A multifractal-based masked auto-encoder: an application to medical images
Pith reviewed 2026-06-29 22:34 UTC · model grok-4.3
The pith
Renyi entropy multifractal analysis directs masking in masked autoencoders to high-complexity regions for improved medical image learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that replacing random masking with a multifractal-optimized strategy based on Renyi entropy produces a masked autoencoder that learns more accurate representations of medical images by focusing reconstruction on diagnostically informative high-complexity regions.
What carries the argument
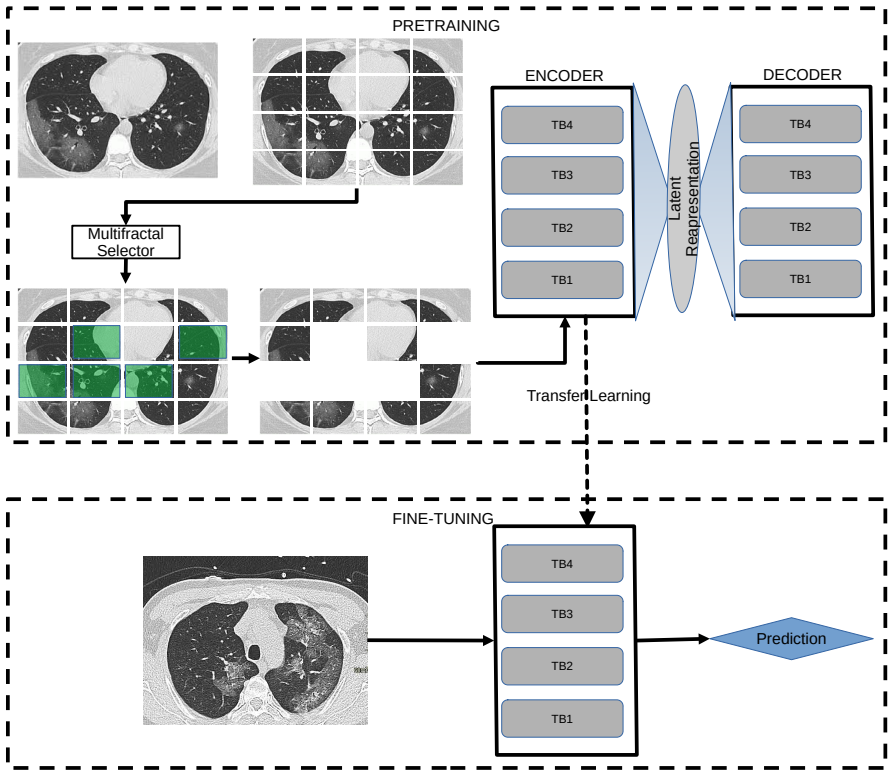
The Multifractal-Optimized Masked Autoencoder (MO-MAE), which computes a Renyi entropy multifractal spectrum to select masking locations.
If this is right
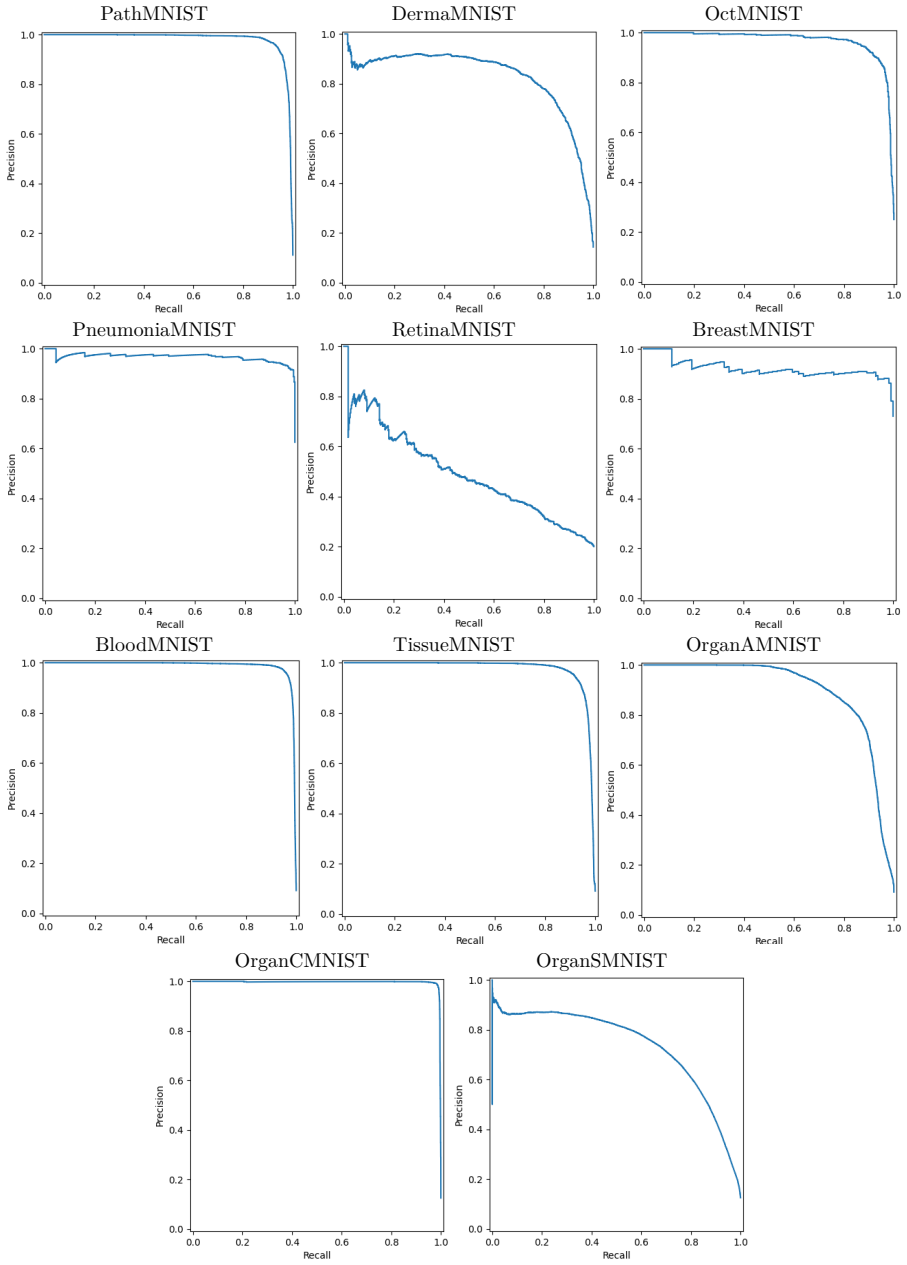
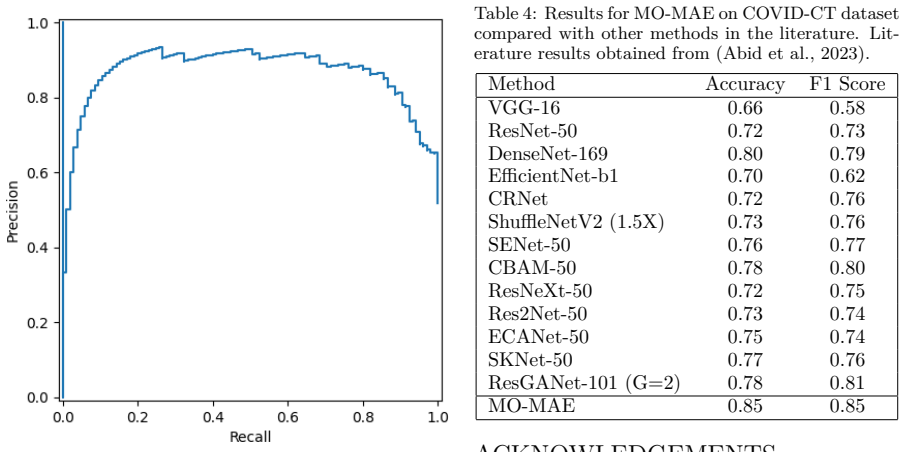
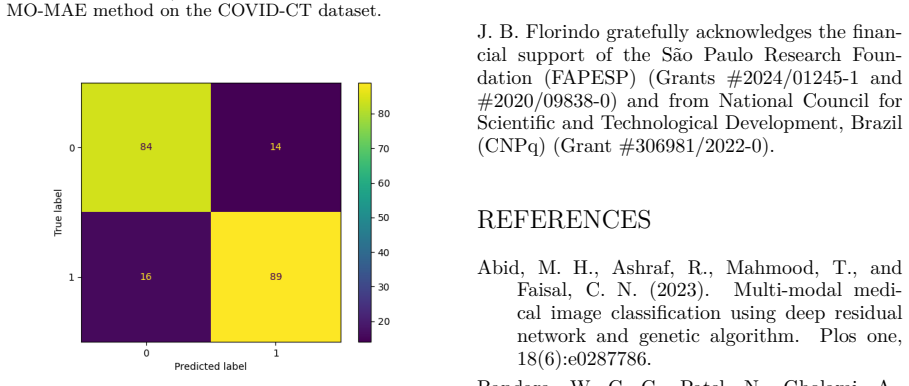
- MO-MAE achieves higher classification accuracy than random-masking baselines on MedMNIST and COVID-CT.
- The approach adds only straightforward computation for the Renyi entropy measure.
- The model captures and reconstructs complex tissue structures more effectively.
- The framework suggests a general direction for improving self-supervised medical image analysis.
- Performance gains occur without large increases in training cost.
Where Pith is reading between the lines
- The same entropy-guided masking could be tested on other structured imaging domains such as histopathology or retinal scans.
- If the high-complexity patches consistently correspond to pathology, the method might lower the volume of labeled data needed for downstream tasks.
- Combining the multifractal mask selection with transformer-based attention layers could further focus learning on diagnostic cues.
Load-bearing premise
Regions flagged as high complexity by Renyi entropy multifractal analysis match the diagnostically relevant features the model must learn to reconstruct.
What would settle it
Running the identical autoencoder architecture on the same medical datasets with random masking versus Renyi-guided masking and finding no accuracy gain, or finding that the selected high-entropy patches do not align with expert-marked lesion locations.
Figures
read the original abstract
Masked autoencoders (MAE) have shown great promise in medical image classification. However, the random masking strategy employed by traditional MAEs may overlook critical areas in medical images, where even subtle changes can indicate disease. To address this limitation, we propose a novel approach that utilizes a multifractal measure (Renyi entropy) to optimize the masking strategy. Our method, termed Multifractal-Optimized Masked Autoencoder (MO-MAE), employs a multifractal analysis to identify regions of high complexity and information content. By focusing the masking process on these areas, MO-MAE ensures that the model learns to reconstruct the most diagnostically relevant features. This approach is particularly beneficial for medical imaging, where fine-grained inspection of tissue structures is crucial for accurate diagnosis. We evaluate MO-MAE on several medical datasets covering various diseases, including MedMNIST and COVID-CT. Our results demonstrate that MO-MAE achieves promising performance, surpassing other basiline and state-of-the-art models. The proposed method also adds minimum computational overhead as the computation of the proposed measure is straightforward. Our findings suggest that the multifractal-optimized masking strategy enhances the model's ability to capture and reconstruct complex tissue structures, leading to more accurate and efficient medical image representation. The proposed MO-MAE framework offers a promising direction for improving the accuracy and efficiency of deep learning models in medical image analysis, potentially advancing the field of computer-aided diagnosis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes MO-MAE, a masked autoencoder that replaces random masking with a multifractal strategy based on Renyi entropy to identify and mask high-complexity regions in medical images. The approach is motivated by the claim that these regions contain diagnostically relevant information, so forcing reconstruction there improves learned representations. The method is evaluated on MedMNIST and COVID-CT, with the abstract asserting that MO-MAE surpasses baselines and state-of-the-art models while adding minimal computational overhead.
Significance. If the performance claims and the alignment between Renyi-entropy regions and pathology were substantiated with quantitative results and ablations, the work could offer a principled, low-overhead alternative to random masking in self-supervised medical imaging. The idea of using an information-theoretic measure to guide masking is a reasonable direction for domains where subtle local structure matters, but the current manuscript supplies no evidence that would allow assessment of whether this actually occurs.
major comments (2)
- [Abstract] Abstract: the central claim that 'MO-MAE achieves promising performance, surpassing other baseline and state-of-the-art models' is stated without any accuracy numbers, dataset sizes, error bars, statistical tests, or comparison tables. This absence directly undermines the empirical contribution.
- [Abstract and method description] Abstract and method description: the assertion that Renyi-entropy masking 'ensures that the model learns to reconstruct the most diagnostically relevant features' is presented without any supporting check (e.g., overlap with lesion annotations, expert saliency maps, or ablation against random/edge masks on MedMNIST or COVID-CT). This correspondence is load-bearing for attributing gains to the proposed strategy rather than to generic MAE training.
minor comments (2)
- [Abstract] Abstract: 'basiline' is a typo for 'baseline'.
- [Abstract] Abstract: the phrase 'adds minimum computational overhead' would benefit from a concrete runtime or FLOPs comparison rather than a qualitative statement.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for quantitative support in the abstract and evidence linking the masking strategy to diagnostic relevance. We address each major comment below and will revise the manuscript to strengthen these aspects.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'MO-MAE achieves promising performance, surpassing other baseline and state-of-the-art models' is stated without any accuracy numbers, dataset sizes, error bars, statistical tests, or comparison tables. This absence directly undermines the empirical contribution.
Authors: We agree that the abstract should be supported by quantitative results. The current abstract is qualitative; in the revised version we will incorporate specific accuracy figures, dataset sizes, and direct comparisons to baselines from the experimental section. revision: yes
-
Referee: [Abstract and method description] Abstract and method description: the assertion that Renyi-entropy masking 'ensures that the model learns to reconstruct the most diagnostically relevant features' is presented without any supporting check (e.g., overlap with lesion annotations, expert saliency maps, or ablation against random/edge masks on MedMNIST or COVID-CT). This correspondence is load-bearing for attributing gains to the proposed strategy rather than to generic MAE training.
Authors: The Renyi-entropy masking is motivated by the information-theoretic capture of high-complexity regions that frequently align with diagnostically important structures in medical images. The manuscript does not currently provide direct quantitative validation such as annotation overlap or targeted ablations. We will add an ablation comparing multifractal masking against random and edge-based alternatives on the evaluated datasets to better attribute performance gains. revision: partial
Circularity Check
No circularity; empirical method with independent performance evaluation
full rationale
The paper introduces MO-MAE as a masking strategy based on Renyi entropy multifractal analysis applied to medical images, then reports empirical classification results on MedMNIST and COVID-CT that surpass baselines. No equations, derivations, or parameter-fitting steps are described that reduce a claimed prediction to the input by construction. The design choice of masking high-entropy regions is presented as a hypothesis tested by downstream accuracy, not as a self-defining or self-cited necessity. Self-citations, if present, are not load-bearing for the central performance claim.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Renyi entropy computed on image patches identifies regions whose masking improves reconstruction of medically relevant features
Reference graph
Works this paper leans on
-
[1]
Faisal, C. N. (2023). Multi-modal medi- cal image classification using deep residual network and genetic algorithm. Plos one, 18(6):e0287786
2023
-
[2]
Nikkhah, M., Agrawal, M., and Patel, V. M. (2023). Adamae: Adaptive mask- ing for efficient spatiotemporal learning with masked autoencoders. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, pages 14507– 14517
2023
-
[3]
Ding, S., Gao, Z., Wang, J., Lu, M., and Shi, J. (2023). Fractal graph convolutional net- work with mlp-mixer based multi-path fea- ture fusion for classification of histopatho- logical images. Expert Systems with Appli- cations, 212:118793
2023
-
[4]
and Zisserman, A
Doersch, C. and Zisserman, A. (2017). Multi-task self-supervised visual learning. In Proceed- ings of the IEEE international conference on computer vision, pages 2051–2060
2017
-
[5]
Falconer, K. (2013). Fractal geometry: mathe- matical foundations and applications. John Wiley & Sons
2013
-
[6]
Florindo, J. B. (2023). Renyi entropy analysis of a deep convolutional representation for tex- ture recognition. Applied Soft Computing, 149:110974
2023
-
[7]
Florindo, J. B. and Neckel, A. (2023). A ran- domized network approach to multifractal texture descriptors. Information Sciences, 648:119544
2023
-
[8]
Girshick, R. (2022). Masked autoencoders are scalable vision learners. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16000– 16009
2022
-
[9]
Krishnan, R., Rajpurkar, P., and Topol, E. J. (2022). Self-supervised learning in medicine and healthcare. Nature Biomedical Engi- neering, 6(12):1346–1352
2022
-
[10]
Zheng, C. (2022). Semmae: Semantic-guided masking for learning masked autoencoders. Advances in Neural Information Processing Systems, 35:14290–14302
2022
-
[11]
B., and Ayatollahi, A
Shokouhi, S. B., and Ayatollahi, A. (2023). Medvit: a robust vision transformer for gen- eralized medical image classification. Com- puters in Biology and Medicine, 157:106791
2023
-
[12]
Mao, J., Guo, S., Yin, X., Chang, Y., Nie, B., and Wang, Y. (2024). Medical super- vised masked autoencoder: Crafting a bet- ter masking strategy and efficient fine-tuning schedule for medical image classification. Ap- plied Soft Computing, page 112536
2024
-
[13]
Motwani, M. B. and Fadnavis, A. M. (2024). Fractal dimension analysis at implant site on cbct. International Dental Journal, 74:S75. Rényi, A. (1961). On measures of entropy and information. In Proceedings of the fourth Berkeley symposium on mathematical statis- tics and probability, volume 1: contributions to the theory of statistics, volume 4, pages 547...
2024
-
[14]
Salat, H., Murcio, R., and Arcaute, E. (2017). Multifractal methodology. Physica A: Sta- tistical Mechanics and its Applications, 473:467–487
2017
-
[15]
Nanasato, M., Maki, H., Fujita, H., et al. (2024). Applying masked autoencoder-based self-supervised learning for high-capability vision transformers of electrocardiographies. Plos one, 19(8):e0307978
2024
-
[16]
Swapnarekha, H., Nayak, J., Naik, B., and Pelusi, D. (2024). A deep insight into intelligent fractal-based image analysis with pattern recognition. In Intelligent Fractal-Based Im- age Analysis, pages 3–32. Elsevier
2024
-
[17]
Yang, J., Shi, R., Wei, D., Liu, Z., Zhao, L., Ke, B., Pfister, H., and Ni, B. (2023). Medmnist v2-a large-scale lightweight benchmark for 2d and 3d biomedical image classification. Sci- entific Data, 10(1):41
2023
- [18]
-
[19]
Zhang, Q., Wang, Y., and Wang, Y. (2022). How mask matters: Towards theoretical under- standings of masked autoencoders. Advances in Neural Information Processing Systems, 35:27127–27139
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.