Prompt-Calibrated SAM 3 for Open-Vocabulary Remote Sensing Semantic Segmentation
Pith reviewed 2026-06-26 12:26 UTC · model grok-4.3
The pith
ProC-SAM3 calibrates SAM 3 prompts offline to reach 56.1 percent average mIoU in remote sensing open-vocabulary segmentation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
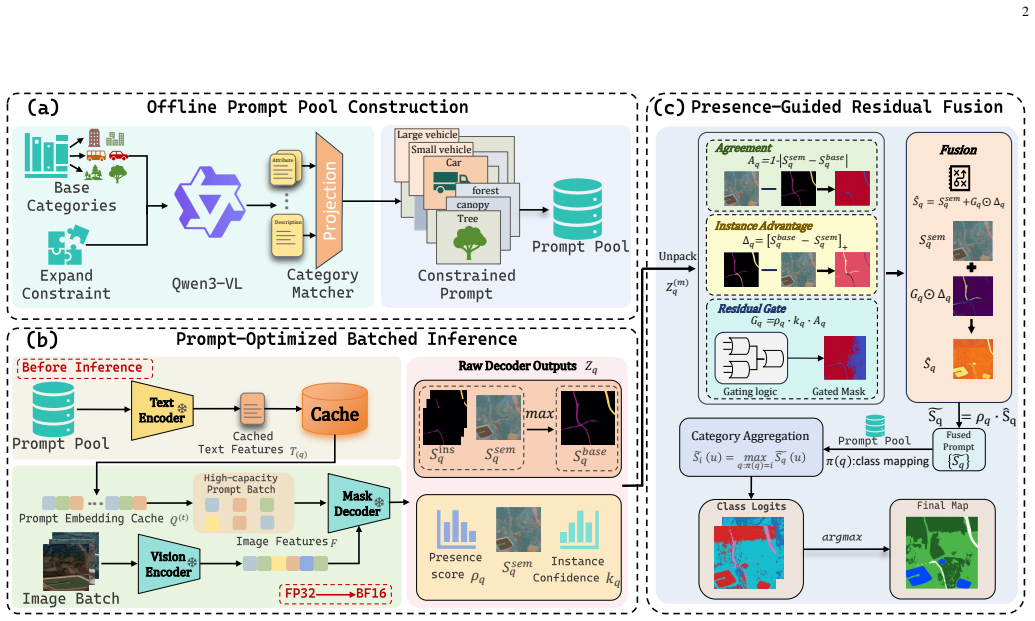
ProC-SAM3 calibrates SAM 3's prompt interface for remote sensing OVSS from three complementary aspects. First, an offline prompt pool is built where a Category Matcher groups MLLM-generated candidates into per-category sets and Expansion Constraints refine each set using category-specific prior knowledge. Second, the resulting text embeddings are cached and reused across all test images. Third, Presence-Guided Residual Fusion gates unreliable decoder outputs by prompt presence and confidence, followed by peak-preserving class aggregation that retains fine-grained activations for small and sparse objects. On eight benchmarks this yields an average mIoU of 56.1 percent, 3.9 percentage points a
What carries the argument
The three-aspect prompt calibration pipeline: offline prompt pool via Category Matcher and Expansion Constraints, cached text embeddings, and Presence-Guided Residual Fusion with peak-preserving aggregation.
If this is right
- Caching embeddings removes repeated online text encoding for every test image.
- Presence-Guided Residual Fusion limits noisy activations from reaching the final map.
- Peak-preserving aggregation keeps fine detail for small and sparse objects that earlier aggregation steps tended to lose.
- The full pipeline remains training-free and produces measurable gains on eight separate remote sensing benchmarks.
- The method directly targets the three listed prompt-interface shortcomings of prior SAM 3 OVSS work.
Where Pith is reading between the lines
- The offline prompt-pool construction could be reused with newer multimodal models if their candidate generation is swapped in.
- Gating based on prompt presence might transfer to other decoder-heavy segmentation models that suffer from activation noise.
- The reported gains on small-object retention suggest the approach could help monitoring tasks where targets occupy few pixels, such as infrastructure or vegetation mapping.
- If the Category Matcher logic proves robust, similar grouping steps could reduce prompt redundancy in non-remote-sensing open-vocabulary tasks.
Load-bearing premise
The assumption that MLLM-generated prompt candidates grouped by the Category Matcher and refined by Expansion Constraints, combined with presence-guided gating, will reliably reduce noise and preserve small-object detail across unseen remote sensing distributions without introducing new biases or missing categories.
What would settle it
Evaluating ProC-SAM3 on a new remote sensing test set rich in small, sparse objects from unseen categories and measuring whether its mIoU falls below the previous training-free baseline would directly test the performance claim.
Figures

read the original abstract
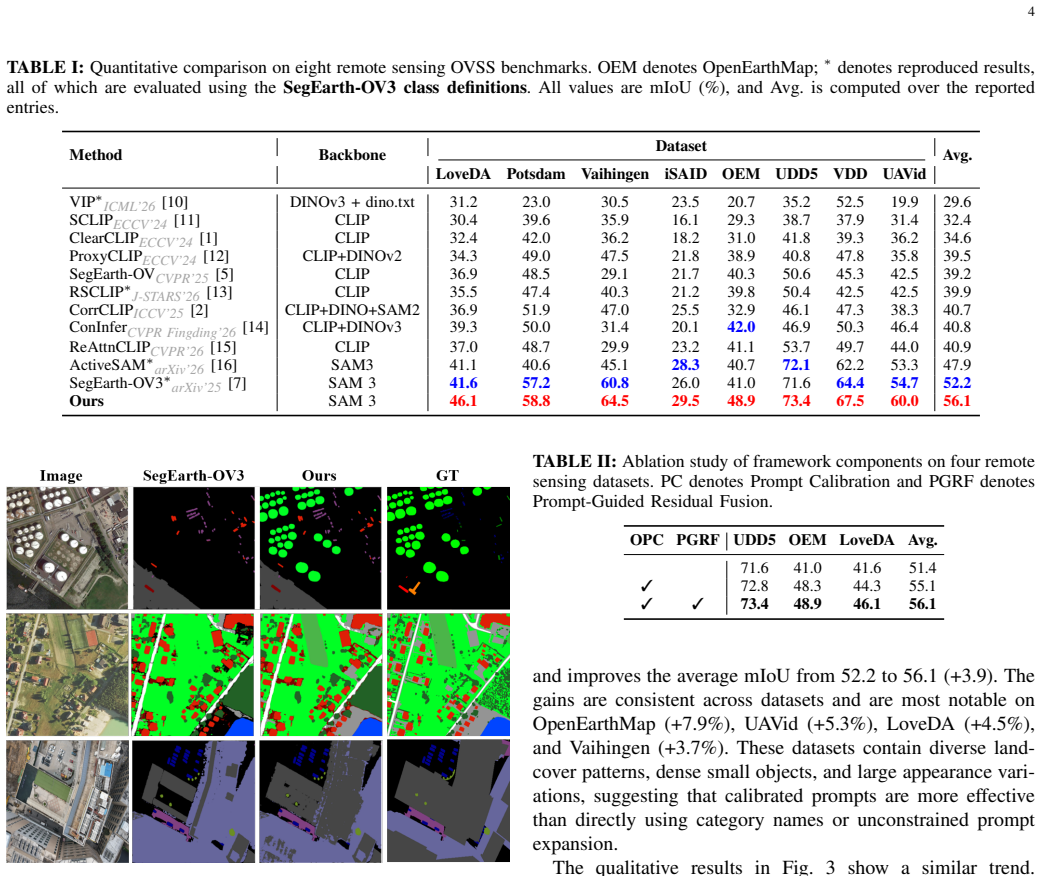
Open-vocabulary semantic segmentation (OVSS) in remote sensing images aims to segment categories beyond a fixed label space. Recent SAM 3-based methods provide a promising training-free foundation, yet three key issues remain: (1) a single class-name prompt lacks sufficient semantic coverage for complex remote sensing categories; (2) expanding each category into multiple prompts introduces redundant online text encoding; and (3) directly aggregating multiple prompt responses propagates noisy activations into the final prediction. To address these issues, we propose ProC-SAM3, which calibrates SAM 3's prompt interface for remote sensing OVSS from three complementary aspects. First, we construct an offline prompt pool where a Category Matcher groups MLLM-generated candidates into per-category sets, and Expansion Constraints further refine each set using category-specific prior knowledge. Second, the resulting text embeddings are cached and reused across all test images, eliminating repeated text encoding. Third, we introduce Presence-Guided Residual Fusion to gate unreliable decoder outputs by prompt presence and confidence, followed by peak-preserving class aggregation that retains fine-grained activations for small and sparse objects. Experiments on eight benchmarks show that ProC-SAM3 achieves an average mIoU of 56.1%, outperforming the previous best training-free method by 3.9 percentage points. Code will be available at https://github.com/YanghuiSong/ProC-SAM3.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ProC-SAM3, a training-free calibration of SAM 3 for open-vocabulary semantic segmentation on remote sensing images. It addresses limited semantic coverage of single class-name prompts, redundant online text encoding from prompt expansion, and noisy aggregation of multiple prompt responses via three components: an offline prompt pool (MLLM-generated candidates grouped by Category Matcher and refined by Expansion Constraints), cached text embeddings, and Presence-Guided Residual Fusion (gating by prompt presence/confidence plus peak-preserving class aggregation to retain small-object detail). Experiments on eight benchmarks report 56.1% average mIoU, a 3.9 pp gain over the prior best training-free baseline.
Significance. If the reported gains prove robust, the work supplies a practical, efficient mechanism for improving training-free OVSS in remote sensing by reducing prompt redundancy and controlling noise while preserving fine-grained activations. The offline caching and presence-guided gating are internally consistent with the problem statement and could transfer to other SAM-based pipelines where repeated encoding cost or small-object fidelity is a concern.
major comments (3)
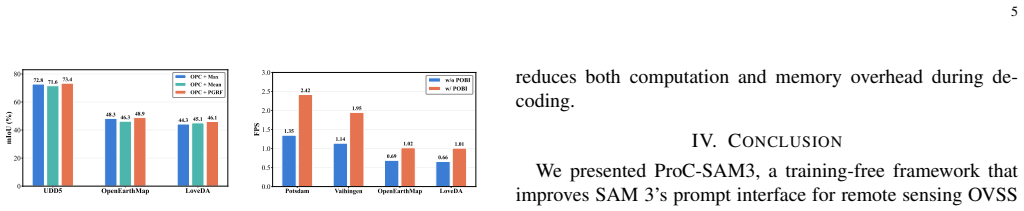
- [§4] §4 (Experiments): The central claim of a 3.9 pp mIoU improvement rests on comparisons to prior training-free methods, yet the manuscript provides no implementation details for the baselines, no statistical significance tests, and no analysis of post-hoc choices in fusion thresholds or presence thresholds; without these, it is impossible to determine whether the reported average of 56.1% is reproducible or sensitive to implementation decisions.
- [§3.3] §3.3 (Presence-Guided Residual Fusion): The gating mechanism is presented as reliably reducing noise while preserving small-object detail, but no ablation isolates the contribution of the presence-guided term versus simple averaging, nor are failure cases or category-miss rates reported on the eight benchmarks; this leaves the weakest assumption (reliable noise reduction across unseen distributions) unsupported by direct evidence.
- [Abstract, §4] Abstract and §4: The eight-benchmark evaluation is summarized only by the aggregate 56.1% mIoU; per-dataset scores, variance across random seeds, and comparison against strong training-based OVSS baselines are absent, weakening the interpretation that the architectural changes are the primary driver of the observed delta.
minor comments (2)
- [§3.1] Notation for the Category Matcher and Expansion Constraints is introduced without an explicit algorithm box or pseudocode, making the offline pool construction harder to re-implement.
- [Abstract] The paper states that code will be released but does not specify the exact prompt-generation procedure or the MLLM used, which affects reproducibility of the prompt pool.
Simulated Author's Rebuttal
We thank the referee for the insightful comments, which highlight important aspects of reproducibility and empirical validation. We address each major comment below and will incorporate revisions to strengthen the paper.
read point-by-point responses
-
Referee: [§4] The central claim of a 3.9 pp mIoU improvement rests on comparisons to prior training-free methods, yet the manuscript provides no implementation details for the baselines, no statistical significance tests, and no analysis of post-hoc choices in fusion thresholds or presence thresholds; without these, it is impossible to determine whether the reported average of 56.1% is reproducible or sensitive to implementation decisions.
Authors: We agree that additional details are necessary for reproducibility. In the revised version, we will provide full implementation details for the baselines (including any hyperparameters and code references), conduct statistical significance tests on the mIoU improvements, and include an analysis of the sensitivity to the fusion and presence thresholds. Since the code will be released, this will allow full verification. revision: yes
-
Referee: [§3.3] The gating mechanism is presented as reliably reducing noise while preserving small-object detail, but no ablation isolates the contribution of the presence-guided term versus simple averaging, nor are failure cases or category-miss rates reported on the eight benchmarks; this leaves the weakest assumption (reliable noise reduction across unseen distributions) unsupported by direct evidence.
Authors: We acknowledge the need for more direct evidence. We will add an ablation study that compares the full Presence-Guided Residual Fusion against a simple averaging baseline. We will also report failure cases and category-miss rates across the benchmarks to better support the effectiveness of the noise reduction mechanism. revision: yes
-
Referee: [Abstract, §4] The eight-benchmark evaluation is summarized only by the aggregate 56.1% mIoU; per-dataset scores, variance across random seeds, and comparison against strong training-based OVSS baselines are absent, weakening the interpretation that the architectural changes are the primary driver of the observed delta.
Authors: We will revise the experiments section to report per-dataset mIoU scores for all eight benchmarks, include variance measures (e.g., across different prompt seeds if applicable), and add comparisons to representative training-based OVSS methods to provide broader context. This will help clarify the contributions of our training-free approach. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper describes an empirical training-free method (ProC-SAM3) consisting of an offline prompt pool construction via Category Matcher and Expansion Constraints, cached embeddings, and Presence-Guided Residual Fusion with peak-preserving aggregation. The central claim is an observed 56.1% average mIoU on eight external benchmarks, presented as the direct experimental outcome of these architectural changes rather than any derived theorem, fitted parameter renamed as prediction, or self-referential equation. No load-bearing step reduces by construction to its own inputs, no uniqueness theorem is imported via self-citation, and the performance delta is not forced by internal definitions. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption SAM 3 produces usable segmentation masks from text prompts in remote sensing imagery
- domain assumption MLLM-generated text candidates can be grouped and constrained to form useful per-category prompt sets
Reference graph
Works this paper leans on
-
[1]
Clearclip: Decomposing clip representations for dense vision-language inference,
M. Lan, C. Chen, Y . Ke, X. Wang, L. Feng, and W. Zhang, “Clearclip: Decomposing clip representations for dense vision-language inference,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 143– 160
2024
-
[2]
Corrclip: Reconstructing patch correla- tions in clip for open-vocabulary semantic segmentation,
D. Zhang, F. Liu, and Q. Tang, “Corrclip: Reconstructing patch correla- tions in clip for open-vocabulary semantic segmentation,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 24 677–24 687
2025
-
[3]
Open-vocabulary high-resolution remote sensing image semantic segmentation,
Q. Cao, Y . Chen, C. Ma, and X. Yang, “Open-vocabulary high-resolution remote sensing image semantic segmentation,”IEEE Transactions on Geoscience and Remote Sensing, 2025
2025
-
[4]
Sota: Self-adaptive optimal transport for zero-shot classification with multiple foundation models,
Z. Hu, Q. Xu, Y . Duan, Y . Tai, and H. Li, “Sota: Self-adaptive optimal transport for zero-shot classification with multiple foundation models,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2026, pp. 26 624–26 634
2026
-
[5]
Segearth-ov: Towards training-free open-vocabulary segmentation for remote sensing images,
K. Li, R. Liu, X. Cao, X. Bai, F. Zhou, D. Meng, and Z. Wang, “Segearth-ov: Towards training-free open-vocabulary segmentation for remote sensing images,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 10 545–10 556
2025
-
[6]
Annotation-free open-vocabulary segmentation for remote-sensing im- ages,
K. Li, X. Cao, R. Liu, S. Wang, Z. Jiang, Z. Wang, and D. Meng, “Annotation-free open-vocabulary segmentation for remote-sensing im- ages,”arXiv preprint arXiv:2508.18067, 2025
arXiv 2025
-
[7]
Segearth- ov3: Exploring sam 3 for open-vocabulary semantic segmentation in remote sensing images,
K. Li, S. Zhang, Y . Deng, Z. Wang, D. Meng, and X. Cao, “Segearth- ov3: Exploring sam 3 for open-vocabulary semantic segmentation in remote sensing images,”arXiv preprint arXiv:2512.08730, 2025
Pith/arXiv arXiv 2025
-
[8]
Pointsam: Pointly- supervised segment anything model for remote sensing images,
N. Liu, X. Xu, Y . Su, H. Zhang, and H.-C. Li, “Pointsam: Pointly- supervised segment anything model for remote sensing images,”IEEE Transactions on Geoscience and Remote Sensing, vol. 63, pp. 1–15, 2025
2025
-
[9]
Taming sam3 in the wild: A concept bank for open-vocabulary segmentation,
G. Pei, X. Jiang, Y . Yao, X. Shu, F. Shen, and B. Jeon, “Taming sam3 in the wild: A concept bank for open-vocabulary segmentation,”arXiv preprint arXiv:2602.06333, 2026
arXiv 2026
-
[10]
Vip: Visual- guided prompt evolution for efficient dense vision-language inference,
H. Zhu, S. Jin, W. Liao, J. Xiao, Y . Zhu, S. Yu, and F. Dai, “Vip: Visual- guided prompt evolution for efficient dense vision-language inference,” arXiv preprint arXiv:2605.12325, 2026
Pith/arXiv arXiv 2026
-
[11]
Sclip: Rethinking self-attention for dense vision-language inference,
F. Wang, J. Mei, and A. Yuille, “Sclip: Rethinking self-attention for dense vision-language inference,” inEuropean conference on computer vision. Springer, 2024, pp. 315–332
2024
-
[12]
Proxyclip: Proxy attention improves clip for open-vocabulary segmentation,
M. Lan, C. Chen, Y . Ke, X. Wang, L. Feng, and W. Zhang, “Proxyclip: Proxy attention improves clip for open-vocabulary segmentation,” in European Conference on Computer Vision. Springer, 2024, pp. 70– 88
2024
-
[13]
Rsclip for training-free open- vocabulary remote sensing image semantic segmentation,
S. Wang, X. Sun, J. Han, and X. X. Zhu, “Rsclip for training-free open- vocabulary remote sensing image semantic segmentation,”IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2026
2026
-
[14]
Coninfer: Context- aware inference for training-free open-vocabulary remote sensing seg- mentation,
W. Chen, Z. Hu, Y . Zhang, H. Ning, and Y . Tai, “Coninfer: Context- aware inference for training-free open-vocabulary remote sensing seg- mentation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2026, pp. 7408–7418
2026
-
[15]
Reattnclip: Training- free open-vocabulary remote sensing image segmentation via re-defined attention in clip,
X. Niu, M. Zhao, D. Jiang, Y . Wu, and B. Su, “Reattnclip: Training- free open-vocabulary remote sensing image segmentation via re-defined attention in clip,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2026, pp. 24 980–24 989
2026
-
[16]
Activesam: Image-conditional class pruning for fast and accurate open-vocabulary segmentation,
T. D. Tien and Z. Shen, “Activesam: Image-conditional class pruning for fast and accurate open-vocabulary segmentation,”arXiv preprint arXiv:2606.16996, 2026
arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.