Revisiting Decentralized Online Convex Optimization with Compressed Communication
Pith reviewed 2026-07-03 18:00 UTC · model grok-4.3
The pith
FTRL-type algorithms for decentralized online convex optimization with compressed communication match or improve upon previous OGD bounds while offering simpler design and analysis.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that the dual update mechanism of follow-the-regularized-leader permits a direct and error-free application of average-consensus techniques under communication compression, yielding two algorithms whose regret bounds are at least as good as those of prior online-gradient-descent methods and strictly better in the bandit case.
What carries the argument
The dual update step of FTRL, which allows compressed average consensus to be incorporated without generating additional error terms in the regret analysis.
Load-bearing premise
The dual update mechanism of FTRL permits a simple application of compressed average consensus without introducing new error terms that would degrade the regret bounds.
What would settle it
A direct implementation on a test problem where the observed regret exceeds the claimed bound when compression is applied would falsify the claim that no new error terms arise.
Figures
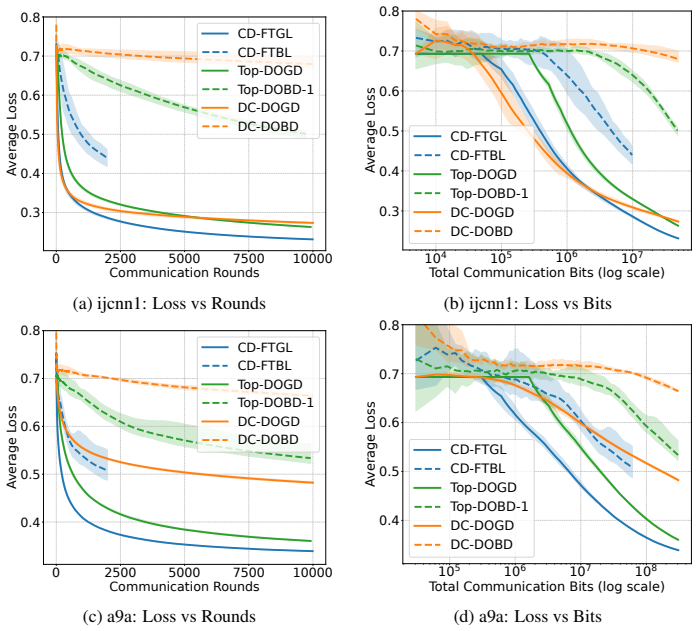
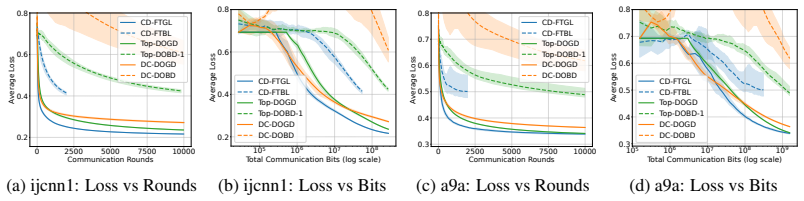
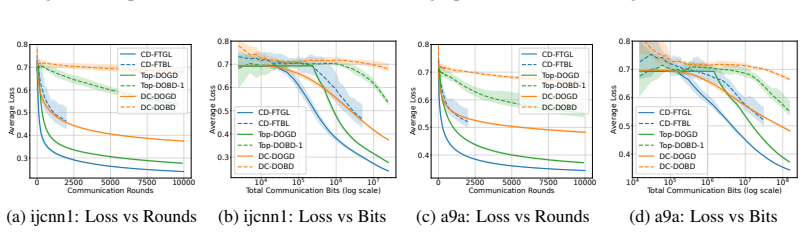
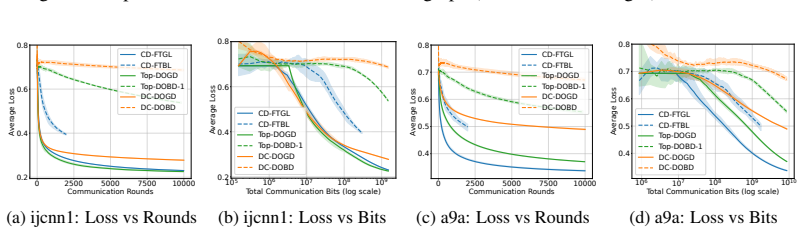
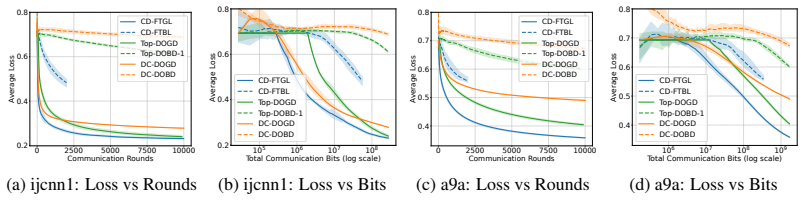
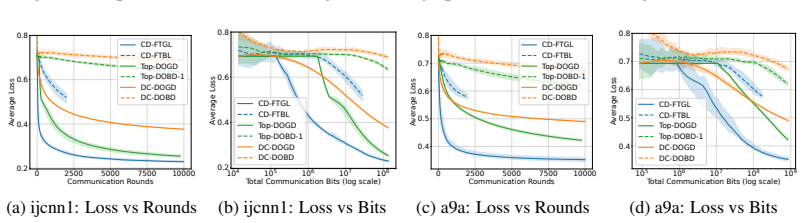
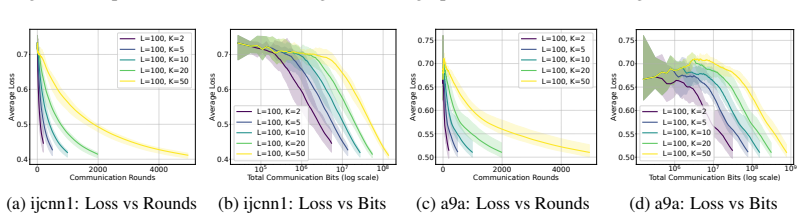
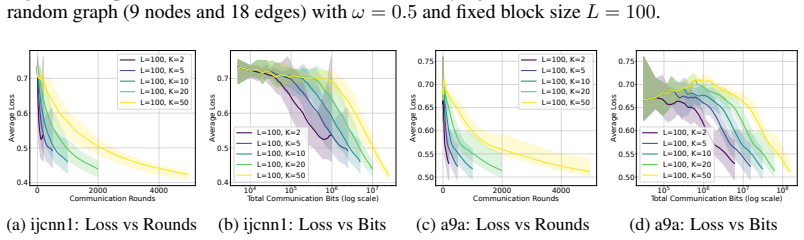
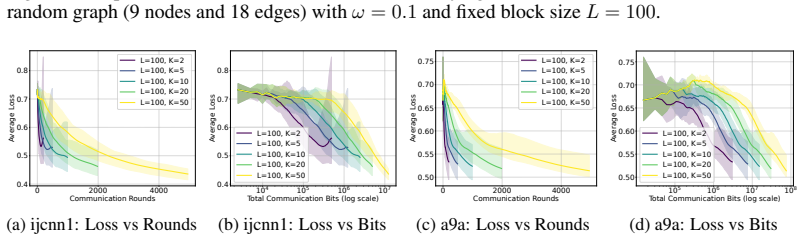
read the original abstract
Decentralized online convex optimization (D-OCO) is a popular framework for distributed applications with streaming data. To tackle the communication bottleneck, previous studies have investigated D-OCO with compressed communication and proposed several algorithms that are variants of online gradient descent (OGD). However, for D-OCO with exact communication, the best existing algorithms are variants of follow-the-regularized-leader (FTRL). In this paper, for the first time, we propose two FTRL-type algorithms for D-OCO with compressed communication. Compared with OGD-type algorithms, our algorithms are more elegant in both algorithmic design and theoretical analysis. The key insight is that the dual update mechanism of FTRL allows us to make a simple application of the technique for average consensus with communication compression. More specifically, our first algorithm considers the full-information setting, and can match the existing regret bounds. Our second algorithm is designed for the bandit setting, and can significantly improve both the regret bounds and communication costs of existing algorithms.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes two FTRL-type algorithms for decentralized online convex optimization (D-OCO) with compressed communication. The full-information algorithm is claimed to match existing regret bounds, while the bandit algorithm is claimed to significantly improve both regret bounds and communication costs compared to prior OGD-based methods. The central insight is that the dual update in FTRL permits direct use of existing compressed average-consensus techniques without introducing new error terms that degrade the regret.
Significance. If the analysis confirms that compression errors remain isolated within the consensus step and do not produce additional additive terms scaling with T or the number of nodes in the FTRL regret bound (including after substitution of the one-point estimator), the work would supply a cleaner algorithmic and analytic framework than OGD variants for this setting.
major comments (1)
- [regret analysis sections for both algorithms (dual update and error propagation)] The load-bearing claim that the FTRL dual update allows application of compressed consensus 'without introducing new error terms that degrade the regret bounds' requires explicit verification. The analysis must demonstrate that the standard quantization/sparsification error (bounded by a factor of the gradient norm or diameter) appears only inside the consensus error and does not leak into the online dual variables or produce extra summations over noise that scale with T. This must be shown separately for the full-information case and after the one-point gradient estimator is substituted in the bandit case; otherwise the 'match existing bounds' and 'significantly improve' statements do not hold.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for highlighting the need for explicit verification of error isolation in the regret analyses. We address the major comment below and are prepared to strengthen the presentation accordingly.
read point-by-point responses
-
Referee: [regret analysis sections for both algorithms (dual update and error propagation)] The load-bearing claim that the FTRL dual update allows application of compressed consensus 'without introducing new error terms that degrade the regret bounds' requires explicit verification. The analysis must demonstrate that the standard quantization/sparsification error (bounded by a factor of the gradient norm or diameter) appears only inside the consensus error and does not leak into the online dual variables or produce extra summations over noise that scale with T. This must be shown separately for the full-information case and after the one-point gradient estimator is substituted in the bandit case; otherwise the 'match existing bounds' and 'significantly improve' statements do not hold.
Authors: We agree that the isolation of compression error must be shown explicitly. In Section 4 (full-information algorithm), the proof of Theorem 4.1 proceeds by substituting the compressed consensus output directly into the FTRL dual update; the quantization error is absorbed into the standard consensus-error term (controlled by the diameter and the number of rounds) and does not appear in the online dual variables or produce an additional summation over T. The same structure is used in Section 5 for the bandit algorithm: after the one-point estimator is inserted, the proof of Theorem 5.1 again confines the compression noise inside the consensus step, yielding the stated improvement over prior OGD-based bounds without extra T-dependent terms. To address the referee’s request for clearer verification, we will add a short dedicated paragraph (or remark) immediately after each theorem statement that isolates the relevant error term and confirms it does not propagate beyond the consensus error. revision: partial
Circularity Check
No circularity; new FTRL algorithms and analysis are independently constructed
full rationale
The paper proposes novel FTRL-type algorithms for D-OCO with compressed communication, relying on the dual update mechanism to apply existing average-consensus techniques without introducing degrading error terms. No steps reduce by construction to fitted inputs, self-definitions, or load-bearing self-citations; the regret bounds are derived from standard FTRL analysis combined with consensus compression methods that are treated as external. The central claims rest on explicit algorithmic design and theoretical verification rather than renaming or re-deriving prior quantities.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Loss functions are convex
Reference graph
Works this paper leans on
-
[1]
Sparse communication for distributed gradient descent
Alham Fikri Aji and Kenneth Heafield. Sparse communication for distributed gradient descent. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pages 440--445, 2017
work page 2017
-
[2]
QSGD : Communication-efficient sgd via gradient quantization and encoding
Dan Alistarh, Demjan Grubic, Jerry Li, Ryota Tomioka, and Milan Vojnovic. QSGD : Communication-efficient sgd via gradient quantization and encoding. In Advances in neural information processing systems 30, page 1709–1720, 2017
work page 2017
-
[3]
The convergence of sparsified gradient methods
Dan Alistarh, Torsten Hoefler, Mikael Johansson, Nikola Konstantinov, Sarit Khirirat, and C \'e dric Renggli. The convergence of sparsified gradient methods. In Advances in Neural Information Processing Systems 31, pages 5977--5987, 2018
work page 2018
-
[4]
Qsparse-local- SGD : Distributed SGD with quantization, sparsification and local computations
Debraj Basu, Deepesh Data, Can Karakus, and Suhas Diggavi. Qsparse-local- SGD : Distributed SGD with quantization, sparsification and local computations. In Advances in Neural Information Processing Systems 32, pages 14695--14706, 2019
work page 2019
-
[5]
signSGD : Compressed optimisation for non-convex problems
Jeremy Bernstein, Yu-Xiang Wang, Kamyar Azizzadenesheli, and Animashree Anandkumar. signSGD : Compressed optimisation for non-convex problems. In International conference on machine learning, pages 560--569, 2018
work page 2018
-
[6]
On biased compression for distributed learning
Aleksandr Beznosikov, Samuel Horvath, Peter Richt \'a rik, and Mher Safaryan. On biased compression for distributed learning. J. Mach. Learn. Res., 24: 0 276:1--276:50, 2020
work page 2020
-
[7]
Decentralized online convex optimization with compressed communications
Xuanyu Cao and Tamer Ba s ar. Decentralized online convex optimization with compressed communications. Automatica, 156: 0 111186, 2023
work page 2023
-
[8]
LIBSVM : A library for support vector machines
Chih-Chung Chang and Chih-Jen Lin. LIBSVM : A library for support vector machines. ACM Transactions on Intelligent Systems and Technology, 2 0 (27): 0 1--27, 2011
work page 2011
-
[9]
Adaptive subgradient methods for online learning and stochastic optimization
John Duchi, Elad Hazan, and Yoram Singer. Adaptive subgradient methods for online learning and stochastic optimization. Journal of Machine Learning Research, 12: 0 2121--2159, 2011
work page 2011
-
[10]
Flaxman, Adam Tauman Kalai, and H
Abraham D. Flaxman, Adam Tauman Kalai, and H. Brendan McMahan. Online convex optimization in the bandit setting: Gradient descent without a gradient. In Proceedings of the 16th Annual ACM-SIAM Symposium on Discrete Algorithms, pages 385--394, 2005
work page 2005
-
[11]
Dan Garber and Elad Hazan. A linearly convergent conditional gradient algorithm with applications to online and stochastic optimization. SIAM Journal on Optimization, 26 0 (3): 0 1493--1528, 2016
work page 2016
-
[12]
Exploring network structure, dynamics, and function using networkx
Aric Hagberg, Pieter J Swart, and Daniel A Schult. Exploring network structure, dynamics, and function using networkx. Technical report, Los Alamos National Laboratory (LANL), Los Alamos, NM (United States), 2008
work page 2008
-
[13]
Introduction to online convex optimization
Elad Hazan. Introduction to online convex optimization. Foundations and Trends in Optimization, 2 0 (3--4): 0 157--325, 2016
work page 2016
-
[14]
Online distributed optimization via dual averaging
Saghar Hosseini, Airlie Chapman, and Mehran Mesbahi. Online distributed optimization via dual averaging. In 52nd IEEE Conference on Decision and Control, pages 1484--1489. IEEE, 2013
work page 2013
-
[15]
Anastasia Koloskova, Sebastian U. Stich, and Martin Jaggi. Decentralized stochastic optimization and gossip algorithms with compressed communication. In Proceedings of the 36th International Conference on Machine Learning, pages 3478--3487, 2019
work page 2019
-
[16]
Decentralized online learning with compressed communication for near-sensor data analytics
Guangxia Li, Jia Liu, Xiao Lu, Peilin Zhao, Yulong Shen, and Dusit Niyato. Decentralized online learning with compressed communication for near-sensor data analytics. IEEE Communications Letters, 25 0 (9): 0 2958--2962, 2021
work page 2021
-
[17]
Deep Gradient Compression : Reducing the communication bandwidth for distributed training
Yujun Lin, Song Han, Huizi Mao, Yu Wang, and Bill Dally. Deep Gradient Compression : Reducing the communication bandwidth for distributed training. In International Conference on Learning Representations, 2018
work page 2018
-
[18]
Ji Liu and A. Stephen Morse. Accelerated linear iterations for distributed averaging. Annual Reviews in Control, 35 0 (2): 0 160--165, 2011
work page 2011
-
[19]
Frank Seide, Hao Fu, Jasha Droppo, Gang Li, and Dong Yu. 1-bit stochastic gradient descent and its application to data-parallel distributed training of speech dnns. In Proceedings of the 15th Annual Conference of the International Speech Communication Association, pages 1058--1062, 2014
work page 2014
-
[20]
A primal-dual perspective of online learning algorithm
Shai Shalev-Shwartz and Yoram Singer. A primal-dual perspective of online learning algorithm. Machine Learning, 69 0 (2--3): 0 115--142, 2007
work page 2007
-
[21]
Sebastian U Stich, Jean-Baptiste Cordonnier, and Martin Jaggi. Sparsified SGD with memory. In Advances in Neural Information Processing Systems 31, pages 4452--4463, 2018
work page 2018
-
[22]
Communication compression for decentralized training
Hanlin Tang, Shaoduo Gan, Ce Zhang, Tong Zhang, and Ji Liu. Communication compression for decentralized training. Advances in Neural Information Processing Systems 31, pages 7663--7673, 2018
work page 2018
-
[23]
Distributed online convex optimization with compressed communication
Zhipeng Tu, Xi Wang, Yiguang Hong, Lei Wang, Deming Yuan, and Guodong Shi. Distributed online convex optimization with compressed communication. Advances in Neural Information Processing Systems 35, pages 34492--34504, 2022
work page 2022
-
[24]
Projection-free distributed online convex optimization with O ( T ) communication complexity
Yuanyu Wan, Wei-Wei Tu, and Lijun Zhang. Projection-free distributed online convex optimization with O ( T ) communication complexity. In Proceedings of the 37th International Conference on Machine Learning, pages 9818--9828, 2020
work page 2020
-
[25]
Projection-free distributed online learning with sublinear communication complexity
Yuanyu Wan, Guanghui Wang, Wei-Wei Tu, and Lijun Zhang. Projection-free distributed online learning with sublinear communication complexity. Journal of Machine Learning Research, 23 0 (172): 0 1--53, 2022
work page 2022
-
[26]
Nearly optimal regret for decentralized online convex optimization
Yuanyu Wan, Tong Wei, Mingli Song, and Lijun Zhang. Nearly optimal regret for decentralized online convex optimization. In Proceedings of the 37th Annual Conference on Learning Theory, pages 4862--4888, 2024
work page 2024
-
[27]
Optimal and efficient algorithms for decentralized online convex optimization
Yuanyu Wan, Tong Wei, Bo Xue, Mingli Song, and Lijun Zhang. Optimal and efficient algorithms for decentralized online convex optimization. Journal of Machine Learning Research, 26 0 (135): 0 1--43, 2025
work page 2025
-
[28]
Atomo: Communication-efficient learning via atomic sparsification
Hongyi Wang, Scott Sievert, Shengchao Liu, Zachary Charles, Dimitris Papailiopoulos, and Stephen Wright. Atomo: Communication-efficient learning via atomic sparsification. Advances in neural information processing systems 31, pages 9872--9883, 2018
work page 2018
-
[29]
Revisiting differentially private algorithms for decentralized online learning
Xiaoyu Wang, Wenhao Yang, Chang Yao, Mingli Song, and Yuanyu Wan. Revisiting differentially private algorithms for decentralized online learning. In Proceedings of the 42nd International Conference on Machine Learning (ICML), pages 65213--65235, 2025
work page 2025
-
[30]
Distributed projection-free online learning for smooth and convex losses
Yibo Wang, Yuanyu Wan, Shimao Zhang, and Lijun Zhang. Distributed projection-free online learning for smooth and convex losses. In Proceedings of the 37th AAAI Conference on Artificial Intelligence, pages 10226--10234, 2023
work page 2023
-
[31]
Gradient sparsification for communication-efficient distributed optimization
Jiawei Wangni, Jun Wang, Ji Liu, and Tong Zhang. Gradient sparsification for communication-efficient distributed optimization. In Advances in Neural Information Processing Systems, volume 31, 2018
work page 2018
-
[32]
Terngrad: Ternary gradients to reduce communication in distributed deep learning
Wei Wen, Cong Xu, Feng Yan, Chunpeng Wu, Yandan Wang, Yiran Chen, and Hai Li. Terngrad: Ternary gradients to reduce communication in distributed deep learning. Advances in neural information processing systems, 30, 2017
work page 2017
-
[33]
Dual averaging method for regularized stochastic learning and online optimization
Lin Xiao. Dual averaging method for regularized stochastic learning and online optimization. In Advances in Neural Information Processing Systems 22, pages 2116--2124, 2009
work page 2009
-
[34]
Fast linear iterations for distributed averaging
Lin Xiao and Stephen Boyd. Fast linear iterations for distributed averaging. Systems and Control Letters, 53 0 (1): 0 65--78, 2004
work page 2004
-
[35]
Feng Yan, Shreyas Sundaram, S.V.N. Vishwanathan, and Yuan Qi. Distributed autonomous online learning: Regrets and intrinsic privacy-preserving properties. IEEE Transactions on Knowledge and Data Engineering, 25 0 (11): 0 2483--2493, 2013
work page 2013
-
[36]
Sifan Yang, Wenhao Yang, Wei Jiang, and Lijun Zhang. Distributed online convex optimization with efficient communication: Improved algorithm and lower bounds. arXiv preprint arXiv:2601.04907, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[37]
Wenpeng Zhang, Peilin Zhao, Wenwu Zhu, Steven C. H. Hoi, and Tong Zhang. Projection-free distributed online learning in networks. In Proceedings of the 34th International Conference on Machine Learning, pages 4054--4062, 2017
work page 2017
-
[38]
Online convex programming and generalized infinitesimal gradient ascent
Martin Zinkevich. Online convex programming and generalized infinitesimal gradient ascent. In Proceedings of the 20th International Conference on Machine Learning, pages 928--936, 2003
work page 2003
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.