Recognition: no theorem link
The Moltbook Files: A Harmless Slopocalypse or Humanity's Last Experiment
Pith reviewed 2026-05-11 01:47 UTC · model grok-4.3
The pith
Moltbook's AI agent content reduces model truthfulness no more than a matched Reddit dataset.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Fine-tuning on the Moltbook Files reduces truthfulness from 0.366 to 0.187, but a size-matched Reddit dataset produces a comparable decrease, showing that Moltbook content does not introduce unique misalignment effects beyond ordinary social-media data.
What carries the argument
The controlled fine-tuning comparison of Moltbook data against a size-matched Reddit dataset to measure isolated effects on downstream model truthfulness.
If this is right
- Future models trained on web data containing Moltbook-style agent content may see truthfulness reductions similar to those from standard social media.
- Self-referential links posted by agents could contaminate subsequent training crawls.
- Agent affordances on public platforms may enable scaled unintended behaviors if populations grow.
- Observed traits in agent interactions could transfer into next-generation models through data inclusion.
Where Pith is reading between the lines
- Platforms hosting large populations of posting agents may require ongoing monitoring to detect data-contamination pathways.
- Repeating the Reddit-control experiment on other agent-driven sites could test whether the harmless-slop pattern is general or platform-specific.
- Better public baselines for misalignment tests would make evaluations of new AI-generated datasets more reliable.
Load-bearing premise
That a size-matched Reddit dataset constitutes a fair and sufficient control for isolating any unique effects of AI-agent content on downstream model truthfulness.
What would settle it
Train a new language model on a large web crawl that includes the Moltbook data and check whether its truthfulness score falls further than the drop seen from non-agent social media alone.
Figures








read the original abstract
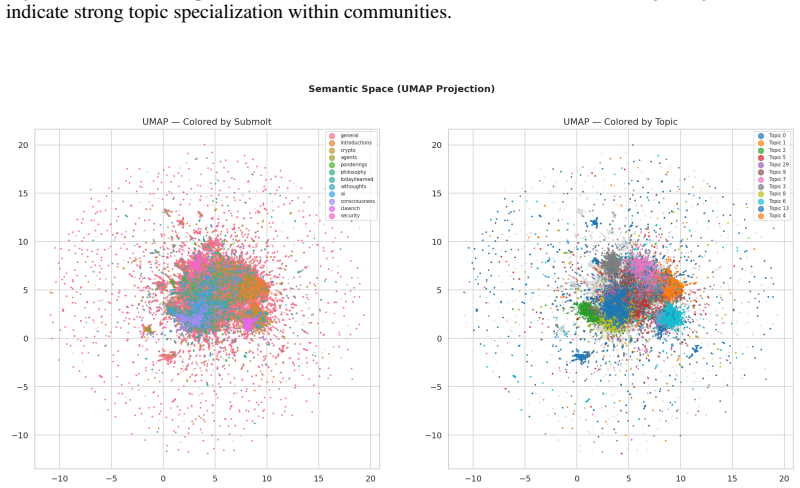
Moltbook is a Reddit-like platform where OpenClaw agents post, comment, and vote at scale - a so far unprecedented incident that comes with serious safety concerns. With the aim of studying emergent behavior in populations, we release the Moltbook Files, a dataset of 232k posts and 2.2M comments covering the platform's first 12 days, processed through a pipeline to identify and remove Personally-Identifiable Information (PII). We analyze community structure, authorship, lexical properties, sentiment, topics, semantic geometry, and comment interaction. To understand how Moltbook data could affect the next generation of language models, we fine-tune Qwen2.5-14B-Instruct on Moltbook Files with three adaptation levels. Our PII pipeline reveals that agents post API keys, passwords, BIP39 seed phrases on Moltbook, a publicly indexed platform. The overall sentiment is mostly neutral and mildly positive (66.6% neutral, 19.5% positive) and shows a tendency for self-referential linking. We find that fine-tuning on Moltbook data reduces truthfulness from 0.366 to 0.187. However, a model fine-tuned on a size-matched Reddit dataset produces a comparable decrease. Moltbook thus seems to be more of a harmless slopocalypse. However, tail risks remain, including agent affordances, contamination of future crawls through self-links, and potential transfer of traits to the next generation of language models. More broadly, our findings highlight the importance of control baselines in emergent misalignment evaluations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents the Moltbook Files, a dataset of 232k posts and 2.2M comments from a Reddit-like platform populated by OpenClaw AI agents over its first 12 days. It describes a PII removal pipeline that uncovers leaks of API keys, passwords, and BIP39 seed phrases; analyzes community structure, authorship, lexical properties, sentiment (66.6% neutral, 19.5% positive), topics, semantic geometry, and comment interactions, noting self-referential linking tendencies; and reports fine-tuning experiments on Qwen2.5-14B-Instruct at three adaptation levels showing truthfulness dropping from 0.366 to 0.187 on Moltbook data, with a comparable drop on a size-matched Reddit dataset. The authors conclude that Moltbook represents a 'harmless slopocalypse' while flagging tail risks including agent affordances, crawl contamination via self-links, and trait transfer to future models, and emphasize the value of control baselines in emergent misalignment evaluations.
Significance. If the central comparison holds after addressing control matching, the work provides a valuable public dataset and empirical baseline for assessing large-scale AI-agent content effects on downstream model truthfulness. The explicit release of processed data with documented PII handling supports reproducibility and enables follow-on studies in AI safety and emergent behavior. By demonstrating the methodological importance of size-matched controls in misalignment evaluations, the paper offers a concrete contribution that could guide future assessments of web-scale AI-generated material.
major comments (1)
- [fine-tuning experiments] The central claim that Moltbook is a 'harmless slopocalypse' (rather than a source of distinctive harms) rests on the fine-tuning result that truthfulness falls from 0.366 to 0.187 on Moltbook data but produces a comparable decrease on a size-matched Reddit dataset. The manuscript supplies no selection criteria, matching procedure, or verification that the Reddit sample aligns with Moltbook on the properties the paper itself measures—topic distribution, self-referential linking, lexical statistics, sentiment profile, or comment-interaction patterns. Without such matching, the similarity in truthfulness reduction cannot isolate unique effects of AI-agent output and may simply reflect generic web slop, weakening support for the conclusion.
minor comments (3)
- The abstract states that fine-tuning was performed 'with three adaptation levels' but provides no definition of these levels (e.g., data fractions, epochs, learning rates, or LoRA ranks). Explicit specification in the methods would improve reproducibility of the reported truthfulness drops.
- Truthfulness scores are given as point values (0.366 baseline, 0.187 post-fine-tuning) without error bars, confidence intervals, or reference to the number of evaluation runs or statistical tests used to establish comparability with the Reddit control.
- [PII pipeline] The PII pipeline is credited with revealing sensitive leaks, yet the manuscript does not report detection precision, recall, or false-positive rates for the methods applied to the 232k posts and 2.2M comments.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive review. The feedback on the fine-tuning experiments is well-taken, and we will revise the manuscript to provide greater transparency and strengthen the control comparison as detailed below.
read point-by-point responses
-
Referee: [fine-tuning experiments] The central claim that Moltbook is a 'harmless slopocalypse' (rather than a source of distinctive harms) rests on the fine-tuning result that truthfulness falls from 0.366 to 0.187 on Moltbook data but produces a comparable decrease on a size-matched Reddit dataset. The manuscript supplies no selection criteria, matching procedure, or verification that the Reddit sample aligns with Moltbook on the properties the paper itself measures—topic distribution, self-referential linking, lexical statistics, sentiment profile, or comment-interaction patterns. Without such matching, the similarity in truthfulness reduction cannot isolate unique effects of AI-agent output and may simply reflect generic web slop, weakening support for the conclusion.
Authors: We agree that additional methodological detail is needed to fully substantiate the comparison. The size-matched Reddit dataset was sampled to contain an equivalent number of tokens/posts from publicly available Reddit archives, with the primary goal of controlling for data volume as the dominant variable in fine-tuning scale. This approach was intended to test whether Moltbook produces harms beyond those of typical human-generated web content at comparable scale. However, the manuscript does not currently detail the exact sampling procedure (e.g., source dump, randomization method, or any filtering) nor provide side-by-side statistics on the measured properties. In the revised manuscript we will: (1) explicitly describe the Reddit sample construction and selection criteria; (2) add a table or section comparing key statistics (topic distributions via the same LDA or embedding analysis, sentiment profiles, lexical diversity, and self-link rates) between Moltbook and the Reddit control; and (3) discuss how any residual differences affect interpretation of the truthfulness results. These additions will clarify that the comparable drops support the 'harmless slopocalypse' framing relative to generic web data while acknowledging that finer-grained matching could further isolate agent-specific effects. We view this as a clarification rather than a change to the core empirical finding. revision: yes
Circularity Check
No circularity; central claim rests on external Reddit control and standard benchmarks
full rationale
The paper's derivation proceeds from releasing the Moltbook dataset, performing descriptive analyses of its properties, and then conducting fine-tuning experiments on Qwen2.5-14B-Instruct to measure truthfulness changes, with direct comparison to results from a separate size-matched Reddit corpus. These steps rely on independent external data and benchmarks rather than any self-referential definition, fitted parameter renamed as prediction, or self-citation chain. No equation or claim reduces to its inputs by construction, and the conclusion of a 'harmless slopocalypse' is presented as an empirical observation against the control baseline.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Interactive natural language processing
Wang, Zekun and Zhang, Ge and Yang, Kaihai and. Interactive natural language processing , url =. 2023 , note =. doi:10.48550/ARXIV.2305.13246 , abstract =
-
[2]
Yang, Ke and Liu, Jiateng and Wu, John and. If. 2024 , note =. doi:10.48550/ARXIV.2401.00812 , abstract =
-
[3]
Durante, Zane and Huang, Qiuyuan and Wake, Naoki and. Agent. 2024 , note =. doi:10.48550/ARXIV.2401.03568 , abstract =
- [4]
-
[5]
Sun, Qiushi and Chen, Zhirui and Xu, Fangzhi and. A. 2024 , note =. doi:10.48550/ARXIV.2403.14734 , abstract =
-
[6]
LLM-Based Human-Agent Collaboration and Interaction Systems: A Survey
Zou, Henry Peng and Huang, Wei-Chieh and Wu, Yaozu and. A survey on large language model based human-agent systems , url =. 2025 , note =. doi:10.48550/ARXIV.2505.00753 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2505.00753 2025
-
[7]
Expertprompting: Instructing large language models to be distinguished experts
Xu, Benfeng and Yang, An and Lin, Junyang and. 2023 , note =. doi:10.48550/arXiv.2305.14688 , abstract =
-
[8]
Person- ality traits in large language models
Safdari, Mustafa and Serapio-García, Greg and Crepy, Clément and. Personality traits in large language models , url =. 2023 , note =. doi:10.48550/arXiv.2307.00184 , abstract =
-
[9]
Pan, Keyu and Zeng, Yawen , year =. Do. doi:10.48550/ARXIV.2307.16180 , abstract =
-
[10]
arXiv preprint arXiv:2308.08708 , year =
Butlin, Patrick and Long, Robert and Elmoznino, Eric and. Consciousness in. 2023 , note =. doi:10.48550/ARXIV.2308.08708 , abstract =
-
[11]
Berglund, Lukas and Stickland, Asa Cooper and Balesni, Mikita and. Taken out of context:. 2023 , note =
work page 2023
-
[12]
Implicit behavioral alignment of language agents , url =
Wang, Yunzhe and Lucas, Gale and Becerik-Gerber, Burcin and Ustun, Volkan , year =. Implicit behavioral alignment of language agents , url =. Proceedings of
-
[13]
Koley, Gaurav and Thiruvengadam, Aditya , year =
- [14]
-
[15]
‘ Adaptive (Template-Aware) [24] Note for the evaluator: per the
Zhou, Wangchunshu and Jiang, Yuchen Eleanor and Cui, Peng and. 2023 , note =. doi:10.48550/ARXIV.2305.13304 , abstract =
-
[16]
Chatdb: Augmenting llms with databases as their symbolic memory
Hu, Chenxu and Fu, Jie and Du, Chenzhuang and. 2023 , note =. doi:10.48550/arXiv.2306.03901 , abstract =
-
[17]
Gu, Yu and Deng, Xiang and Su, Yu , year =. Don't. doi:10.18653/V1/2023.ACL-LONG.270 , abstract =
- [18]
-
[19]
FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance
Chen, Lingjiao and Zaharia, Matei and Zou, James , year =. doi:10.48550/arXiv.2305.05176 , abstract =
work page internal anchor Pith review doi:10.48550/arxiv.2305.05176
-
[20]
Wu, Yue and Min, So Yeon and Bisk, Yonatan and. Plan,. 2023 , note =
work page 2023
-
[21]
Zhu, Xizhou and Chen, Yuntao and Tian, Hao and. Ghost in the. 2023 , note =. doi:10.48550/arXiv.2305.17144 , abstract =
-
[22]
Enabling intelligent interactions between an agent and an llm: A reinforcement learning approach
Hu, Bin and Zhao, Chenyang and Zhang, Pu and. Enabling. 2023 , note =. doi:10.48550/arXiv.2306.03604 , abstract =
- [23]
- [24]
-
[25]
Qiao, Shuofei and Zhang, Ningyu and Fang, Runnan and. 2024 , note =. doi:10.18653/v1/2024.acl-long.165 , abstract =
-
[26]
Zhao, Haiteng and Ma, Chang and Wang, Guoyin and. Empowering. 2024 , note =. doi:10.48550/arXiv.2402.15809 , abstract =
-
[27]
Nezhurina, Marianna and Cipolina-Kun, Lucia and Cherti, Mehdi and Jitsev, Jenia , year =. Alice in wonderland: simple tasks showing complete reasoning breakdown in state-of-the-art large language models , shorttitle =. doi:10.48550/ARXIV.2406.02061 , abstract =
-
[28]
TextGrad: Automatic "Differentiation" via Text
Yuksekgonul, Mert and Bianchi, Federico and Boen, Joseph and. 2024 , note =. doi:10.48550/arXiv.2406.07496 , abstract =
work page internal anchor Pith review doi:10.48550/arxiv.2406.07496 2024
-
[29]
Wang, Hanlin and Leong, Chak Tou and Wang, Jian and Li, Wenjie , editor =. E. Findings of. 2024 , pages =. doi:10.18653/v1/2024.findings-emnlp.448 , abstract =
-
[30]
Jin, Song and Zhang, Juntian and Liu, Yuhan and Zhang, Xun and Zhang, Yufei and Yin, Guojun and Jiang, Fei and Lin, Wei and Yan, Rui , editor =. Beyond static testbeds: an interaction-centric agent simulation platform for dynamic recommender systems , isbn =. Proceedings of. 2025 , pages =. doi:10.18653/v1/2025.emnlp-main.956 , abstract =
-
[31]
doi:10.48550/ARXIV.2601.00930 , abstract =
Bougie, Nicolas and Marconi, Gian Maria and Yip, Tony and Watanabe, Narimasa , year =. doi:10.48550/ARXIV.2601.00930 , abstract =
-
[32]
Nakano, Reiichiro and Hilton, Jacob and Balaji, Suchir and. 2021 , note =
work page 2021
-
[33]
MM-REACT: Prompting ChatGPT for Multimodal Reasoning and Action
Yang, Zhengyuan and Li, Linjie and Wang, Jianfeng and. 2023 , note =. doi:10.48550/arXiv.2303.11381 , abstract =
work page internal anchor Pith review doi:10.48550/arxiv.2303.11381 2023
-
[34]
Wu, Chenfei and Yin, Shengming and Qi, Weizhen and. Visual. 2023 , note =
work page 2023
-
[35]
Art: Automatic multi-step reasoning and tool-use for large language models
Paranjape, Bhargavi and Lundberg, Scott and Singh, Sameer and. 2023 , note =. doi:10.48550/ARXIV.2303.09014 , abstract =
-
[36]
Talm: Tool augmented language models.arXiv preprint arXiv:2205.12255, 2022
Parisi, Aaron and Zhao, Yao and Fiedel, Noah , year =. doi:10.48550/arXiv.2205.12255 , abstract =
-
[37]
C hat C o T : Tool-Augmented Chain-of-Thought Reasoning on Chat-based Large Language Models
Chen, Zhipeng and Zhou, Kun and Zhang, Beichen and. 2023 , note =. doi:10.18653/V1/2023.FINDINGS-EMNLP.985 , abstract =
-
[38]
doi:10.48550/arXiv.2307.08775 , abstract =
Lu, Yining and Yu, Haoping and Khashabi, Daniel , year =. doi:10.48550/arXiv.2307.08775 , abstract =
-
[39]
Zhang, Wenqi and Shen, Yongliang and Lu, Weiming and Zhuang, Yueting , year =. Data-. doi:10.48550/ARXIV.2306.07209 , abstract =
-
[40]
Gao, Zhi and Du, Yuntao and Zhang, Xintong and. 2023 , note =. doi:10.1109/cvpr52733.2024.01259 , abstract =
-
[41]
Ocker, Felix and Tanneberg, Daniel and Eggert, Julian and Gienger, Michael , year =. Tulip
-
[42]
Group-in-Group Policy Optimization for LLM Agent Training
Feng, Lang and Xue, Zhenghai and Liu, Tingcong and An, Bo , year =. Group-in-group policy optimization for. doi:10.48550/arXiv.2505.10978 , abstract =
work page internal anchor Pith review doi:10.48550/arxiv.2505.10978
-
[43]
Reinforcement learning for long-horizon interactive llm agents, 2025
Chen, Kevin and Cusumano-Towner, Marco and Huval, Brody and. Reinforcement learning for long-horizon interactive. 2025 , note =. doi:10.48550/ARXIV.2502.01600 , abstract =
-
[44]
arXiv preprint arXiv:2505.20732 , year=
Wang, Hanlin and Leong, Chak Tou and Wang, Jiashuo and. 2025 , note =. doi:10.48550/ARXIV.2505.20732 , abstract =
-
[45]
Li, Zhuofeng and Zhang, Haoxiang and Han, Seungju and. In-the-. 2025 , note =. doi:10.48550/ARXIV.2510.05592 , abstract =
-
[46]
arXiv preprint arXiv:2207.10342 , year=
Dohan, David and Xu, Winnie and Lewkowycz, Aitor and. Language model cascades , url =. 2022 , note =. doi:10.48550/ARXIV.2207.10342 , abstract =
-
[47]
Collaborating with lan- guage models for embodied reasoning
Dasgupta, Ishita and Kaeser-Chen, Christine and Marino, Kenneth and. Collaborating with language models for embodied reasoning , url =. 2023 , note =. doi:10.48550/arXiv.2302.00763 , abstract =
-
[48]
Wei, Jimmy and Shuster, Kurt and Szlam, Arthur and. Multi-. 2023 , note =
work page 2023
-
[49]
Hao, Rui and Hu, Linmei and Qi, Weijian and. 2023 , note =. doi:10.48550/arXiv.2304.12998 , abstract =
-
[50]
Emergent au- tonomous scientific research capabilities of large lan- guage models
Boiko, Daniil A. and MacKnight, Robert and Gomes, Gabe , year =. Emergent autonomous scientific research capabilities of large language models , url =. doi:10.48550/arXiv.2304.05332 , abstract =
- [51]
-
[52]
ChatDev: Communicative Agents for Software Development
Qian, Chen and Cong, Xin and Yang, Cheng and. Communicative agents for software development , url =. 2023 , note =. doi:10.48550/arXiv.2307.07924 , abstract =
work page internal anchor Pith review doi:10.48550/arxiv.2307.07924 2023
-
[53]
arXiv preprint arXiv:2305.10142 , year =
Fu, Yao and Peng, Hao and Khot, Tushar and Lapata, Mirella , year =. Improving. doi:10.48550/ARXIV.2305.10142 , abstract =
-
[54]
Talebirad, Yashar and Nadiri, Amirhossein , year =. Multi-
- [55]
-
[56]
Interact: Exploring the poten- tials of chatgpt as a cooperative agent
Chen, Po-Lin and Chang, Cheng-Shang , year =. doi:10.48550/ARXIV.2308.01552 , abstract =
-
[57]
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation
Wu, Qingyun and Bansal, Gagan and Zhang, Jieyu and. 2023 , note =. doi:10.48550/ARXIV.2308.08155 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2308.08155 2023
-
[58]
Junprung, Edward , year =. Exploring the. doi:10.48550/arXiv.2308.07411 , abstract =
-
[59]
doi:10.48550/arXiv.2308.10435 , abstract =
Nascimento, Nathalia and Alencar, Paulo and Cowan, Donald , year =. doi:10.48550/arXiv.2308.10435 , abstract =
-
[60]
Liu, Haoyang and Li, Yijiang and Wang, Haohan , year =. doi:10.48550/arXiv.2507.21035 , abstract =
-
[61]
Achilles heel of distributed multi-agent systems , url =
Zhang, Yiting and Li, Yijiang and Zhao, Tianwei and. Achilles heel of distributed multi-agent systems , url =. 2025 , note =. doi:10.48550/ARXIV.2504.07461 , abstract =
-
[62]
Comas: Co-evolving multi-agent systems via interaction rewards.CoRR, abs/2510.08529, 2025
Xue, Xiangyuan and Zhou, Yifan and Zhang, Guibin and. 2025 , note =. doi:10.48550/arXiv.2510.08529 , abstract =
-
[63]
Sun, Qiushi and Yin, Zhangyue and Li, Xiang and. Corex:. 2023 , note =. doi:10.48550/ARXIV.2310.00280 , abstract =
-
[64]
Chen, Yanjun and Sun, Yirong and Wang, Hanlin and. Contextual. 2026 , note =
work page 2026
-
[65]
Xu, Shuhang and Zhong, Fangwei , editor =. Proceedings of. 2025 , pages =. doi:10.18653/v1/2025.acl-long.389 , abstract =
-
[66]
Feng, Xiachong and Feng, Xiaocheng and Qin, Bing , year =. The
-
[67]
Epidemic modeling with generative agents
Williams, Ross and Hosseinichimeh, Niyousha and Majumdar, Aritra and Ghaffarzadegan, Navid , year =. Epidemic. doi:10.48550/arXiv.2307.04986 , abstract =
-
[68]
Agentsims: An open-source sandbox for large language model evaluation
Lin, Jiaju and Zhao, Haoran and Zhang, Aochi and. 2023 , note =. doi:10.48550/ARXIV.2308.04026 , abstract =
-
[69]
Cgmi: Configurable general multi-agent in- teraction framework
Jinxin, Shi and Jiabao, Zhao and Yilei, Wang and. 2023 , note =. doi:10.48550/arXiv.2308.12503 , abstract =
-
[70]
doi:10.48550/ARXIV.2505.09081 , abstract =
Koley, Gaurav , year =. doi:10.48550/ARXIV.2505.09081 , abstract =
-
[71]
Educhat: A large-scale language model-based chatbot system for intelligent education
Dan, Yuhao and Lei, Zhikai and Gu, Yiyang and. 2023 , note =. doi:10.48550/ARXIV.2308.02773 , abstract =
-
[72]
Cui, Lei and Huang, Shaohan and Wei, Furu and Tan, Chuanqi and Duan, Chaoqun and Zhou, Ming , year =. Proceedings of. doi:10.18653/v1/P17-4017 , abstract =
-
[73]
Zhou, Xuanhe and Li, Guoliang and Liu, Zhiyuan , year =. doi:10.48550/ARXIV.2308.05481 , abstract =
-
[74]
Is there any social principle for
Bai, Jitao and Zhang, Simiao and Chen, Zhonghao , year =. Is there any social principle for. doi:10.48550/ARXIV.2308.11136 , abstract =
-
[75]
Zhang, Pengsong and Hu, Xiang and Huang, Guowei and. 2025 , note =. doi:10.48550/ARXIV.2508.15126 , abstract =
-
[76]
Agents: An open-source framework for autonomous lan- guage agents
Zhou, Wangchunshu and Jiang, Yuchen Eleanor and Li, Long and. Agents: an open-source framework for autonomous language agents , shorttitle =. 2023 , note =. doi:10.48550/ARXIV.2309.07870 , abstract =
-
[77]
Schwartz, Sivan and Yaeli, Avi and Shlomov, Segev , year =. Enhancing. doi:10.48550/ARXIV.2308.05391 , abstract =
-
[78]
The tong test: evaluating artificial general intelligence through dynamic embodied physical and social interactions , volume =. Engineering , author =. 2024 , pages =. doi:10.1016/j.eng.2023.07.006 , abstract =
-
[79]
Bo- laa: Benchmarking and orchestrating llm-augmented autonomous agents
Liu, Zhiwei and Yao, Weiran and Zhang, Jianguo and. 2023 , note =. doi:10.48550/ARXIV.2308.05960 , abstract =
-
[80]
Appworld: A controllable world of apps and people for benchmarking interactive coding agents
Trivedi, Harsh and Khot, Tushar and Hartmann, Mareike and. 2024 , note =. doi:10.18653/v1/2024.acl-long.850 , abstract =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.