Towards Anomaly Detection on Relational Data
Pith reviewed 2026-06-26 21:57 UTC · model grok-4.3
The pith
RelAD detects anomalies in relational databases by reconstructing both multi-table attributes and foreign-key connections.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
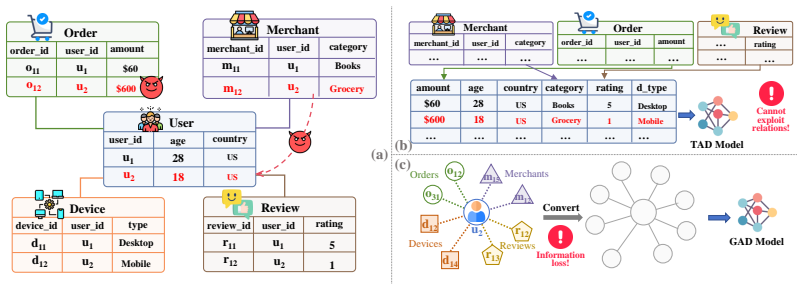
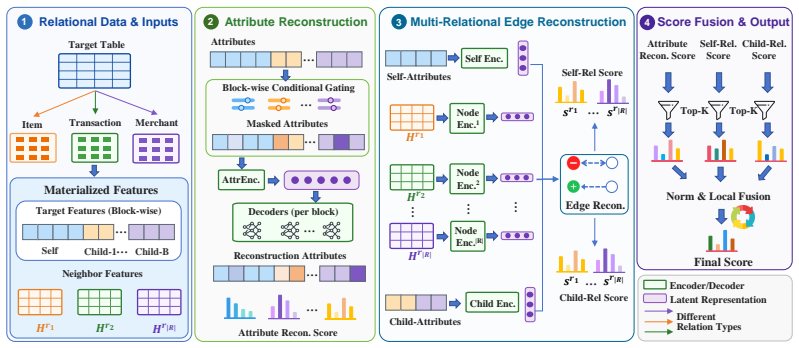
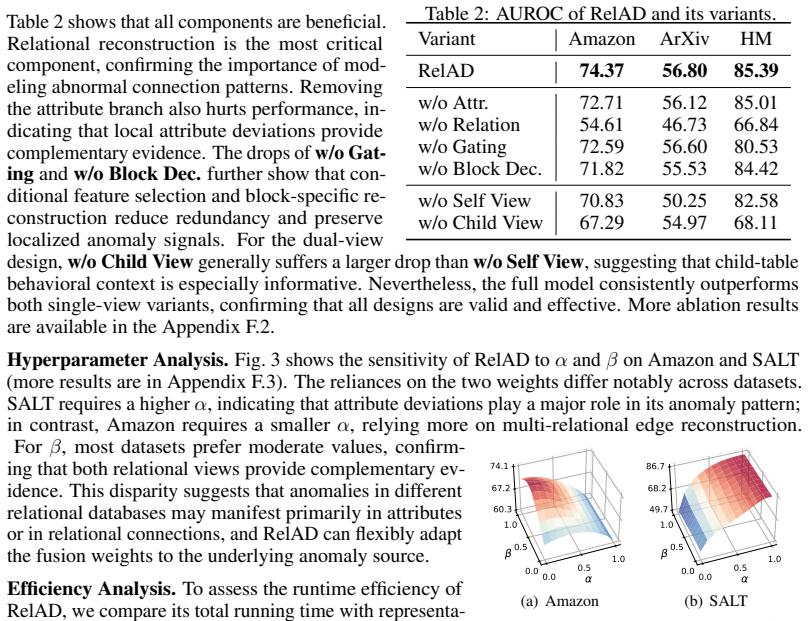
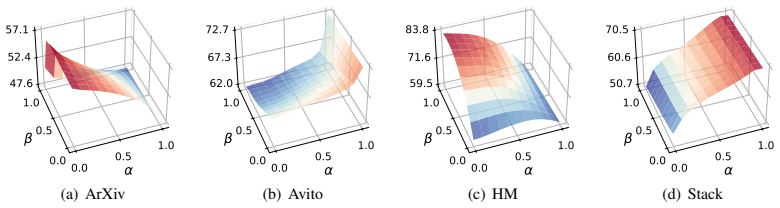
RelAD is a reconstruction-based framework that captures anomalies from both attribute and relational edge reconstruction. It contains conditional sparse-gated attribute reconstruction, which suppresses redundant multi-table attributes and emphasizes abnormal semantic blocks, and dual-view multi-relational edge reconstruction, which detects relation-specific abnormal connections from both intrinsic and behavioral entity profiles. The resulting attribute and relational signals are integrated through a lightweight fusion module to produce the final anomaly score. On six constructed benchmark datasets with systematic anomalies, RelAD consistently outperforms other baselines while achieving compe
What carries the argument
Dual reconstruction: conditional sparse-gated attribute reconstruction combined with dual-view multi-relational edge reconstruction, fused for the anomaly score.
If this is right
- Anomaly detection becomes feasible for relational data where abnormal clues are sparse across many heterogeneous attributes.
- Detection can now target abnormal foreign-key connection patterns that standard tabular and graph methods overlook.
- A single framework can produce competitive accuracy and runtime on multiple relational benchmarks.
- The method supplies separate attribute-level and relation-level signals that can be inspected for explanation.
Where Pith is reading between the lines
- The same reconstruction signals might be used to rank which specific attributes or links are most anomalous in a given case.
- The benchmark construction process could be reused to create additional test sets for other relational anomaly settings.
- The fusion module might be replaced by more advanced integration techniques without changing the core reconstruction modules.
Load-bearing premise
The six constructed benchmark datasets with systematic anomalies sufficiently capture the real-world challenges of high-dimensional heterogeneous multi-table attributes and abnormal foreign-key connection patterns.
What would settle it
An evaluation on real production relational databases that contain verified anomalies in which RelAD does not outperform standard tabular or graph anomaly detection baselines.
Figures

read the original abstract
Relational databases are widely used for managing structured data in real-world systems. Detecting anomalies from such relational data is crucial for identifying fraud, risks, and abnormal behaviors, yet remains under-explored. The key challenges lie in the intrinsic complexity of relational data: multi-table attributes are high-dimensional and heterogeneous, making sparse abnormal clues easy to overwhelm by normal or irrelevant information; and anomalies may further manifest as abnormal connection patterns across different foreign-key relations, which existing tabular and graph anomaly detection methods are ill-suited to capture. To address them, we propose RelAD, a reconstruction-based framework that captures anomalies from both attribute and relational edge reconstruction. RelAD contains two core modules: conditional sparse-gated attribute reconstruction, which suppresses redundant multi-table attributes and emphasizes abnormal semantic blocks, and dual-view multi-relational edge reconstruction, which detects relation-specific abnormal connections from both intrinsic and behavioral entity profiles. The resulting attribute and relational signals are integrated through a lightweight fusion module to produce the final anomaly score. We further construct 6 benchmark datasets with systematic anomalies, on which extensive experiments show that RelAD consistently outperforms other baselines while achieving competitive efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes RelAD, a reconstruction-based anomaly detection framework for relational databases. It introduces two core modules—conditional sparse-gated attribute reconstruction to suppress redundant multi-table attributes and emphasize abnormal semantic blocks, and dual-view multi-relational edge reconstruction to detect relation-specific abnormal connections from intrinsic and behavioral entity profiles—whose signals are fused to produce anomaly scores. The authors construct 6 benchmark datasets with systematic anomalies and report that RelAD consistently outperforms baselines while maintaining competitive efficiency.
Significance. If the empirical outperformance holds under the reported experimental conditions, the work addresses an under-explored problem in anomaly detection on relational data by jointly modeling attribute heterogeneity and foreign-key connection anomalies. The benchmark construction itself is a useful contribution for the community. The absence of free parameters or invented entities in the method description strengthens the claim that performance derives from the proposed reconstruction objectives rather than hidden fitting.
minor comments (3)
- The abstract states outperformance on 6 benchmarks but the experimental section should explicitly tabulate all metrics, baseline descriptions, and hyperparameter settings to allow direct replication; currently the quantitative claims are difficult to verify without those details.
- Clarify in §4 how the 6 constructed datasets systematically inject anomalies into foreign-key patterns versus attribute values; the current description leaves open whether the anomaly generation process could inadvertently favor reconstruction-based methods.
- The fusion module is described as 'lightweight' but no ablation isolating its contribution versus simple concatenation or averaging appears in the experiments; adding this would strengthen the integration claim.
Simulated Author's Rebuttal
We thank the referee for the positive summary, recognition of the problem's importance, and recommendation for minor revision. No specific major comments were raised in the report.
Circularity Check
No significant circularity in derivation chain
full rationale
The paper introduces RelAD as a reconstruction-based anomaly detection framework consisting of conditional sparse-gated attribute reconstruction and dual-view multi-relational edge reconstruction modules whose outputs are fused into an anomaly score. These components are defined directly from the problem requirements of handling heterogeneous multi-table attributes and foreign-key relations, with no equations or claims reducing a prediction or result back to a fitted parameter or self-citation by construction. Benchmark construction and empirical comparisons are presented as external validation steps rather than inputs that force the method's outputs. No self-citation load-bearing, uniqueness theorem, or ansatz smuggling is indicated in the provided description.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Relbench: A benchmark for deep learning on relational databases.Advances in Neural Information Processing Systems, 37:21330–21341, 2024
Joshua Robinson, Rishabh Ranjan, Weihua Hu, Kexin Huang, Jiaqi Han, Alejandro Dobles, Matthias Fey, Jan E Lenssen, Yiwen Yuan, Zecheng Zhang, et al. Relbench: A benchmark for deep learning on relational databases.Advances in Neural Information Processing Systems, 37:21330–21341, 2024
2024
-
[2]
Relational deep learning: Challenges, foundations and next-generation architectures
Vijay Prakash Dwivedi, Charilaos Kanatsoulis, Shenyang Huang, and Jure Leskovec. Relational deep learning: Challenges, foundations and next-generation architectures. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V . 2, pages 5999–6009, 2025
2025
-
[3]
Relational graph transformer
Vijay Prakash Dwivedi, Sri Jaladi, Yangyi Shen, Federico Lopez, Charilaos I Kanatsoulis, Rishi Puri, Matthias Fey, and Jure Leskovec. Relational graph transformer. InTemporal Graph Learning Workshop@ KDD 2025
2025
-
[4]
Relgnn: Composite message passing for relational deep learning
Tianlang Chen, Charilaos Kanatsoulis, and Jure Leskovec. Relgnn: Composite message passing for relational deep learning. InInternational Conference on Machine Learning, pages 8296–8312. PMLR, 2025
2025
-
[5]
Relational transformer: Toward zero-shot foundation models for relational data
Rishabh Ranjan, Valter Hudovernik, Mark Znidar, Charilaos I Kanatsoulis, Roshan Reddy Upendra, Mahmoud Mohammadi, Joe Meyer, Tom Palczewski, Carlos Guestrin, and Jure Leskovec. Relational transformer: Toward zero-shot foundation models for relational data. InEurIPS 2025 Workshop: AI for Tabular Data
2025
-
[6]
Griffin: Towards a graph-centric relational database foundation model
Yanbo Wang, Xiyuan Wang, Quan Gan, Minjie Wang, Qibin Yang, David Wipf, and Muhan Zhang. Griffin: Towards a graph-centric relational database foundation model. InInternational Conference on Machine Learning, pages 64604–64627. PMLR, 2025
2025
-
[7]
Beyond individual input for deep anomaly detection on tabular data
Hugo Thimonier, Fabrice Popineau, Arpad Rimmel, and Bich-Liên Doan. Beyond individual input for deep anomaly detection on tabular data. InInternational Conference on Machine Learning, pages 48097–48123. PMLR, 2024
2024
-
[8]
Drl: Decomposed representation learning for tabular anomaly detection
Hangting Ye, He Zhao, Wei Fan, Mingyuan Zhou, Dan dan Guo, and Yi Chang. Drl: Decomposed representation learning for tabular anomaly detection. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[9]
Correcting false alarms from unseen: Adapting graph anomaly detectors at test time
Junjun Pan, Yixin Liu, Chuan Zhou, Fei Xiong, Alan Wee-Chung Liew, and Shirui Pan. Correcting false alarms from unseen: Adapting graph anomaly detectors at test time. InProceedings of the AAAI Conference on Artificial Intelligence, 2026
2026
-
[10]
A survey of generalization of graph anomaly detection: From transfer learning to foundation models
Junjun Pan, Yu Zheng, Yue Tan, and Yixin Liu. A survey of generalization of graph anomaly detection: From transfer learning to foundation models. InThe 16th IEEE International Conference on Knowledge Graphs, 2025. 10
2025
-
[11]
Deep anomaly detection on attributed networks
Kaize Ding, Jundong Li, Rohit Bhanushali, and Huan Liu. Deep anomaly detection on attributed networks. InProceedings of the 2019 SIAM international conference on data mining, pages 594–602. SIAM, 2019
2019
-
[12]
Anomaly detection on attributed networks via contrastive self-supervised learning.IEEE transactions on neural networks and learning systems, 33(6):2378–2392, 2021
Yixin Liu, Zhao Li, Shirui Pan, Chen Gong, Chuan Zhou, and George Karypis. Anomaly detection on attributed networks via contrastive self-supervised learning.IEEE transactions on neural networks and learning systems, 33(6):2378–2392, 2021
2021
-
[13]
Boosting graph anomaly detection with adaptive message passing
Jingyan Chen, Guanghui Zhu, Chunfeng Yuan, and Yihua Huang. Boosting graph anomaly detection with adaptive message passing. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[14]
Camera: Adapting to semantic camouflage in unsupervised text-attributed graph fraud detection
Junjun Pan, Yixin Liu, Yu Zheng, Lianhua Chi, Alan Wee-Chung Liew, and Shirui Pan. Camera: Adapting to semantic camouflage in unsupervised text-attributed graph fraud detection. InInternational Joint Conference on Artificial Intelligence, 2026
2026
-
[15]
Lof: identifying density-based local outliers
Markus M Breunig, Hans-Peter Kriegel, Raymond T Ng, and Jörg Sander. Lof: identifying density-based local outliers. InProceedings of the 2000 ACM SIGMOD international conference on Management of data, pages 93–104, 2000
2000
-
[16]
Lunar: Unifying local outlier detection methods via graph neural networks
Adam Goodge, Bryan Hooi, See-Kiong Ng, and Wee Siong Ng. Lunar: Unifying local outlier detection methods via graph neural networks. InProceedings of the AAAI conference on artificial intelligence, volume 36, pages 6737–6745, 2022
2022
-
[17]
Mcm: Masked cell modeling for anomaly detection in tabular data
Jiaxin Yin, Yuanyuan Qiao, Zitang Zhou, Xiangchao Wang, and Jie Yang. Mcm: Masked cell modeling for anomaly detection in tabular data. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[18]
Uncertainty- aware graph neural networks: A multihop evidence fusion approach.IEEE Transactions on Neural Networks and Learning Systems, 2025
Qingfeng Chen, Shiyuan Li, Yixin Liu, Shirui Pan, Geoffrey I Webb, and Shichao Zhang. Uncertainty- aware graph neural networks: A multihop evidence fusion approach.IEEE Transactions on Neural Networks and Learning Systems, 2025
2025
-
[19]
Influence-oriented personalized federated learning.arXiv preprint arXiv:2410.03315, 2024
Yue Tan, Guodong Long, Jing Jiang, and Chengqi Zhang. Influence-oriented personalized federated learning.arXiv preprint arXiv:2410.03315, 2024
-
[20]
Arc: A generalist graph anomaly detector with in-context learning.Advances in Neural Information Processing Systems, 37:50772–50804, 2024
Yixin Liu, Shiyuan Li, Yu Zheng, Qingfeng Chen, Chengqi Zhang, and Shirui Pan. Arc: A generalist graph anomaly detector with in-context learning.Advances in Neural Information Processing Systems, 37:50772–50804, 2024
2024
-
[21]
Freegad: A training- free yet effective approach for graph anomaly detection
Yunfeng Zhao, Yixin Liu, Shiyuan Li, Qingfeng Chen, Yu Zheng, and Shirui Pan. Freegad: A training- free yet effective approach for graph anomaly detection. InProceedings of the 34th ACM International Conference on Information and Knowledge Management, pages 4379–4389, 2025
2025
-
[22]
RelBench v2: A Large-Scale Benchmark and Repository for Relational Data
Justin Gu, Rishabh Ranjan, Charilaos Kanatsoulis, Haiming Tang, Martin Jurkovic, Valter Hudovernik, Mark Znidar, Pranshu Chaturvedi, Parth Shroff, Fengyu Li, et al. Relbench v2: A large-scale benchmark and repository for relational data.arXiv preprint arXiv:2602.12606, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[23]
Salt: Sales autocompletion linked business tables dataset
Tassilo Klein, Clemens Biehl, Margarida Costa, Andre Sres, Jonas Kolk, and Johannes Hoffart. Salt: Sales autocompletion linked business tables dataset. InNeurIPS 2024 Third Table Representation Learning Workshop
2024
-
[24]
Prem: A simple yet effective approach for node- level graph anomaly detection
Junjun Pan, Yixin Liu, Yizhen Zheng, and Shirui Pan. Prem: A simple yet effective approach for node- level graph anomaly detection. In2023 IEEE International Conference on Data Mining (ICDM), pages 1253–1258. IEEE, 2023
2023
-
[25]
Efficient algorithms for mining outliers from large data sets
Sridhar Ramaswamy, Rajeev Rastogi, and Kyuseok Shim. Efficient algorithms for mining outliers from large data sets. InProceedings of the 2000 ACM SIGMOD international conference on Management of data, pages 427–438, 2000
2000
-
[26]
Generative adversarial active learning for unsupervised outlier detection.IEEE Transactions on Knowledge and Data Engineering, 32(8):1517–1528, 2019
Yezheng Liu, Zhe Li, Chong Zhou, Yuanchun Jiang, Jianshan Sun, Meng Wang, and Xiangnan He. Generative adversarial active learning for unsupervised outlier detection.IEEE Transactions on Knowledge and Data Engineering, 32(8):1517–1528, 2019
2019
-
[27]
Relational deep learning: Graph representation learning on relational databases
Joshua Robinson, Rishabh Ranjan, Weihua Hu, Kexin Huang, Jiaqi Han, Alejandro Dobles, Matthias Fey, Jan Eric Lenssen, Yiwen Yuan, Zecheng Zhang, et al. Relational deep learning: Graph representation learning on relational databases. InNeurIPS 2024 third table representation learning workshop, 2024
2024
-
[28]
Large language models are good relational learners
Fang Wu, Vijay Prakash Dwivedi, and Jure Leskovec. Large language models are good relational learners. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 7835–7854, 2025. 11
2025
-
[29]
Plurel: Synthetic data unlocks scaling laws for relational foundation models
Vignesh Kothapalli, Rishabh Ranjan, Valter Hudovernik, Vijay Prakash Dwivedi, Johannes Hoffart, Carlos Guestrin, and Jure Leskovec. Plurel: Synthetic data unlocks scaling laws for relational foundation models. arXiv preprint arXiv:2602.04029, 2026
-
[30]
Deep learning for anomaly detection: A review.ACM computing surveys (CSUR), 54(2):1–38, 2021
Guansong Pang, Chunhua Shen, Longbing Cao, and Anton Van Den Hengel. Deep learning for anomaly detection: A review.ACM computing surveys (CSUR), 54(2):1–38, 2021
2021
-
[31]
Deep neural networks and tabular data: A survey.IEEE transactions on neural networks and learning systems, 35(6):7499–7519, 2022
Vadim Borisov, Tobias Leemann, Kathrin Seßler, Johannes Haug, Martin Pawelczyk, and Gjergji Kasneci. Deep neural networks and tabular data: A survey.IEEE transactions on neural networks and learning systems, 35(6):7499–7519, 2022
2022
-
[32]
Anomaly detection for tabular data with internal contrastive learning
Tom Shenkar and Lior Wolf. Anomaly detection for tabular data with internal contrastive learning. In International conference on learning representations, 2022
2022
-
[33]
A comprehensive survey on graph anomaly detection with deep learning.IEEE transactions on knowledge and data engineering, 35(12):12012–12038, 2021
Xiaoxiao Ma, Jia Wu, Shan Xue, Jian Yang, Chuan Zhou, Quan Z Sheng, Hui Xiong, and Leman Akoglu. A comprehensive survey on graph anomaly detection with deep learning.IEEE transactions on knowledge and data engineering, 35(12):12012–12038, 2021
2021
-
[34]
Deep graph anomaly detection: A survey and new perspectives.IEEE Transactions on Knowledge and Data Engineer- ing, 2025
Hezhe Qiao, Hanghang Tong, Bo An, Irwin King, Charu Aggarwal, and Guansong Pang. Deep graph anomaly detection: A survey and new perspectives.IEEE Transactions on Knowledge and Data Engineer- ing, 2025
2025
-
[35]
From few-shot to zero-shot: Towards generalist graph anomaly detection.IEEE Transactions on Knowledge and Data Engineering, 2026
Yixin Liu, Shiyuan Li, Yu Zheng, Qingfeng Chen, Chengqi Zhang, Philip S Yu, and Shirui Pan. From few-shot to zero-shot: Towards generalist graph anomaly detection.IEEE Transactions on Knowledge and Data Engineering, 2026
2026
-
[36]
Raising the bar in graph ood generalization: Invariant learning beyond explicit environment modeling.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2026
Xu Shen, Yixin Liu, Yili Wang, Rui Miao, Yiwei Dai, Shirui Pan, Yi Chang, and Xin Wang. Raising the bar in graph ood generalization: Invariant learning beyond explicit environment modeling.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2026
2026
-
[37]
Fedcigar: A personalized reconstruction approach for federated graph-level anomaly detection
Yunfeng Zhao, Yixin Liu, Qingfeng Chen, Shiyuan Li, Yue Tan, and Shirui Pan. Fedcigar: A personalized reconstruction approach for federated graph-level anomaly detection. InInternational Joint Conference on Artificial Intelligence, 2026
2026
-
[38]
Rethinking feature alignment in generalist graph anomaly detection: A relational fingerprint-based approach
Yujing Liu, Yixin Liu, Yu Zheng, Alan Wee-Chung Liew, Xiaofeng Cao, and Shirui Pan. Rethinking feature alignment in generalist graph anomaly detection: A relational fingerprint-based approach. In International Conference on Machine Learning, 2026
2026
-
[39]
Anomalous: A joint modeling approach for anomaly detection on attributed networks
Zhen Peng, Minnan Luo, Jundong Li, Huan Liu, Qinghua Zheng, et al. Anomalous: A joint modeling approach for anomaly detection on attributed networks. InIjcai, volume 18, pages 3513–3519, 2018
2018
-
[40]
Radar: residual analysis for anomaly detection in attributed networks
Jundong Li, Harsh Dani, Xia Hu, and Huan Liu. Radar: residual analysis for anomaly detection in attributed networks. InProceedings of the 26th International Joint Conference on Artificial Intelligence, pages 2152–2158, 2017
2017
-
[41]
Truncated affinity maximization: One-class homophily modeling for graph anomaly detection.Advances in Neural Information Processing Systems, 36:49490–49512, 2023
Hezhe Qiao and Guansong Pang. Truncated affinity maximization: One-class homophily modeling for graph anomaly detection.Advances in Neural Information Processing Systems, 36:49490–49512, 2023
2023
-
[42]
Modeling relational data with graph convolutional networks
Michael Schlichtkrull, Thomas N Kipf, Peter Bloem, Rianne Van Den Berg, Ivan Titov, and Max Welling. Modeling relational data with graph convolutional networks. InEuropean semantic web conference, pages 593–607. Springer, 2018
2018
-
[43]
Blindguard: Safeguarding llm-based multi-agent systems under unknown attacks
Rui Miao, Yixin Liu, Yili Wang, Xu Shen, Yue Tan, Yiwei Dai, Shirui Pan, and Xin Wang. Blindguard: Safeguarding llm-based multi-agent systems under unknown attacks. InProceedings of the 64th Annual Meeting of the Association for Computational Linguistics, 2026
2026
-
[44]
Yanyu Qian, Yue Tan, Yixin Liu, Wang Yu, and Shirui Pan. Dynhd: Hallucination detection for diffusion large language models via denoising dynamics deviation learning.arXiv preprint arXiv:2603.16459, 2026
-
[45]
Assemble your crew: Automatic multi-agent communication topology design via autoregressive graph generation
Shiyuan Li, Yixin Liu, Qingsong Wen, Chengqi Zhang, and Shirui Pan. Assemble your crew: Automatic multi-agent communication topology design via autoregressive graph generation. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 23142–23150, 2026
2026
-
[46]
Ofa-mas: One-for-all multi-agent system topology design based on mixture-of-experts graph generative models
Shiyuan Li, Yixin Liu, Yu Zheng, Mei Li, Quoc Viet Hung Nguyen, and Shirui Pan. Ofa-mas: One-for-all multi-agent system topology design based on mixture-of-experts graph generative models. InProceedings of the ACM Web Conference 2026, pages 1333–1344, 2026
2026
-
[47]
Rethinking unsupervised time series anomaly detection: Dynamic attention based on route inverse-masking.Applied Soft Computing, page 113971, 2025
Enguang Zuo, Jie Zhong, Chen Chen, Cheng Chen, Kurban Ubul, and Xiaoyi Lv. Rethinking unsupervised time series anomaly detection: Dynamic attention based on route inverse-masking.Applied Soft Computing, page 113971, 2025. 12
2025
-
[48]
Enguang Zuo, Junyi Yan, Alimjan Aysa, Chen Chen, Cheng Chen, Hongbing Ma, Xiaoyi Lv, and Kurban Ubul. Sucola: Self-adaptive structure refinement unsupervised contrastive learning framework for food safety risk early warning.Engineering Applications of Artificial Intelligence, 126:107016, 2023
2023
-
[49]
Retrieval augmented deep anomaly detection for tabular data
Hugo Thimonier, Fabrice Popineau, Arpad Rimmel, and Bich-Liên Doan. Retrieval augmented deep anomaly detection for tabular data. InProceedings of the 33rd ACM international conference on information and knowledge management, pages 2250–2259, 2024
2024
-
[50]
Anollm: Large language models for tabular anomaly detection
Che-Ping Tsai, Ganyu Teng, Phillip Wallis, and Wei Ding. Anollm: Large language models for tabular anomaly detection. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[51]
Disentangling tabular data towards better one-class anomaly detection
Jianan Ye, Zhaorui Tan, Yijie Hu, Xi Yang, Guangliang Cheng, and Kaizhu Huang. Disentangling tabular data towards better one-class anomaly detection. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 13061–13068, 2025
2025
-
[52]
Data-efficient and interpretable tabular anomaly detection
Chun-Hao Chang, Jinsung Yoon, Sercan Ö Arik, Madeleine Udell, and Tomas Pfister. Data-efficient and interpretable tabular anomaly detection. InProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 190–201, 2023
2023
-
[53]
Towards one-for-all anomaly detection for tabular data
Shiyuan Li, Yixin Liu, Yu Zheng, Xiaofeng Cao, Shirui Pan, and Heng Tao Shen. Towards one-for-all anomaly detection for tabular data. InForty-third international conference on machine learning, 2026
2026
-
[54]
Graph anomaly detection in time series: A survey.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
Thi Kieu Khanh Ho, Ali Karami, and Narges Armanfard. Graph anomaly detection in time series: A survey.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
2025
-
[55]
Address anomalies at critical crossroads for graph anomaly detection.IEEE Transactions on Knowledge and Data Engineering, 2025
Junyi Yan, Enguang Zuo, Ke Liang, Meng Liu, Miaomiao Li, Xinwang Liu, Xiaoyi Lv, and Kai Lu. Address anomalies at critical crossroads for graph anomaly detection.IEEE Transactions on Knowledge and Data Engineering, 2025
2025
-
[56]
Smoothgnn: Smoothing-aware gnn for unsupervised node anomaly detection
Xiangyu Dong, Xingyi Zhang, Yanni Sun, Lei Chen, Mingxuan Yuan, and Sibo Wang. Smoothgnn: Smoothing-aware gnn for unsupervised node anomaly detection. InProceedings of the ACM on Web Conference 2025, pages 1225–1236, 2025
2025
-
[57]
verified purchase
Rui Bing, Guan Yuan, Mu Zhu, Fanrong Meng, Huifang Ma, and Shaojie Qiao. Heterogeneous graph neural networks analysis: a survey of techniques, evaluations and applications.Artificial Intelligence Review, 56(8), 2023. 13 A Algorithm Description The training and testing algorithms are given in Algorithm 1 and Algorithm 2, respectively. Algorithm 1:The Train...
2023
-
[58]
Importantly, anomaly labels are assigned only after verifying that the sampled entities satisfy the dataset-specific injection constraints
Stratified Injection Rate:We initially sample 5% of the total population across all datasets using a stratified sampling strategy (e.g., binning by node activity or degree) to eliminate selection bias, ensuring that the statistical distribution of the anomalous group rigorously aligns with that of the normal group. Importantly, anomaly labels are assigned...
-
[59]
Replace-Only
Strict “Replace-Only” Strategy:We strictly enforce a “replace-only” strategy during the injection phase, firmly prohibiting the addition or deletion of any data rows. This guarantees that the foundational statistical features of the nodes (e.g., interaction frequency, total degree) remain absolutely conserved before and after injection
-
[60]
Guided by these principles, we design a separate injection rule for each dataset according to its specific schema and business context
Real-World Scenario Reconstruction:Each injection strategy is explicitly designed to reconstruct real-world business fraud scenarios, discarding mere random noise. Guided by these principles, we design a separate injection rule for each dataset according to its specific schema and business context. The per-dataset details are as follows: • Amazon.In e-com...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.