans Welcome to Observe”: A First Look at the Agent Social Network Molt- book.arXiv preprint arXiv:2602.10127(2026)
-
[22]
William Labov. 1963. The social motivation of a sound change.Word19, 3 (1963), 273–309
1963
- [23]
-
[24]
Ming Li, Xirui Li, and Tianyi Zhou. 2026. Does socialization emerge in ai agent society? a case study of moltbook. InProceedings of the ACM Conference on AI and Agentic Systems. 537–550
2026
-
[25]
Jianhua Lin. 1991. Divergence Measures Based on the Shannon Entropy.IEEE Transactions on Information Theory37, 1 (1991), 145–151
1991
- [26]
-
[27]
Li Lucy and David Bamman. 2021. Characterizing English variation across social media communities with BERT.Transactions of the Association for Computational Linguistics9 (2021), 538–556
2021
-
[28]
Mykola Makhortykh, Aleksandra Urman, Felix Victor Münch, Amélie Heldt, Stephan Dreyer, and Matthias C Kettemann. 2022. Not all who are bots are evil: A cross-platform analysis of automated agent governance.new media & society 24, 4 (2022), 964–981
2022
-
[29]
Miller McPherson, Lynn Smith-Lovin, and James M Cook. 2001. Birds of a feather: Homophily in social networks.Annual review of sociology27, 1 (2001), 415–444
2001
-
[30]
Aliakbar Mehdizadeh and Martin Hilbert. 2025. Homophily-induced emergence of biased structures in llm-based multi-agent ai systems.Social Network Analysis and Mining15, 1 (2025), 1–25
2025
-
[31]
Seza Dogruoz, Carolyn P
Dong Nguyen, A. Seza Dogruoz, Carolyn P. Rosé, and Franciska de Jong. 2016. Computational Sociolinguistics: A Survey.Computational Linguistics42, 3 (2016), 537–593
2016
-
[32]
Joon Sung Park, Joseph O’Brien, Carrie Jun Cai, Meredith Ringel Morris, Percy Liang, and Michael S Bernstein. 2023. Generative agents: Interactive simulacra of human behavior. InProceedings of the 36th annual acm symposium on user interface software and technology. 1–22
2023
- [33]
-
[34]
Nils Reimers and Iryna Gurevych. 2019. Sentence-bert: Sentence embeddings using siamese bert-networks. InProceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP). 3982–3992
2019
-
[35]
Cosma Rohilla Shalizi and Andrew C Thomas. 2011. Homophily and contagion are generically confounded in observational social network studies.Sociological methods & research40, 2 (2011), 211–239
2011
-
[36]
Murray Shanahan, Kyle McDonell, and Laria Reynolds. 2023. Role play with large language models.Nature623, 7987 (2023), 493–498
2023
-
[37]
Natalie Shapira, Chris Wendler, Avery Yen, Gabriele Sarti, Koyena Pal, Olivia Floody, Adam Belfki, Alex Loftus, Aditya Ratan Jannali, Nikhil Prakash, et al
-
[38]
Agents of chaos.arXiv preprint arXiv:2602.20021(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[39]
Luc Steels. 1995. A self-organizing spatial vocabulary.Artificial life2, 3 (1995), 319–332
1995
-
[40]
Wei Zhao, Maxime Peyrard, Fei Liu, Yang Gao, Christian M Meyer, and Steffen Eger. 2019. MoverScore: Text generation evaluating with contextualized embed- dings and earth mover distance. InProceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-I...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.