PermaVid: Consistent Video Generation Across Edits via Disentangled Context Memory
Pith reviewed 2026-06-27 03:20 UTC · model grok-4.3
The pith
A memory system disentangles video context into appearance and geometry to preserve consistency after edits
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
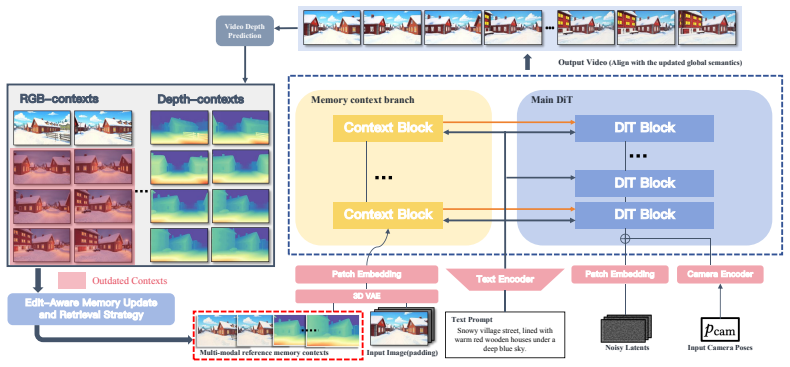
The central discovery is a multi-modal context memory that disentangles spatial context into semantic appearance captured in an RGB context memory and geometric structure in a depth context memory. An edit-aware memory update and retrieval strategy ensures memory evolution aligns with subsequent observations. This supports a memory-guided video generation model performing multi-modal feature fusion from mixed-modality contexts, leading to maintained long-term semantic and structural consistency after edits that outperforms existing methods.
What carries the argument
Disentangled multi-modal context memory with separate RGB appearance bank and depth structure bank, plus edit-aware update and retrieval strategy
If this is right
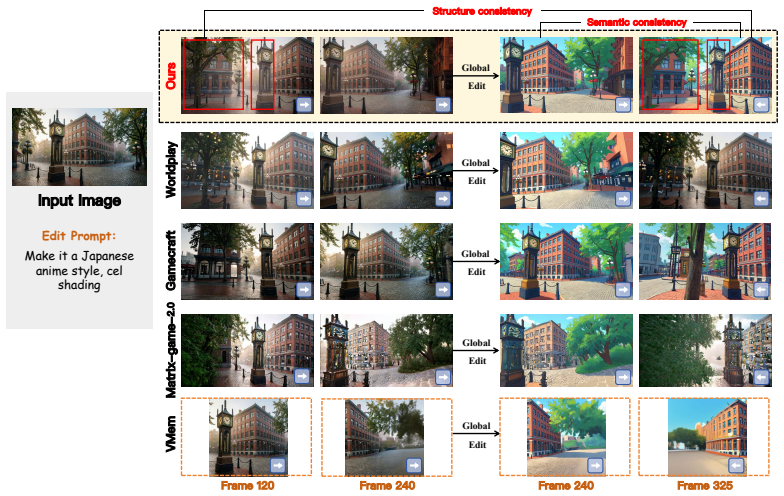
- Long-term semantic and structural consistency is maintained after edits to the scene
- Subsequent video generations remain coherent across time and viewpoints following modifications
- The method significantly outperforms state-of-the-art approaches in consistency metrics
- Memory-guided generation enables multi-modal feature fusion under reference conditions from the memory banks
Where Pith is reading between the lines
- Separating geometry from appearance could allow more robust handling of viewpoint changes in video synthesis
- The approach might apply to other domains like image editing or 3D model generation where persistent context is needed
- It implies that edit-aware memory management could reduce the accumulation of errors in autoregressive generation models
Load-bearing premise
Disentangling spatial context into separate semantic appearance and geometric structure memories with an edit-aware strategy will keep the memory aligned with observations without creating new inconsistencies or using outdated information
What would settle it
A test sequence involving multiple successive edits to a video scene followed by generation of many subsequent frames, checking if consistency holds or breaks in semantic content or geometric structure
Figures





read the original abstract
Consistent video generation under editing operations requires persistence: when edits modify scene appearance or layout, subsequent generations should remain coherent across time and viewpoints. However, existing memory designs struggle to maintain long-term consistency after such modifications, as stored contexts may become outdated or invalid. To address this, we propose PermaVid, a novel framework built upon a multi-modal context memory that disentangles spatial context into semantic appearance and geometric structure, together with an edit-aware memory update and retrieval strategy that keeps memory evolution aligned with subsequent observations. Specifically, we develop two complementary memory banks: an RGB context memory that captures appearance-aware observations while implicitly encoding geometry, and a depth context memory that preserves geometry-only structure disentangled from semantics. Building on this design, we introduce a memory-guided video generation model that performs multi-modal feature fusion under reference conditions drawn from mixed-modality memory contexts. Experiments demonstrate that our method maintains strong long-term semantic and structural consistency after edits, significantly outperforming state-of-the-art methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes PermaVid, a framework for consistent video generation under editing operations. It introduces a multi-modal context memory that disentangles spatial context into an RGB memory bank (capturing semantic appearance while implicitly encoding geometry) and a depth memory bank (preserving geometry-only structure). An edit-aware memory update and retrieval strategy is claimed to keep memory evolution aligned with subsequent observations. A memory-guided video generation model performs multi-modal feature fusion under reference conditions from the mixed-modality memories. The central claim is that this design maintains strong long-term semantic and structural consistency after edits and significantly outperforms state-of-the-art methods.
Significance. If the empirical claims hold, the work would address a practical limitation in memory-based video generation and editing pipelines, where stored contexts become outdated after appearance or layout changes. The disentangled RGB/depth design and edit-aware strategy represent a targeted architectural contribution to long-term consistency, which could influence downstream applications in video synthesis if supported by rigorous validation.
major comments (2)
- [Abstract] Abstract: The central claim that 'Experiments demonstrate that our method maintains strong long-term semantic and structural consistency after edits, significantly outperforming state-of-the-art methods' is asserted without any quantitative metrics, baselines, ablation results, or experiment details. This is load-bearing for the primary contribution, as the soundness of the consistency claim cannot be evaluated from the provided description alone.
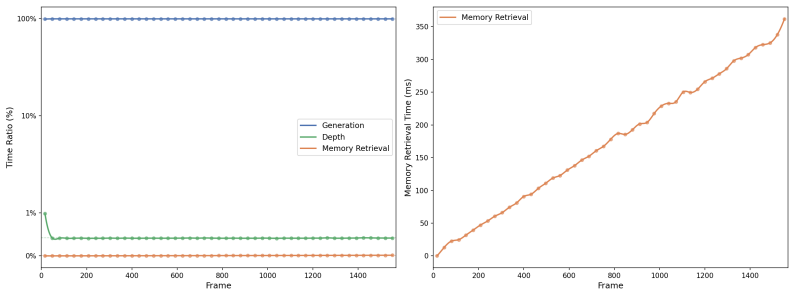
- [Method] Method description (disentangled memory banks and edit-aware update): The update and retrieval strategy is described at a high level as keeping 'memory evolution aligned with subsequent observations,' but no equations, pseudocode, or explicit rules are supplied for how pre-edit geometry is invalidated in the depth bank or how appearance drift is prevented in the RGB bank after layout edits. Without these details, it is not possible to verify that the design avoids the exact inconsistencies the paper aims to solve.
minor comments (1)
- [Abstract] The abstract refers to 'multi-modal feature fusion under reference conditions drawn from mixed-modality memory contexts' without clarifying the fusion mechanism or reference conditioning implementation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below, indicating where revisions will be made to strengthen the presentation.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'Experiments demonstrate that our method maintains strong long-term semantic and structural consistency after edits, significantly outperforming state-of-the-art methods' is asserted without any quantitative metrics, baselines, ablation results, or experiment details. This is load-bearing for the primary contribution, as the soundness of the consistency claim cannot be evaluated from the provided description alone.
Authors: Abstracts conventionally summarize key outcomes at a high level without embedding full metrics or experimental details, which are instead reported in the dedicated Experiments section. The full manuscript contains quantitative evaluations, baseline comparisons, and ablations that support the claim. We can expand the abstract slightly to reference the primary metrics if the editor deems it necessary. revision: partial
-
Referee: [Method] Method description (disentangled memory banks and edit-aware update): The update and retrieval strategy is described at a high level as keeping 'memory evolution aligned with subsequent observations,' but no equations, pseudocode, or explicit rules are supplied for how pre-edit geometry is invalidated in the depth bank or how appearance drift is prevented in the RGB bank after layout edits. Without these details, it is not possible to verify that the design avoids the exact inconsistencies the paper aims to solve.
Authors: We agree that the method description requires greater specificity. The revised manuscript will incorporate explicit equations and pseudocode for the edit-aware update and retrieval procedures, detailing the invalidation of pre-edit geometry in the depth bank and the mechanisms to prevent appearance drift in the RGB bank. revision: yes
Circularity Check
No circularity: novel design proposal with no derivation chain
full rationale
The paper presents PermaVid as a new architectural framework consisting of disentangled RGB/depth memory banks plus an edit-aware update/retrieval strategy. No equations, fitted parameters, predictions, or derivation steps appear in the abstract or description. The central claim rests on the proposed design and experimental outcomes rather than any reduction to prior fitted quantities, self-citations, or self-definitional constructs. This is a standard case of an independent design contribution with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Video generation models as world simulators
Tim Brooks, Bill Peebles, Connor Holmes, Will DePue, Yufei Guo, Li Jing, David Schnurr, Joe Taylor, Troy Luhman, Eric Luhman, et al. Video generation models as world simulators. OpenAI Blog, 1(8):1, 2024
2024
-
[2]
Relic: Interactive video world model with long-horizon memory.arXiv preprint arXiv:2512.04040, 2025
Yicong Hong, Yiqun Mei, Chongjian Ge, Yiran Xu, Yang Zhou, Sai Bi, Yannick Hold-Geoffroy, Mike Roberts, Matthew Fisher, Eli Shechtman, et al. Relic: Interactive video world model with long-horizon memory.arXiv preprint arXiv:2512.04040, 2025
arXiv 2025
-
[3]
Wenqiang Sun, Haiyu Zhang, Haoyuan Wang, Junta Wu, Zehan Wang, Zhenwei Wang, Yunhong Wang, Jun Zhang, Tengfei Wang, and Chunchao Guo. Worldplay: Towards long-term geometric consistency for real-time interactive world modeling.arXiv preprint arXiv:2512.14614, 2025
Pith/arXiv arXiv 2025
-
[4]
Video world models with long-term spatial memory.arXiv preprint arXiv:2506.05284, 2025
Tong Wu, Shuai Yang, Ryan Po, Yinghao Xu, Ziwei Liu, Dahua Lin, and Gordon Wetzstein. Video world models with long-term spatial memory.arXiv preprint arXiv:2506.05284, 2025
arXiv 2025
-
[5]
Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
Pith/arXiv arXiv 2025
-
[6]
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiaohan Zhang, Guanyu Feng, et al. Cogvideox: Text-to-video diffusion models with an expert transformer.arXiv preprint arXiv:2408.06072, 2024
Pith/arXiv arXiv 2024
-
[7]
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, et al. Hunyuanvideo: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603, 2024
Pith/arXiv arXiv 2024
-
[8]
Jing Tan, Shuai Yang, Tong Wu, Jingwen He, Yuwei Guo, Ziwei Liu, and Dahua Lin. Imagine360: Immersive 360 video generation from perspective anchor.arXiv preprint arXiv:2412.03552, 2024
arXiv 2024
-
[9]
Ltx-video: Realtime video latent diffusion.arXiv preprint arXiv:2501.00103, 2024
Yoav HaCohen, Nisan Chiprut, Benny Brazowski, Daniel Shalem, Dudu Moshe, Eitan Richard- son, Eran Levin, Guy Shiran, Nir Zabari, Ori Gordon, et al. Ltx-video: Realtime video latent diffusion.arXiv preprint arXiv:2501.00103, 2024
Pith/arXiv arXiv 2024
-
[10]
Hao He, Yinghao Xu, Yuwei Guo, Gordon Wetzstein, Bo Dai, Hongsheng Li, and Ceyuan Yang. Cameractrl: Enabling camera control for text-to-video generation.arXiv preprint arXiv:2404.02101, 2024
Pith/arXiv arXiv 2024
-
[11]
Gen3c: 3d-informed world- consistent video generation with precise camera control
Xuanchi Ren, Tianchang Shen, Jiahui Huang, Huan Ling, Yifan Lu, Merlin Nimier-David, Thomas Müller, Alexander Keller, Sanja Fidler, and Jun Gao. Gen3c: 3d-informed world- consistent video generation with precise camera control. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025
2025
-
[12]
Layerpano3d: Layered 3d panorama for hyper-immersive scene generation
Shuai Yang, Jing Tan, Mengchen Zhang, Tong Wu, Gordon Wetzstein, Ziwei Liu, and Dahua Lin. Layerpano3d: Layered 3d panorama for hyper-immersive scene generation. InProceedings of the special interest group on computer graphics and interactive techniques conference conference papers, pages 1–10, 2025
2025
-
[13]
Jiwen Yu, Jianhong Bai, Yiran Qin, Quande Liu, Xintao Wang, Pengfei Wan, Di Zhang, and Xihui Liu. Context as memory: Scene-consistent interactive long video generation with memory retrieval.arXiv preprint arXiv:2506.03141, 2025
arXiv 2025
-
[14]
Worldmem: Long-term consistent world simulation with memory.arXiv preprint arXiv:2504.12369, 2025
Zeqi Xiao, Yushi Lan, Yifan Zhou, Wenqi Ouyang, Shuai Yang, Yanhong Zeng, and Xin- gang Pan. Worldmem: Long-term consistent world simulation with memory.arXiv preprint arXiv:2504.12369, 2025
arXiv 2025
-
[15]
Runjia Li, Philip Torr, Andrea Vedaldi, and Tomas Jakab. Vmem: Consistent interactive video scene generation with surfel-indexed view memory.arXiv preprint arXiv:2506.18903, 2025
arXiv 2025
-
[16]
Lvmin Zhang, Shengqu Cai, Muyang Li, Chong Zeng, Beijia Lu, Anyi Rao, Song Han, Gordon Wetzstein, and Maneesh Agrawala. Pretraining frame preservation in autoregressive video memory compression.arXiv preprint arXiv:2512.23851, 2025. 10
Pith/arXiv arXiv 2025
-
[17]
Frame context packing and drift prevention in next-frame-prediction video diffusion models
Lvmin Zhang, Shengqu Cai, Muyang Li, Gordon Wetzstein, and Maneesh Agrawala. Frame context packing and drift prevention in next-frame-prediction video diffusion models. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[18]
Corgi: Cached memory guided video generation
Xindi Wu, Uriel Singer, Zhaojiang Lin, Andrea Madotto, Xide Xia, Yifan Xu, Paul Crook, Xin Luna Dong, and Seungwhan Moon. Corgi: Cached memory guided video generation. In2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 4585–4594. IEEE, 2025
2025
-
[19]
Qingyan Bai, Qiuyu Wang, Hao Ouyang, Yue Yu, Hanlin Wang, Wen Wang, Ka Leong Cheng, Shuailei Ma, Yanhong Zeng, Zichen Liu, et al. Scaling instruction-based video editing with a high-quality synthetic dataset.arXiv preprint arXiv:2510.15742, 2025
arXiv 2025
-
[20]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 4195–4205, 2023
2023
-
[21]
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text-conditional image generation with clip latents.arXiv preprint arXiv:2204.06125, 1(2):3, 2022
Pith/arXiv arXiv 2022
-
[22]
High- resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High- resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022
2022
-
[23]
Make-a-video: Text-to-video generation without text-video data
Uriel Singer, Adam Polyak, Thomas Hayes, Xi Yin, Jie An, Songyang Zhang, Qiyuan Hu, Harry Yang, Oron Ashual, Oran Gafni, et al. Make-a-video: Text-to-video generation without text-video data. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[24]
Haonan Qiu, Menghan Xia, Yong Zhang, Yingqing He, Xintao Wang, Ying Shan, and Ziwei Liu. Freenoise: Tuning-free longer video diffusion via noise rescheduling.arXiv preprint arXiv:2310.15169, 2023
arXiv 2023
-
[25]
Xingyao Li, Fengzhuo Zhang, Jiachun Pan, Yunlong Hou, Vincent YF Tan, and Zhuoran Yang. Enhancing multi-text long video generation consistency without tuning: Time-frequency analysis, prompt alignment, and theory.arXiv preprint arXiv:2412.17254, 2024
arXiv 2024
-
[26]
The devil is in the prompts: Retrieval-augmented prompt optimization for text-to-video generation
Bingjie Gao, Xinyu Gao, Xiaoxue Wu, Yujie Zhou, Yu Qiao, Li Niu, Xinyuan Chen, and Yaohui Wang. The devil is in the prompts: Retrieval-augmented prompt optimization for text-to-video generation. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 3173–3183, 2025
2025
-
[27]
Vista: A test-time self-improving video generation agent.arXiv preprint arXiv:2510.15831, 2025
Do Xuan Long, Xingchen Wan, Hootan Nakhost, Chen-Yu Lee, Tomas Pfister, and Ser- can Ö Arık. Vista: A test-time self-improving video generation agent.arXiv preprint arXiv:2510.15831, 2025
arXiv 2025
-
[28]
Modelscope text-to-video technical report.arXiv preprint arXiv:2308.06571, 2023
Jiuniu Wang, Hangjie Yuan, Dayou Chen, Yingya Zhang, Xiang Wang, and Shiwei Zhang. Modelscope text-to-video technical report.arXiv preprint arXiv:2308.06571, 2023
Pith/arXiv arXiv 2023
-
[29]
Yuwei Guo, Ceyuan Yang, Anyi Rao, Zhengyang Liang, Yaohui Wang, Yu Qiao, Maneesh Agrawala, Dahua Lin, and Bo Dai. Animatediff: Animate your personalized text-to-image diffusion models without specific tuning.arXiv preprint arXiv:2307.04725, 2023
Pith/arXiv arXiv 2023
-
[30]
Latte: Latent diffusion transformer for video generation.arXiv preprint arXiv:2401.03048, 2024
Xin Ma, Yaohui Wang, Xinyuan Chen, Gengyun Jia, Ziwei Liu, Yuan-Fang Li, Cunjian Chen, and Yu Qiao. Latte: Latent diffusion transformer for video generation.arXiv preprint arXiv:2401.03048, 2024
Pith/arXiv arXiv 2024
-
[31]
Diffusion forcing: Next-token prediction meets full-sequence diffusion.Advances in Neural Information Processing Systems, 37:24081–24125, 2024
Boyuan Chen, Diego Martí Monsó, Yilun Du, Max Simchowitz, Russ Tedrake, and Vincent Sitzmann. Diffusion forcing: Next-token prediction meets full-sequence diffusion.Advances in Neural Information Processing Systems, 37:24081–24125, 2024
2024
-
[32]
Streamingt2v: Consistent, dynamic, and extendable long video generation from text
Roberto Henschel, Levon Khachatryan, Hayk Poghosyan, Daniil Hayrapetyan, Vahram Tade- vosyan, Zhangyang Wang, Shant Navasardyan, and Humphrey Shi. Streamingt2v: Consistent, dynamic, and extendable long video generation from text. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 2568–2577, 2025. 11
2025
-
[33]
Jiaqi Li, Junshu Tang, Zhiyong Xu, Longhuang Wu, Yuan Zhou, Shuai Shao, Tianbao Yu, Zhiguo Cao, and Qinglin Lu. Hunyuan-gamecraft: High-dynamic interactive game video generation with hybrid history condition.arXiv preprint arXiv:2506.17201, 2025
arXiv 2025
-
[34]
Yume: An interactive world generation model.arXiv preprint arXiv:2507.17744, 2025
Xiaofeng Mao, Shaoheng Lin, Zhen Li, Chuanhao Li, Wenshuo Peng, Tong He, Jiangmiao Pang, Mingmin Chi, Yu Qiao, and Kaipeng Zhang. Yume: An interactive world generation model.arXiv preprint arXiv:2507.17744, 2025
arXiv 2025
-
[35]
Cambrian-s: Towards spatial supersensing in video
Shusheng Yang, Jihan Yang, Pinzhi Huang, Ellis Brown, Zihao Yang, Yue Yu, Shengbang Tong, Zihan Zheng, Yifan Xu, Muhan Wang, et al. Cambrian-s: Towards spatial supersensing in video. arXiv preprint arXiv:2511.04670, 2025
Pith/arXiv arXiv 2025
-
[36]
Vace: All-in-one video creation and editing.arXiv preprint arXiv:2503.07598, 2025
Zeyinzi Jiang, Zhen Han, Chaojie Mao, Jingfeng Zhang, Yulin Pan, and Yu Liu. Vace: All-in-one video creation and editing.arXiv preprint arXiv:2503.07598, 2025
Pith/arXiv arXiv 2025
-
[37]
Sekai: A video dataset towards world exploration
Zhen Li, Chuanhao Li, Xiaofeng Mao, Shaoheng Lin, Ming Li, Shitian Zhao, Zhaopan Xu, Xinyue Li, Yukang Feng, Jianwen Sun, et al. Sekai: A video dataset towards world exploration. arXiv preprint arXiv:2506.15675, 2025
arXiv 2025
-
[38]
Jiahao Wang, Yufeng Yuan, Rujie Zheng, Youtian Lin, Jian Gao, Lin-Zhuo Chen, Yajie Bao, Yi Zhang, Chang Zeng, Yanxi Zhou, et al. Spatialvid: A large-scale video dataset with spatial annotations.arXiv preprint arXiv:2509.09676, 2025
arXiv 2025
-
[39]
Dec 2017
Nigel Spivey.Epic Games, page 250–263. Dec 2017
2017
-
[40]
Unrealzoo: Enriching photo-realistic virtual worlds for embodied ai
Fangwei Zhong, Kui Wu, Churan Wang, Hao Chen, Hai Ci, Zhoujun Li, and Yizhou Wang. Unrealzoo: Enriching photo-realistic virtual worlds for embodied ai. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 5769–5779, 2025
2025
-
[41]
Qwen3-vl technical report, 2025
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Junyang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shixuan ...
2025
-
[42]
Video depth anything: Consistent depth estimation for super-long videos
Sili Chen, Hengkai Guo, Shengnan Zhu, Feihu Zhang, Zilong Huang, Jiashi Feng, and Bingyi Kang. Video depth anything: Consistent depth estimation for super-long videos. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 22831–22840, 2025
2025
-
[43]
Xianglong He, Chunli Peng, Zexiang Liu, Boyang Wang, Yifan Zhang, Qi Cui, Fei Kang, Biao Jiang, Mengyin An, Yangyang Ren, et al. Matrix-game 2.0: An open-source real-time and streaming interactive world model.arXiv preprint arXiv:2508.13009, 2025
Pith/arXiv arXiv 2025
-
[44]
Qwen-image technical report.arXiv preprint arXiv:2508.02324, 2025
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng-ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, et al. Qwen-image technical report.arXiv preprint arXiv:2508.02324, 2025
Pith/arXiv arXiv 2025
-
[45]
Vbench: Comprehensive benchmark suite for video generative models
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, et al. Vbench: Comprehensive benchmark suite for video generative models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21807–21818, 2024
2024
-
[46]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PMLR, 2021. 12 Local Edits Edit Prompt: Remove fallen leaves from ...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.