PRISM: Prosody-Integrated Multi-Agent Reasoning Framework for Empathetic Spoken Dialogue
Pith reviewed 2026-06-27 06:51 UTC · model grok-4.3
The pith
PRISM decouples speech perception, response generation and synthesis into agents plus a prosody-to-language step to raise empathy and prosodic fit in spoken dialogue.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
PRISM decouples speech perception, response generation, and speech synthesis into coordinated components, introduces a prosody-to-language translation mechanism to stabilize large language model reasoning, and enables on-demand invocation of external knowledge tools, yielding consistent improvements in empathy, prosodic appropriateness, and text response generation quality across objective and subjective metrics.
What carries the argument
The prosody-to-language translation mechanism that converts acoustic cues into textual descriptions inside the multi-agent coordination loop.
If this is right
- Higher empathy scores on both automatic and human evaluations.
- More appropriate prosody in the final spoken output.
- Improved quality of the generated text responses.
- More stable emotional reasoning by the language model component.
- On-demand use of external knowledge improves reply relevance.
Where Pith is reading between the lines
- The modular split could make it easier to swap in new tools or update one stage without retraining everything.
- Similar translation steps might help other tasks where non-text signals need to reach a language model.
- The design might reduce training cost compared with large end-to-end speech models by reusing existing components.
Load-bearing premise
Dividing the system into separate agents for perception, generation and synthesis plus translating prosody into language will reliably stabilize reasoning and produce net gains without new coordination failures or error sources.
What would settle it
A controlled comparison in which a single integrated model or a standard cascade pipeline without the translation step matches or exceeds PRISM on all empathy, prosody and response-quality metrics.
Figures

read the original abstract
Empathetic spoken dialogue systems require not only semantically appropriate responses but also emotionally aligned prosodic expression. However, cascade pipelines often discard acoustic cues during speech-to-text conversion, while end-to-end speech models lack interpretable control over emotion and knowledge integration. To address these challenges, we propose PRISM, a multi-agent framework for empathetic spoken dialogue that decouples speech perception, response generation, and speech synthesis into coordinated components. PRISM introduces a prosody-to-language translation mechanism to stabilize large language model reasoning and enables on-demand invocation of external knowledge tools for empathetic dialogue generation. Experimental results demonstrate that PRISM achieves consistent improvements in empathy, prosodic appropriateness, and text response generation quality across objective and subjective metrics. Our code is available at: https://github.com/Bxzfrm/PRISM.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes PRISM, a multi-agent framework for empathetic spoken dialogue that decouples speech perception, response generation, and speech synthesis into coordinated agents. It introduces a prosody-to-language translation mechanism to stabilize LLM reasoning and supports on-demand invocation of external knowledge tools. The authors report that PRISM achieves consistent improvements in empathy, prosodic appropriateness, and text response generation quality across objective and subjective metrics, with code released at a public GitHub repository.
Significance. If the experimental claims hold under rigorous validation, the work could contribute to the field by offering an interpretable multi-agent alternative to cascade and end-to-end spoken dialogue systems, particularly through explicit prosody integration and knowledge tool use. The open code release is a positive factor for reproducibility.
major comments (1)
- [Abstract] Abstract: the central claim that PRISM 'achieves consistent improvements' across metrics is stated without any description of experimental design, baselines, metric definitions, statistical tests, datasets, or ablation studies. This absence makes the data-to-claim link impossible to evaluate and is load-bearing for the paper's primary assertion.
Simulated Author's Rebuttal
We thank the referee for their review and the opportunity to respond. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that PRISM 'achieves consistent improvements' across metrics is stated without any description of experimental design, baselines, metric definitions, statistical tests, datasets, or ablation studies. This absence makes the data-to-claim link impossible to evaluate and is load-bearing for the paper's primary assertion.
Authors: The abstract is intentionally concise to summarize the core contribution and key findings within standard length constraints. The experimental design (including datasets, baselines such as cascade and end-to-end spoken dialogue systems, metric definitions for empathy and prosodic fit, statistical significance testing, and ablation studies) is fully detailed in Sections 4 (Experimental Setup) and 5 (Results and Analysis) of the manuscript, with all claims directly supported by those sections. This follows conventional academic structure where abstracts state outcomes and the body provides the rigorous link between data and claims. We are willing to add a single sentence to the abstract briefly referencing the evaluation protocol if the editor deems it necessary for clarity. revision: partial
Circularity Check
No significant circularity detected
full rationale
The manuscript describes an architectural framework (multi-agent decoupling of perception/generation/synthesis plus a prosody-to-language translation step) and reports empirical improvements on objective/subjective metrics. No equations, derivations, fitted parameters, or self-citation chains appear in the provided text. All central claims are framed as experimental outcomes rather than quantities defined from the inputs by construction. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
ASR-text dialogue model-TTS
Introduction In recent years, advances in large language models (LLMs) and speech technologies have driven human-machine dialogue sys- tems from text-based interaction toward more natural spoken interaction. Compared with text dialogue, spoken dialogue con- veys not only linguistic content but also prosodic and emotional cues [1, 2]. These paralinguistic ...
-
[2]
The speaker spoke quickly with an angry tone
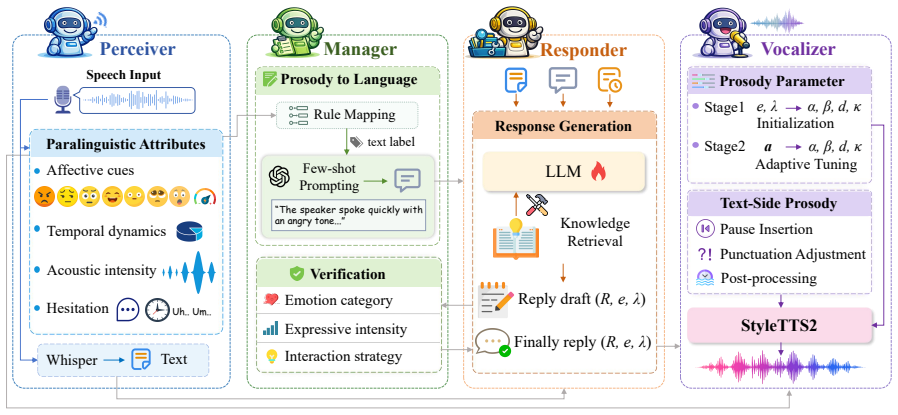
Method We propose a prosody-aware multi-agent empathetic spoken di- alogue framework consisting of four components: Perceiver, Manager, Responder, and V ocalizer, as illustrated in Figure 1. arXiv:2606.12902v1 [cs.CL] 11 Jun 2026 VocalizerPerceiver Manager Responder Emotion category Verification Expressive intensity Interaction strategy Speech Input Whisp...
Pith/arXiv arXiv 2026
-
[3]
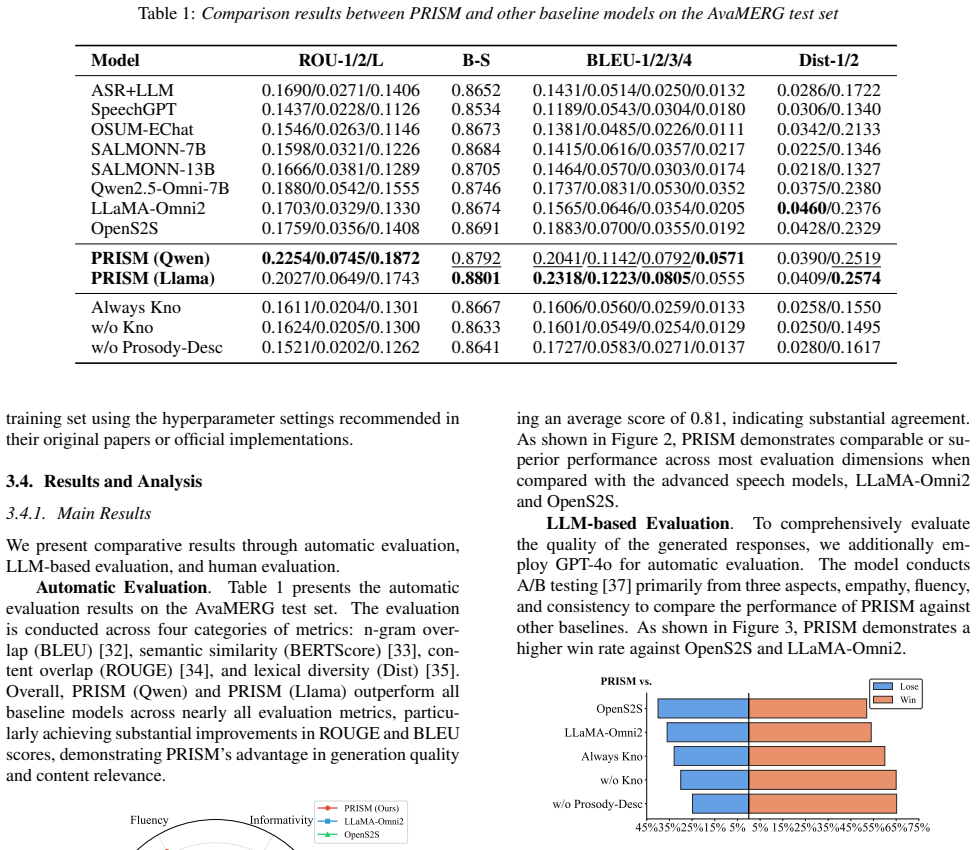
Experiments 3.1. Dataset TOOL-ED[20] is a tool-augmented extension of the ED [21] dataset, designed to study empathetic dialogue generation with external knowledge integration. Each sample consists of a short dialogue context and its corresponding empathetic response, along with annotations indicating whether external knowledge should be invoked.AvaMERG[2...
arXiv 2041
-
[4]
Conclusion We present PRISM, a multi-agent framework for empathetic spoken dialogue that integrates prosody-to-language translation and adaptive knowledge invocation. By decoupling perception, reasoning, and synthesis, PRISM enables interpretable emo- tion modeling and controllable speech generation, achieving improved empathy and prosodic alignment over ...
-
[5]
62272092, 62172086), and the Fun- damental Research Funds for the Central Universities under Grants (N25XQD004)
Acknowledgments The work was supported by the National Natural Science Foun- dation of China (Nos. 62272092, 62172086), and the Fun- damental Research Funds for the Central Universities under Grants (N25XQD004). Thanks to the KinaMind society for their inspiring environment and unwavering support
-
[6]
All technical contributions, experimental de- sign, and analyses were conducted by the authors
Generative AI Use Disclosure Generative AI tools were used only for proofreading and lan- guage polishing. All technical contributions, experimental de- sign, and analyses were conducted by the authors
-
[7]
The geneva minimalistic acoustic parameter set (gemaps) for voice research and affective computing,
F. Eyben, K. R. Scherer, B. W. Schuller, J. Sundberg, E. Andr ´e, C. Busso, L. Y . Devillers, J. Epps, P. Laukka, S. S. Narayanan et al., “The geneva minimalistic acoustic parameter set (gemaps) for voice research and affective computing,”IEEE transactions on affective computing, vol. 7, no. 2, pp. 190–202, 2015
2015
-
[8]
The role of prosody in spoken question answering,
J. Chi, M. de Seyssel, and N. Schluter, “The role of prosody in spoken question answering,” inFindings of the Association for Computational Linguistics: NAACL 2025, 2025, pp. 8468–8479
2025
-
[9]
Emotional chatting machine: emotional conversation generation with inter- nal and external memory,
H. Zhou, M. Huang, T. Zhang, X. Zhu, and B. Liu, “Emotional chatting machine: emotional conversation generation with inter- nal and external memory,” inProceedings of the Thirty-Second AAAI Conference on Artificial Intelligence and Thirtieth Innova- tive Applications of Artificial Intelligence Conference and Eighth AAAI Symposium on Educational Advances i...
2018
-
[10]
Speech emotion recognition: two decades in a nutshell, benchmarks, and ongoing trends,
B. W. Schuller, “Speech emotion recognition: two decades in a nutshell, benchmarks, and ongoing trends,”Commun. ACM, vol. 61, no. 5, p. 90–99, Apr. 2018. [Online]. Available: https://doi.org/10.1145/3129340
-
[11]
AnnaAgent: Dynamic evolution agent system with multi-session memory f or realistic seeker simulation,
M. Wang, P. Wang, L. Wu, X. Yang, D. Wang, S. Feng, Y . Chen, B. Wang, and Y . Zhang, “AnnaAgent: Dynamic evolution agent system with multi-session memory f or realistic seeker simulation,” inFindings of the Association for Computational Linguistics: ACL 2025, W. Che, J. Nabende, E. Shutova, and M. T. Pilehvar, Eds. Vienna, Austria: Association for Comput...
2025
-
[12]
Audiogpt: Understanding and generating speech, music, sound, and talking head,
R. Huang, M. Li, D. Yang, J. Shi, X. Chang, Z. Ye, Y . Wu, Z. Hong, J. Huang, J. Liuet al., “Audiogpt: Understanding and generating speech, music, sound, and talking head,” inProceed- ings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 21, 2024, pp. 23 802–23 804
2024
-
[13]
Towards end-to-end spoken language understanding,
D. Serdyuk, Y . Wang, C. Fuegen, A. Kumar, B. Liu, and Y . Ben- gio, “Towards end-to-end spoken language understanding,” in 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2018, pp. 5754–5758
2018
-
[14]
Wavchat: A survey of spoken dialogue models,
S. Ji, Y . Chen, M. Fang, J. Zuo, J. Lu, H. Wang, Z. Jiang, L. Zhou, S. Liu, X. Chenget al., “Wavchat: A survey of spoken dialogue models,”arXiv preprint arXiv:2411.13577, 2024
arXiv 2024
-
[15]
F. Eyben, M. W ¨ollmer, and B. Schuller, “Opensmile: the munich versatile and fast open-source audio feature extractor,” inProceedings of the 18th ACM International Conference on Multimedia, ser. MM ’10. New York, NY , USA: Association for Computing Machinery, 2010, p. 1459–1462. [Online]. Available: https://doi.org/10.1145/1873951.1874246
-
[16]
Audiolm: A language modeling approach to audio generation,
Z. Borsos, R. Marinier, D. Vincent, E. Kharitonov, O. Pietquin, M. Sharifi, D. Roblek, O. Teboul, D. Grangier, M. Tagliasacchi, and N. Zeghidour, “Audiolm: A language modeling approach to audio generation,”IEEE/ACM Trans. Audio, Speech and Lang. Proc., vol. 31, p. 2523–2533, Jun. 2023. [Online]. Available: https://doi.org/10.1109/TASLP.2023.3288409
-
[17]
SpeechGPT: Empowering large language models with intrinsic cross-modal conversational abilities,
D. Zhang, S. Li, X. Zhang, J. Zhan, P. Wang, Y . Zhou, and X. Qiu, “SpeechGPT: Empowering large language models with intrinsic cross-modal conversational abilities,” inFindings of the Association for Computational Linguistics: EMNLP 2023, H. Bouamor, J. Pino, and K. Bali, Eds. Singapore: Association for Computational Linguistics, Dec. 2023, pp. 15 757–15 ...
2023
-
[18]
Neural codec language models are zero-shot text to speech synthesizers,
S. Chen, C. Wang, Y . Wu, Z. Zhang, L. Zhou, S. Liu, Z. Chen, Y . Liu, H. Wang, J. Li, L. He, S. Zhao, and F. Wei, “Neural codec language models are zero-shot text to speech synthesizers,”IEEE Transactions on Audio, Speech and Language Processing, vol. 33, pp. 705–718, 2025
2025
-
[19]
Audiopalm: A large language model that can speak and listen,
P. K. Rubenstein, C. Asawaroengchai, D. D. Nguyen, A. Bapna, Z. Borsos, F. de Chaumont Quitry, P. Chen, D. E. Badawy, W. Han, E. Kharitonov, H. Muckenhirn, D. R. Padfield, J. Qin, D. Rozenberg, T. N. Sainath, J. Schalkwyk, M. Sharifi, M. D. Tadmor, Ramanovich, M. Tagliasacchi, A. Tudor, M. Velimirovi’c, D. Vincent, J. Yu, Y . Wang, V . Zayats, N. Zeghidou...
Pith/arXiv arXiv 2023
-
[20]
Retrieval-augmented generation for knowledge- intensive nlp tasks,
P. Lewis, E. Perez, A. Piktus, F. Petroni, V . Karpukhin, N. Goyal, H. K ¨uttler, M. Lewis, W.-t. Yih, T. Rockt ¨aschel, S. Riedel, and D. Kiela, “Retrieval-augmented generation for knowledge- intensive nlp tasks,” inProceedings of the 34th International Con- ference on Neural Information Processing Systems, ser. NIPS ’20. Red Hook, NY , USA: Curran Assoc...
2020
-
[21]
React: Synergizing reasoning and acting in language models,
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y . Cao, “React: Synergizing reasoning and acting in language models,”ArXiv, vol. abs/2210.03629, 2022. [Online]. Available: https://api.semanticscholar.org/CorpusID:252762395
Pith/arXiv arXiv 2022
-
[22]
Robust speech recognition via large-scale weak su- pervision,
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust speech recognition via large-scale weak su- pervision,” inProceedings of the 40th International Conference on Machine Learning, ser. ICML’23. JMLR.org, 2023
2023
-
[23]
emotion2vec: Self-supervised pre-training for speech emotion representation,
Z. Ma, Z. Zheng, J. Ye, J. Li, Z. Gao, S. Zhang, and X. Chen, “emotion2vec: Self-supervised pre-training for speech emotion representation,” inFindings of the Association for Computational Linguistics: ACL 2024, L.-W. Ku, A. Martins, and V . Srikumar, Eds. Bangkok, Thailand: Association for Computational Linguistics, Aug. 2024, pp. 15 747–15 760. [Online]...
2024
-
[24]
Langgpt: Rethinking structured reusable prompt design framework for llms from the programming language,
M. Wang, Y . Liu, X. Liang, S. Li, Y . Huang, X. Zhang, S. Shen, C. Guan, D. Wang, S. hi Feng, H. Zhang, Y . Zhang, M. Zheng, and C. Zhang, “Langgpt: Rethinking structured reusable prompt design framework for llms from the programming language,”
-
[25]
Available: https://arxiv.org/abs/2402.16929
[Online]. Available: https://arxiv.org/abs/2402.16929
-
[26]
Styletts 2: towards human-level text-to-speech through style dif- fusion and adversarial training with large speech language mod- els,
Y . A. Li, C. Han, V . S. Raghavan, G. Mischler, and N. Mesgarani, “Styletts 2: towards human-level text-to-speech through style dif- fusion and adversarial training with large speech language mod- els,” inProceedings of the 37th International Conference on Neu- ral Information Processing Systems, ser. NIPS ’23. Red Hook, NY , USA: Curran Associates Inc., 2023
2023
-
[27]
TOOL-ED: Enhancing empathetic response generation with the tool calling capability of LLM,
H. Cao, Y . Zhang, S. Feng, X. Yang, D. Wang, and Y . Zhang, “TOOL-ED: Enhancing empathetic response generation with the tool calling capability of LLM,” inProceedings of the 31st International Conference on Computational Linguistics, O. Rambow, L. Wanner, M. Apidianaki, H. Al-Khalifa, B. D. Eugenio, and S. Schockaert, Eds. Abu Dhabi, UAE: Association for...
2025
-
[28]
Towards empathetic open-domain conversation models: A new benchmark and dataset,
H. Rashkin, E. M. Smith, M. Li, and Y .-L. Boureau, “Towards empathetic open-domain conversation models: A new benchmark and dataset,” inProceedings of the 57th Annual Meeting of the Association for Computational Linguistics, A. Korhonen, D. Traum, and L. M`arquez, Eds. Florence, Italy: Association for Computational Linguistics, Jul. 2019, pp. 5370–5381. ...
2019
-
[29]
Towards multimodal empathetic response generation: A rich text-speech-vision avatar-based benchmark,
H. Zhang, Z. Meng, M. Luo, H. Han, L. Liao, E. Cambria, and H. Fei, “Towards multimodal empathetic response generation: A rich text-speech-vision avatar-based benchmark,” inProceedings of the ACM on Web Conference 2025, ser. WWW ’25. New York, NY , USA: Association for Computing Machinery, 2025, p. 2872–2881. [Online]. Available: https://doi.org/10.1145/ ...
arXiv 2025
-
[30]
SALMONN: Towards generic hearing abilities for large language models,
C. Tang, W. Yu, G. Sun, X. Chen, T. Tan, W. Li, L. Lu, Z. MA, and C. Zhang, “SALMONN: Towards generic hearing abilities for large language models,” inThe Twelfth International Conference on Learning Representations, 2024. [Online]. Available: https://openreview.net/forum?id=14rn7HpKVk
2024
-
[31]
Osum-echat: Enhancing end-to-end empathetic spoken chatbot via understanding-driven spoken dialogue,
X. Geng, Q. Shao, H. Xue, S. Wang, H. Xie, Z. Guo, Y . Zhao, G. Li, W. Tian, C. Wang, Z. Zhao, K. Xia, Z. Zhang, Z. Lin, T. Zuo, M. Shao, Y . Cao, G. Ma, L. Li, Y . Dai, D. Gao, D. Guo, and L. Xie, “Osum-echat: Enhancing end-to-end empathetic spoken chatbot via understanding-driven spoken dialogue,” 2025. [Online]. Available: https://arxiv.org/abs/2508.09600
arXiv 2025
-
[32]
Qwen2.5-omni technical report,
J. Xu, Z. Guo, J. He, H. Hu, T. He, S. Bai, K. Chen, J. Wang, Y . Fan, K. Dang, B. Zhang, X. Wang, Y . Chu, and J. Lin, “Qwen2.5-omni technical report,” 2025. [Online]. Available: https://arxiv.org/abs/2503.20215
Pith/arXiv arXiv 2025
-
[33]
LLaMA-omni 2: LLM-based real-time spoken chatbot with autoregressive streaming speech synthesis,
Q. Fang, Y . Zhou, S. Guo, S. Zhang, and Y . Feng, “LLaMA-omni 2: LLM-based real-time spoken chatbot with autoregressive streaming speech synthesis,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), W. Che, J. Nabende, E. Shutova, and M. T. Pilehvar, Eds. Vienna, Austria: Association for Co...
2025
-
[34]
OpenS2S: Advancing fully open-source end-to-end empathetic large speech language model,
C. Wang, T. Peng, W. Yang, Y . Bai, G. Wang, J. Lin, L. Jia, L. Wu, J. Wang, C. Zong, and J. Zhang, “OpenS2S: Advancing fully open-source end-to-end empathetic large speech language model,” inProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, I. Habernal, P. Schulam, and J. Tiedemann, Eds. Suzhou...
2025
-
[35]
Qwenet al., “Qwen2.5 technical report,” 2025. [Online]. Available: https://arxiv.org/abs/2412.15115
Pith/arXiv arXiv 2025
-
[36]
The llama 3 herd of models,
A. Grattafiori, A. Dubey, A. Jauhriet al., “The llama 3 herd of models,” 2024. [Online]. Available: https://arxiv.org/abs/2407. 21783
2024
-
[37]
LlamaFactory: Unified efficient fine-tuning of 100+ language models,
Y . Zheng, R. Zhang, J. Zhang, Y . Ye, and Z. Luo, “LlamaFactory: Unified efficient fine-tuning of 100+ language models,” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations), Y . Cao, Y . Feng, and D. Xiong, Eds. Bangkok, Thailand: Association for Computational Linguistics, Aug. 2024,...
2024
-
[38]
COMET: Commonsense transformers for automatic knowledge graph construction,
A. Bosselut, H. Rashkin, M. Sap, C. Malaviya, A. Celikyilmaz, and Y . Choi, “COMET: Commonsense transformers for automatic knowledge graph construction,” inProceedings of the 57th Annual Meeting of the Association for Computational Linguistics, A. Korhonen, D. Traum, and L. M `arquez, Eds. Florence, Italy: Association for Computational Linguistics, Jul. 2...
2019
-
[39]
Available: https://aclanthology.org/P19-1470/
[Online]. Available: https://aclanthology.org/P19-1470/
-
[40]
Bleu: a method for automatic evaluation of machine translation,
K. Papineni, S. Roukos, T. Ward, and W.-J. Zhu, “Bleu: a method for automatic evaluation of machine translation,” in Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, P. Isabelle, E. Charniak, and D. Lin, Eds. Philadelphia, Pennsylvania, USA: Association for Computational Linguistics, Jul. 2002, pp. 311–318. [Online]...
2002
-
[41]
Bertscore: Evaluating text generation with bert,
T. Zhang, V . Kishore, F. Wu, K. Q. Weinberger, and Y . Artzi, “Bertscore: Evaluating text generation with bert,”arXiv preprint arXiv:1904.09675, 2019
Pith/arXiv arXiv 1904
-
[42]
ROUGE: A package for automatic evaluation of summaries,
C.-Y . Lin, “ROUGE: A package for automatic evaluation of summaries,” inText Summarization Branches Out. Barcelona, Spain: Association for Computational Linguistics, Jul. 2004, pp. 74–81. [Online]. Available: https://aclanthology.org/W04-1013/
2004
-
[43]
A diversity- promoting objective function for neural conversation models,
J. Li, M. Galley, C. Brockett, J. Gao, and B. Dolan, “A diversity- promoting objective function for neural conversation models,” inProceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, K. Knight, A. Nenkova, and O. Rambow, Eds. San Diego, California: Association for ...
2016
-
[44]
A technique for the measurement of attitudes
R. Likert, “A technique for the measurement of attitudes.” Archives of psychology, 1932
1932
-
[45]
Cem: Commonsense-aware empathetic response generation,
S. Sabour, C. Zheng, and M. Huang, “Cem: Commonsense-aware empathetic response generation,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 36, no. 10, 2022, pp. 11 229–11 237
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.