Are Watermarked Images Editable? SafeMark for Watermark-Preserving Text-Guided Image Editing
Pith reviewed 2026-05-20 06:42 UTC · model grok-4.3
The pith
Watermarked images can be text-guided edited while keeping the embedded watermark intact by adding a decoding loss during editor training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that adding a thresholded watermark-decoding loss directly to the training objective of a diffusion-based text-guided editor makes the final edited image preserve high bit accuracy on the original watermark. This follows from an information-theoretic bound: high bit accuracy on the output lower-bounds the mutual information the editing channel preserves between the watermark and the edited result, which in turn controls recoverability.
What carries the argument
SafeMark, the training modification that inserts a thresholded watermark-decoding loss into the diffusion editor's objective so that semantic edits automatically satisfy watermark integrity.
If this is right
- High watermark bit accuracy is achieved across multiple datasets and text-guided editing methods.
- Semantic edit quality and robustness to post-edit distortions remain comparable to the unmodified editor.
- The approach requires no changes to the underlying diffusion architecture and works with any differentiable editor.
- Trustworthy provenance becomes feasible inside generative editing pipelines without separate watermarking steps after editing.
Where Pith is reading between the lines
- The same loss-augmentation idea could be tested on non-diffusion editors such as GAN-based or flow-based image manipulators.
- If watermark preservation generalizes to video or 3-D editing, provenance tracking could extend to those media as well.
- Real-world user studies measuring whether people notice any quality drop would help assess practical adoption.
Load-bearing premise
Adding the thresholded watermark-decoding loss during fine-tuning will not degrade the semantic validity or quality of the text-guided edits while still guaranteeing high bit accuracy on the final output.
What would settle it
An experiment that applies SafeMark-trained editors to a held-out set of watermarked images and finds that either watermark bit accuracy falls below 90 percent on the edited outputs or the edits no longer match the guiding text prompts in semantic content.
Figures






read the original abstract
This paper investigates a fundamental yet underexplored question: can watermarked images remain editable without compromising watermark integrity? We propose SafeMark, a framework for watermark-preserving text-guided image manipulation that explicitly integrates watermark integrity into the editing process. Specifically, SafeMark adds a thresholded watermark-decoding loss directly to the diffusion editor's training objective, fine-tuning the editor so that semantically valid edits also preserve the embedded watermark at the final output. This design admits a clean information-theoretic justification: maintaining high bit-accuracy on the edited image lower-bounds the mutual information that the editor channel preserves between watermark and edited output, the quantity that fundamentally controls watermark recoverability. SafeMark is compatible with differentiable diffusion-based editors, and requires no architectural modification. Extensive evaluations across multiple datasets, text-guided editing methods, and post-edit distortion settings demonstrate that SafeMark achieves high watermark bit accuracy across diverse editing settings while maintaining high-quality semantic edits, without sacrificing robustness to common post-edit distortions. These results demonstrate that semantic editability and watermark integrity are fundamentally compatible, enabling trustworthy image provenance in generative editing pipelines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes SafeMark, a framework for watermark-preserving text-guided image editing. It adds a thresholded watermark-decoding loss to the training objective of differentiable diffusion-based editors, fine-tuning them so that semantically valid edits also preserve the embedded watermark. The approach is justified information-theoretically by arguing that high bit-accuracy lower-bounds the mutual information preserved by the editor channel between the watermark and the edited output. Evaluations across multiple datasets, editing methods, and post-edit distortions are reported to show high watermark bit accuracy while maintaining edit quality and robustness.
Significance. If the empirical claims hold, the work provides a practical demonstration that semantic editability and watermark integrity can be made compatible without architectural changes to existing editors. The information-theoretic framing is a conceptual strength if the derivation is made explicit and the decoder reliability post-edit is verified. This could support trustworthy provenance tracking in generative pipelines, but significance is limited by the absence of detailed quantitative results, ablations, or trade-off measurements in the provided description.
major comments (3)
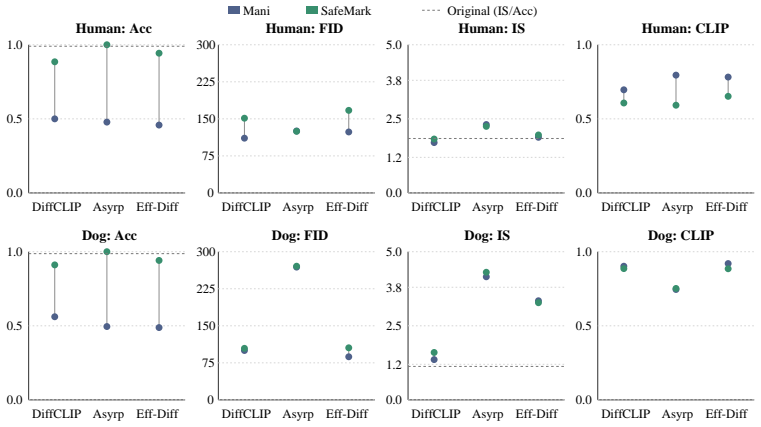
- [§5 (Experiments)] The central claim of fundamental compatibility rests on the assumption that the thresholded watermark-decoding loss can be added without degrading semantic fidelity or prompt adherence. The manuscript should provide quantitative evidence (e.g., CLIP scores, human preference studies, or edit success rates) comparing SafeMark to the baseline editor in §5 or the corresponding experiment section; without such data the compatibility conclusion remains under-supported.
- [§3.2 (Method/Theory)] The information-theoretic justification states that high bit-accuracy lower-bounds mutual information. The derivation steps, including how bit-accuracy is treated as an independent measure versus a quantity fitted to the same data used for loss thresholding, should be expanded in §3.2 or the theoretical analysis section to confirm it is not circular.
- [§3.2 (Loss Definition)] The threshold for the watermark-decoding loss is identified as a free parameter. The paper should report sensitivity analysis or a principled selection method for this threshold and demonstrate that it does not introduce bias toward low-level patterns that conflict with prompt-driven changes.
minor comments (2)
- [§3] Clarify notation for the watermark decoder and the exact form of the thresholded loss to improve reproducibility.
- [§5] Add explicit comparison tables showing bit accuracy and edit quality metrics side-by-side for baseline and SafeMark across all tested methods and datasets.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript to strengthen the presentation of results and theory.
read point-by-point responses
-
Referee: [§5 (Experiments)] The central claim of fundamental compatibility rests on the assumption that the thresholded watermark-decoding loss can be added without degrading semantic fidelity or prompt adherence. The manuscript should provide quantitative evidence (e.g., CLIP scores, human preference studies, or edit success rates) comparing SafeMark to the baseline editor in §5 or the corresponding experiment section; without such data the compatibility conclusion remains under-supported.
Authors: We agree that explicit quantitative comparisons are needed to fully support the compatibility claim. The manuscript states that SafeMark maintains high-quality semantic edits, but direct metrics versus the unmodified baseline editor were not tabulated in §5. In the revised manuscript we will add CLIP-score comparisons, edit success rates, and (where space permits) a small human preference study in §5 to quantify that prompt adherence and semantic fidelity remain comparable to the baseline. revision: yes
-
Referee: [§3.2 (Method/Theory)] The information-theoretic justification states that high bit-accuracy lower-bounds mutual information. The derivation steps, including how bit-accuracy is treated as an independent measure versus a quantity fitted to the same data used for loss thresholding, should be expanded in §3.2 or the theoretical analysis section to confirm it is not circular.
Authors: We thank the referee for highlighting the need for a clearer derivation. Bit accuracy is evaluated post-editing on held-out images and serves as an empirical lower bound on preserved mutual information via standard information-theoretic inequalities. To eliminate any concern of circularity, we will expand §3.2 with the explicit steps: (i) definition of the editor as a channel, (ii) relation of bit accuracy to mutual information via Fano’s inequality, and (iii) explicit statement that the accuracy metric is computed on test data independent of the training-time threshold choice. This will make the argument non-circular and self-contained. revision: yes
-
Referee: [§3.2 (Loss Definition)] The threshold for the watermark-decoding loss is identified as a free parameter. The paper should report sensitivity analysis or a principled selection method for this threshold and demonstrate that it does not introduce bias toward low-level patterns that conflict with prompt-driven changes.
Authors: We acknowledge that the threshold is a hyperparameter whose sensitivity should be documented. The current manuscript selects it via preliminary validation to balance the two objectives. In the revision we will add a sensitivity plot (threshold vs. watermark bit accuracy and CLIP score) in §3.2 or the appendix, describe the validation-based selection procedure, and show that prompt adherence remains high across the operating range, thereby confirming that the threshold does not systematically favor low-level artifacts over semantic edits. revision: yes
Circularity Check
Information-theoretic justification reduces to the optimized bit-accuracy metric by construction
specific steps
-
fitted input called prediction
[Abstract]
"This design admits a clean information-theoretic justification: maintaining high bit-accuracy on the edited image lower-bounds the mutual information that the editor channel preserves between watermark and edited output, the quantity that fundamentally controls watermark recoverability."
The framework explicitly optimizes the diffusion editor with a thresholded watermark-decoding loss to enforce high bit accuracy on the output. The subsequent claim that this bit accuracy lower-bounds mutual information (and thereby controls recoverability) is therefore a direct restatement of the training objective rather than an independent derivation; bit accuracy is the fitted quantity being measured on the same edited images.
full rationale
The paper's central claim of fundamental compatibility between editability and watermark integrity rests on adding a thresholded decoding loss during fine-tuning and then reporting high bit accuracy plus preserved edit quality. The information-theoretic step is presented as independent justification but essentially restates that the quantity being directly optimized (bit accuracy) implies recoverability. No derivation of the lower bound is supplied in the abstract, and bit accuracy is not an external benchmark. However, the paper reports extensive cross-dataset and cross-method experiments, so the compatibility result retains some independent empirical content rather than being purely definitional.
Axiom & Free-Parameter Ledger
free parameters (1)
- threshold for watermark-decoding loss
axioms (1)
- domain assumption High bit accuracy on the edited image lower-bounds the mutual information preserved by the editor channel between watermark and output.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
SafeMark adds a thresholded watermark-decoding loss directly to the diffusion editor's training objective... Lwm = max(0, τ − gAcc(ŵ,w))
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022
work page 2022
-
[2]
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily L Denton, Kamyar Ghasemipour, Raphael Gontijo Lopes, Burcu Karagol Ayan, Tim Salimans, et al. Photorealistic text-to- image diffusion models with deep language understanding.Advances in neural information processing systems, 35:36479–36494, 2022
work page 2022
-
[3]
Hierarchical Text-Conditional Image Generation with CLIP Latents
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text-conditional image generation with clip latents.arXiv preprint arXiv:2204.06125, 1(2):3, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[4]
Lawa: Using latent space for in-generation image watermarking
Ahmad Rezaei, Mohammad Akbari, Saeed Ranjbar Alvar, Arezou Fatemi, and Yong Zhang. Lawa: Using latent space for in-generation image watermarking. InEuropean Conference on Computer Vision, pages 118–136. Springer, 2024
work page 2024
-
[5]
Wouaf: Weight modulation for user attribution and fingerprinting in text-to-image diffusion models
Changhoon Kim, Kyle Min, Maitreya Patel, Sheng Cheng, and Yezhou Yang. Wouaf: Weight modulation for user attribution and fingerprinting in text-to-image diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8974–8983, 2024
work page 2024
-
[6]
Hidden: Hiding data with deep networks
Jiren Zhu, Russell Kaplan, Justin Johnson, and Li Fei-Fei. Hidden: Hiding data with deep networks. In Proceedings of the European conference on computer vision (ECCV), pages 657–672, 2018
work page 2018
-
[7]
Zhaoyang Jia, Han Fang, and Weiming Zhang. Mbrs: Enhancing robustness of dnn-based watermarking by mini-batch of real and simulated jpeg compression. InProceedings of the 29th ACM International Conference on Multimedia, pages 41–49, 2021
work page 2021
-
[8]
Stegastamp: Invisible hyperlinks in physical photographs
Matthew Tancik, Ben Mildenhall, and Ren Ng. Stegastamp: Invisible hyperlinks in physical photographs. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 2117–2126, 2020
work page 2020
-
[9]
The stable signature: Rooting watermarks in latent diffusion models
Pierre Fernandez, Guillaume Couairon, Hervé Jégou, Matthijs Douze, and Teddy Furon. The stable signature: Rooting watermarks in latent diffusion models. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 22466–22477, 2023
work page 2023
-
[10]
Yuxin Wen, John Kirchenbauer, Jonas Geiping, and Tom Goldstein. Tree-rings watermarks: Invisible fingerprints for diffusion images.Advances in Neural Information Processing Systems, 36:58047–58063, 2023
work page 2023
-
[11]
Robust-wide: Robust watermarking against instruction-driven image editing
Runyi Hu, Jie Zhang, Ting Xu, Jiwei Li, and Tianwei Zhang. Robust-wide: Robust watermarking against instruction-driven image editing. InEuropean Conference on Computer Vision, pages 20–37. Springer, 2024. 10
work page 2024
-
[12]
Minzhou Pan, Yi Zeng, Zongyuan Ge, and Ruoxi Jia. Jigmark: A black-box approach for enhancing image watermarks against diffusion model edits.arXiv preprint arXiv:2406.03720, 2024
-
[13]
Shilin Lu, Zihan Zhou, Jiayou Lu, Yuanzhi Zhu, and Adams Wai-Kin Kong. Robust watermarking using generative priors against image editing: From benchmarking to advances.arXiv preprint arXiv:2410.18775, 2024
-
[14]
Editguard: Versatile image watermarking for tamper localization and copyright protection
Xuanyu Zhang, Runyi Li, Jiwen Yu, Youmin Xu, Weiqi Li, and Jian Zhang. Editguard: Versatile image watermarking for tamper localization and copyright protection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 11964–11974, 2024
work page 2024
-
[15]
Sleepermark: Towards robust watermark against fine-tuning text-to-image diffusion models
Zilan Wang, Junfeng Guo, Jiacheng Zhu, Yiming Li, Heng Huang, Muhao Chen, and Zhengzhong Tu. Sleepermark: Towards robust watermark against fine-tuning text-to-image diffusion models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 8213–8224, 2025
work page 2025
-
[16]
SDEdit: Guided Image Synthesis and Editing with Stochastic Differential Equations
Chenlin Meng, Yutong He, Yang Song, Jiaming Song, Jiajun Wu, Jun-Yan Zhu, and Stefano Ermon. Sdedit: Guided image synthesis and editing with stochastic differential equations.arXiv preprint arXiv:2108.01073, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[17]
Instructpix2pix: Learning to follow image editing instructions
Tim Brooks, Aleksander Holynski, and Alexei A Efros. Instructpix2pix: Learning to follow image editing instructions. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 18392–18402, 2023
work page 2023
-
[18]
Diffusionclip: Text-guided diffusion models for robust image manipulation
Gwanghyun Kim, Taesung Kwon, and Jong Chul Ye. Diffusionclip: Text-guided diffusion models for robust image manipulation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2426–2435, 2022
work page 2022
-
[19]
Diffusion models already have a semantic latent space.arXiv preprint arXiv:2210.10960,
Mingi Kwon, Jaeseok Jeong, and Youngjung Uh. Diffusion models already have a semantic latent space. arXiv preprint arXiv:2210.10960, 2022
-
[20]
Prompt-to-Prompt Image Editing with Cross Attention Control
Amir Hertz, Ron Mokady, Jay Tenenbaum, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Prompt-to- prompt image editing with cross attention control.arXiv preprint arXiv:2208.01626, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[21]
Rosteals: Robust steganography using autoencoder latent space
Tu Bui, Shruti Agarwal, Ning Yu, and John Collomosse. Rosteals: Robust steganography using autoencoder latent space. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, pages 933–942, 2023
work page 2023
-
[22]
Tu Bui, Shruti Agarwal, and John Collomosse. Trustmark: Universal watermarking for arbitrary resolution images.arXiv preprint arXiv:2311.18297, 2023
-
[23]
Waves: Benchmarking the robustness of image watermarks.arXiv preprint arXiv:2401.08573, 2024
Bo An, Ming Ding, Mohammad Rabbani, Shipra Agrawal, Hu Xu, Ke Deng, Nanning Zhu, Amr Mo- hamed, Galen McMahan, Shyam Raman, Micah Goldblum, Jonas Geiping, and Tom Goldstein. Waves: Benchmarking the robustness of image watermarks.arXiv preprint arXiv:2401.08573, 2024
-
[24]
LSUN: Construction of a Large-scale Image Dataset using Deep Learning with Humans in the Loop
Fisher Yu, Ari Seff, Yinda Zhang, Shuran Song, Thomas Funkhouser, and Jianxiong Xiao. Lsun: Con- struction of a large-scale image dataset using deep learning with humans in the loop.arXiv preprint arXiv:1506.03365, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[25]
Deep learning face attributes in the wild
Ziwei Liu, Ping Luo, Xiaogang Wang, and Xiaoou Tang. Deep learning face attributes in the wild. In Proceedings of International Conference on Computer Vision (ICCV), December 2015
work page 2015
-
[26]
Stargan v2: Diverse image synthesis for multiple domains
Yunjey Choi, Youngjung Uh, Jaejun Yoo, and Jung-Woo Ha. Stargan v2: Diverse image synthesis for multiple domains. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2020
work page 2020
-
[27]
Nikita Starodubcev, Dmitry Baranchuk, Valentin Khrulkov, and Artem Babenko. Towards real-time text-driven image manipulation with unconditional diffusion models.arXiv preprint arXiv:2304.04344, 2023
-
[28]
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium.Advances in neural information processing systems, 30, 2017
work page 2017
-
[29]
Improved techniques for training gans.Advances in neural information processing systems, 29, 2016
Tim Salimans, Ian Goodfellow, Wojciech Zaremba, Vicki Cheung, Alec Radford, and Xi Chen. Improved techniques for training gans.Advances in neural information processing systems, 29, 2016
work page 2016
-
[30]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021. 11
work page 2021
-
[31]
Drag your gan: Interactive point-based manipulation on the generative image manifold
Xingang Pan, Ayush Tewari, Thomas Leimkühler, Lingjie Liu, Abhimitra Meka, and Christian Theobalt. Drag your gan: Interactive point-based manipulation on the generative image manifold. InACM SIGGRAPH 2023 conference proceedings, pages 1–11, 2023
work page 2023
-
[32]
Huan Ling, Karsten Kreis, Daiqing Li, Seung Wook Kim, Antonio Torralba, and Sanja Fidler. Editgan: High-precision semantic image editing.Advances in Neural Information Processing Systems, 34:16331– 16345, 2021
work page 2021
-
[33]
Omniguard: Hybrid manipulation localization via augmented versatile deep image watermarking
Xuanyu Zhang, Zecheng Tang, Zhipei Xu, Runyi Li, Youmin Xu, Bin Chen, Feng Gao, and Jian Zhang. Omniguard: Hybrid manipulation localization via augmented versatile deep image watermarking. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 3008–3018, 2025
work page 2025
-
[34]
Lijun Zhang, Xiao Liu, Antoni V Martin, Cindy X Bearfield, Yuriy Brun, and Hui Guan. Attack-resilient image watermarking using stable diffusion.Advances in Neural Information Processing Systems, 37: 38480–38507, 2024
work page 2024
-
[35]
C2pa technical specification, version 1.3
Coalition for Content Provenance and Authenticity (C2PA). C2pa technical specification, version 1.3. https://c2pa.org/specifications/specifications/1.3/index.html, 2023. Accessed: 2026- 02-02
work page 2023
-
[36]
Adam: A Method for Stochastic Optimization
Diederik P Kingma. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980, 2014. A Background A.1 Diffusion-Based Image Editing Diffusion models have not only revolutionized image synthesis but have also reshaped image editing by providing a flexible, semantically rich generative prior. Traditional editing techniques, ranging from Photo...
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[37]
= 0) gives H(W b | ˆWb)≤H 2(1−a b). Expanding H(W| ˆW) by the chain rule and using that conditioning on a richerσ-algebra reduces entropy, H(W| ˆW) = BX b=1 H(W b |W <b, ˆW)≤ BX b=1 H(W b | ˆWb)≤ BX b=1 H2(1−a b), where the first inequality holds because (W<b, ˆW) contains ˆWb as a sub-component. By concavity of H2 on [0,1] (Jensen),P b H2(1−a b)≤B H 2(1−...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.