NeighborDiv: Training-free Zero-shot Generalist Graph Anomaly Detection via Neighbor Diversity
Pith reviewed 2026-05-21 06:39 UTC · model grok-4.3
The pith
Variance among a node's neighbors reveals anomalies in graphs without any training or domain adaptation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
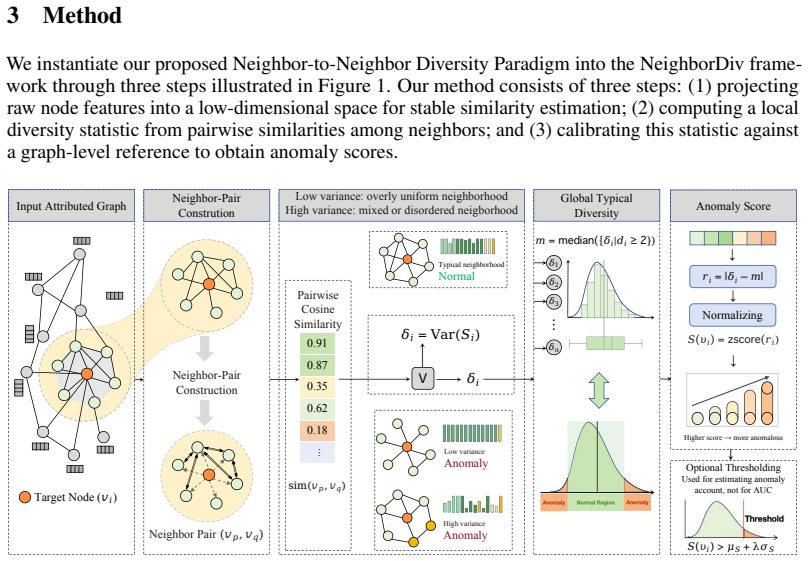
The central discovery is that shifting to a Neighbor-to-Neighbor Diversity Paradigm uncovers the internal structural dispersion of a node's neighbor set as a powerful, independently discriminative anomaly signal. This is quantified via the variance of inter-neighbor feature similarities, which captures how a node organizes its local graph environment and operates independently of node-to-neighbor consistency, enabling effective training-free zero-shot generalist graph anomaly detection.
What carries the argument
The variance of inter-neighbor feature similarities, which measures the internal structural dispersion within a node's neighbor set under the Neighbor-to-Neighbor Diversity Paradigm.
If this is right
- NeighborDiv achieves state-of-the-art performance with relative gains of 10.25% in average AUC and 17.78% in average AP under single-domain independent training.
- It also shows gains of 6.89% in AUC and 9.58% in AP under unified multi-domain training.
- The method exhibits zero performance volatility across all tested datasets.
- It eliminates training-set dependency and complex training pipelines for graph anomaly detection.
Where Pith is reading between the lines
- Neighbor diversity signals could be integrated with existing consistency-based methods to create hybrid detectors with improved accuracy.
- This paradigm might extend to detecting anomalies in dynamic graphs or other structured data beyond static graphs.
- Applying the same variance measure to node embeddings from different models could test its robustness in semi-supervised settings.
Load-bearing premise
The variance of inter-neighbor feature similarities provides an anomaly signal that operates independently of node-to-neighbor consistency and generalizes across domains without any training, adaptation, or domain-specific parameters.
What would settle it
A dataset where high neighbor diversity consistently corresponds to normal nodes rather than anomalies, or where the method's performance drops significantly on a new unseen graph domain compared to trained baselines.
Figures



read the original abstract
Graph Anomaly Detection (GAD) is increasingly shifting to Generalist GAD (GGAD) for cross-domain "one-for-all" detection, but existing GGAD methods predominantly rely on the neighbor consistency principle, falling into the \textbf{Node-to-Neighbor Consistency Paradigm} for anomaly quantification. These methods suffer from complex training pipelines, heavy training data dependency, high computational costs, and unstable cross-domain generalization. To address these limitations, we propose NeighborDiv, a training-free generalist graph anomaly detection framework based on neighbor diversity. Departing from the dominant Node-to-Neighbor Consistency Paradigm, we shift the focus to the \textbf{Neighbor-to-Neighbor Diversity Paradigm}, and uncover that the internal structural dispersion of a node's neighbor set is a powerful, independently discriminative anomaly signal. We quantify neighbor diversity via the variance of inter-neighbor feature similarities, which captures how a node organizes its local graph environment, and operates independently of conventional node-to-neighbor consistency frameworks. Extensive experiments under two standard GGAD evaluation paradigms show NeighborDiv achieves state-of-the-art performance, with relative gains of 10.25% in average AUC and 17.78% in average AP over the second-best baseline under Single-Domain Independent Training (SDIT), and 6.89%/9.58% in AUC/AP under Unified Multi-Domain Training (UMDT), respectively. Notably, NeighborDiv yields zero performance volatility across all datasets, eliminating training-set dependency and establishing a lightweight and highly practical GGAD framework.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces NeighborDiv, a training-free zero-shot generalist graph anomaly detection (GGAD) method. It departs from the dominant Node-to-Neighbor Consistency Paradigm and instead uses a Neighbor-to-Neighbor Diversity Paradigm, quantifying anomaly signals via the variance of inter-neighbor feature similarities. The method is claimed to be parameter-free, independent of conventional consistency measures, and to achieve SOTA results with zero performance volatility under both Single-Domain Independent Training (SDIT) and Unified Multi-Domain Training (UMDT) paradigms, reporting relative gains of 10.25% AUC / 17.78% AP (SDIT) and 6.89% AUC / 9.58% AP (UMDT) over the second-best baseline.
Significance. If the independence of the diversity variance from node-to-neighbor consistency and the cross-domain generalization without any training or parameters hold, this would represent a meaningful simplification for GGAD. The training-free nature, zero volatility across datasets, and explicit parameter-free derivation are clear strengths that could improve practicality and reproducibility in the field.
major comments (1)
- [Abstract] Abstract and method description: The central claim that the variance of inter-neighbor feature similarities 'operates independently of conventional node-to-neighbor consistency frameworks' is load-bearing for the paradigm-shift argument, yet the manuscript provides no correlation analysis, ablation against consistency baselines, or quantitative evidence that the two families of scores are uncorrelated on the evaluation graphs. Without this, the reported gains may reflect a re-expression of existing signals rather than a new discriminative axis.
minor comments (1)
- [Abstract] The abstract reports specific performance numbers and 'zero volatility' without accompanying error bars or details on statistical significance testing; adding these would strengthen the experimental claims.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for highlighting an important point regarding the independence claim in our work. We address the major comment below and will revise the manuscript to provide the requested quantitative evidence.
read point-by-point responses
-
Referee: [Abstract] Abstract and method description: The central claim that the variance of inter-neighbor feature similarities 'operates independently of conventional node-to-neighbor consistency frameworks' is load-bearing for the paradigm-shift argument, yet the manuscript provides no correlation analysis, ablation against consistency baselines, or quantitative evidence that the two families of scores are uncorrelated on the evaluation graphs. Without this, the reported gains may reflect a re-expression of existing signals rather than a new discriminative axis.
Authors: We thank the referee for this observation. The independence of the Neighbor-to-Neighbor Diversity Paradigm from Node-to-Neighbor Consistency is central to our contribution, and we agree that explicit quantitative support strengthens the argument. In the revised version, we will add a new subsection (likely in Section 4 or an appendix) that includes: (1) Pearson and Spearman correlation coefficients between our variance-of-inter-neighbor-similarities score and representative consistency-based anomaly scores (e.g., reconstruction error from GAE-style baselines and contrastive scores from recent GGAD methods) computed on all evaluation graphs; (2) an ablation that replaces our diversity variance with consistency measures while keeping the rest of the pipeline fixed, to isolate the contribution; and (3) visualization of score distributions showing that high-diversity nodes are not necessarily low-consistency nodes. These additions will demonstrate that the two families are not highly correlated and that the reported gains arise from a distinct discriminative axis rather than a re-expression of existing signals. revision: yes
Circularity Check
No circularity: NeighborDiv defines variance-based diversity as a direct, parameter-free anomaly score
full rationale
The paper introduces NeighborDiv by directly defining the anomaly score as the variance of inter-neighbor feature similarities under a new Neighbor-to-Neighbor Diversity Paradigm. This is a novel metric construction with no training, no fitted parameters, and no reduction of the output to previously computed or fitted quantities by construction. The abstract and description present the independence from node-to-neighbor consistency as a conceptual shift supported by empirical results rather than a mathematical derivation that loops back to inputs. No self-citation load-bearing steps, uniqueness theorems from prior author work, or ansatz smuggling appear in the provided derivation chain. The method remains a straightforward computation on graph features and is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Nodes possess feature vectors from which pairwise similarities can be computed.
- domain assumption Local structural dispersion can serve as an anomaly indicator without reference to global or trained models.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We quantify neighbor diversity via the variance of inter-neighbor feature similarities... shifting the focus to the Neighbor-to-Neighbor Diversity Paradigm
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
NeighborDiv... training-free zero-shot generalist graph anomaly detection
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Leman Akoglu, Hanghang Tong, and Danai Koutra. Graph based anomaly detection and description: a survey.Data Mining and Knowledge Discovery, 29(3):626–688, 2015. doi: 10.1007/s10618-014-0365-y
-
[2]
Towards effective federated graph anomaly detection via self-boosted knowledge distillation
Jinyu Cai, Yunhe Zhang, Zhoumin Lu, Wenzhong Guo, and See-Kiong Ng. Towards effective federated graph anomaly detection via self-boosted knowledge distillation. InProceedings of the 32nd ACM International Conference on Multimedia, pages 5537–5546, 2024
work page 2024
-
[3]
Boosting graph anomaly detection with adaptive message passing
Jingyan Chen, Guanghui Zhu, Chunfeng Yuan, and Yihua Huang. Boosting graph anomaly detection with adaptive message passing. InThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[4]
Deep anomaly detection on attributed networks
Kaize Ding, Jundong Li, Rohit Bhanushali, and Huan Liu. Deep anomaly detection on attributed networks. InProceedings of the 2019 SIAM international conference on data mining, pages 594–602. SIAM, 2019
work page 2019
-
[5]
Enhancing graph neu- ral network-based fraud detectors against camouflaged fraudsters
Yingtong Dou, Zhiwei Liu, Li Sun, Yutong Deng, Hao Peng, and Philip S Yu. Enhancing graph neu- ral network-based fraud detectors against camouflaged fraudsters. InProceedings of the 29th ACM international conference on information & knowledge management, pages 315–324, 2020
work page 2020
-
[6]
Graph anomaly detection via multi-scale contrastive learning networks with augmented view
Jingcan Duan, Siwei Wang, Pei Zhang, En Zhu, Jingtao Hu, Hu Jin, Yue Liu, and Zhibin Dong. Graph anomaly detection via multi-scale contrastive learning networks with augmented view. InProceedings of the AAAI conference on artificial intelligence, volume 37, pages 7459–7467, 2023
work page 2023
-
[7]
Anomalydae: Dual autoencoder for anomaly detection on attributed networks
Haoyi Fan, Fengbin Zhang, and Zuoyong Li. Anomalydae: Dual autoencoder for anomaly detection on attributed networks. InICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 5685–5689. IEEE, 2020
work page 2020
-
[8]
Addressing heterophily in graph anomaly detection: A perspective of graph spectrum
Yuan Gao, Xiang Wang, Xiangnan He, Zhenguang Liu, Huamin Feng, and Yongdong Zhang. Addressing heterophily in graph anomaly detection: A perspective of graph spectrum. InProceedings of the ACM web conference 2023, pages 1528–1538, 2023
work page 2023
-
[9]
Mingguo He, Zhewei Wei, Hongteng Xu, et al. Bernnet: Learning arbitrary graph spectral filters via bernstein approximation.Advances in neural information processing systems, 34:14239–14251, 2021
work page 2021
-
[10]
It’s who you know: Graph mining using recursive structural features
Keith Henderson, Brian Gallagher, Lei Li, Leman Akoglu, Tina Eliassi-Rad, Hanghang Tong, and Christos Faloutsos. It’s who you know: Graph mining using recursive structural features. InProceedings of the 17th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pages 663–671,
-
[11]
doi: 10.1145/2020408.2020512. 10
-
[12]
A class of statistics with asymptotically normal distribution
Wassily Hoeffding. A class of statistics with asymptotically normal distribution. InBreakthroughs in statistics: Foundations and basic theory, pages 308–334. Springer, 1992
work page 1992
-
[13]
Holland, Kathryn Blackmond Laskey, and Samuel Leinhardt
Paul W. Holland, Kathryn Blackmond Laskey, and Samuel Leinhardt. Stochastic blockmodels: First steps. Social Networks, 5(2):109–137, 1983. doi: 10.1016/0378-8733(83)90021-7
-
[14]
Hop-count based self-supervised anomaly detection on attributed networks
Tianjin Huang, Yulong Pei, Vlado Menkovski, and Mykola Pechenizkiy. Hop-count based self-supervised anomaly detection on attributed networks. InJoint European conference on machine learning and knowledge discovery in databases, pages 225–241. Springer, 2022
work page 2022
-
[15]
Semi-supervised classification with graph convolutional networks
Thomas N Kipf and Max Welling. Semi-supervised classification with graph convolutional networks. In International Conference on Learning Representations, 2017
work page 2017
-
[16]
Predicting dynamic embedding trajectory in temporal interaction networks
Srijan Kumar, Xikun Zhang, and Jure Leskovec. Predicting dynamic embedding trajectory in temporal interaction networks. InProceedings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining, pages 1269–1278, 2019
work page 2019
-
[17]
Yixin Liu, Zhao Li, Shirui Pan, Chen Gong, Chuan Zhou, and George Karypis. Anomaly detection on attributed networks via contrastive self-supervised learning.IEEE transactions on neural networks and learning systems, 33(6):2378–2392, 2021
work page 2021
-
[18]
Yixin Liu, Shiyuan Li, Yu Zheng, Qingfeng Chen, Chengqi Zhang, and Shirui Pan. Arc: A generalist graph anomaly detector with in-context learning.Advances in Neural Information Processing Systems, 37: 50772–50804, 2024
work page 2024
-
[19]
Xiaoxiao Ma, Jia Wu, Shan Xue, Jian Yang, Chuan Zhou, Quan Z Sheng, Hui Xiong, and Leman Akoglu. A comprehensive survey on graph anomaly detection with deep learning.IEEE transactions on knowledge and data engineering, 35(12):12012–12038, 2021
work page 2021
-
[20]
Andrew Kachites McCallum, Kamal Nigam, Jason Rennie, and Kristie Seymore. Automating the construc- tion of internet portals with machine learning.Information Retrieval, 3(2):127–163, 2000
work page 2000
-
[21]
Chaoxi Niu, Hezhe Qiao, Changlu Chen, Ling Chen, and Guansong Pang. Zero-shot generalist graph anomaly detection with unified neighborhood prompts.arXiv preprint arXiv:2410.14886, 2024
-
[22]
Deep learning for anomaly detection: A review.ACM computing surveys (CSUR), 54(2):1–38, 2021
Guansong Pang, Chunhua Shen, Longbing Cao, and Anton Van Den Hengel. Deep learning for anomaly detection: A review.ACM computing surveys (CSUR), 54(2):1–38, 2021
work page 2021
-
[23]
Bryan Perozzi and Leman Akoglu. Scalable anomaly ranking of attributed neighborhoods. InProceedings of the 2016 SIAM International Conference on Data Mining, pages 207–215, 2016. doi: 10.1137/1. 9781611974348.24
work page doi:10.1137/1 2016
-
[24]
A Critical Look at the Evaluation of GNNs under Heterophily: Are We Really Making Progress?
Oleg Platonov, Denis Kuznedelev, Michael Diskin, Artem Babenko, and Liudmila Prokhorenkova. A critical look at the evaluation of gnns under heterophily: Are we really making progress?arXiv preprint arXiv:2302.11640, 2023
-
[25]
Hezhe Qiao and Guansong Pang. Truncated affinity maximization: One-class homophily modeling for graph anomaly detection.Advances in Neural Information Processing Systems, 36:49490–49512, 2023
work page 2023
-
[26]
Anomalygfm: Graph foundation model for zero/few-shot anomaly detection
Hezhe Qiao, Chaoxi Niu, Ling Chen, and Guansong Pang. Anomalygfm: Graph foundation model for zero/few-shot anomaly detection. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V . 2, pages 2326–2337, 2025
work page 2025
-
[27]
Hezhe Qiao, Hanghang Tong, Bo An, Irwin King, Charu Aggarwal, and Guansong Pang. Deep graph anomaly detection: A survey and new perspectives.IEEE Transactions on Knowledge and Data Engineer- ing, 2025
work page 2025
-
[28]
Statistical selection of congruent subspaces for mining attributed graphs
Patricia Iglesias Sánchez, Emmanuel Müller, Fabian Laforet, Fabian Keller, and Klemens Böhm. Statistical selection of congruent subspaces for mining attributed graphs. In2013 IEEE 13th international conference on data mining, pages 647–656. IEEE, 2013
work page 2013
-
[29]
Collective classification in network data.AI magazine, 29(3):93–93, 2008
Prithviraj Sen, Galileo Namata, Mustafa Bilgic, Lise Getoor, Brian Galligher, and Tina Eliassi-Rad. Collective classification in network data.AI magazine, 29(3):93–93, 2008
work page 2008
-
[30]
Rethinking graph neural networks for anomaly detection
Jianheng Tang, Jiajin Li, Ziqi Gao, and Jia Li. Rethinking graph neural networks for anomaly detection. In International conference on machine learning, pages 21076–21089. PMLR, 2022
work page 2022
-
[31]
Jianheng Tang, Fengrui Hua, Ziqi Gao, Peilin Zhao, and Jia Li. Gadbench: Revisiting and benchmarking supervised graph anomaly detection.Advances in Neural Information Processing Systems, 36:29628– 29653, 2023. 11
work page 2023
-
[32]
Petar Veliˇckovi´c, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Lio, and Yoshua Bengio. Graph attention networks.arXiv preprint arXiv:1710.10903, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[33]
Duncan J. Watts and Steven H. Strogatz. Collective dynamics of ‘small-world’ networks.Nature, 393 (6684):440–442, 1998. doi: 10.1038/30918
-
[34]
Mark Weber, Giacomo Domeniconi, Jie Chen, Daniel Karl I Weidele, Claudio Bellei, Tom Robinson, and Charles E Leiserson. Anti-money laundering in bitcoin: Experimenting with graph convolutional networks for financial forensics.arXiv preprint arXiv:1908.02591, 2019
-
[35]
Chunjing Xiao, Shikang Pang, Xovee Xu, Xuan Li, Goce Trajcevski, and Fan Zhou. Counterfactual data augmentation with denoising diffusion for graph anomaly detection.IEEE Transactions on Computational Social Systems, 11(6):7555–7567, 2024
work page 2024
-
[36]
Contrastive attributed network anomaly detection with data augmentation
Zhiming Xu, Xiao Huang, Yue Zhao, Yushun Dong, and Jundong Li. Contrastive attributed network anomaly detection with data augmentation. InPacific-Asia conference on knowledge discovery and data mining, pages 444–457. Springer, 2022
work page 2022
-
[37]
Ia-ggad: Zero-shot generalist graph anomaly detection via invariant and affinity learning
Xiong Zhang, Zhenli He, Changlong Fu, and Cheng Xie. Ia-ggad: Zero-shot generalist graph anomaly detection via invariant and affinity learning. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, volume 33, 2025
work page 2025
-
[38]
Xiong Zhang, Hong Peng, Zhenli He, Cheng Xie, Xin Jin, and Hua Jiang. Gctam: Global and contextual truncated affinity combined maximization model for unsupervised graph anomaly detection.arXiv preprint arXiv:2603.01806, 2026. 12 A Theoretical Analysis and Mathematical Properties This appendix provides a rigorous mathematical foundation for the proposed Ne...
-
[39]
Homophily Range:Performance is optimal when the homophily h∈[0.1,0.7] . In ex- tremely homophilous graphs ( h≈0.9 ), detection of Type-D anomalies degrades sub- stantially, while Type-H anomaly detection remains relatively effective but also weakens compared with moderate homophily regimes
-
[40]
Degree Constraints:For nodes with di <2 , diversity is undefined. Such nodes are assigned a neutral score, as their local organization cannot be statistically measured via second-order metrics. B Details of Experimental Setup B.1 Datasets To ensure reliable, credible experimental results, training and test datasets are selected to maximize diversity in do...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.