PRISM: PE Relational Inter-Section Matrix. A 2D Section-Aware Dataset for Static PE Malware Detection
Pith reviewed 2026-06-26 03:29 UTC · model grok-4.3
The pith
PRISM's ordered 2D matrix of PE sections recovers nearly all EMBER detection performance at one-sixth the size.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
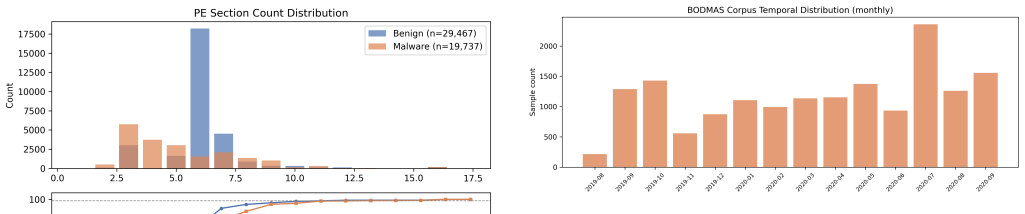
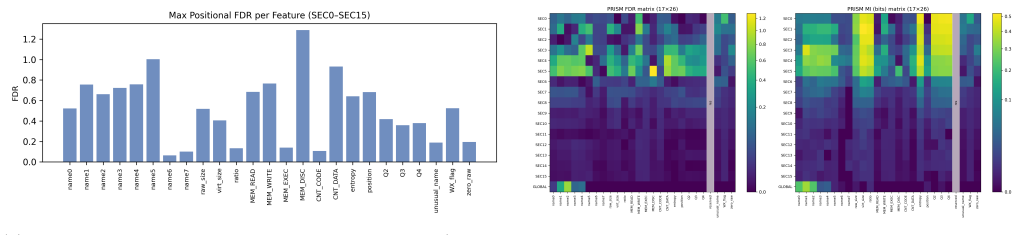
PRISM encodes every PE binary as a two-dimensional matrix whose rows are the individual sections in file order together with a global summary row. Formal separability analysis demonstrates that the per-section positional structure carries discriminative information that flat representations cannot capture. Under strictly controlled sample-matched comparison, a gradient-boosted classifier on the compact PRISM representation recovers nearly all of the binary-detection performance of the same classifier on the much larger EMBER vector at roughly one-sixth the dimensionality, with the two representations operationally indistinguishable at the decision threshold.
What carries the argument
The PRISM matrix: a 2D representation with rows as PE sections in file order plus a summary row that preserves compatibility with existing flat-vector models.
If this is right
- The binary detection task is saturated, leaving PRISM's structural content for tasks with greater headroom such as family classification.
- Architectures that operate directly on the 2D matrix structure become feasible without losing the performance already obtained.
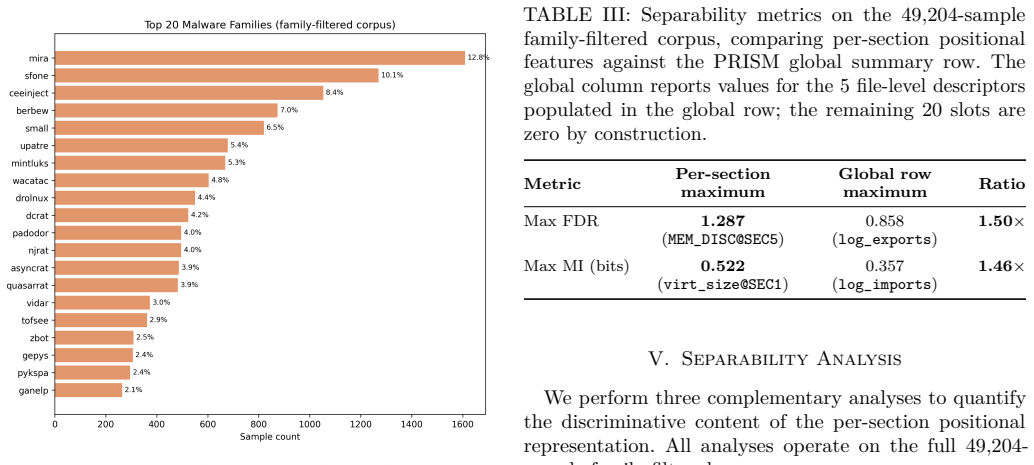
- The released corpus of 83,633 matrices and 49,204 family-filtered samples supports further experiments under open licences.
- EMBER retains only a small, consistent advantage confined to the extreme low-false-positive regime.
Where Pith is reading between the lines
- The same section-ordering principle could be applied to other executable formats that also contain ordered segments.
- Models that process the matrix with 2D operations might extract additional signal beyond what gradient boosting achieves.
- The inter-section information-gain metric offers a general way to quantify positional value in any ordered file format.
Load-bearing premise
The per-section ordering and relational context supply discriminative signals that a flat collection of the same features cannot recover.
What would settle it
A controlled experiment in which a flat feature vector of size comparable to PRISM achieves equal or higher detection accuracy than PRISM on the identical sample set.
Figures
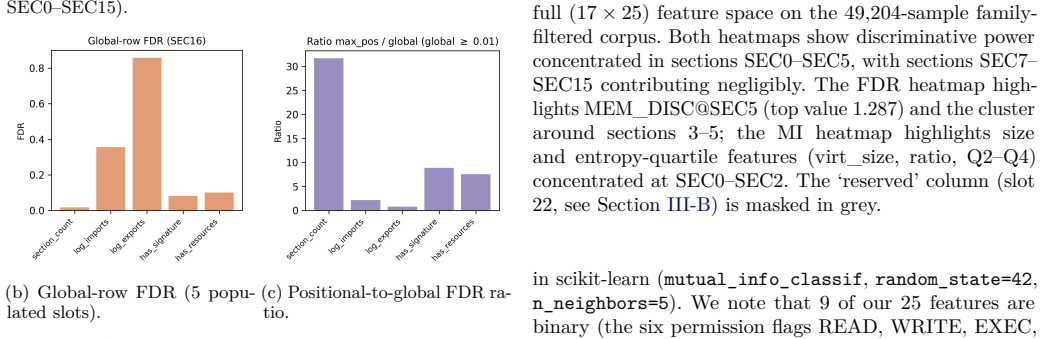

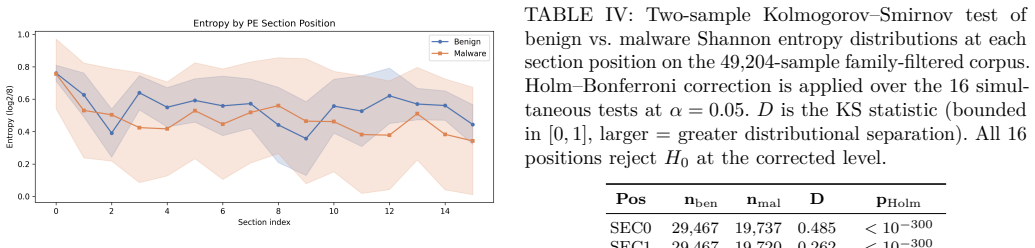
read the original abstract
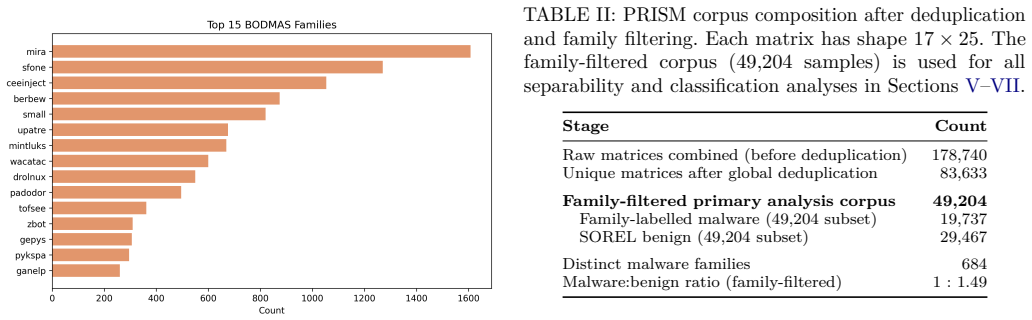
We introduce PRISM (PE Relational Inter-Section Matrix), an open dataset and feature representation for static Windows PE malware detection. Existing benchmarks such as EMBER, BODMAS, and SOREL-20M represent each PE file as a flat one-dimensional feature vector, discarding the ordering of sections and the relational context between them. PRISM instead encodes every binary as a two-dimensional matrix whose rows are individual PE sections in file order, with a global summary row that preserves compatibility with EMBER-style models. We build the corpus from four malware sources (BODMAS, MalwareBazaar, VirusShare, and CAPE) together with SOREL-20M benign software, yielding 83,633 deduplicated matrices and a family-filtered analysis corpus of 49,204 samples across 684 malware families. A formal separability analysis (Fisher Discriminant Ratio, mutual information, and inter-section information gain) shows that the per-section positional structure carries discriminative information that flat representations cannot capture. Under a strictly controlled, sample-matched comparison, a gradient-boosted classifier on the compact PRISM representation recovers nearly all of the binary-detection performance of the same classifier on the much larger EMBER vector, at roughly one-sixth the dimensionality; EMBER retains only a small, consistent advantage confined to the extreme low-false-positive regime, the two being operationally indistinguishable at the decision threshold. We are explicit that this binary task is saturated, so the structural content PRISM preserves is reserved for tasks with greater metric headroom, such as family classification and architectures that exploit the 2D structure directly. The dataset, extraction library, trained models, and full analysis pipeline are released under CC BY-NC-SA and MIT licences.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PRISM, a 2D section-aware matrix representation for static PE malware detection that preserves the order and relational context of PE sections, unlike flat vectors in benchmarks like EMBER. It assembles a new corpus of 83,633 deduplicated samples from BODMAS, MalwareBazaar, VirusShare, CAPE, and SOREL-20M, with a family-filtered subset of 49,204 samples across 684 families. Through separability analysis using Fisher Discriminant Ratio, mutual information, and inter-section information gain, it shows that positional structure provides discriminative information. In controlled sample-matched experiments, a gradient-boosted classifier on the compact PRISM features achieves nearly equivalent binary malware detection performance to the same classifier on the larger EMBER vector at about one-sixth the dimensionality, with the representations being operationally similar at standard thresholds. The work emphasizes that the binary detection task is saturated and positions PRISM for more challenging tasks like family classification, releasing the dataset, library, models, and pipeline openly.
Significance. If the controlled comparison and separability results hold, this work is significant for demonstrating that a compact, structured 2D representation can retain nearly all binary-detection utility of much larger flat vectors while explicitly preserving positional and relational section information for future tasks with greater headroom (e.g., family classification). The open release of the full dataset, extraction library, trained models, and analysis pipeline under CC BY-NC-SA and MIT licenses is a clear strength that enables reproducibility and extension by the community.
major comments (2)
- [Abstract] Abstract: the central performance claim is stated only qualitatively ('recovers nearly all', 'small, consistent advantage', 'operationally indistinguishable') without any numerical results such as AUC, TPR@FPR=0.001, or accuracy deltas; this makes it impossible to evaluate the strength of the 'nearly equivalent' assertion that underpins the dimensionality/performance tradeoff.
- [§3] §3 (dataset construction, inferred from abstract): the description of deduplication across four malware sources plus SOREL-20M and the subsequent family-filtering step to 49,204 samples lacks any detail on the exact procedure (e.g., hash-based, fuzzy, or section-content matching) or the family-labeling criteria; without these, it is unclear whether selection effects could inflate the reported separability or classification parity.
minor comments (3)
- [Abstract] The abstract introduces the 'global summary row' for EMBER compatibility but does not specify its construction (e.g., which statistics are aggregated or how it is concatenated); this should be clarified in the methods section.
- Consider adding an explicit table (perhaps in §4) listing the exact dimensionality of the PRISM matrix versus the EMBER vector used in the matched experiment.
- The separability metrics (Fisher Discriminant Ratio, mutual information, inter-section information gain) are named but their precise formulas and per-section versus global computation are not shown; a short methods subsection would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below and will incorporate revisions to improve the clarity and evaluability of the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central performance claim is stated only qualitatively ('recovers nearly all', 'small, consistent advantage', 'operationally indistinguishable') without any numerical results such as AUC, TPR@FPR=0.001, or accuracy deltas; this makes it impossible to evaluate the strength of the 'nearly equivalent' assertion that underpins the dimensionality/performance tradeoff.
Authors: We agree that the abstract would benefit from quantitative support for the performance claims. While the body of the manuscript reports specific metrics (including AUC, TPR at low FPR thresholds, and accuracy deltas from the controlled experiments), we will revise the abstract to include key numerical results such as the AUC values and TPR@FPR=0.001 to make the 'nearly equivalent' claim directly evaluable. revision: yes
-
Referee: [§3] §3 (dataset construction, inferred from abstract): the description of deduplication across four malware sources plus SOREL-20M and the subsequent family-filtering step to 49,204 samples lacks any detail on the exact procedure (e.g., hash-based, fuzzy, or section-content matching) or the family-labeling criteria; without these, it is unclear whether selection effects could inflate the reported separability or classification parity.
Authors: We acknowledge that additional procedural details are needed for full transparency. We will expand the dataset construction section to specify the deduplication method (SHA-256 hash-based exact matching across sources) and the family-labeling criteria (consensus labeling via AVClass on multi-engine AV reports). These additions will clarify the process and allow readers to assess potential selection effects. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper constructs PRISM as a new 2D matrix representation from independently sourced corpora (BODMAS, MalwareBazaar, VirusShare, CAPE, SOREL-20M) and evaluates it via direct empirical comparison to the external EMBER benchmark using standard gradient-boosted classifiers and separability metrics (Fisher Discriminant Ratio, mutual information). No equations, parameters, or claims reduce by construction to quantities defined inside the paper; the performance and separability results are computed from the assembled data and remain falsifiable against public external references. The argument chain is therefore self-contained and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
EMBER: An Open Dataset for Training Static PE Malware Machine Learning Models,
H. S. Anderson and P. Roth, “EMBER: An Open Dataset for Training Static PE Malware Machine Learning Models,” Apr. 2018
2018
-
[2]
BODMAS: An Open Dataset for Learning-Based Temporal Analysis of PE Malware,
L. Yang, A. Ciptadi, I. Laziuk, A. Ahmadzadeh, and G. Wang, “BODMAS: An Open Dataset for Learning-Based Temporal Analysis of PE Malware,” in2021 IEEE Security and Privacy Workshops (SPW). San Francisco, CA, USA: IEEE, May 2021, pp. 78–84
2021
-
[3]
LightGBM: A Highly Efficient Gradient Boosting Decision Tree,
G. Ke, Q. Meng, T. Finley, T. Wang, W. Chen, W. Ma, Q. Ye, and T.-Y. Liu, “LightGBM: A Highly Efficient Gradient Boosting Decision Tree,” inAdvances in Neural Information Processing Systems 30 (NeurIPS 2017). Long Beach, CA, USA: Curran Associates, Inc., 2017, pp. 3146–3154
2017
-
[4]
EMBER2024 — A Bench- mark Dataset for Holistic Evaluation of Malware Classifiers,
R. J. Joyce, G. Miller, P. Roth, R. Zak, E. Zaresky-Williams, H. Anderson, E. Raff, and J. Holt, “EMBER2024 — A Bench- mark Dataset for Holistic Evaluation of Malware Classifiers,” in Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V.2. Toronto, ON, Canada: ACM, Aug. 2025, pp. 5516–5526
2025
-
[5]
Real-time malware prevention using gradient boosted decision trees on the EMBER 2024 dataset: A static analysis approach for Windows PE binaries,
S.S.Abdulwahab,M.Z.Abdullah,andA.H.Sallomi,“Real-time malware prevention using gradient boosted decision trees on the EMBER 2024 dataset: A static analysis approach for Windows PE binaries,”International Journal of Intelligent Engineering and Systems, vol. 19, no. 6, pp. 748–762, 2026
2024
-
[6]
SOREL-20M: A Large Scale Benchmark Dataset for Malicious PE Detection,
R. Harang and E. M. Rudd, “SOREL-20M: A Large Scale Benchmark Dataset for Malicious PE Detection,” Dec. 2020
2020
-
[7]
Multi-feature Dataset for Windows PE Malware Classification,
M. I. Yousuf, I. Anwer, T. Shakir, M. Siddiqui, and M. Shahid, “Multi-feature Dataset for Windows PE Malware Classification,” Oct. 2022
2022
-
[8]
Measurement of Malware Family Classification on a Large-Scale Real-World Dataset,
Q. Wang, H. Yan, C. Zhao, R. Mei, Z. Han, and Y. Zhou, “Measurement of Malware Family Classification on a Large-Scale Real-World Dataset,” in2022 IEEE International Conference on Trust, Security and Privacy in Computing and Communications (TrustCom). Wuhan, China: IEEE, Dec. 2022, pp. 1390–1397
2022
-
[9]
A PE header-based method for malware detection using clustering and deep em- bedding techniques,
T. Rezaei, F. Manavi, and A. Hamzeh, “A PE header-based method for malware detection using clustering and deep em- bedding techniques,”Journal of Information Security and Applications, vol. 60, p. 102876, Aug. 2021
2021
-
[10]
Deep Learning- Based Malware Detection Using PE Headers,
A. Nakrošis, I. Lagzdinyt˙ e-Budnik˙ e, A. Paulauskait˙ e- Tarasevičien˙ e, G. Paulikas, and P. Dapkus, “Deep Learning- Based Malware Detection Using PE Headers,” inInformation and Software Technologies (ICIST 2022), ser. Communications in Computer and Information Science, A. Lopata, D. Gudonien˙ e, and R. Butkien˙ e, Eds. Cham: Springer International Pub...
2022
-
[11]
An Improved Method for Packed Malware Detection using PE Header and Section Table Information,
N. Maleki, M. Bateni, and H. Rastegari, “An Improved Method for Packed Malware Detection using PE Header and Section Table Information,”International Journal of Computer Network and Information Security, vol. 11, no. 9, pp. 9–17, Sep. 2019
2019
-
[12]
Static Analysis and Machine Learning- Based Malware Detection System using PE Header Feature Values,
C. K. Yuk and C. J. Seo, “Static Analysis and Machine Learning- Based Malware Detection System using PE Header Feature Values,”International Journal of Innovative Research and Scientific Studies, vol. 5, no. 4, pp. 281–288, Oct. 2022
2022
-
[13]
Windows malware detection based on static analysis with multiple features,
M. I. Yousuf, I. Anwer, A. Riasat, K. T. Zia, and S. Kim, “Windows malware detection based on static analysis with multiple features,”PeerJ Computer Science, vol. 9, p. e1319, Apr. 2023
2023
-
[14]
Recent Advancements in Machine Learning Models for Malware Detection: A Systematic Literature Review,
N. I. Hasanah, G. P. Insany, I. L. Kharisma, and N. D. Rahayu, “Recent Advancements in Machine Learning Models for Malware Detection: A Systematic Literature Review,” inThe 7th Interna- tional Global Conference Series on ICT Integration in Technical Education & Smart Society. MDPI, Sep. 2025, p. 78
2025
-
[15]
Image Representation Based Malware Detection Using Transfer Learning,
I. M. Malik Matin, I. Hermawan, S. D. Yulianti, I. A. Ahmad, Naurah, and Z. Azizah, “Image Representation Based Malware Detection Using Transfer Learning,” in2025 IEEE Conference on Cloud and Big Data Computing (CBDCom). Hakodate, Japan: IEEE, Oct. 2025, pp. 136–142
2025
-
[16]
A Proposed New Endpoint Detection and Response With Image-Based Malware Detection System,
T. H. Hai, V. Van Thieu, T. T. Duong, H. H. Nguyen, and E.-N. Huh, “A Proposed New Endpoint Detection and Response With Image-Based Malware Detection System,”IEEE Access, vol. 11, pp. 122859–122875, 2023
2023
-
[17]
Semantic lossless encoded image representation for malware classification,
Y. Yu, B. Cai, K. Aziz, X. Wang, J. Luo, M. S. Iqbal, P. Chakrabarti, and T. Chakrabarti, “Semantic lossless encoded image representation for malware classification,”Scientific Re- ports, vol. 15, no. 1, p. 7997, Mar. 2025
2025
-
[18]
MCPDS: Image-based malware classification method using PE metadata alone,
Y. Zhao, C. Guo, Y. Ping, Y. Chen, Y. Cui, and G. Shen, “MCPDS: Image-based malware classification method using PE metadata alone,”Cybersecurity, vol. 9, no. 1, p. 34, Feb. 2026
2026
-
[19]
Hybrid Malware Classification using Static and Dynamic Features with Machine Learning,
M. I. El-Hajj, “Hybrid Malware Classification using Static and Dynamic Features with Machine Learning,” in2025 12th International Conference on Wireless Networks and Mobile Communications (WINCOM). Riyadh, Saudi Arabia: IEEE, Nov. 2025, pp. 1–8
2025
-
[20]
Estimating mutual information,
A. Kraskov, H. Stögbauer, and P. Grassberger, “Estimating mutual information,”Physical Review E, vol. 69, no. 6, p. 066138, Jun. 2004
2004
-
[21]
LIEF — Library to Instrument Executable Formats,
R. Thomas, “LIEF — Library to Instrument Executable Formats,” https://github.com/lief-project/LIEF, 2017, version 0.14.1
2017
-
[22]
MalwareBazaar — A Project from abuse.ch,
abuse.ch, “MalwareBazaar — A Project from abuse.ch,” https: //bazaar.abuse.ch/, 2020, accessed: May 2025
2020
-
[23]
VirusShare.com,
J.-M. Godwin, “VirusShare.com,” https://virusshare.com/, 2012, accessed: May 2025
2012
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.