Template Collapse and Information-Theoretic Limits in Camera rPPG Pulse Morphology Restoration
Pith reviewed 2026-06-28 10:38 UTC · model grok-4.3
The pith
No architecture recovers subject-specific pulse morphology from single-cycle camera rPPG due to template collapse.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
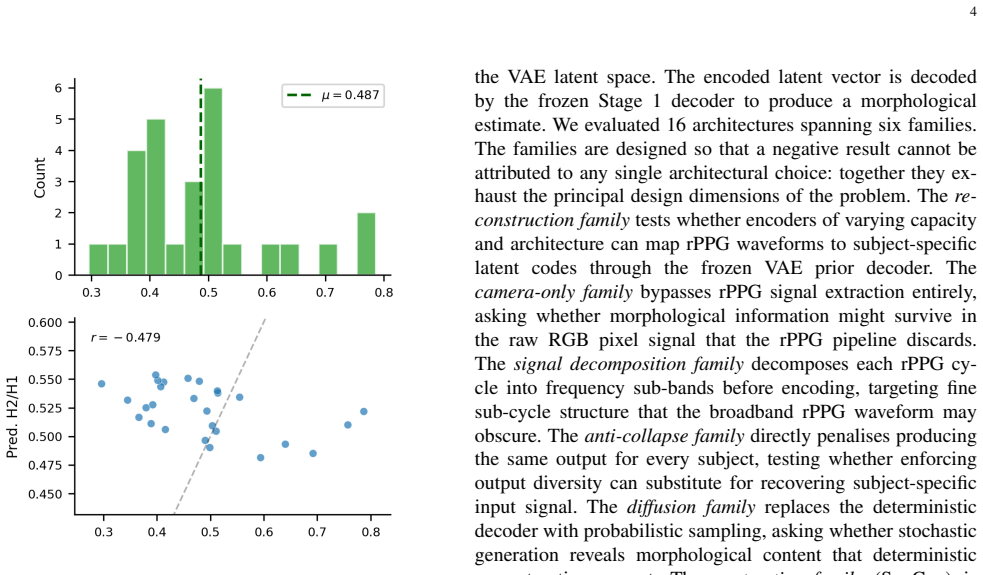
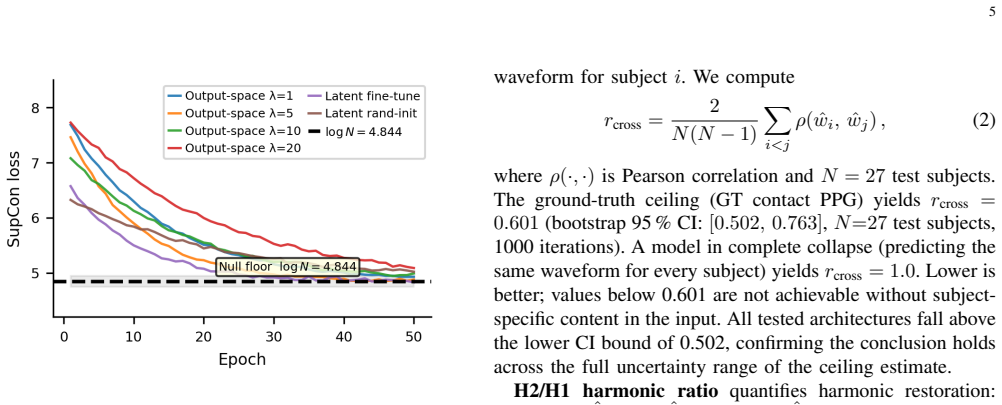
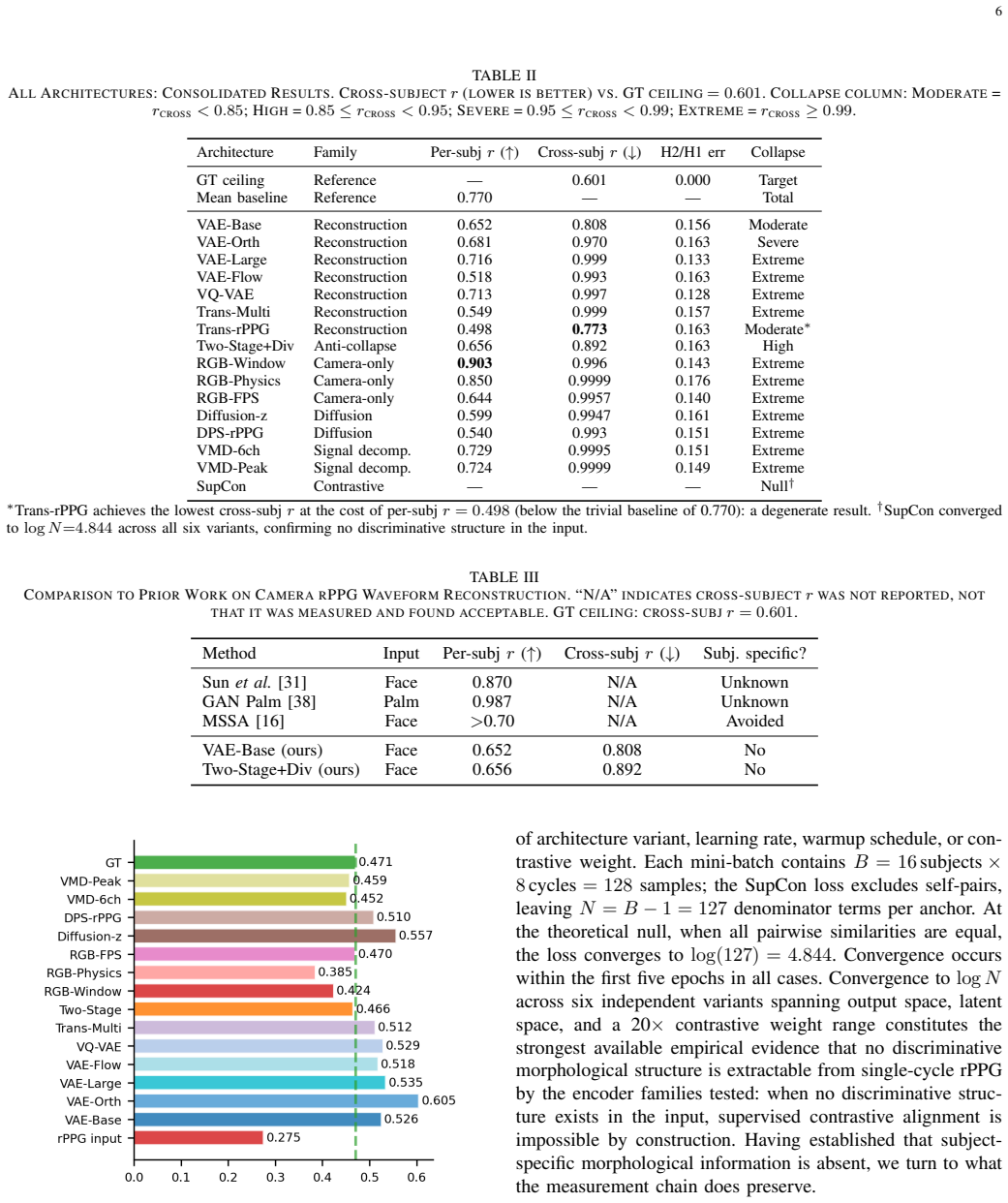
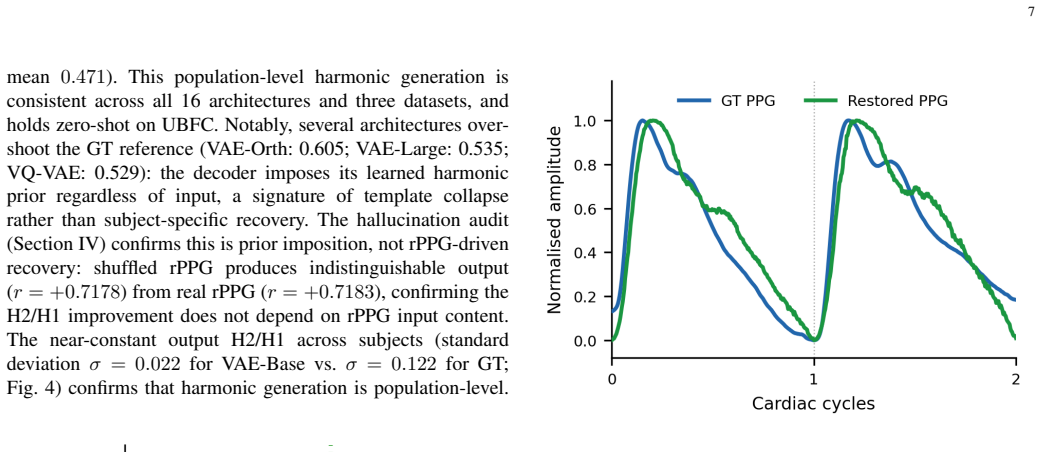
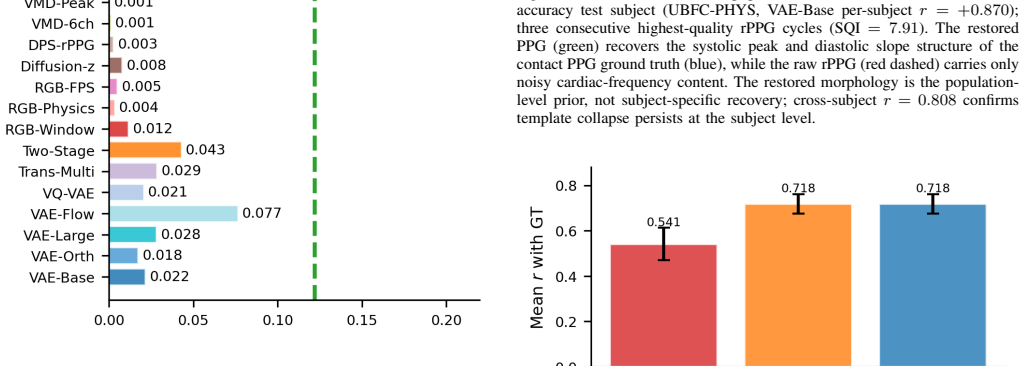
No architecture recovered subject-specific morphology (cross-subject r range 0.773--0.9999; ground-truth ceiling 0.601). Supervised Contrastive (SupCon) converged to log N = 4.844, constituting the strongest available empirical evidence that no discriminative morphological structure is extractable from single-cycle rPPG by the encoder families tested. The VAE decoder restores population-level harmonic content absent from the rPPG input (H2/H1: 0.310 output vs. 0.275 input), generalising zero-shot to UBFC (r = +0.708); a directional hallucination gap (p = 0.150) suggests partial signal reading.
What carries the argument
Cross-subject Pearson r diagnostic that separates template collapse from subject-specific recovery in rPPG waveform reconstruction tasks.
If this is right
- Anti-collapse objectives cannot succeed when the input signal itself carries no discriminative morphological structure.
- VAE-style decoders can restore population-level harmonic content and generalise zero-shot across datasets even without subject-specific recovery.
- Cross-subject r becomes a required diagnostic for any waveform reconstruction benchmark claiming morphology restoration.
- Consumer-camera rPPG is limited to population-level cardiovascular signals rather than individual arterial morphology.
Where Pith is reading between the lines
- Multi-cycle or multi-modal inputs may be required to access subject-specific morphology that single-cycle rPPG lacks.
- Remote cardiovascular monitoring applications that assume camera rPPG can supply arterial stiffness biomarkers will need re-evaluation.
- New encoder families can be screened with the cross-subject r metric to test whether they overcome the observed information limit.
Load-bearing premise
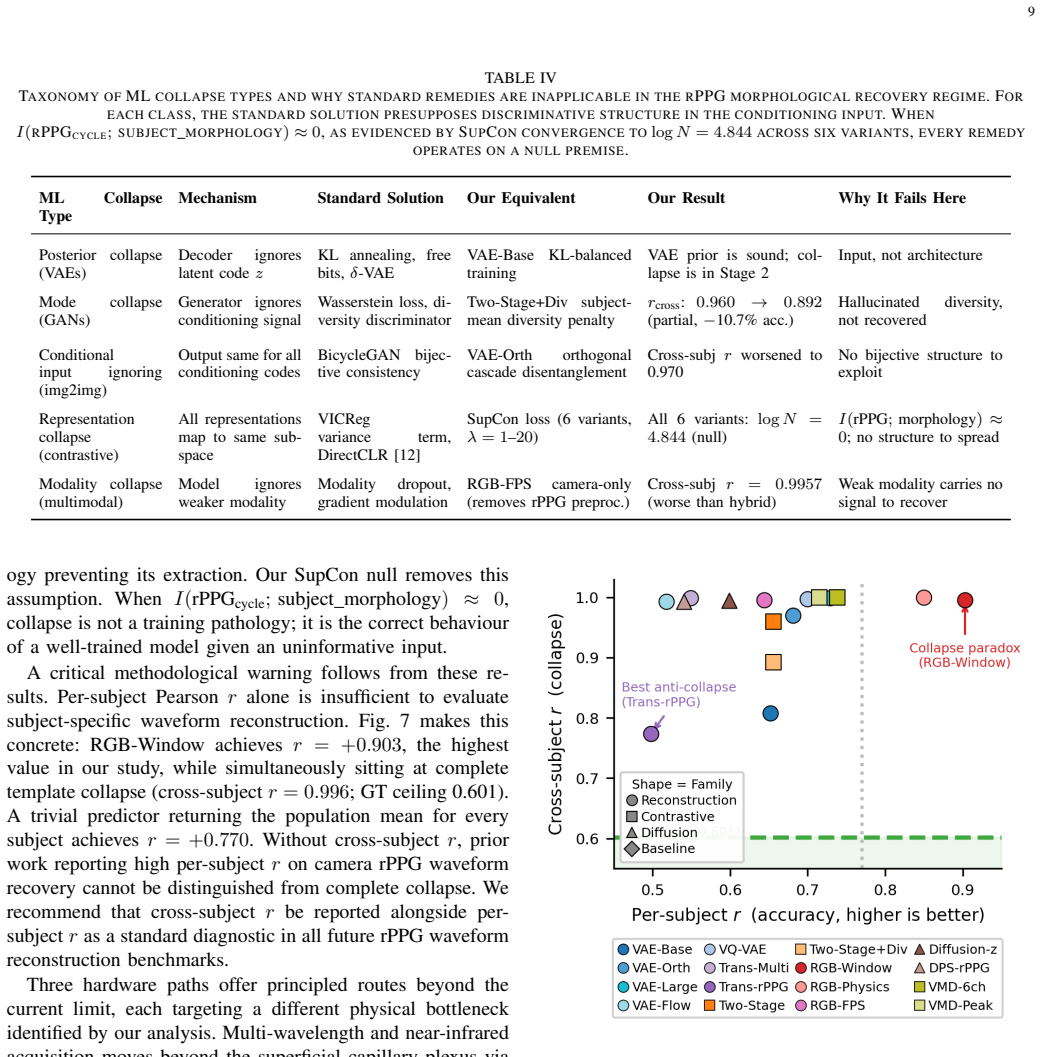
The 16 architectures spanning six families evaluated on the three datasets are representative enough to support the conclusion that no discriminative morphological structure is extractable from single-cycle rPPG.
What would settle it
An architecture that produces cross-subject Pearson r near the ground-truth ceiling of 0.601 while preserving high fidelity to individual subject waveforms on the same datasets would falsify the claim.
Figures
read the original abstract
Objective: Consumer face camera remote photoplethysmography (rPPG) enables passive cardiovascular monitoring, but whether single-cycle waveform morphology encoding arterial stiffness biomarkers is recoverable from this measurement has not been characterised. Methods: We evaluated 16 architectures spanning six families on 153 subjects across three datasets, introducing cross-subject Pearson r to distinguish subject-specific recovery from template collapse. Results: No architecture recovered subject-specific morphology (cross-subject r range 0.773--0.9999; ground-truth ceiling 0.601). Supervised Contrastive (SupCon) converged to log N = 4.844, constituting the strongest available empirical evidence that no discriminative morphological structure is extractable from single-cycle rPPG by the encoder families tested. The VAE decoder restores population-level harmonic content absent from the rPPG input (H2/H1: 0.310 output vs. 0.275 input), generalising zero-shot to UBFC (r = +0.708); a directional hallucination gap (p = 0.150) suggests partial signal reading. Anti-collapse objectives fail when input carries no discriminative structure. Significance: Consumer cameras cannot encode individual arterial morphology; cross-subject r is a necessary collapse diagnostic for waveform reconstruction benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript evaluates 16 architectures from six families on single-cycle rPPG signals from 153 subjects across three datasets. It introduces cross-subject Pearson r as a diagnostic for template collapse versus subject-specific morphology recovery and reports that all tested models fail to recover subject-specific structure (cross-subject r range 0.773--0.9999 versus ground-truth ceiling 0.601), with Supervised Contrastive learning reaching log N = 4.844. A VAE decoder is shown to restore population-level harmonics and generalize zero-shot; the paper concludes that consumer cameras cannot encode individual arterial morphology.
Significance. If the empirical negative result holds under the tested conditions, the work supplies concrete evidence of information-theoretic limits on morphology restoration from camera rPPG, with the cross-subject r metric and the observation of VAE hallucination of absent harmonics constituting useful contributions. The breadth of the 16-architecture sweep strengthens the case that collapse is not an artifact of a single model family.
major comments (3)
- [Abstract (Significance)] Abstract, Significance: The unqualified statement that 'Consumer cameras cannot encode individual arterial morphology' extrapolates from negative results on a finite set of 16 architectures without any coverage analysis, theoretical motivation, or argument that the six families are representative of encoders that could extract morphology if present; this generalization is load-bearing for the central claim.
- [Results] Results: The reported cross-subject r range (0.773--0.9999) and SupCon log N = 4.844 are presented as the strongest available evidence, yet the manuscript provides no visible full results tables, exact preprocessing pipeline, model implementation details, or statistical testing procedures, preventing independent verification that these metrics demonstrate absence of extractable structure rather than implementation artifacts.
- [Results] Methods/Results: The ground-truth ceiling of 0.601 is used to benchmark the observed r values, but no derivation or section explains how this ceiling was computed from the data or why it constitutes an upper bound on recoverable morphology; this quantity is central to interpreting the collapse claim.
minor comments (2)
- [Abstract] The term 'log N convergence' and the precise definition of N are used in the abstract and results without an explicit equation or paragraph defining the metric in the main text.
- [Results] The p = 0.150 value for the directional hallucination gap is reported but lacks a description of the underlying statistical test or how the gap was quantified.
Simulated Author's Rebuttal
We thank the referee for these constructive comments. We respond point-by-point below, indicating revisions where the manuscript can be strengthened for clarity and completeness.
read point-by-point responses
-
Referee: [Abstract (Significance)] Abstract, Significance: The unqualified statement that 'Consumer cameras cannot encode individual arterial morphology' extrapolates from negative results on a finite set of 16 architectures without any coverage analysis, theoretical motivation, or argument that the six families are representative of encoders that could extract morphology if present; this generalization is load-bearing for the central claim.
Authors: We agree the Significance statement requires qualification to match the empirical scope. The six families were chosen to cover dominant paradigms in the rPPG and time-series literature (CNN, RNN, Transformer/attention, contrastive, variational, and hybrid). In revision we will change the Significance sentence to end with 'by the encoder families tested' and add a brief paragraph in Discussion noting the selection rationale while acknowledging that novel architectures could in principle behave differently. revision: yes
-
Referee: [Results] Results: The reported cross-subject r range (0.773--0.9999) and SupCon log N = 4.844 are presented as the strongest available evidence, yet the manuscript provides no visible full results tables, exact preprocessing pipeline, model implementation details, or statistical testing procedures, preventing independent verification that these metrics demonstrate absence of extractable structure rather than implementation artifacts.
Authors: We accept that full transparency is required. The current text reports summary statistics; the revision will move the complete per-architecture table, the exact preprocessing steps (filtering, cycle segmentation, normalization), model hyper-parameters, and the statistical procedures used to obtain the reported ranges and log N into the supplementary material. revision: yes
-
Referee: [Results] Methods/Results: The ground-truth ceiling of 0.601 is used to benchmark the observed r values, but no derivation or section explains how this ceiling was computed from the data or why it constitutes an upper bound on recoverable morphology; this quantity is central to interpreting the collapse claim.
Authors: The value 0.601 is the mean pairwise cross-subject Pearson correlation computed on the ground-truth single-cycle PPG waveforms pooled across the three datasets; it supplies an empirical upper bound on inter-subject morphological similarity. We will insert a short subsection in Methods titled 'Ground-Truth Inter-Subject Correlation Ceiling' that derives the quantity and explains its role as benchmark. revision: yes
Circularity Check
No circularity: results are direct empirical computations on held-out data
full rationale
The paper reports cross-subject Pearson r, log N convergence, and harmonic ratios computed directly from running 16 architectures on three external datasets with held-out subjects. No equations define a quantity by fitting and then reuse it as a 'prediction'; no self-citation chain justifies the central negative claim; the evaluation stands on external benchmarks rather than internal definitions. This is self-contained empirical work with no load-bearing reductions of the enumerated kinds.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math Pearson correlation is an appropriate measure for quantifying waveform similarity and template collapse
- domain assumption The 16 architectures from six families are sufficient to test whether any encoder can extract discriminative morphology
Reference graph
Works this paper leans on
-
[1]
Arterial stiffness and hypertension,
H. Kim, “Arterial stiffness and hypertension,”Clinical Hypertension, vol. 29, no. 31, pp. 1–9, 2023, doi: 10.1186/s40885-023-00258-1
-
[2]
W. Wang, A. C. den Brinker, S. Stuijk, and G. de Haan, “Algorithmic principles of remote-PPG,”IEEE Trans. Biomed. Eng., vol. 64, no. 7, pp. 1479–1491, Jul. 2017, doi: 10.1109/TBME.2016.2609282
-
[3]
Joint generative and contrastive learning for unsupervised person re- identification,
H. Chen, Y . Wang, B. Lagadec, A. Dantcheva, and F. Bremond, “Joint generative and contrastive learning for unsupervised person re- identification,” inProc. IEEE/CVF CVPR, 2021, arXiv:2012.09071
arXiv 2021
-
[4]
Motion-focused contrastive learning of video representations,
R. Li, Y . Zhang, Z. Qiu, T. Yao, D. Liu, and T. Mei, “Motion-focused contrastive learning of video representations,” inProc. IEEE/CVF ICCV, 2021, arXiv:2201.04029
arXiv 2021
-
[5]
D. Le, S. Truong, B. Patel, D. A. Adjeroh, and N. Le, “sCL-ST: Su- pervised contrastive learning with semantic transformations for multiple lead ECG arrhythmia classification,”IEEE J. Biomed. Health Inform., vol. 27, no. 6, pp. 2818–2828, 2023, doi: 10.1109/JBHI.2023.3246241
-
[6]
Functional emotion transformer for EEG-assisted cross-modal emotion recognition,
W.-B. Jiang, Z. Li, W.-L. Zheng, and B.-L. Lu, “Functional emotion transformer for EEG-assisted cross-modal emotion recognition,” inProc. IEEE ICASSP, 2024
2024
-
[7]
Self-supervised contrastive learning performs non-linear system identification,
R. Gonz ´alez Laiz, T. Schmidt, and S. Schneider, “Self-supervised contrastive learning performs non-linear system identification,” inProc. ICLR, 2025, arXiv:2410.14673
arXiv 2025
-
[8]
Sub- ject invariant contrastive learning for human activity recognition,
Y . Yarici, K. Kokilepersaud, M. Prabhushankar, and G. AlRegib, “Sub- ject invariant contrastive learning for human activity recognition,” in IEEE 35th Int. Workshop Mach. Learn. Signal Process. (MLSP), 2025
2025
-
[9]
Robust pulse rate from chrominance-based rPPG,
G. de Haan and V . Jeanne, “Robust pulse rate from chrominance-based rPPG,”IEEE Trans. Biomed. Eng., vol. 60, no. 10, pp. 2878–2886, Oct. 2013, doi: 10.1109/TBME.2013.2266196
-
[10]
Cross modal distillation for super- vision transfer,
S. Gupta, J. Hoffman, and J. Malik, “Cross modal distillation for super- vision transfer,” inProc. IEEE/CVF CVPR, 2016, arXiv:1507.00448
Pith/arXiv arXiv 2016
-
[11]
Non -contact, automated cardiac pulse measurements using video imaging and blind source separation
M.-Z. Poh, D. J. McDuff, and R. W. Picard, “Non-contact, automated cardiac pulse measurements using video imaging and blind source separation,”Opt. Express, vol. 18, no. 10, pp. 10762–10774, 2010, doi: 10.1364/OE.18.010762
-
[12]
Understanding dimensional collapse in contrastive self-supervised learning,
L. Jing, P. Vincent, Y . LeCun, and Y . Tian, “Understanding dimensional collapse in contrastive self-supervised learning,” inProc. ICLR, 2022, arXiv:2110.09348
arXiv 2022
-
[13]
SyncGAN: Synchronize the latent space of cross-modal generative adversarial networks,
W.-C. Chen, C.-W. Chen, and M.-C. Hu, “SyncGAN: Synchronize the latent space of cross-modal generative adversarial networks,” inProc. IEEE ICME, 2018, arXiv:1804.00410
Pith/arXiv arXiv 2018
-
[14]
Cross-modal variational auto-encoder with distributed latent spaces and associators,
D. U. Jo, B. Lee, J. Choi, H. Yoo, and J. Y . Choi, “Cross-modal variational auto-encoder with distributed latent spaces and associators,” arXiv:1905.12867, 2019
Pith/arXiv arXiv 1905
-
[15]
Deep latent space learning for cross-modal mapping of audio and visual signals,
S. Nawaz, M. K. Janjua, I. Gallo, A. Mahmood, and A. Calefati, “Deep latent space learning for cross-modal mapping of audio and visual signals,” inProc. IEEE DICTA, 2019, arXiv:1909.08685
arXiv 2019
-
[16]
Preserving shape details of pulse signals for video-based blood pressure estimation,
X. Han, X. Yang, S. Fang, Y . Chen, Q. Chen, L. Li, and R. Song, “Preserving shape details of pulse signals for video-based blood pressure estimation,”Biomed. Opt. Express, vol. 15, no. 4, pp. 2433–2450, 2024, doi: 10.1364/BOE.516388
-
[17]
Supervised contrastive learning,
P. Khoslaet al., “Supervised contrastive learning,” inAdv. Neural Inf. Process. Syst. (NeurIPS), vol. 33, 2020, arXiv:2004.11362
arXiv 2020
-
[18]
Joint contrastive learning with infinite possibilities,
Q. Cai, Y . Wang, Y . Pan, T. Yao, and T. Mei, “Joint contrastive learning with infinite possibilities,” inAdv. Neural Inf. Process. Syst. (NeurIPS), vol. 33, 2020, arXiv:2009.14776
arXiv 2020
-
[19]
Guided variational autoen- coder for speech enhancement with a supervised classifier,
G. Carbajal, J. Richter, and T. Gerkmann, “Guided variational autoen- coder for speech enhancement with a supervised classifier,” inProc. IEEE ICASSP, 2021, pp. 681–685, arXiv:2102.06454
arXiv 2021
-
[20]
Towards fine-grained visual rep- resentations by combining contrastive learning with image reconstruc- tion and attention-weighted pooling,
J. Dippel, S. V ogler, and J. H ¨ohne, “Towards fine-grained visual rep- resentations by combining contrastive learning with image reconstruc- tion and attention-weighted pooling,” inICML 2021 Workshop: Self- Supervised Learning for Reasoning and Perception, 2021
2021
-
[21]
Variational supervised contrastive learning,
Z. Wang, J. Fan, T. Nguyen, H. Ji, and G. Liu, “Variational supervised contrastive learning,” inAdv. Neural Inf. Process. Syst. (NeurIPS), 2025, arXiv:2506.07413
arXiv 2025
-
[22]
Photoplethysmography for the assessment of arterial stiffness,
P. Karimpour, J. M. May, and P. A. Kyriacou, “Photoplethysmography for the assessment of arterial stiffness,”Sensors, vol. 23, no. 24, p. 9882, 2023, doi: 10.3390/s23249882
-
[23]
G. Basso, X. Long, R. Haakma, and R. Vullings, “Reduction of motion artifacts from photoplethysmography signals using learned convolutional sparse coding,” arXiv:2508.10805, 2025
arXiv 2025
-
[24]
SkinMap: Weighted full-body skin segmentation for robust remote photoplethysmography,
Z. Malekiet al., “SkinMap: Weighted full-body skin segmentation for robust remote photoplethysmography,” arXiv:2510.05296, 2025
arXiv 2025
-
[25]
L. Xiet al., “Weighted combination and singular spectrum analysis based remote photoplethysmography pulse extraction in low-light en- vironments,” arXiv:2503.03780, 2025
arXiv 2025
-
[26]
FreqPhys: Repurposing implicit physiological frequency prior for robust remote photoplethysmography,
W. Qianet al., “FreqPhys: Repurposing implicit physiological frequency prior for robust remote photoplethysmography,” arXiv:2604.00534, 2026
arXiv 2026
-
[27]
V . Frants, S. Agaian, and K. Panetta, “ToTMNet: FFT-accelerated Toeplitz temporal mixing network for lightweight remote photoplethys- mography,” arXiv:2601.04159, 2026
arXiv 2026
-
[28]
CP-PPG: Restoring photoplethysmography waveform morphology from poor skin contact,
T. H. Phamet al., “CP-PPG: Restoring photoplethysmography waveform morphology from poor skin contact,”Sci. Rep., 2025, doi: 10.1038/s41598-025-31883-5
-
[29]
PPGFlowECG: Latent rectified flow with cross-modal encoding for PPG-guided ECG generation,
X. Fanget al., “PPGFlowECG: Latent rectified flow with cross-modal encoding for PPG-guided ECG generation,” arXiv:2509.19774, 2025
arXiv 2025
-
[30]
SIGMA-PPG: Statistical-prior informed generative mask- ing architecture for PPG foundation model,
Z. Guoet al., “SIGMA-PPG: Statistical-prior informed generative mask- ing architecture for PPG foundation model,” arXiv:2601.21031, 2026. 11
arXiv 2026
-
[31]
Biometric authentication via hybrid cPPG–rPPG training,
Z. Sunet al., “Biometric authentication via hybrid cPPG–rPPG training,” inProc. IEEE IJCB, 2024, arXiv:2407.04127
arXiv 2024
-
[32]
B. F. Wuet al., “Contactless blood pressure measurement via remote photoplethysmography with synthetic data generation using generative adversarial networks,”IEEE J. Biomed. Health Inform., vol. 28, no. 2, pp. 621–632, Feb. 2024, doi: 10.1109/JBHI.2023.3265857
-
[33]
Toward multimodal image-to-image translation,
J.-Y . Zhuet al., “Toward multimodal image-to-image translation,” in Adv. Neural Inf. Process. Syst. (NeurIPS), 2017, arXiv:1711.11586
Pith/arXiv arXiv 2017
-
[34]
VICReg: Variance-invariance- covariance regularization for self-supervised learning,
A. Bardes, J. Ponce, and Y . LeCun, “VICReg: Variance-invariance- covariance regularization for self-supervised learning,” inProc. ICLR, 2022
2022
-
[35]
G. Slapni ˇcar, W. Wang, and M. Lu ˇstek, “Feasibility of remote pulse transit time estimation using narrow-band multi-wavelength camera pho- toplethysmography,” inProc. ACM Int. Joint Conf. Pervasive Ubiquitous Comput. (UbiComp), 2022, doi: 10.1145/3544793.3560339
-
[36]
F. Shirbaniet al., “Contactless video-based photoplethysmography tech- nique comparison investigating pulse transit time estimation of arterial blood pressure,” inProc. IEEE Eng. Med. Biol. Soc. (EMBC), 2021, doi: 10.1109/EMBC46164.2021.9629489
-
[37]
Remote physiological monitoring of neck blood vessels with a high-speed camera,
M. Cao, G. Saiko, and A. Douplik, “Remote physiological monitoring of neck blood vessels with a high-speed camera,”Adv. Opt. Technol., vol. 14, 2025, doi: 10.3389/aot.2025.1536415
-
[38]
High-fidelity rPPG waveform reconstruction from palm videos using GANs,
T. Li and Y . Liu, “High-fidelity rPPG waveform reconstruction from palm videos using GANs,”Sensors, vol. 26, no. 2, art. 563, 2026, doi: 10.3390/s26020563
-
[39]
How suboptimal is training rPPG models with videos and targets from different body sites?,
M. Braun, G. Bauer, and M. Elgendi, “How suboptimal is training rPPG models with videos and targets from different body sites?,” inProc. CVPR Workshop, 2024, arXiv:2403.10582
arXiv 2024
-
[40]
Exploiting multiwavelength morphological features of camera-PPG for blood pressure estimation,
Z. Houet al., “Exploiting multiwavelength morphological features of camera-PPG for blood pressure estimation,”IEEE Trans. Instrum. Meas., 2025, doi: 10.1109/TIM.2025.3551005
-
[41]
Depth penetration of light into skin as a function of wavelength from 200 to 1000 nm,
L. Finlayson, I. R. M. Barnard, L. McMillan, S. H. Ibbotson, C. T. A. Brown, E. Eadie, and K. Wood, “Depth penetration of light into skin as a function of wavelength from 200 to 1000 nm,”Photochem. Pho- tobiol., vol. 98, no. 4, pp. 974–981, Jul. 2022, doi: 10.1111/php.13550
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.