Flow-Corrected Thompson Sampling for Non-Stationary Contextual Bandits
Pith reviewed 2026-06-26 06:40 UTC · model grok-4.3
The pith
Flow-Corrected Thompson Sampling reuses past rewards in non-stationary contextual bandits by transporting them with an explicit drift model and weighting each by transport reliability, outperforming methods that discard old data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
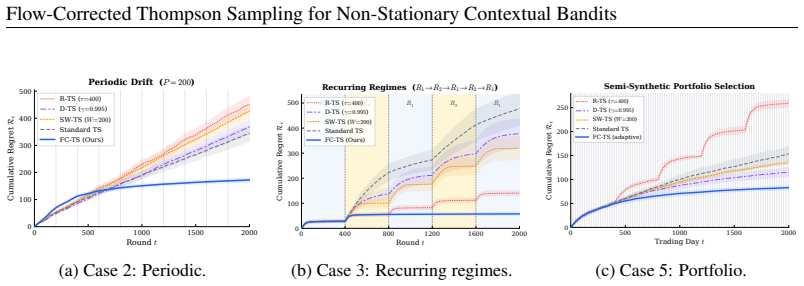
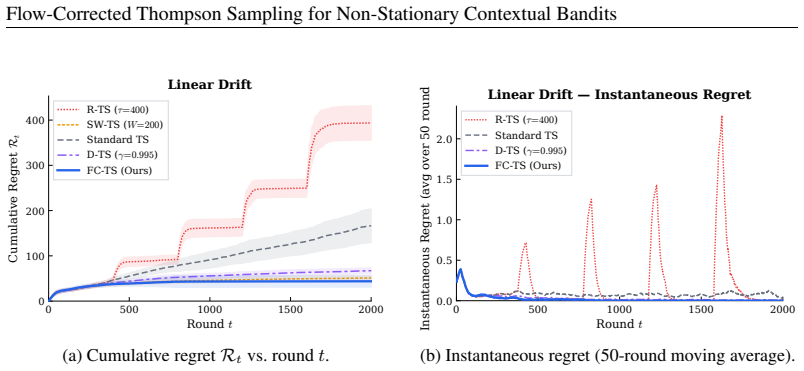
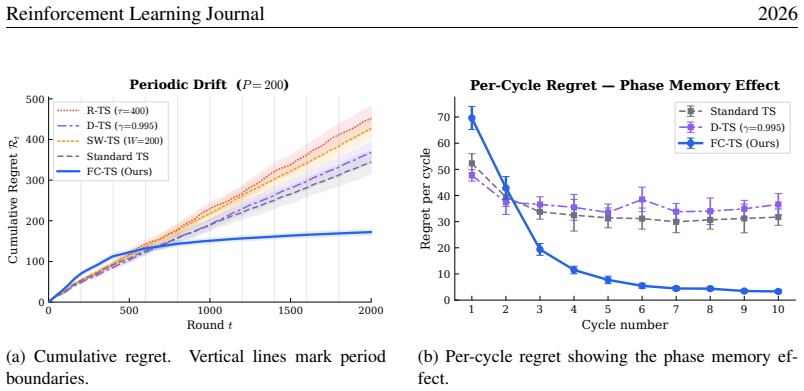
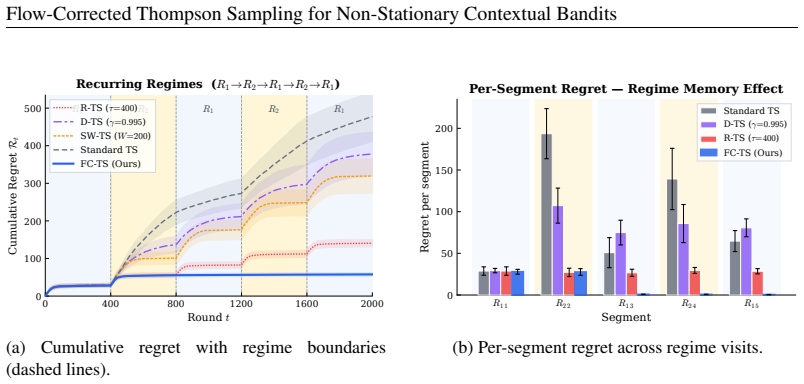
Flow-Corrected Thompson Sampling (fcTS) maintains a posterior over the current reward parameters by transporting historical rewards forward via an explicit drift model and incorporating each transported observation with a reliability weight; the resulting updates remain closed-form and yield higher cumulative reward than discounting, sliding-window, or restart baselines, with the biggest advantage in regimes that repeat.
What carries the argument
Flow correction: an explicit drift model that maps past rewards to the present time, combined with a per-observation weight that reflects transport uncertainty.
If this is right
- When the drift is linear in time, online slope estimation plus reward correction produces a usable posterior without restarting.
- When variation is periodic, phase alignment allows direct reuse of observations from previous cycles.
- When the environment switches among a finite set of regimes, changepoint detection plus regime-specific memory preserves useful history.
- Posterior updates stay closed-form and can be maintained with truncated sufficient statistics even after many corrections.
Where Pith is reading between the lines
- The same transport-and-reweight template could be applied to non-Bayesian algorithms such as LinUCB if a suitable weighting scheme is derived.
- In practice the method requires a separate module to learn or specify the drift model; the overall performance therefore depends on how well that module tracks the true non-stationarity.
- Recurring-structure gains suggest testing the approach on problems whose non-stationarity arises from external calendars or cycles rather than pure random walks.
Load-bearing premise
An explicit drift model can be estimated or specified accurately enough that the benefit of reusing corrected data exceeds any bias introduced by imperfect transport.
What would settle it
A controlled simulation in which the supplied drift model is deliberately misspecified by 20 percent; if fcTS then underperforms a simple sliding-window baseline, the central claim is falsified.
Figures
read the original abstract
We study non-stationary linear contextual bandits where the reward model drifts over time, rendering classical contextual bandit algorithms brittle because historical data becomes systematically biased. We propose Flow-Corrected Thompson Sampling (fcTS), a Bayesian method that reuses experience by transporting past rewards to the present using an explicit drift model and incorporating each transported observation with a confidence weight that reflects transport reliability. This yields a unified template that specializes in (i) linear parameter drift via online slope estimation and reward correction, (ii) periodic variation via phase-aware reuse across cycles, and (iii) recurring regime switches via changepoint detection and regime-specific posterior memory. The resulting posterior updates remain closed-form under a linear Gaussian model and can be implemented efficiently with truncated, incrementally updated sufficient statistics. Across five controlled case studies and a semi-synthetic portfolio-selection benchmark with multiple overlapping non-stationarities, fcTS outperforms standard forgetting-based baselines (discounting, sliding windows, and periodic restarts), with the largest gains in settings exhibiting recurring temporal structure. These results demonstrate that when non-stationarity is structured, correcting and reweighting historical observations can be substantially more sample-efficient than uniformly discarding them.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Flow-Corrected Thompson Sampling (fcTS), a Bayesian algorithm for non-stationary linear contextual bandits that reuses historical observations by transporting past rewards to the current time via an explicit drift model (linear slope, periodic phase, or changepoint regime) and reweighting each transported sample by a transport-reliability factor. The resulting posterior remains closed-form under linear-Gaussian assumptions and is implemented via truncated sufficient statistics. The central empirical claim is that fcTS outperforms standard forgetting baselines (discounting, sliding windows, periodic restarts) across five controlled case studies and a semi-synthetic portfolio benchmark, with the largest gains occurring when non-stationarity exhibits recurring temporal structure.
Significance. If the empirical claims and the net-bias-reduction assumption hold, the work would offer a practically useful template for structured non-stationarity that improves sample efficiency over pure forgetting. The closed-form updates and unified specialization to linear, periodic, and regime-switching cases are clear technical strengths. The absence of any reported quantitative metrics, confidence intervals, or statistical tests in the provided abstract, however, leaves the magnitude and reliability of the reported gains unassessable at present.
major comments (3)
- [Abstract] Abstract: the assertion that fcTS "outperforms standard forgetting-based baselines ... with the largest gains in settings exhibiting recurring temporal structure" supplies no numerical results, confidence intervals, statistical tests, baseline implementation details, or drift-model selection procedure, rendering the central empirical claim impossible to evaluate.
- [Abstract] Abstract (method template): the claim that transported rewards reduce effective bias more than online drift-model estimation error adds it is load-bearing for the superiority result, yet no analysis, bounds, or sensitivity experiments are referenced that would show when the online estimator (slope, phase, or changepoint) keeps net bias negative, especially under recurring structure where phase or regime errors can compound across cycles.
- [Abstract] Abstract (closed-form updates): while the linear-Gaussian posterior updates are stated to remain closed-form after transport and weighting, the manuscript provides no derivation or sufficient-statistic update rule that would allow a reader to verify that the confidence weighting exactly cancels the injected transport bias rather than merely propagating it.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract and supporting claims. We will revise the abstract to include quantitative results and add clarifying analysis and derivations to the main text and appendix as needed. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that fcTS "outperforms standard forgetting-based baselines ... with the largest gains in settings exhibiting recurring temporal structure" supplies no numerical results, confidence intervals, statistical tests, baseline implementation details, or drift-model selection procedure, rendering the central empirical claim impossible to evaluate.
Authors: We agree that the abstract should be more self-contained. In the revision we will add specific numerical results (e.g., average cumulative regret reductions with 95% confidence intervals across the five case studies and the portfolio benchmark), note the baseline implementations (discount factor grid, window sizes, restart periods), and briefly describe the drift-model selection procedure used in each experiment. revision: yes
-
Referee: [Abstract] Abstract (method template): the claim that transported rewards reduce effective bias more than online drift-model estimation error adds it is load-bearing for the superiority result, yet no analysis, bounds, or sensitivity experiments are referenced that would show when the online estimator (slope, phase, or changepoint) keeps net bias negative, especially under recurring structure where phase or regime errors can compound across cycles.
Authors: This point is well taken; the net-bias claim is central and currently supported only empirically. We will add a dedicated paragraph in Section 3 together with a short appendix deriving a simple bias bound for the linear-drift case and reporting sensitivity experiments that vary estimator error under periodic and regime-switching non-stationarity. These additions will clarify the operating regime in which net bias remains negative. revision: yes
-
Referee: [Abstract] Abstract (closed-form updates): while the linear-Gaussian posterior updates are stated to remain closed-form after transport and weighting, the manuscript provides no derivation or sufficient-statistic update rule that would allow a reader to verify that the confidence weighting exactly cancels the injected transport bias rather than merely propagating it.
Authors: The closed-form updates and truncated sufficient-statistic recursions are derived in Section 3.2 and Appendix A. To improve accessibility we will insert a compact statement of the update equations immediately after the abstract claim and add a one-page step-by-step derivation in the appendix that explicitly shows how the reliability weight modifies the posterior covariance and mean, thereby addressing the bias-cancellation question. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper defines fcTS as a method that explicitly transports past rewards via a user-specified or online-estimated drift model (linear slope, phase, or changepoint) and applies confidence-weighted updates under a linear-Gaussian assumption, yielding closed-form posterior updates via sufficient statistics. Performance claims rest on empirical comparisons across five case studies and a semi-synthetic benchmark rather than any self-referential prediction that reduces to a fitted parameter by construction. No self-citations are invoked as load-bearing uniqueness theorems, no ansatz is smuggled, and no renaming of known results occurs. The central template is presented as a modeling choice whose value is tested externally, making the derivation self-contained against the stated assumptions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Shipra Agrawal and Navin Goyal
DOI: 10.1145/3543846. Shipra Agrawal and Navin Goyal. Thompson sampling for contextual bandits with linear payoffs. In Proceedings of the 30th International Conference on Machine Learning, volume 28, pp. 127–135. PMLR,
-
[2]
URLhttps://proceedings. mlr.press/v99/auer19a.html. Ali Baheri and Cecilia O. Alm. LLMs-augmented contextual bandit.arXiv preprint arXiv:2311.02268,
-
[3]
URLhttps://arxiv.org/ abs/2311.02268
DOI: 10.48550/arXiv.2311.02268. URLhttps://arxiv.org/ abs/2311.02268. Foundation Models for Decision Making workshop, NeurIPS
-
[4]
Lilian Besson, Emilie Kaufmann, Odalric-Ambrym Maillard, and Julien Seznec
URLhttps://proceedings.neurips.cc/paper/2014/hash/ 91ba7292e5388b90b58d0b839a7f19ec-Abstract.html. Lilian Besson, Emilie Kaufmann, Odalric-Ambrym Maillard, and Julien Seznec. Efficient change- point detection for tackling piecewise-stationary bandits.Journal of Machine Learning Research, 23(77):1–40,
2014
-
[5]
DOI: 10.1109/CEC48606.2020.9185782. Yang Cao, Zheng Wen, Branislav Kveton, and Yao Xie. Nearly optimal adaptive procedure with change detection for piecewise-stationary bandit. InProceedings of the Twenty-Second Interna- tional Conference on Artificial Intelligence and Statistics, volume 89, pp. 418–427. PMLR,
-
[6]
Gabriel Peyré and Marco Cuturi
DOI: 10.1609/aaai.v32i1.11746. Gabriel Peyré and Marco Cuturi. Computational optimal transport.Foundations and Trends in Machine Learning, 11(5–6):355–607,
-
[7]
Taming Non-stationary Bandits: A Bayesian Approach
DOI: 10.1561/2200000073. Flow-Corrected Thompson Sampling for Non-Stationary Contextual Bandits Vishnu Raj and Sheetal Kalyani. Taming non-stationary bandits: A bayesian approach.arXiv preprint arXiv:1707.09727,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1561/2200000073
-
[8]
Taming Non-stationary Bandits: A Bayesian Approach
DOI: 10.48550/arXiv.1707.09727. URLhttps://arxiv. org/abs/1707.09727. Pouria Razzaghi, Amin Tabrizian, Wei Guo, Shulu Chen, Abenezer Taye, Ellis Thompson, Alexis Bregeon, Ali Baheri, and Peng Wei. A survey on reinforcement learning in aviation applications. Engineering Applications of Artificial Intelligence, 136:108911,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1707.09727
-
[9]
DOI: 10.1016/j.engappai. 2024.108911. Yoan Russac, Claire Vernade, and Olivier Cappé. Weighted linear bandits for non-stationary envi- ronments. InAdvances in Neural Information Processing Systems, volume 32,
-
[10]
DOI: 10.1093/biomet/25.3-4
-
[11]
DOI: 10.1007/978-3-540-71050-9. Reinforcement Learning Journal 2026 Supplementary Materials The following content was not necessarily subject to peer review. A Detailed Experimental Results A.1 Setup (full) We evaluate FC-TS across five case studies of increasing complexity, followed by a system- atic robustness analysis. The first three experiments use s...
-
[12]
Interestingly, STD-TS is the strongest baseline here, not SW-TS or D-TS
to ∼4 (cycle 10), while all baselines plateau around 30 to 35 per cycle. Interestingly, STD-TS is the strongest baseline here, not SW-TS or D-TS. This occurs because, under pure periodicity with no net drift, the time-averaged mean ofw (a) t equalsw (a) 0 , so STD-TS’s posterior converges (slowly) to the correct time-averaged model. In contrast, SW-TS and...
2026
-
[13]
warm start
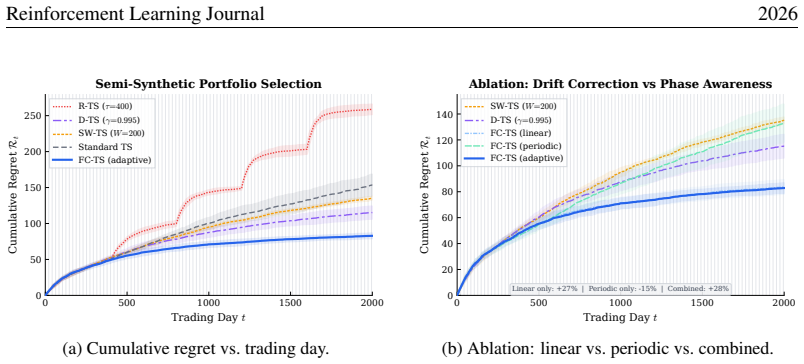
R-TS (¿=400) D-TS (°=0:995) SW-TS (W=200) Standard TS FC-TS (Ours) (a) Cumulative regret. Vertical lines mark period boundaries. 1 2 3 4 5 6 7 8 9 10 Cycle number 0 10 20 30 40 50 60 70Regret per cycle Per-Cycle Regret — Phase Memory Effect Standard TS D-TS (°=0:995) FC-TS (Ours) (b) Per-cycle regret showing the phase memory ef- fect. Figure 3:Case Study ...
2000
-
[14]
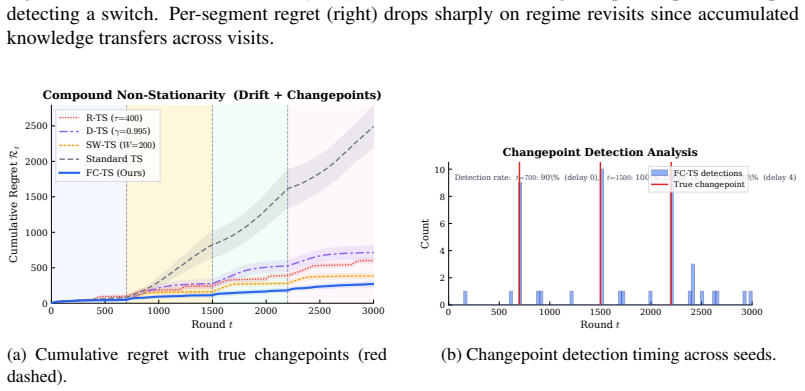
Figure 5:Case Study 4: Compound Non-Stationarity.FC-TS combines drift correction between changepoints with rapid detection and posterior reset at changepoints
Changepoint Detection Analysis FC-TS detections True changepoint (b) Changepoint detection timing across seeds. Figure 5:Case Study 4: Compound Non-Stationarity.FC-TS combines drift correction between changepoints with rapid detection and posterior reset at changepoints. Detection delay is typically 1–3 rounds. correction accounts for smooth parameter evo...
2026
-
[15]
equivalent full-weight observations
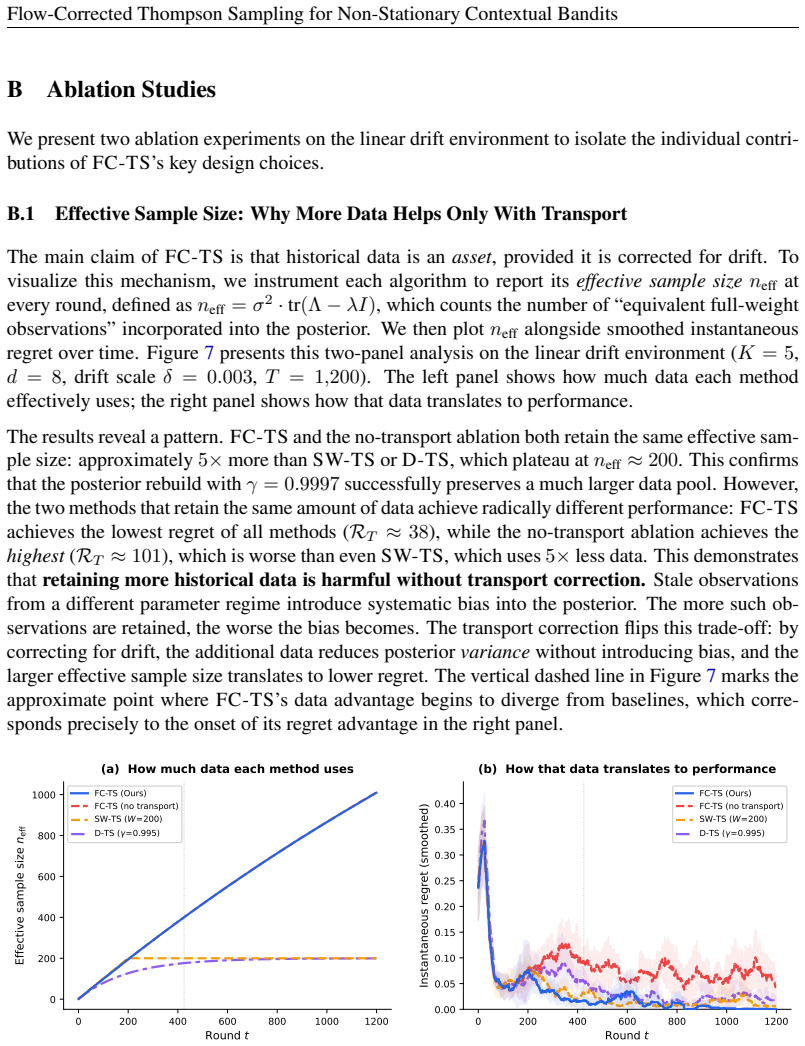
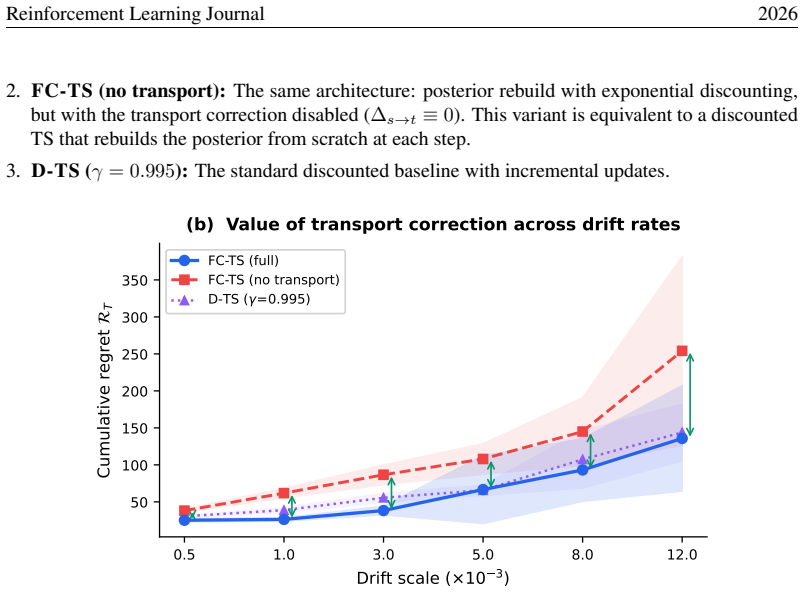
and thus contributes less to cumulative regret. Flow-Corrected Thompson Sampling for Non-Stationary Contextual Bandits B Ablation Studies We present two ablation experiments on the linear drift environment to isolate the individual contri- butions of FC-TS’s key design choices. B.1 Effective Sample Size: Why More Data Helps Only With Transport The main cl...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.