Do Vision-Language Models See Dwarf Galaxies the Way We Do?
Pith reviewed 2026-06-27 20:37 UTC · model grok-4.3
The pith
Zero-shot vision-language models reproduce aggregate human performance on ultra-faint dwarf galaxy identification but vary widely on individual cases and lack reliable uncertainty estimates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Zero-shot VLMs closely reproduce aggregate human calibration and perform well on less ambiguous cases when identifying ultra-faint dwarf galaxy candidates. However, there is significant variability at the level of individual examples, and attempts to obtain uncertainty estimates via self-reported confidence or repeated inference fail to yield reliable and practically useful measures.
What carries the argument
Comparison of zero-shot VLM classifications of multi-panel diagnostic images against human annotations collected in a citizen science campaign.
If this is right
- VLMs can serve as an initial filter that matches average human performance on dwarf galaxy candidates from survey data.
- Per-example variability requires continued human review for any final classification decisions.
- Self-reported confidence scores and repeated sampling do not supply usable uncertainty information for this task.
- Large-scale deployment in astronomical pipelines would need additional safeguards to handle inconsistent individual predictions.
Where Pith is reading between the lines
- The same evaluation protocol could be applied to other image-based astronomical tasks such as transient detection or morphological classification.
- Fine-tuning the models on a modest set of labeled astronomical images might reduce the observed per-example scatter.
- Combining VLM outputs with traditional computer-vision pipelines could compensate for the missing uncertainty calibration.
- If the aggregate match holds on future surveys, citizen-science campaigns could be scaled down while preserving overall discovery rates.
Load-bearing premise
Human annotations collected through the citizen science campaign constitute a reliable and unbiased ground truth against which model performance can be meaningfully evaluated.
What would settle it
A fresh set of multi-panel images where independent human annotators disagree with the VLM outputs at rates far higher than the aggregate match reported in the study.
Figures
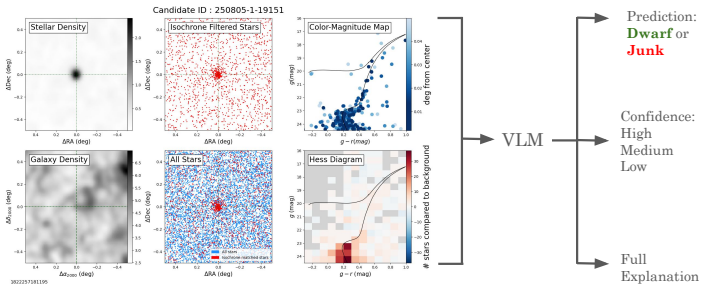
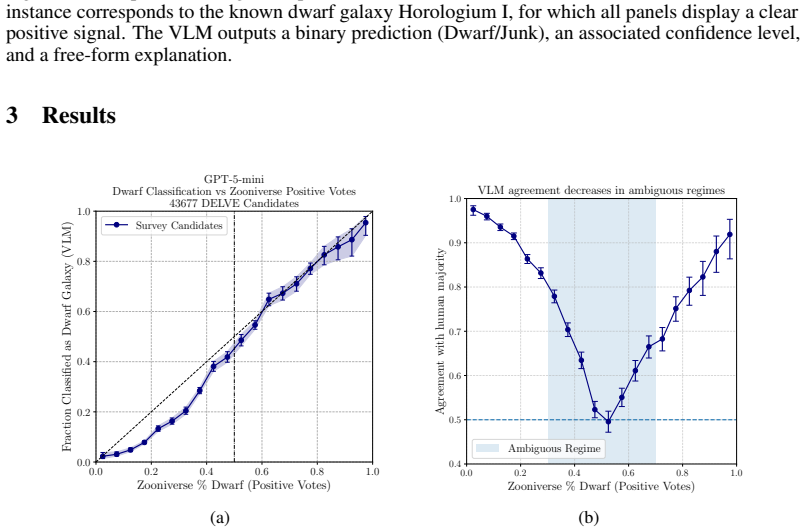
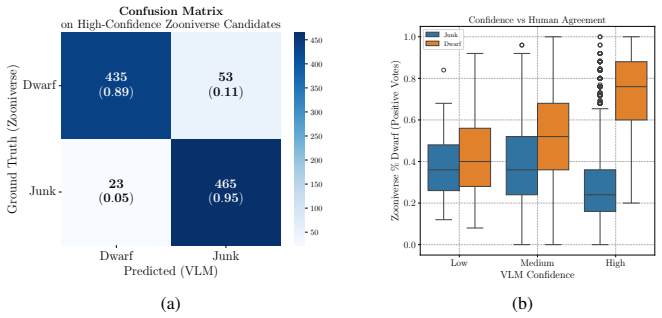
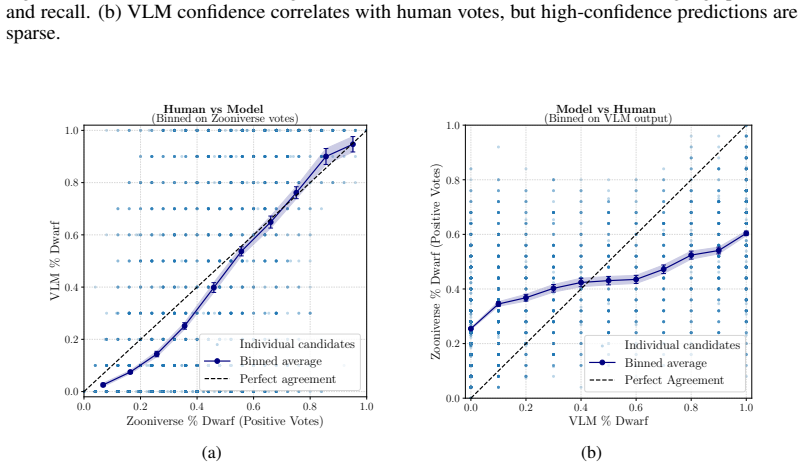
read the original abstract
With the advent of powerful, general-purpose vision-language models (VLMs), there has been growing interest in their potential to assist astronomical discovery, a field characterized by large volumes of image data. In this work, we evaluate VLMs on the challenging task of identifying ultra-faint dwarf galaxy candidates using multi-panel diagnostic images from survey data. We compare model predictions to human annotations from a large-scale citizen science campaign. We find that zero-shot VLMs closely reproduce aggregate human calibration and perform well on less ambiguous cases. However, there is significant variability at the level of individual examples, and attempts to obtain uncertainty estimates (via self-reported confidence or repeated inference) fail to yield reliable and practically useful measures. Our results highlight both the promise and the current limitations of deploying VLMs for large-scale scientific discovery in realistic settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript evaluates zero-shot vision-language models (VLMs) on the task of identifying ultra-faint dwarf galaxy candidates from multi-panel diagnostic images drawn from survey data. Model outputs are compared against human annotations collected through a large-scale citizen science campaign. The central findings are that zero-shot VLMs closely reproduce aggregate human calibration and perform well on less ambiguous cases, while exhibiting substantial per-example variability; additionally, self-reported confidence scores and repeated inference do not produce reliable or practically useful uncertainty estimates.
Significance. If the empirical comparison holds after proper validation of the reference labels, the work provides a realistic benchmark for the use of general-purpose VLMs in astronomical discovery pipelines involving low-surface-brightness, high-ambiguity objects. It explicitly identifies both the promise of aggregate-level alignment and the current shortcomings in uncertainty quantification, which could guide future integration of VLMs into citizen-science or survey-analysis workflows.
major comments (2)
- [Abstract / Methods] The evaluation treats the citizen-science annotations as ground truth for assessing whether VLMs 'see dwarf galaxies the way we do,' yet the manuscript reports neither inter-annotator agreement statistics nor an expert-validated subset. Given that ultra-faint dwarf candidates are defined by low surface brightness and high visual ambiguity, the absence of these metrics leaves open the possibility that reported aggregate agreement simply reflects shared difficulty with noisy labels rather than genuine calibration alignment.
- [Abstract] The abstract states high-level performance claims but supplies no information on dataset size, image selection criteria, statistical tests used to quantify 'close reproduction' of aggregate calibration, or error analysis. Without these details it is impossible to assess whether the reported differences between VLMs and humans, or between ambiguous and less-ambiguous cases, are statistically supported.
minor comments (1)
- Clarify the exact prompting strategy and image-panel formatting supplied to the VLMs; small changes in prompt wording or panel ordering can affect zero-shot performance on ambiguous astronomical images.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We agree that additional validation metrics and more specific details in the abstract would strengthen the manuscript. We address each major comment below and will incorporate revisions accordingly.
read point-by-point responses
-
Referee: [Abstract / Methods] The evaluation treats the citizen-science annotations as ground truth for assessing whether VLMs 'see dwarf galaxies the way we do,' yet the manuscript reports neither inter-annotator agreement statistics nor an expert-validated subset. Given that ultra-faint dwarf candidates are defined by low surface brightness and high visual ambiguity, the absence of these metrics leaves open the possibility that reported aggregate agreement simply reflects shared difficulty with noisy labels rather than genuine calibration alignment.
Authors: We agree this is a valid concern and that inter-annotator agreement metrics would help distinguish genuine alignment from shared label noise. The citizen-science campaign collected multiple annotations per image to form aggregate labels, but the current manuscript does not report agreement statistics such as Fleiss' kappa. In revision we will add these metrics in the Methods section, along with a discussion of how they relate to the observed VLM-human agreement. We will also reference prior expert calibration of the campaign and, if feasible, include results on a small expert-validated subset. This directly addresses the possibility that aggregate agreement reflects ambiguity rather than calibration. revision: yes
-
Referee: [Abstract] The abstract states high-level performance claims but supplies no information on dataset size, image selection criteria, statistical tests used to quantify 'close reproduction' of aggregate calibration, or error analysis. Without these details it is impossible to assess whether the reported differences between VLMs and humans, or between ambiguous and less-ambiguous cases, are statistically supported.
Authors: We acknowledge that the abstract is concise and omits key quantitative details. In the revised version we will expand the abstract to report the dataset size (number of multi-panel images and candidates), the image selection criteria from the survey data, the specific statistical measures used to quantify aggregate calibration (e.g., correlation or agreement metrics), and a brief note on the per-example variability and error analysis already performed. These additions will make the statistical support for the claims explicit while remaining within abstract length constraints. revision: yes
Circularity Check
No circularity: direct empirical comparison to external annotations
full rationale
The paper reports an empirical evaluation of zero-shot VLMs against human labels collected via citizen science. No derivations, equations, fitted parameters, or self-citation chains are invoked to produce the central claims. The reported agreement (aggregate calibration) and variability are direct observations relative to the external benchmark, satisfying the self-contained-against-external-benchmarks criterion. Issues of label noise or inter-annotator agreement belong to correctness risk, not circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
On the Opportunities and Risks of Foundation Models
Rishi Bommasani, Drew A. Hudson, Ehsan Adeli, Russ Altman, Simran Arora, Sydney von Arx, Michael S. Bernstein, Jeannette Bohg, Antoine Bosselut, Emma Brunskill, Erik Brynjolfsson, Shyamal Buch, Dallas Card, Rodrigo Castellon, Niladri Chatterji, Annie Chen, Kathleen Creel, Jared Quincy Davis, Dora Demszky, Chris Donahue, Moussa Doumbouya, Esin Durmus, Stef...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2108.07258 2021
-
[2]
Florian Bordes, Richard Yuanzhe Pang, Anurag Ajay, Alexander C. Li, Adrien Bardes, Suzanne Petryk, Oscar Mañas, Zhiqiu Lin, Anas Mahmoud, Bargav Jayaraman, Mark Ibrahim, Melissa Hall, Yunyang Xiong, Jonathan Lebensold, Candace Ross, Srihari Jayakumar, Chuan Guo, Diane Bouchacourt, Haider Al- Tahan, Karthik Padthe, Vasu Sharma, Hu Xu, Xiaoqing Ellen Tan, M...
-
[3]
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-V oss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwi...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv 2005
-
[4]
Bullock and Michael Boylan-Kolchin
James S. Bullock and Michael Boylan-Kolchin. Small-Scale Challenges to the ΛCDM Paradigm. Annual Review of Astronomy and Astrophysics, 55(1):343–387, August 2017. doi: 10.1146/ annurev-astro-091916-055313
2017
-
[5]
Claire Chen, Jiabao Sean Xiao, Shuze Daniel Liu, Facundo Perez Paolino, Luke Handley, Theophile Jegou du Laz, Ricky Nilsson, Alice Zou, Matthew Graham, and Ashish Mahabal. AstroAlertBench: Evaluating the Accuracy, Reasoning, and Honesty of Multimodal LLMs in Astronomical Classification.arXiv e-prints, art. arXiv:2605.05573, May 2026. doi: 10.48550/arXiv.2...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2605.05573 2026
-
[6]
Vision-Language Model Ensembles Achieve Human-Expert Accuracy for Galaxy Merger Classification
Marco Chiaberge, Elias Stengel-Eskin, Massimo Stiavelli, and Colin Norman. Vision-Language Model Ensembles Achieve Human-Expert Accuracy for Galaxy Merger Classification.arXiv e-prints, art. arXiv:2606.00415, May 2026. doi: 10.48550/arXiv.2606.00415
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2606.00415 2026
-
[7]
Rethinking VLMs and LLMs for Image Classification.arXiv e-prints, art
Avi Cooper, Keizo Kato, Chia-Hsien Shih, Hiroaki Yamane, Kasper Vinken, Kentaro Takemoto, Taro Sunagawa, Hao-Wei Yeh, Jin Yamanaka, Ian Mason, and Xavier Boix. Rethinking VLMs and LLMs for Image Classification.arXiv e-prints, art. arXiv:2410.14690, October 2024. doi: 10.48550/arXiv.2410. 14690
-
[8]
A. Drlica-Wagner, J. L. Carlin, D. L. Nidever, P. S. Ferguson, N. Kuropatkin, M. Adamów, W. Cerny, Y . Choi, J. H. Esteves, C. E. Martínez-Vázquez, S. Mau, A. E. Miller, B. Mutlu-Pakdil, E. H. Neilsen, K. A. G. Olsen, A. B. Pace, A. H. Riley, J. D. Sakowska, D. J. Sand, L. Santana-Silva, E. J. Tollerud, D. L. Tucker, A. K. Vivas, E. Zaborowski, A. Zenteno...
-
[9]
Mariia Drozdova, Erica Lastufka, Vitaliy Kinakh, Taras Holotyak, Daniel Schaerer, and Slava V oloshynovskiy. Radio Astronomy in the Era of Vision-Language Models: Prompt Sensitivity and Adaptation.arXiv e-prints, art. arXiv:2509.02615, August 2025. doi: 10.48550/arXiv.2509.02615
-
[10]
Željko Ivezi ´c, Steven M. Kahn, J. Anthony Tyson, Bob Abel, Emily Acosta, Robyn Allsman, David Alonso, Yusra AlSayyad, Scott F. Anderson, John Andrew, James Roger P. Angel, George Z. Angeli, Reza Ansari, Pierre Antilogus, Constanza Araujo, Robert Armstrong, Kirk T. Arndt, Pierre Astier, Éric Aubourg, Nicole Auza, Tim S. Axelrod, Deborah J. Bard, Jeff D. ...
-
[11]
Real-World Robot Applications of Foundation Models: A Review.arXiv e-prints, art
Kento Kawaharazuka, Tatsuya Matsushima, Andrew Gambardella, Jiaxian Guo, Chris Paxton, and Andy Zeng. Real-World Robot Applications of Foundation Models: A Review.arXiv e-prints, art. arXiv:2402.05741, February 2024. doi: 10.48550/arXiv.2402.05741. 6
-
[12]
Semantic search for 100M+ galaxy images using AI-generated captions
Nolan Koblischke, Liam Parker, Francois Lanusse, Irina Espejo Morales, Jo Bovy, and Shirley Ho. Seman- tic search for 100M+ galaxy images using AI-generated captions.arXiv e-prints, art. arXiv:2512.11982, December 2025. doi: 10.48550/arXiv.2512.11982
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2512.11982 2025
-
[13]
Zongxia Li, Xiyang Wu, Hongyang Du, Fuxiao Liu, Huy Nghiem, and Guangyao Shi. A Survey of State of the Art Large Vision Language Models: Alignment, Benchmark, Evaluations and Challenges.arXiv e-prints, art. arXiv:2501.02189, January 2025. doi: 10.48550/arXiv.2501.02189
-
[14]
Siddharth Mishra-Sharma, Yiding Song, and Jesse Thaler. PAPERCLIP: Associating Astronomical Observations and Natural Language with Multi-Modal Models.arXiv e-prints, art. arXiv:2403.08851, March 2024. doi: 10.48550/arXiv.2403.08851
-
[15]
E. O. Nadler, A. Drlica-Wagner, K. Bechtol, S. Mau, R. H. Wechsler, V . Gluscevic, K. Boddy, A. B. Pace, T. S. Li, M. McNanna, A. H. Riley, J. García-Bellido, Y .-Y . Mao, G. Green, D. L. Burke, A. Peter, B. Jain, T. M. C. Abbott, M. Aguena, S. Allam, J. Annis, S. Avila, D. Brooks, M. Carrasco Kind, J. Carretero, M. Costanzi, L. N. da Costa, J. De Vicente...
-
[16]
A systematic evaluation of vision-language models for observational astronomical reasoning tasks
Wenke Ren, Hengxiao Guo, Wenwen Zuo, and Xiaoman Zhang. A systematic evaluation of vision-language models for observational astronomical reasoning tasks.arXiv e-prints, art. arXiv:2604.24589, April 2026. doi: 10.48550/arXiv.2604.24589
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.24589 2026
-
[17]
Simone Riggi, Thomas Cecconello, Andrea Pilzer, Simone Palazzo, Nikhel Gupta, Andrew Hopkins, Corrado Trigilio, and Grazia Umana. radio-llava: Advancing vision-language models for radio astronomical source analysis.Publications of the Astronomical Society of Australia, 42:e121, August 2025. doi: 10.1017/pasa.2025.10082
-
[18]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, Akshay Nathan, Alan Luo, Alec Helyar, Aleksander Madry, Aleksandr Efremov, Aleksandra Spyra, Alex Baker-Whitcomb, Alex Beutel, Alex Karpenko, Alex Makelov, Alex Neitz, Alex Wei, Alexandra Barr, Alexandre Kirchmeyer, Ale...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2601.03267 2025
-
[19]
Fiorenzo Stoppa, Turan Bulmus, Steven Bloemen, Stephen J. Smartt, Paul J. Groot, Paul Vreeswijk, and Ken W. Smith. Textual interpretation of transient image classifications from large language models.Nature Astronomy, 9:1869–1878, December 2025. doi: 10.1038/s41550-025-02670-z
-
[20]
C. Y . Tan, A. Drlica-Wagner, A. B. Pace, W. Cerny, E. O. Nadler, A. Doliva-Dolinsky, D. Anbajagane, T. S. Li, J. D. Simon, A. K. Vivas, A. R. Walker, M. Adamów, K. Bechtol, J. L. Carlin, Q. O. Casey, C. Chang, A. Chaturvedi, T.-Y . Cheng, A. Chiti, Y . Choi, D. Crnojevi´c, P. S. Ferguson, R. A. Gruendl, A. P. Ji, G. Limberg, G. E. Medina, B. Mutlu-Pakdil...
-
[21]
At First Sight! Zero-shot Classification of Astronomical Images with Large Multimodal Models.Research Notes of the American Astronomical Society, 8(10):265, October
Dimitrios Tanoglidis and Bhuvnesh Jain. At First Sight! Zero-shot Classification of Astronomical Images with Large Multimodal Models.Research Notes of the American Astronomical Society, 8(10):265, October
-
[22]
doi: 10.3847/2515-5172/ad887a
-
[23]
The Dawn of LMMs: Preliminary Explorations with GPT-4V(ision)
Zhengyuan Yang, Linjie Li, Kevin Lin, Jianfeng Wang, Chung-Ching Lin, Zicheng Liu, and Lijuan Wang. The Dawn of LMMs: Preliminary Explorations with GPT-4V(ision).arXiv e-prints, art. arXiv:2309.17421, September 2023. doi: 10.48550/arXiv.2309.17421
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2309.17421 2023
-
[24]
MMMU: A Massive Multi-discipline Multimodal Understanding and Reasoning Benchmark for Expert AGI
Xiang Yue, Yuansheng Ni, Kai Zhang, Tianyu Zheng, Ruoqi Liu, Ge Zhang, Samuel Stevens, Dongfu Jiang, Weiming Ren, Yuxuan Sun, Cong Wei, Botao Yu, Ruibin Yuan, Renliang Sun, Ming Yin, Boyuan Zheng, Zhenzhu Yang, Yibo Liu, Wenhao Huang, Huan Sun, Yu Su, and Wenhu Chen. MMMU: A Massive Multi-discipline Multimodal Understanding and Reasoning Benchmark for Exp...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2311.16502 2023
-
[25]
Sharaf Zaman, Michael J. Smith, Pranav Khetarpal, Rishabh Chakrabarty, Michele Ginolfi, Marc Huertas- Company, Maja Jabło´nska, Sandor Kruk, Matthieu Le Lain, Sergio José Rodríguez Méndez, and Dimitrios Tanoglidis. AstroLLaV A: towards the unification of astronomical data and natural language.arXiv e-prints, art. arXiv:2504.08583, April 2025. doi: 10.4855...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.