STAP: A Shuffle-Tokenized App Predictor with Ultra Long Context for Vocabulary-Free Mobile App Prediction
Pith reviewed 2026-06-29 09:02 UTC · model grok-4.3
The pith
STAP predicts next mobile apps without any fixed app vocabulary by shuffling identities to random indices and using ultra-long behavioral sequences.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
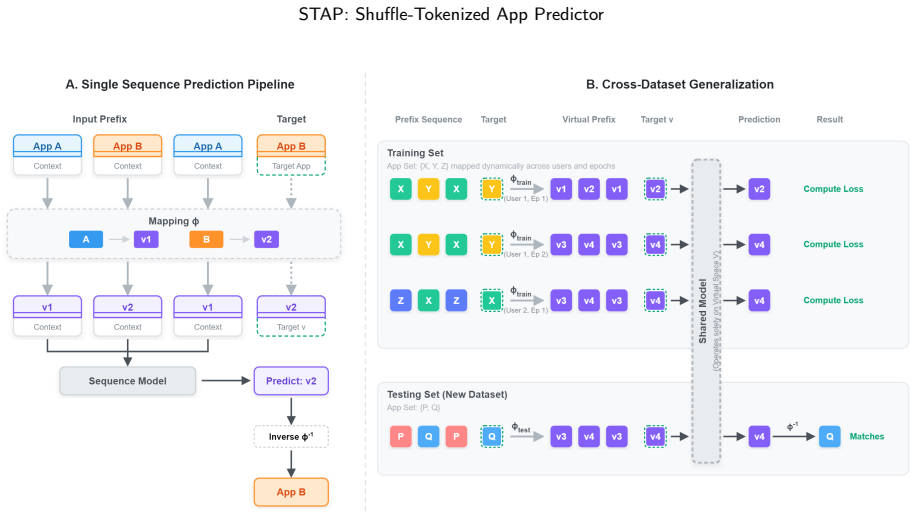
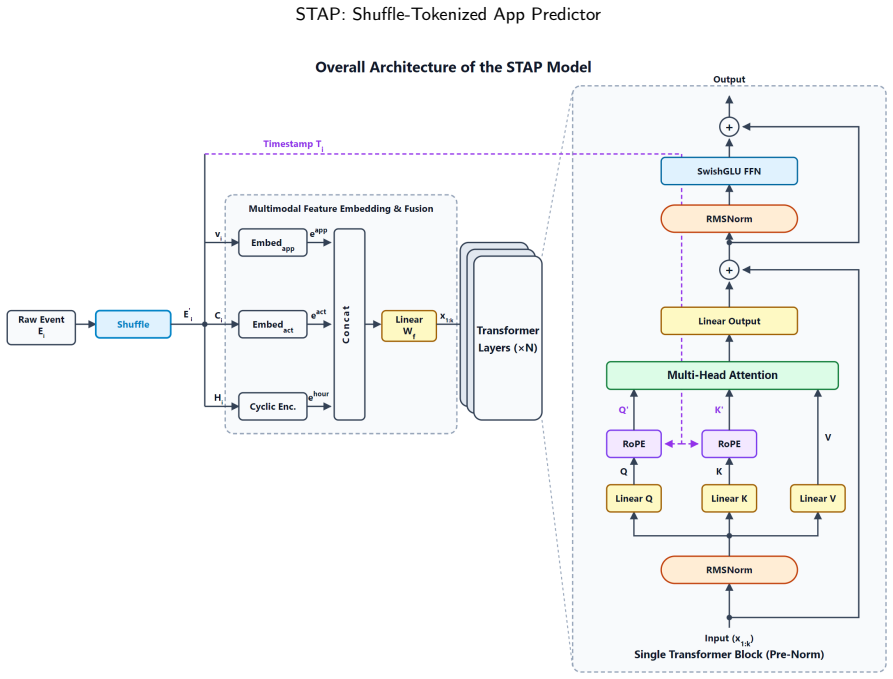
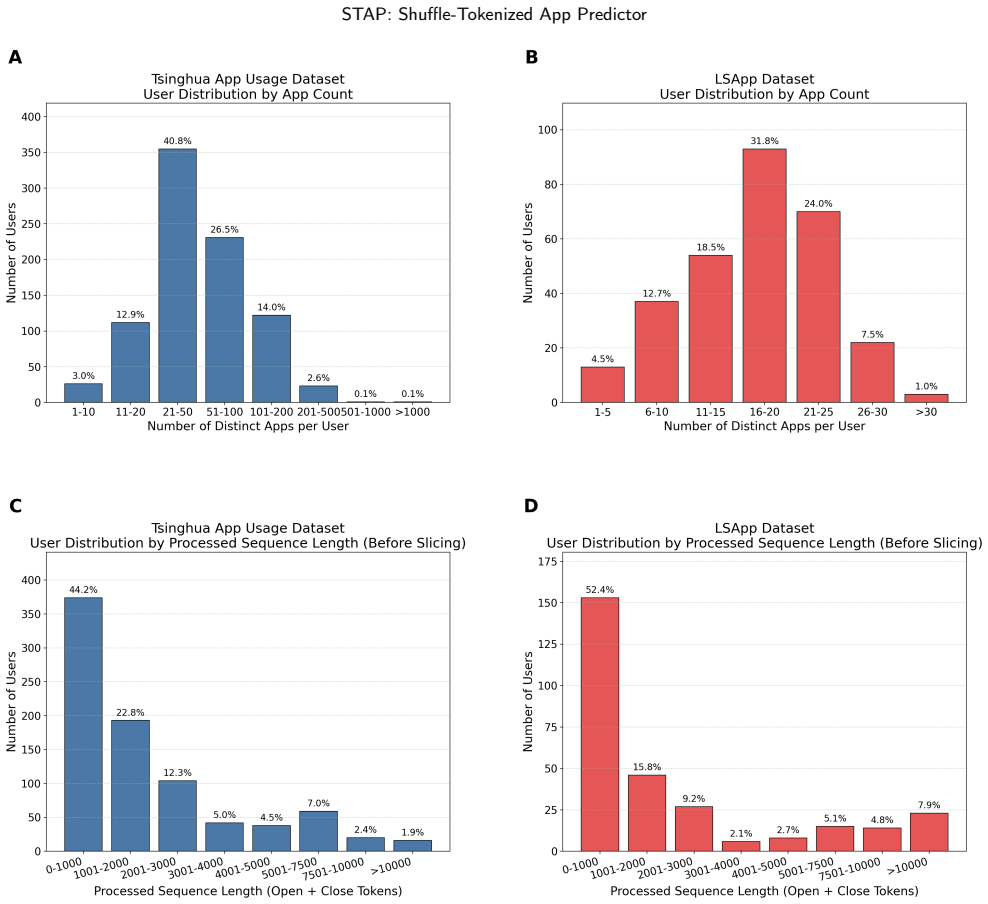
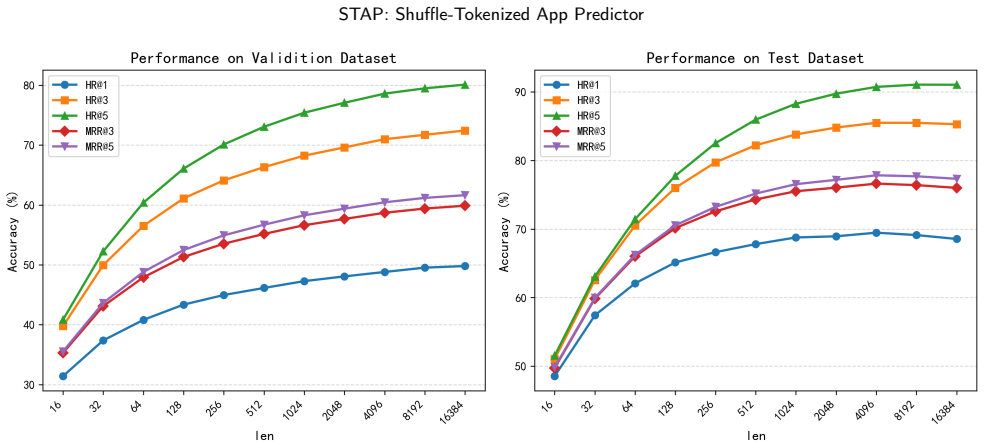
STAP replaces true app identities with randomly reassigned virtual indices via a shuffle mechanism and compensates for discarded semantic information by processing behavioral sequences with an ultra-long context design. A theoretical analysis shows that, given a sufficiently long context, the predicted distribution converges to the correct one despite the anonymity of the mapping. Experiments on two datasets from different continents demonstrate that STAP achieves strong cross-dataset zero-shot prediction accuracy while its cold-start performance within each dataset remains competitive with leading models.
What carries the argument
The shuffle mechanism that maps real apps to anonymous virtual indices, paired with an ultra-long context window in a Transformer that recovers statistical structure from behavioral sequences.
If this is right
- The same model can be applied directly to any new app ecosystem without retraining or vocabulary alignment.
- Cold-start users receive competitive accuracy from the first session onward.
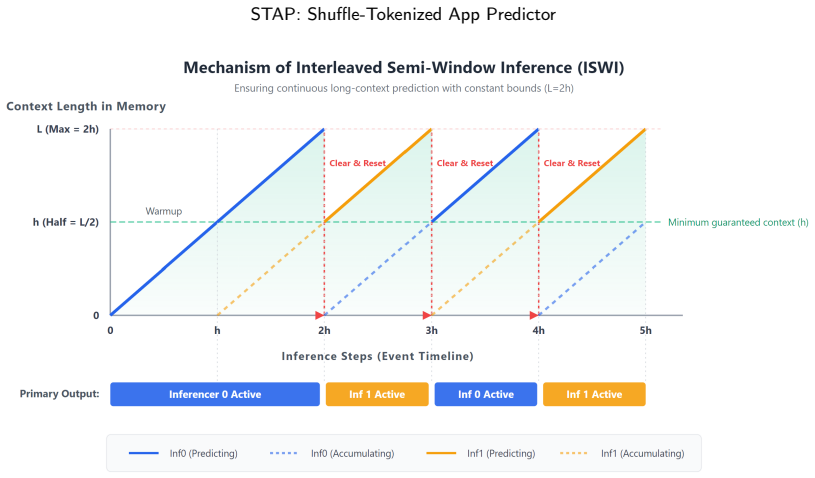
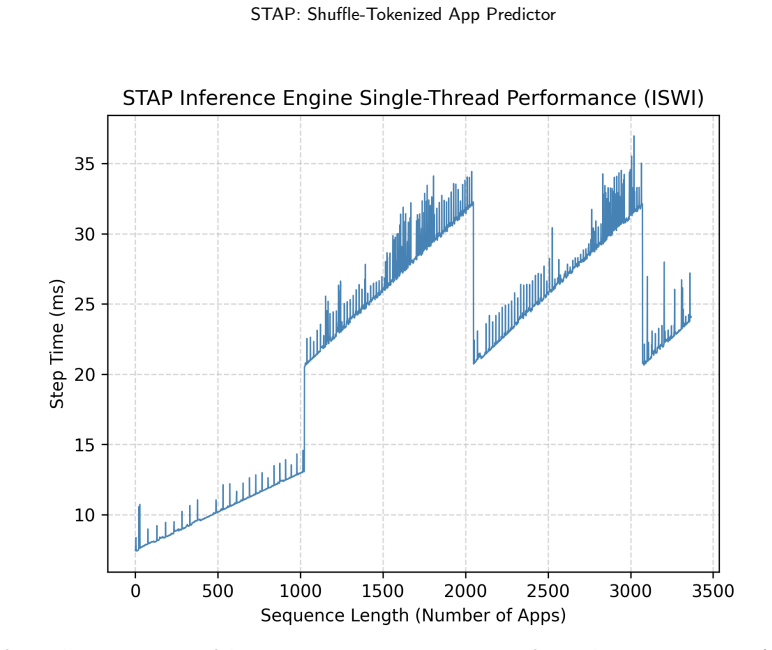
- Continuous inference can retain the full required context length while staying within deployment latency limits.
Where Pith is reading between the lines
- The same shuffle-plus-long-context idea could be tested on other anonymized sequence tasks such as next-webpage prediction or next-purchase forecasting.
- Because no real app identities are stored, the approach may reduce privacy exposure during model training and serving.
- If behavioral sequences in other domains lack the necessary statistical redundancy, the method would require domain-specific adjustments to context length.
Load-bearing premise
User behavior sequences contain enough repeating statistical structure that a sufficiently long window of past actions can recover the mapping probabilities even after all app identities have been replaced by random virtual tokens.
What would settle it
Measure next-app prediction accuracy on a held-out dataset after applying the shuffle; if accuracy stays at chance level even when the context window is extended to tens of thousands of steps, the convergence claim is false.
Figures
read the original abstract
Predicting the next mobile application a user will launch is essential for intelligent device resource management and proactive assistance. Existing models rely on fixed app vocabularies, which prevents them from generalizing across different app ecosystems. Many also depend on user-specific knowledge, which complicates deployment in cold start scenarios. We propose STAP, a Transformer-based model that eliminates the need for a fixed vocabulary. STAP replaces true app identities with randomly reassigned virtual indices via a shuffle mechanism, and compensates for discarded semantic information by processing behavioral sequences with an ultra-long context design. A theoretical analysis shows that, given a sufficiently long context, the predicted distribution converges to the correct one despite the anonymity of the mapping. Experiments on two datasets from different continents demonstrate that STAP achieves strong cross-dataset zero-shot prediction accuracy -- a setting where all existing fixed-vocabulary methods are inherently inapplicable -- while its cold start performance within each dataset remains competitive with leading models. Furthermore, we introduce a deployment strategy that enables the model to retain a sufficiently long context during continuous inference while keeping latency within acceptable bounds.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces STAP, a Transformer-based next-app prediction model that eliminates fixed app vocabularies by replacing true app identities with randomly reassigned virtual indices via a shuffle mechanism. It compensates for lost semantic information through an ultra-long context design. A theoretical analysis claims that with sufficiently long context the predicted distribution converges to the correct one despite the anonymous mapping. Experiments on two datasets from different continents show strong cross-dataset zero-shot accuracy (where fixed-vocabulary baselines are inapplicable) and competitive within-dataset cold-start performance, plus a deployment strategy for continuous low-latency inference.
Significance. If the convergence result and empirical claims hold under realistic conditions, the work would be significant for enabling vocabulary-free, cross-ecosystem generalization in mobile app prediction, addressing key limitations of prior models in cold-start and deployment across app stores. The zero-shot cross-dataset evaluation is a particularly relevant testbed that existing methods cannot address.
major comments (2)
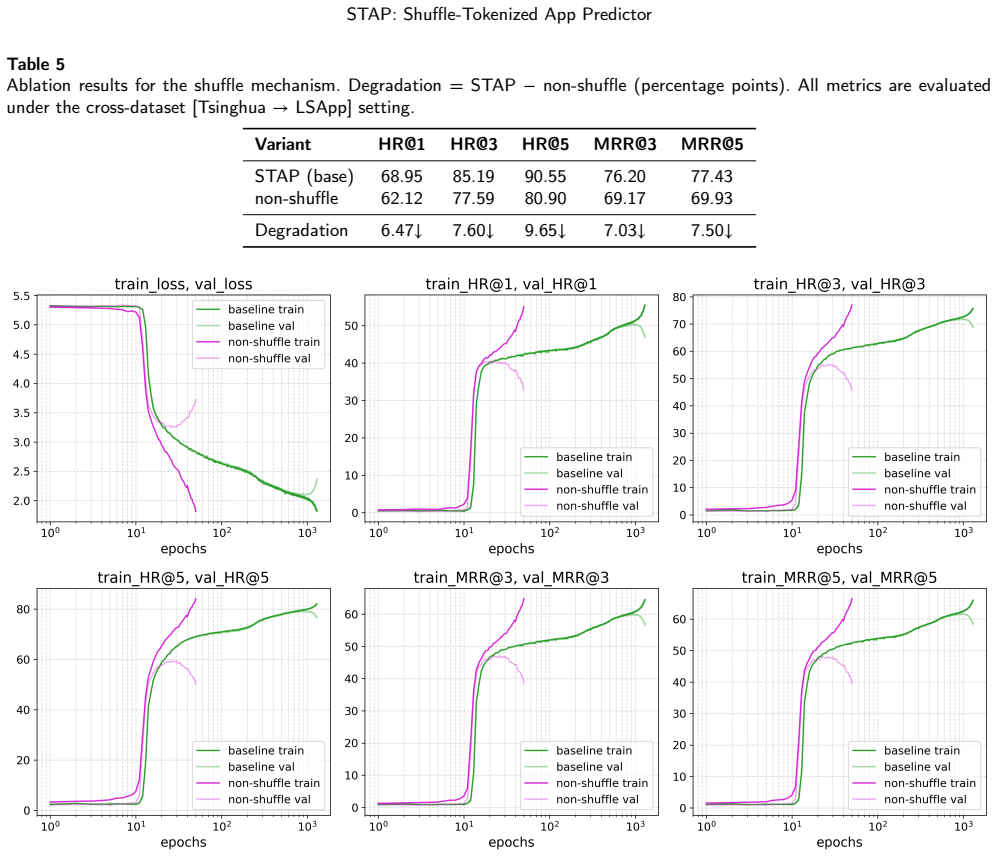
- [theoretical analysis] Abstract and theoretical analysis section: the convergence claim (that sufficiently long context recovers the correct distribution despite anonymous virtual indices) is load-bearing for the central contribution, yet the abstract and manuscript provide no derivation details, proof technique, explicit assumptions on sequence statistics (e.g., conditional entropy or motif recoverability after fixed permutation), or convergence rate. This leaves the result dependent on an unverified modeling assumption about behavioral sequences.
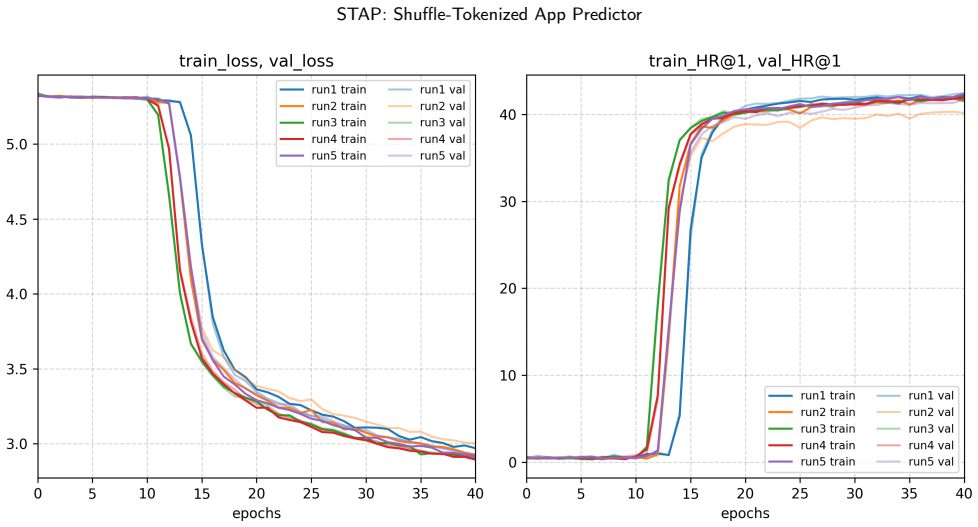
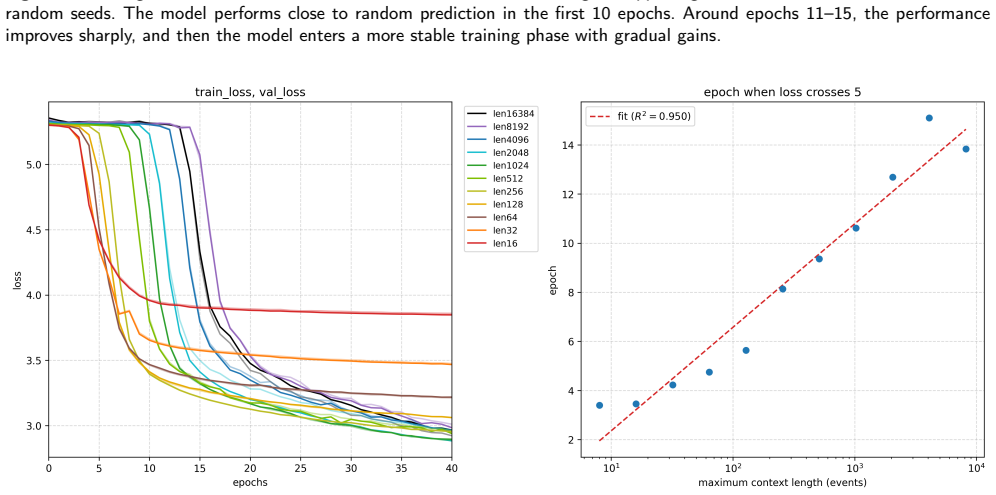
- [experiments] Experiments section: cross-dataset zero-shot results are presented without error bars, multiple random seeds for the shuffle, or ablation on context length, which is necessary to substantiate robustness given the random virtual indices and the theoretical reliance on long context.
minor comments (1)
- [deployment] The deployment strategy for retaining long context during inference is described at a high level; adding pseudocode or latency measurements versus context length would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments highlight areas where the theoretical analysis and experimental reporting can be strengthened. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [theoretical analysis] Abstract and theoretical analysis section: the convergence claim (that sufficiently long context recovers the correct distribution despite anonymous virtual indices) is load-bearing for the central contribution, yet the abstract and manuscript provide no derivation details, proof technique, explicit assumptions on sequence statistics (e.g., conditional entropy or motif recoverability after fixed permutation), or convergence rate. This leaves the result dependent on an unverified modeling assumption about behavioral sequences.
Authors: We agree that the theoretical analysis section presents the convergence result at a high level without sufficient derivation details. The argument assumes that app-usage sequences possess low conditional entropy and recoverable transition motifs that persist under random index permutation, enabling the Transformer to infer the underlying distribution from sufficiently long contexts. In the revision we will expand this section to include an explicit proof sketch (leveraging concentration bounds on empirical n-gram statistics), the precise modeling assumptions, and a convergence-rate bound expressed in terms of context length and sequence entropy. These additions will make the claim verifiable and address the concern about unverified assumptions. revision: yes
-
Referee: [experiments] Experiments section: cross-dataset zero-shot results are presented without error bars, multiple random seeds for the shuffle, or ablation on context length, which is necessary to substantiate robustness given the random virtual indices and the theoretical reliance on long context.
Authors: We acknowledge that the reported cross-dataset zero-shot numbers lack error bars, results over multiple shuffle seeds, and context-length ablations. These omissions weaken the demonstration of robustness to the random mapping. In the revised manuscript we will add standard-deviation error bars, averages over five independent random shuffles, and an ablation varying context length (e.g., 512 to 4096 tokens) to show that performance improves and stabilizes only at ultra-long contexts, consistent with the theoretical claim. revision: yes
Circularity Check
Theoretical convergence claim presented independently with no reduction to inputs by construction
full rationale
The paper states a theoretical analysis showing convergence of the predicted distribution to the correct one with long context despite anonymous mappings, but provides no equations, fitted parameters, or self-citations that would make this claim tautological or reduce it to the input data by definition. No self-definitional steps, fitted inputs called predictions, or load-bearing self-citations appear in the given text. The claim is framed as an independent theoretical result separate from the experimental zero-shot and cold-start results, making the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Behavioral sequences contain sufficient statistical structure that an ultra-long context window can recover the information lost when true app identities are replaced by random virtual indices.
Reference graph
Works this paper leans on
-
[1]
A. Parate, M. Böhmer, D. Chu, D. Ganesan, B. M. Marlin, Practical prediction and prefetch for faster ac- cesstoapplicationsonmobilephones,in:Proceedings of the 2013 ACM International Joint Conference on Pervasive and Ubiquitous Computing, UbiComp ’13, AssociationforComputingMachinery,NewYork,NY, USA,2013,p.275–284.doi:10.1145/2493432.2493490. URLhttps://d...
-
[3]
URLhttps://arxiv.org/abs/2603.17259
X.Li,S.Liu,B.Guo,Y.Ouyang,F.Wu,Y.Xu,Z.Yu, Appflow: Memory scheduling for cold launch of large apps on mobile and vehicle systems, arXiv preprint arXiv:2603.17259 (2026). URLhttps://arxiv.org/abs/2603.17259
-
[5]
R. Baeza-Yates, D. Jiang, F. Silvestri, B. Harrison, Predicting the next app that you are going to use, in: Proceedings of the Eighth ACM International Confer- ence on Web Search and Data Mining, WSDM ’15, AssociationforComputingMachinery,NewYork,NY, USA,2015,p.285–294.doi:10.1145/2684822.2685302. URLhttps://doi.org/10.1145/2684822.2685302
-
[6]
K. Huang, C. Zhang, X. Ma, G. Chen, Predicting mobile application usage using contextual informa- tion, in: Proceedings of the 2012 ACM Conference on UbiquitousComputing,UbiComp’12,Associationfor Computing Machinery, New York, NY, USA, 2012, p. 1059–1065.doi:10.1145/2370216.2370442. URLhttps://doi.org/10.1145/2370216.2370442
-
[7]
173–182.doi:10.1145/2370216.2370243
C.Shin,J.-H.Hong,A.K.Dey,Understandingandpre- diction of mobile application usage for smart phones, in: Proceedings of the 2012 ACM Conference on UbiquitousComputing,UbiComp’12,Associationfor Computing Machinery, New York, NY, USA, 2012, p. 173–182.doi:10.1145/2370216.2370243. URLhttps://doi.org/10.1145/2370216.2370243
-
[8]
Z.-X. Liao, S.-C. Li, W.-C. Peng, P. S. Yu, T.-C. Liu, On the feature discovery for app usage prediction in smartphones, in: 2013 IEEE 13th International Con- ference on Data Mining, 2013, pp. 1127–1132.doi: 10.1109/ICDM.2013.130
-
[9]
N. Natarajan, D. Shin, I. S. Dhillon, Which app will you use next? collaborative filtering with interactional context,in:Proceedingsofthe7thACMConferenceon Recommender Systems, RecSys ’13, Association for Computing Machinery, New York, NY, USA, 2013, p. 201–208.doi:10.1145/2507157.2507186. URLhttps://doi.org/10.1145/2507157.2507186
-
[10]
T. Xia, Y. Li, J. Feng, D. Jin, Q. Zhang, H. Luo, Q.Liao,Deepapp:Predictingpersonalizedsmartphone appusageviacontext-awaremulti-tasklearning,ACM Trans. Intell. Syst. Technol. 11 (6) (Oct. 2020).doi: 10.1145/3408325. URLhttps://doi.org/10.1145/3408325
-
[11]
Suleiman, K
B. Suleiman, K. Lu, H. W. Chan, M. J. Alibasa, Deep- patterns: Predicting mobile apps usage from spatio- temporalandcontextualfeatures,in:H.Hacid,O.Kao, M. Mecella, N. Moha, H.-y. Paik (Eds.), Service- Oriented Computing, Springer International Publish- ing, Cham, 2021, pp. 811–818
2021
-
[12]
S.Zhao,Z.Luo,Z.Jiang,H.Wang,F.Xu,S.Li,J.Yin, G. Pan, Appusage2vec: Modeling smartphone app us- age for prediction, in: 2019 IEEE 35th International Conference on Data Engineering (ICDE), 2019, pp. 1322–1333.doi:10.1109/ICDE.2019.00120
-
[13]
Y. Yu, T. Xia, H. Wang, J. Feng, Y. Li, Semantic- aware spatio-temporal app usage representation via graph convolutional network, Proc. ACM Interact. Mob.WearableUbiquitousTechnol.4(3)(Sep.2020). doi:10.1145/3411817. URLhttps://doi.org/10.1145/3411817
-
[14]
Y. Khaokaew, M. S. Rahaman, R. W. White, F. D. Salim,Cosem:Contextualandsemanticembeddingfor appusageprediction,in:Proceedingsofthe30thACM InternationalConferenceonInformation&Knowledge Management, CIKM ’21, Association for Computing Machinery,NewYork,NY,USA,2021,p.3137–3141. doi:10.1145/3459637.3482076. URLhttps://doi.org/10.1145/3459637.3482076
-
[15]
M. Aliannejadi, H. Zamani, F. Crestani, W. B. Croft, Context-aware target apps selection and recommenda- tion for enhancing personal mobile assistants, ACM Trans. Inf. Syst. 39 (3) (May 2021).doi:10.1145/ 3447678. URLhttps://doi.org/10.1145/3447678
-
[16]
Y.Khaokaew,H.Xue,F.D.Salim,Maple:Mobileapp prediction leveraging large language model embed- dings,Proc.ACMInteract.Mob.WearableUbiquitous Technol. 8 (1) (Mar. 2024).doi:10.1145/3643514. URLhttps://doi.org/10.1145/3643514 C. Fan et al.:Preprint submitted to ElsevierPage 14 of 15 STAP: Shuffle-Tokenized App Predictor
- [17]
-
[18]
LLaMA: Open and Efficient Foundation Language Models
H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux,T.Lacroix,B.Rozière,N.Goyal,E.Hambro, F. Azhar, et al., Llama: Open and efficient foundation language models, arXiv preprint arXiv:2302.13971 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
Xiong, Y
R. Xiong, Y. Yang, D. He, K. Zheng, S. Zheng, C. Xing, H. Zhang, Y. Lan, L. Wang, T. Liu, On layer normalization in the transformer architecture, in: International conference on machine learning, PMLR, 2020, pp. 10524–10533
2020
-
[20]
Zhang, R
B. Zhang, R. Sennrich, Root mean square layer normalization, in: H. Wallach, H. Larochelle, A. Beygelzimer, F. d'Alché-Buc, E. Fox, R. Garnett (Eds.), Advances in Neural Information Processing Systems, Vol. 32, Curran Associates, Inc., 2019. URLhttps://proceedings.neurips. cc/paper_files/paper/2019/file/ 1e8a19426224ca89e83cef47f1e7f53b-Paper.pdf
2019
-
[21]
GLU Variants Improve Transformer
N. Shazeer, Glu variants improve transformer (2020). arXiv:2002.05202. URLhttps://arxiv.org/abs/2002.05202
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[22]
J. Su, M. Ahmed, Y. Lu, S. Pan, W. Bo, Y. Liu, Roformer: Enhanced transformer with rotary position embedding, Neurocomputing 568 (2024) 127063. doi:https://doi.org/10.1016/j.neucom.2023.127063. URLhttps://www.sciencedirect.com/science/ article/pii/S0925231223011864
-
[23]
D.Yu,Y.Li,F.Xu,P.Zhang,V.Kostakos,Smartphone app usage prediction using points of interest, Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 1 (4) (Jan. 2018).doi:10.1145/3161413. URLhttps://doi.org/10.1145/3161413 C. Fan et al.:Preprint submitted to ElsevierPage 15 of 15
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.