Efficiency of Valid Inferential Models: Choquet-risk Optimal Possibility Measures, and Direct Comparisons
Pith reviewed 2026-06-30 03:47 UTC · model grok-4.3
The pith
Valid possibility contours achieve minimal Choquet risk precisely when their level sets are optimal confidence sets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that Choquet risk ranks valid possibility measures by their informativeness and that, for concentration penalties, this risk equals the integrated expected size of the nested α-cuts of the contour. Levelwise optimal confidence sets therefore induce Choquet-risk optimal valid contours. A possibilistic definition of unbiasedness is shown to coincide with unbiasedness of the induced sets and tests, allowing UMPU results to carry over. An equivariant minimax theory is developed, including the result that the Gaussian possibility contour is Choquet-risk minimax for radial distance-to-truth losses. Choquet loss also extends classical confidence risk comparisons to non-additive cal
What carries the argument
Choquet risk, the sampling expectation of the Choquet integral of a non-negative penalty with respect to the data-dependent possibility measure; the central reduction expresses this risk through the nested α-cuts of the contour and equates it to integrated expected set size under concentration penalties.
If this is right
- Levelwise optimal confidence sets produce Choquet-risk optimal valid contours under concentration penalties.
- Possibilistic unbiasedness coincides with unbiasedness of the induced confidence sets and tests, so UMPU results transfer to contours.
- Equivariant minimax contours exist and can be identified by the same techniques used for equivariant confidence sets.
- The Gaussian possibility contour is Choquet-risk minimax among equivariant procedures for radial distance losses.
- Efficiency rankings between valid models depend on the chosen penalty functional.
Where Pith is reading between the lines
- Simulation experiments that directly estimate expected contour volumes could provide numerical confirmation of the claimed optimality ordering.
- For penalties other than concentration penalties the optimal contour may no longer coincide with the levelwise optimal one.
- The local connection to Fisher-Rao geometry suggests that divergence-based penalties could yield contours that are asymptotically efficient in regular parametric models.
Load-bearing premise
That the Choquet integral of a penalty with respect to the possibility measure is a well-defined and meaningful loss for comparing different valid procedures.
What would settle it
Generate many data sets from a known distribution, construct two different valid contours, compute their Choquet risks under a concentration penalty, and check whether the contour whose level sets are the smallest calibrated sets at each level has strictly lower risk.
Figures
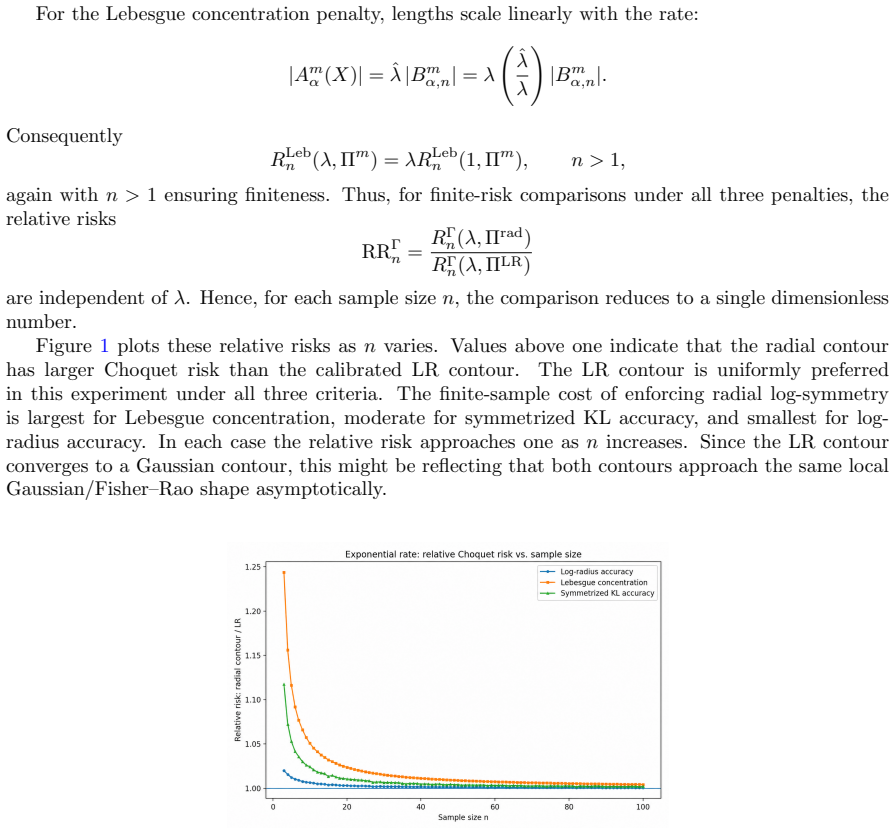
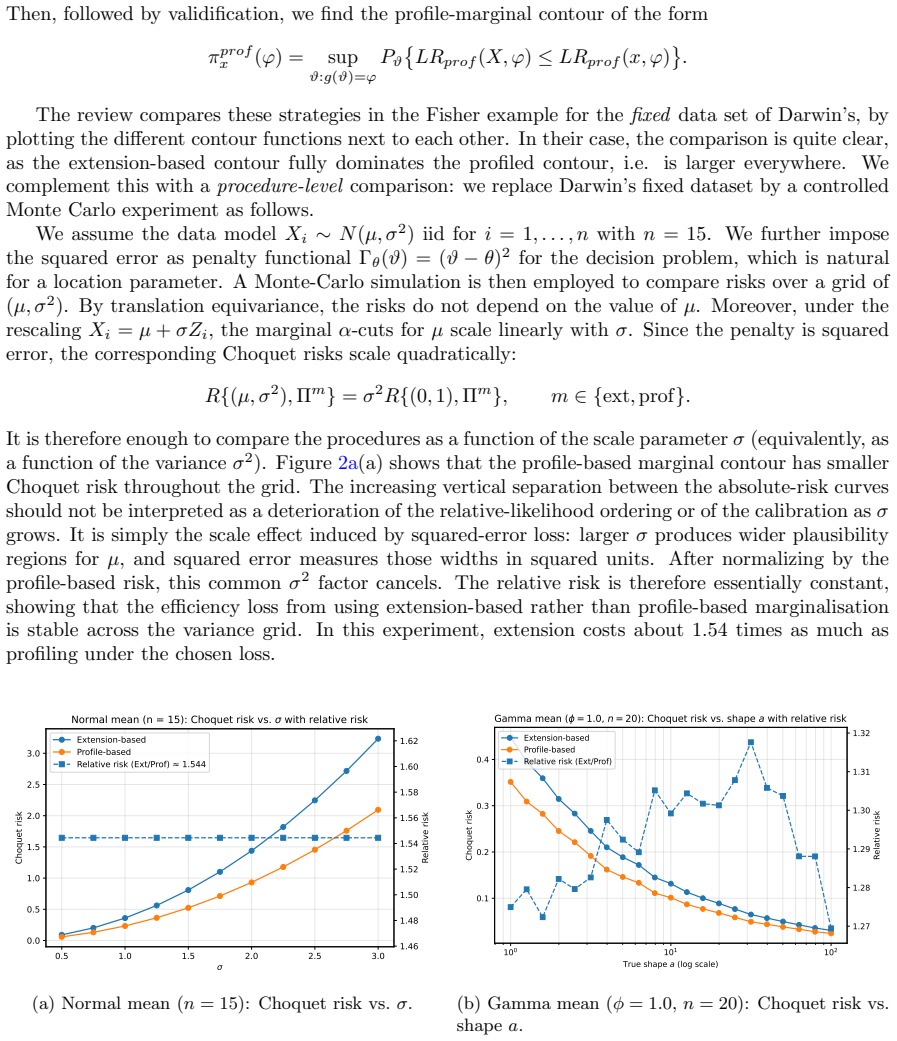
read the original abstract
Valid possibilistic inferential models provide exact finite-sample calibration, but validity alone does not determine which valid procedure results in the most informative inferential summary. This paper proposes Choquet risk as a decision-theoretic criterion for comparing valid possibility measures in finite samples. Given a non-negative penalty functional, Choquet loss is defined as the Choquet integral of that penalty with respect to the data-dependent possibility measure, and Choquet risk as its sampling expectation. A key reduction expresses this risk through the nested $\alpha$-cuts of the contour, linking procedure-level efficiency to the expected performance of calibrated confidence sets. For concentration penalties, the criterion reduces to integrated expected set size, equivalently expected contour volume, so levelwise optimal confidence sets induce Choquet-risk optimal valid contours. The framework is developed along two classical routes to optimality. First, a possibilistic notion of unbiasedness is introduced and shown, under validity, to coincide with unbiasedness of the induced confidence sets and tests, allowing UMPU and most-accurate-unbiased results to be transferred to valid contours. Second, an equivariant minimax theory is developed, including a Gaussian-location result in which the Gaussian possibility contour is Choquet-risk minimax for radial distance-to-truth losses. The construction also extends confidence risk from additive confidence distributions to non-additive calibrated inferential-model output, with Choquet loss acting as a least-favourable confidence loss. Finally, the paper clarifies the penalty-dependence of efficiency comparisons and motivates invariant size criteria and divergence-based intrinsic losses connected locally to Fisher--Rao geometry.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that Choquet risk—defined via the Choquet integral of a non-negative penalty functional with respect to a data-dependent possibility measure, then taking its sampling expectation—serves as a decision-theoretic criterion for ranking valid (exactly calibrated) possibility measures. A central reduction shows that this risk is expressed through the nested α-cuts, so that for concentration penalties it equals integrated expected set size (equivalently expected contour volume); levelwise optimal confidence sets therefore induce Choquet-risk optimal contours. The framework transfers classical UMPU and equivariant-minimax results to the possibilistic setting (including a Gaussian-location minimax result for radial losses) and extends additive confidence-risk ideas to non-additive inferential-model output.
Significance. If the reductions hold, the work supplies a coherent, penalty-dependent efficiency criterion that directly links valid inferential models to classical decision theory without extra continuity or approximation assumptions. The direct transfer via the Choquet-integral definition plus Fubini for concentration penalties, together with the unbiasedness and minimax correspondences, constitutes a concrete advance; the motivation of invariant size criteria and local Fisher–Rao connections further strengthens the contribution.
minor comments (2)
- [Abstract] Abstract: the phrase 'Choquet loss acting as a least-favourable confidence loss' is stated without a one-sentence gloss on the precise loss functional; a brief parenthetical definition would improve immediate readability.
- The manuscript would benefit from an explicit statement, early in the introduction, of the precise measurability conditions required for the Choquet integral to be well-defined when the contour is data-dependent.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of the manuscript, the clear summary of its contributions, and the recommendation to accept. No major comments were raised.
Circularity Check
No significant circularity
full rationale
The claimed reduction for concentration penalties follows directly from the definition of the Choquet integral with respect to a possibility measure (equal to the integral over level sets) combined with Fubini to interchange expectation and integration over α-cuts. Validity ensures each α-cut is calibrated, so levelwise optimality transfers without additional fitted parameters or self-referential definitions. The unbiasedness and equivariant-minimax results are likewise direct corollaries of the same correspondence. The framework builds on external classical results rather than self-citations or ansatzes that reduce the central claim to its inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
URLhttps://doi.org/10.1098/rspa.2018
doi: 10.1098/rspa.2018.0565. URLhttps://doi.org/10.1098/rspa.2018
-
[2]
URLhttps://www.worldscientific.com/doi/abs/10.1142/ 13640
doi: 10.1142/13640. URLhttps://www.worldscientific.com/doi/abs/10.1142/ 13640. Christer Borell. The ehrhard inequality.Comptes Rendus Mathematique, 337(10):663–666,
-
[3]
doi: https://doi.org/10.1016/j.crma.2003.09.031
ISSN 1631-073X. doi: https://doi.org/10.1016/j.crma.2003.09.031. URLhttps://www.sciencedirect. com/science/article/pii/S1631073X03004461. D. Coupier and Yu. Davydov. Random symmetrizations of convex bodies.Advances in Applied Probability, 46(3):603 – 621,
-
[4]
doi: 10.1239/aap/1409319551. URLhttps://doi.org/10. 1239/aap/1409319551. 33 In´ es Couso, Susana Montes, and Pedro Gil. The necessity of the strongα-cuts of a fuzzy set.Interna- tional Journal of Uncertainty, Fuzziness and Knowledge-Based Systems, 9(02):249–262,
-
[5]
URLhttps: //doi.org/10.1214/24-STS924
doi: 10.1214/24-STS924. URLhttps: //doi.org/10.1214/24-STS924. Daniel Daners. Krahn’s proof of the rayleigh conjecture revisited.Archiv der Mathematik, 96(2): 187–199,
-
[6]
doi: 10.1007/s00013-010-0218-x. Didier Dubois. Possibility theory and statistical reasoning.Computational Statistics & Data Analysis, 51(1):47–69,
-
[7]
doi: 10.1016/j.csda.2006.04.015. Didier Dubois and Henri Prade.Possibility Theory: An Approach to Computerized Processing of Uncertainty. Plenum Press, New York,
-
[8]
doi: https://doi.org/ 10.1016/0888-613X(90)90015-T
ISSN 0888-613X. doi: https://doi.org/ 10.1016/0888-613X(90)90015-T. URLhttps://www.sciencedirect.com/science/article/pii/ 0888613X9090015T. Didier Dubois and Henri Prade. Reasoning and learning in the setting of possibility theory - overview and perspectives.International Journal of Approximate Reasoning, 171:109028,
-
[9]
doi: https://doi.org/10.1016/j.ijar.2023.109028
ISSN 0888- 613X. doi: https://doi.org/10.1016/j.ijar.2023.109028. URLhttps://www.sciencedirect.com/ science/article/pii/S0888613X23001597. Synergies between Machine Learning and Reasoning. Didier Dubois, Laurent Foulloy, Gilles Mauris, and Henri Prade. Probability-possibility transforma- tions, triangular fuzzy sets, and probabilistic inequalities.Reliabl...
-
[10]
URLhttp://www.jstor.org/stable/24491511
ISSN 00255521, 19031807. URLhttp://www.jstor.org/stable/24491511. Jan Hannig, Hari Iyer, Randy C. S. Lai, and Thomas C. M. Lee and. Generalized fiducial inference: A review and new results.Journal of the American Statistical Association, 111(515):1346–1361,
-
[11]
Wood, Natalya Pya, and Benjamin Säfken
doi: 10.1080/01621459.2016.1165102. URLhttps://doi.org/10.1080/01621459.2016.1165102. Harold Jeffreys. An invariant form for the prior probability in estimation problems.Proceedings of the Royal Society of London. Series A, Mathematical and Physical Sciences, 186(1007):453–461,
-
[12]
URLhttps://arxiv.org/abs/2211.14567. Ryan Martin. No-prior bayesian inference reimagined: probabilistic approximations of inferential models,
-
[13]
No-prior Bayes reIMagined: probabilistic approximations of inferential models
URLhttps://arxiv.org/abs/2503.19748. Ryan Martin. Possibilistic inferential models: A review.Journal of the American Statistical Associ- ation, 121(553):807–826, 2026a. doi: 10.1080/01621459.2025.2606127. URLhttps://doi.org/10. 1080/01621459.2025.2606127. Ryan Martin. An efficient monte carlo method for valid prior-free possibilistic statistical inference...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1080/01621459.2025.2606127 2025
-
[14]
doi: 10.1080/01621459.2012.747960
ISSN 1537-274X. doi: 10.1080/01621459.2012.747960. URLhttp://dx.doi.org/10.1080/01621459. 2012.747960. Ryan Martin and Jonathan P. Williams. Asymptotic efficiency of inferential models and a pos- sibilistic bernstein–von mises theorem.International Journal of Approximate Reasoning, 180: 109389,
-
[15]
doi: https://doi.org/10.1016/j.ijar.2025.109389
ISSN 0888-613X. doi: https://doi.org/10.1016/j.ijar.2025.109389. URLhttps: //www.sciencedirect.com/science/article/pii/S0888613X25000301. Ryan Martin, Shih-Ni Prim, and Jonathan Williams. Decision-making with possibilistic inferential models,
-
[16]
URLhttps://arxiv.org/abs/2112.13247. John W. Pratt. Length of confidence intervals.Journal of the American Statistical Association, 56 (295):549–567,
-
[17]
URLhttps://www.tandfonline.com/ doi/abs/10.1080/01621459.1961.10480644
doi: 10.1080/01621459.1961.10480644. URLhttps://www.tandfonline.com/ doi/abs/10.1080/01621459.1961.10480644. Tore Schweder. Unbiased confidence. Presentation at the FocuStat Conference 2018, Uni- versity of Oslo,
-
[18]
Glenn Shafer.A Mathematical Theory of Evidence
doi: 10.1017/CBO9781139046671. Glenn Shafer.A Mathematical Theory of Evidence. Princeton University Press,
-
[19]
ISBN 978-0-470-72377-7. doi: 10.1002/9781118762622. URL https://onlinelibrary.wiley.com/doi/book/10.1002/9781118762622. Min-ge Xie and Kesar Singh. Confidence distribution, the frequentist distribution estimator of a parameter: A review.International Statistical Review, 81(1):3–39,
-
[20]
doi: https://doi.org/10. 1111/insr.12000. URLhttps://onlinelibrary.wiley.com/doi/abs/10.1111/insr.12000. Lotfi A. Zadeh. Fuzzy sets as a basis for a theory of possibility.Fuzzy Sets and Systems, 1(1):3–28,
-
[21]
doi: 10.1016/0165-0114(78)90029-5. A Appendix Lemma A.1(Hunt-Stein symmetrization for valid contours, compact case.).Let a groupGact mea- surably on the sample spaceXand parameter spaceΘ. Assume the model{P θ :θ∈Θ}isG-invariant, and the penalty isG-invariant in the sense that Γθ(ϑ) =h ρ(ϑ, θ) , ρ(g·ϑ, g·θ) =ρ(ϑ, θ) for some nondecreasinghandρ: Θ×Θ→[0,∞)a ...
-
[22]
There are some minor bookkeeping details about left or right invariance that need to be consistent throughout however
or Lehmann and Romano [2005]) yields an exactly invariant randomized procedure with the same minimax bound. There are some minor bookkeeping details about left or right invariance that need to be consistent throughout however. In the compact case we have treated above, we have been lax on that issue, since then any Haar is both left and right-invariant. S...
2005
-
[23]
Ifτ(m) =∞, the same inequality is trivial
Ifτ(m)<∞, thenτ(m) belongs to the feasible set {t≥0 :H(m, t)≥1−α}, hence τ(m)≥inf{t≥0 :H(m, t)≥1−α}=τ ∗ α(m). Ifτ(m) =∞, the same inequality is trivial. Therefore τ(m)≥τ ∗ α(m) forµ M-a.e.m. This is exactly the claimed orbitwise minimality. The equivalent formulation for measurableM- dependentρ-ball rules follows from the same conditioning argument as abo...
1983
-
[24]
Take anyx∈B ωA
= 1 2(w1 +σ ωu2). Take anyx∈B ωA. Then x= 1 2(a+σ ωb) for somea, b∈A. Hence ∥x−w∥ ≤ 1 2 ∥a−w 1∥+ 1 2 ∥σωb−σ ωu2∥= 1 2 ∥a−w 1∥+ 1 2 ∥b−u 2∥ ≤t, becausew 1, u2 ∈E A(t). Thereforew∈E BωA(t), proving the claim. Applying Ehrhard’s inequality to the convex setsE A(t) andσ ωEA(t) yields γd(EBωA(t))≥γ d 1 2 EA(t) +σ ωEA(t) ≥γ d(EA(t)). Since γd(EA(t)) =P{φ A(W)≤t...
2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.