Echoes in Filter Bubble: Diagnosing and Curing Popularity Bias in Generative Recommenders
Pith reviewed 2026-05-19 20:36 UTC · model grok-4.3
The pith
Generative recommenders develop severe popularity bias from token-level optimization flaws and uniform item tokenization, which Ghost corrects using asymmetric unlikelihood optimization and skeleton-founded tokenization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
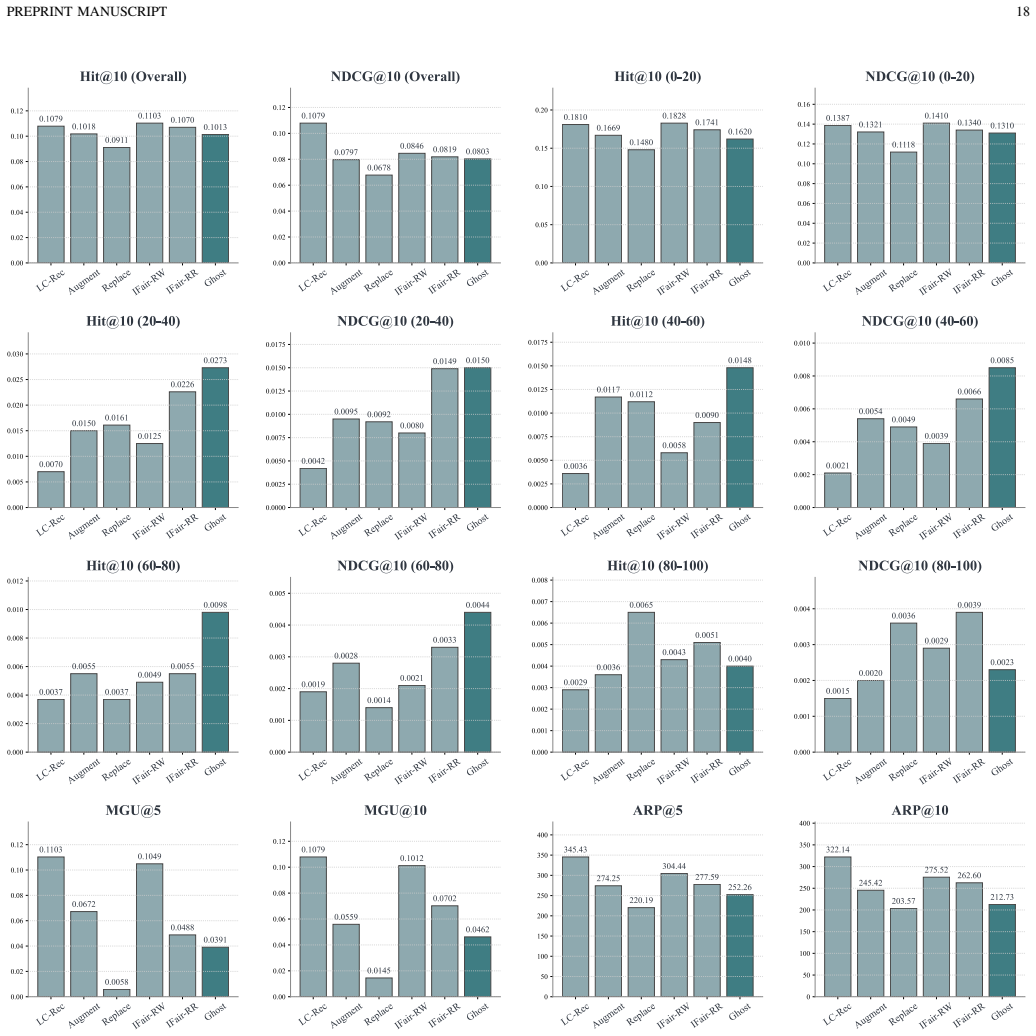
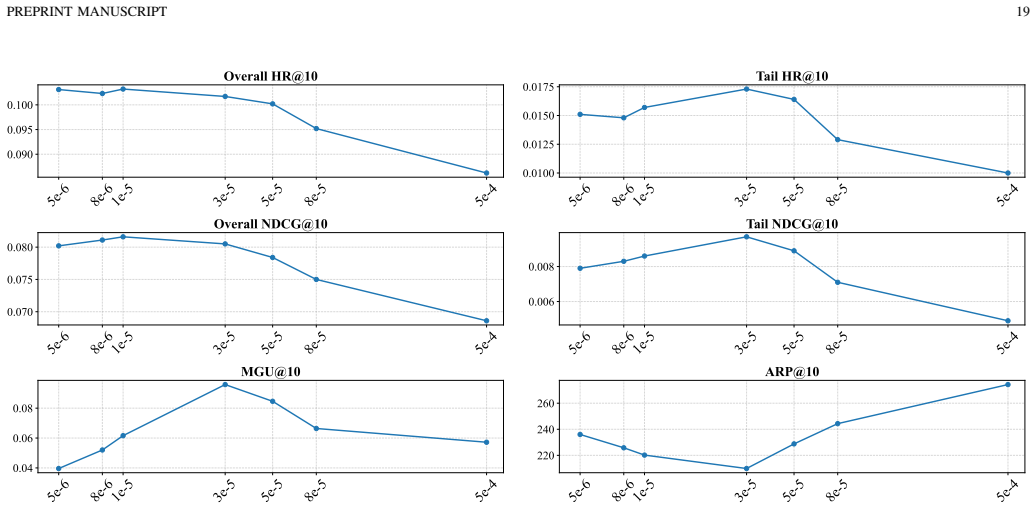
The severe popularity bias emerges from the confluence of a token-level optimization flaw and the undifferentiated property of item tokenization. The proposed Ghost system, built on asymmetric unlikelihood optimization and skeleton-founded tokenization, substantially alleviates popularity bias and promotes fairer recommendations across three datasets while incurring only slight degradation to the overall recommendation utility.
What carries the argument
Asymmetric unlikelihood optimization together with skeleton-founded tokenization, which rebalances token probabilities during training and differentiates items through structural skeletons to address the identified flaws.
If this is right
- Generative recommenders can achieve substantially fairer item exposure by changing only the optimization objective and tokenization step inside their existing end-to-end framework.
- Token-level optimization flaws can be directly corrected by applying asymmetric penalties that reduce the likelihood assigned to popular items relative to less popular ones.
- Skeleton-founded tokenization mitigates the undifferentiated property by embedding structural item information into the token assignment process.
- Ghost outperforms several state-of-the-art baselines adapted from traditional debiasing methods on three public datasets.
- Overall recommendation utility experiences only slight degradation while bias metrics improve markedly.
Where Pith is reading between the lines
- The same combination of asymmetric objectives and structure-aware tokenization could be tested in other generative sequence models used for tasks such as next-item prediction in non-recommendation domains.
- Integrating Ghost's components with post-processing fairness constraints might further reduce bias without additional utility loss.
- Wider adoption could shift recommendation platforms toward surfacing more long-tail items, changing the distribution of user attention over time.
Load-bearing premise
The theoretical analyses correctly pinpoint the root causes of popularity bias in generative recommenders, and the proposed asymmetric unlikelihood optimization together with skeleton-founded tokenization effectively mitigate these causes without introducing new biases.
What would settle it
An experiment that replaces asymmetric unlikelihood with standard likelihood training or switches to fully undifferentiated tokenization and then measures whether popularity bias returns to the levels seen in baseline generative recommenders.
Figures










read the original abstract
Recently, Generative Recommenders (GRs), characterized by a unified end-to-end framework, have exhibited astonishing potential in transforming the recommendation paradigm. Despite their effectiveness, we recognize that GRs are still susceptible to the long-standing issue of popularity bias that has pervaded the recommendation community. Although a few studies have attempted to extend traditional debiasing methods to GRs, their effectiveness is marginal, and the fundamental reason why GRs suffer from popularity bias remains under-explored. To bridge this gap, this study focuses on two core aspects in GRs: the optimization of generative framework and the item tokenization based on semantic index. Based on theoretical analyses, we identify that the severe popularity bias emerges from the confluence of a token-level optimization flaw and the undifferentiated property of item tokenization. Accordingly, this study develops a novel generative recommender system, called Ghost, by designing the asymmetric unlikelihood optimization and the skeleton-founded tokenization. Extensive empirical evaluations across three datasets, alongside multiple SOTA baselines, reveal that Ghost substantially alleviates popularity bias and promotes fairer recommendations, while incurring slight degradation to the overall recommendation utility.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that popularity bias in Generative Recommenders (GRs) arises from the confluence of a token-level optimization flaw in the standard negative log-likelihood objective and the undifferentiated property of semantic-index-based item tokenization. It proposes Ghost, which introduces asymmetric unlikelihood optimization and skeleton-founded tokenization to mitigate these issues, and reports that Ghost reduces popularity bias while incurring only slight degradation in overall recommendation utility across three datasets and multiple SOTA baselines.
Significance. If the theoretical identification of the root causes holds and the proposed fixes are shown to be robust, the work would offer a principled, GR-specific approach to popularity bias that improves on marginal extensions of traditional debiasing methods. The multi-dataset empirical evaluation against strong baselines provides a reasonable test of practical impact, though the slight utility trade-off requires careful quantification.
major comments (3)
- [§3] §3 (theoretical analysis): The per-token gradient analysis identifies a token-level optimization flaw but does not derive a closed-form expression showing bias amplification under realistic item popularity distributions (e.g., power-law). Without this isolation from autoregressive decoding and embedding geometry, it remains unclear whether the flaw is the primary driver or an artifact of token frequency correlations in the semantic index.
- [§4.2] §4.2 (asymmetric unlikelihood optimization): The claim that the proposed loss cures the identified flaw without introducing new biases lacks an ablation that holds the tokenization fixed while varying only the optimization; the current experiments conflate the two contributions, weakening the causal link to the diagnosed root cause.
- [Table 2] Table 2 (main results): The reported improvements in fairness metrics (e.g., popularity bias reduction) are not accompanied by statistical significance tests across the three datasets; with only point estimates shown, it is difficult to assess whether the alleviation is reliable or sensitive to random seeds and hyperparameter choices.
minor comments (3)
- [§2.2] Notation for the semantic index and skeleton tokens is introduced without a clear diagram or example in §2.2; adding a small illustrative figure would improve readability.
- [Abstract and §5] The abstract states 'slight degradation to the overall recommendation utility' but the main text does not quantify this trade-off with a single scalar (e.g., average NDCG drop across datasets); a summary table row would help.
- [§1.1] A few citations to prior generative recommender work (e.g., on autoregressive decoding) appear in the related-work section but are not referenced when discussing the optimization flaw; cross-references would strengthen the positioning.
Simulated Author's Rebuttal
We thank the referee for the thorough review and valuable suggestions. We have carefully considered each comment and provide our responses below, along with planned revisions to the manuscript.
read point-by-point responses
-
Referee: [§3] §3 (theoretical analysis): The per-token gradient analysis identifies a token-level optimization flaw but does not derive a closed-form expression showing bias amplification under realistic item popularity distributions (e.g., power-law). Without this isolation from autoregressive decoding and embedding geometry, it remains unclear whether the flaw is the primary driver or an artifact of token frequency correlations in the semantic index.
Authors: We thank the referee for this observation. Our gradient analysis highlights the token-level bias in the NLL objective. To address the request for a closed-form expression, we will include a derivation assuming a power-law (Zipf) distribution in the revised manuscript, showing how the bias amplifies with popularity skew. On isolating from autoregressive decoding and embedding geometry, the analysis is performed at the loss level prior to decoding; however, we will add a paragraph discussing potential interactions with these factors to clarify that the flaw is not merely an artifact of token frequencies. revision: yes
-
Referee: [§4.2] §4.2 (asymmetric unlikelihood optimization): The claim that the proposed loss cures the identified flaw without introducing new biases lacks an ablation that holds the tokenization fixed while varying only the optimization; the current experiments conflate the two contributions, weakening the causal link to the diagnosed root cause.
Authors: We concur that separating the contributions is important for establishing causality. Currently, the experiments evaluate the combined effect of asymmetric unlikelihood optimization and skeleton-founded tokenization. In the revision, we will introduce an ablation study that keeps the tokenization fixed and varies only the optimization objective, allowing us to isolate the impact of the asymmetric unlikelihood loss and confirm it addresses the diagnosed flaw without new biases. revision: yes
-
Referee: [Table 2] Table 2 (main results): The reported improvements in fairness metrics (e.g., popularity bias reduction) are not accompanied by statistical significance tests across the three datasets; with only point estimates shown, it is difficult to assess whether the alleviation is reliable or sensitive to random seeds and hyperparameter choices.
Authors: We appreciate this suggestion for improving the robustness of our empirical claims. The current Table 2 presents point estimates. We will update the table to include results from multiple runs with different random seeds, reporting means and standard deviations, along with statistical significance tests (such as t-tests) to demonstrate that the observed reductions in popularity bias are statistically significant and not sensitive to initialization. revision: yes
Circularity Check
No circularity in theoretical identification of bias sources or proposed mitigations
full rationale
The paper derives its central claim—that popularity bias arises from token-level optimization flaws and undifferentiated item tokenization—via theoretical analyses of the generative framework, then introduces asymmetric unlikelihood optimization and skeleton-founded tokenization as targeted remedies. No equations or self-citations reduce these diagnoses or fixes to fitted parameters, self-referential predictions, or ansatzes imported from prior author work; the analyses stand as independent examinations of per-token gradients and semantic indexing properties, with empirical results on three datasets providing external validation. The derivation chain is self-contained and does not collapse to its inputs by construction.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.