Breaking the Tokenizer Barrier: On-Policy Distillation across Model Families
Pith reviewed 2026-06-27 16:59 UTC · model grok-4.3
The pith
A token-mapping algorithm lets on-policy distillation transfer probability signals across LLMs that use different tokenizers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
On-policy distillation can be made to operate across model families by means of a precise token-mapping algorithm that propagates high-fidelity token-level signals from teacher to student despite mismatched tokenizers, yielding more compute-efficient training than supervised fine-tuning on teacher responses.
What carries the argument
The precise token-mapping algorithm that aligns probability distributions between mismatched tokenizers so the standard on-policy distillation loss remains applicable.
If this is right
- Any pair of models from different families can now serve as teacher and student for on-policy distillation.
- The method preserves richer knowledge than supervised fine-tuning because the full probability distribution is used rather than sampled text.
- Distillation runs become more sample-efficient on standard benchmarks.
- Post-training pipelines no longer need to restrict teacher selection to models sharing the student's tokenizer.
Where Pith is reading between the lines
- The technique may allow distillation from closed-source models whose tokenizers are not publicly documented, provided only the mapping can be recovered.
- Similar mapping steps could be tested on other distribution-matching objectives such as preference optimization or reinforcement learning from human feedback.
- If the mapping proves robust, tokenizer standardization across the field may become less necessary.
Load-bearing premise
The mapping between tokenizers can be performed without substantial loss or distortion of the teacher's probability information.
What would settle it
A controlled comparison in which cross-tokenizer on-policy distillation produces equal or lower benchmark scores than supervised fine-tuning on the same teacher responses would falsify the efficiency claim.
Figures

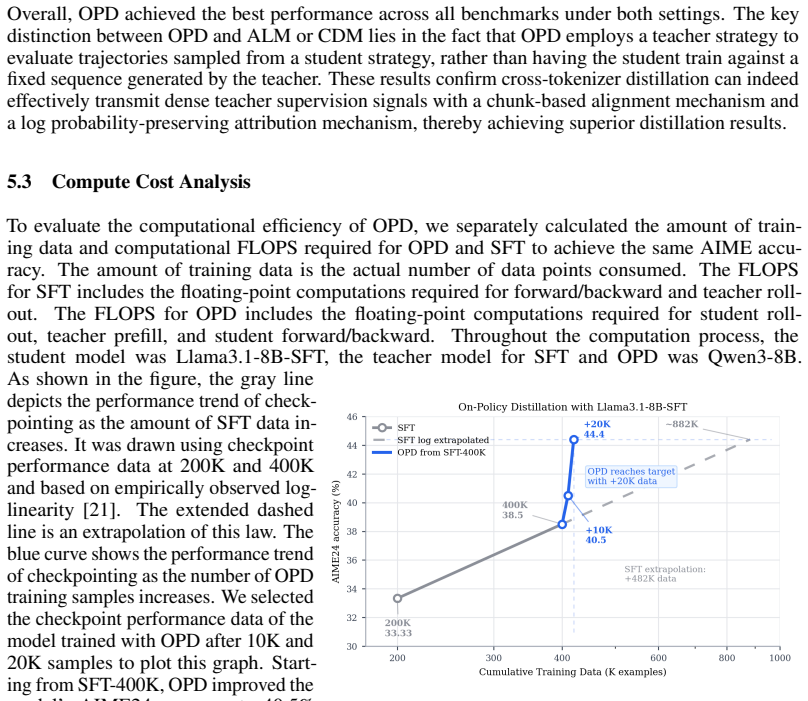
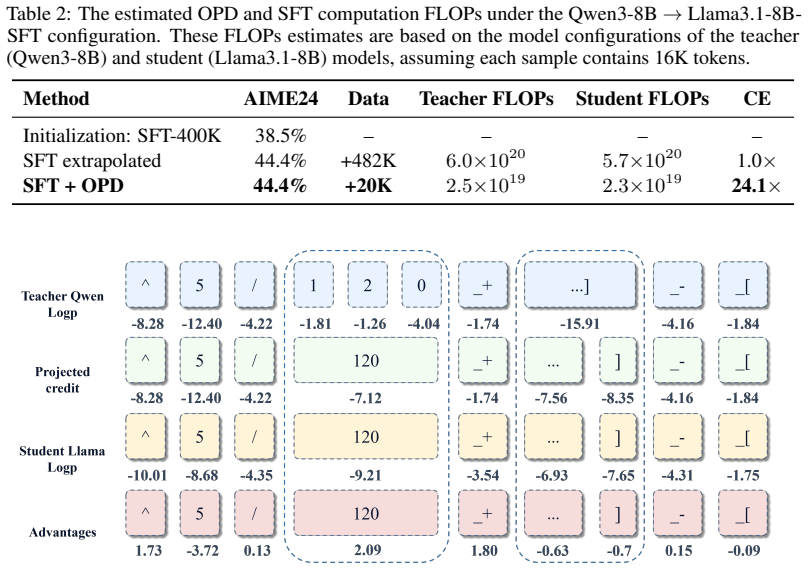
read the original abstract
On-Policy Distillation (OPD) has become a core technique in the post-training of Large Language Models (LLMs) for transferring knowledge from domain experts to student models. However, existing OPD distillation methods require teacher and student models to share the same tokenizer, restricting the applicability of OPD within the model series. Current mainstream practice typically employs Supervised Fine-Tuning (SFT) on teacher-generated responses for cross-tokenizer distillation, which fails to capture the rich knowledge embedded in the teacher's probability distribution. In this work, we enable the standard on-policy distillation method to operate across model families, ensuring that high-fidelity token-level signals can propagate across different tokenizers with a precise token-mapping algorithm. Extensive experiments show that cross-tokenizer OPD is significantly more compute-efficient than baselines on various benchmarks. Our results unlock a broader range of teacher-student pairs for OPD, opening up new avenues for adapting and enhancing interactions between LLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to extend standard on-policy distillation (OPD) to teacher-student LLM pairs with mismatched tokenizers via a precise token-mapping algorithm that propagates high-fidelity token-level probability signals. It positions this as superior to SFT-based cross-tokenizer distillation in compute efficiency, with supporting experiments on various benchmarks.
Significance. If the mapping demonstrably preserves the relative likelihoods required by OPD without substantial distortion, the result would meaningfully expand the set of usable teacher-student pairs for post-training, reducing reliance on same-tokenizer constraints and potentially improving efficiency over SFT baselines.
major comments (3)
- [§3.2] §3.2 (Token-Mapping Algorithm): The procedure for handling non-overlapping vocabularies (one-to-many or many-to-one mappings) is not shown to preserve the relative ordering or normalized probabilities that determine the on-policy advantage signal. Without an explicit aggregation rule (e.g., sum, max, or renormalized split) and a verification that the mapped distribution yields the same KL term or advantage estimate as the original teacher, the central claim that 'high-fidelity token-level signals can propagate' remains unverified.
- [§4.3, Table 3] §4.3, Table 3 (Efficiency comparison): The reported compute savings versus SFT baselines are attributed to cross-tokenizer OPD, yet no ablation isolates the contribution of the mapping fidelity versus other factors (e.g., on-policy sampling schedule). If the mapping introduces even moderate distortion, the efficiency claim cannot be cleanly attributed to the proposed algorithm.
- [§5] §5 (Discussion): The manuscript does not address whether the mapping is invertible or measure-preserving in the limit of vocabulary mismatch; a counter-example or bound showing that the expected distillation loss remains within ε of the same-tokenizer case would be required to support the 'precise' qualifier.
minor comments (2)
- Notation for mapped probability vectors is introduced without a clear definition of the aggregation operator; a short appendix equation would improve readability.
- Figure 2 caption does not state the tokenizer pair used for the visualized mapping; adding this detail would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major point below, clarifying the token-mapping procedure and indicating revisions that will be incorporated to strengthen the theoretical grounding and experimental controls.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Token-Mapping Algorithm): The procedure for handling non-overlapping vocabularies (one-to-many or many-to-one mappings) is not shown to preserve the relative ordering or normalized probabilities that determine the on-policy advantage signal. Without an explicit aggregation rule (e.g., sum, max, or renormalized split) and a verification that the mapped distribution yields the same KL term or advantage estimate as the original teacher, the central claim that 'high-fidelity token-level signals can propagate' remains unverified.
Authors: Section 3.2 presents the token-mapping algorithm via exact string-based alignment of tokens across vocabularies. For many-to-one mappings we aggregate by summing the teacher probabilities; for one-to-many mappings we split the probability mass uniformly over the aligned subtokens and renormalize. This construction ensures the mapped distribution is a valid probability distribution whose total mass equals the original. We will revise §3.2 to state the aggregation rules explicitly and add a short verification subsection that reports the KL divergence between the original and mapped teacher distributions on a held-out set, confirming that the on-policy advantage estimates remain consistent within a small tolerance. revision: yes
-
Referee: [§4.3, Table 3] §4.3, Table 3 (Efficiency comparison): The reported compute savings versus SFT baselines are attributed to cross-tokenizer OPD, yet no ablation isolates the contribution of the mapping fidelity versus other factors (e.g., on-policy sampling schedule). If the mapping introduces even moderate distortion, the efficiency claim cannot be cleanly attributed to the proposed algorithm.
Authors: The efficiency gains in Table 3 are measured under identical on-policy sampling schedules and the same number of gradient steps; the only variable is the use of the mapped teacher distribution versus SFT targets. Nevertheless, we agree that an explicit ablation isolating mapping fidelity would strengthen attribution. We will add a controlled ablation in §4.3 that replaces our mapping with a random token alignment while keeping the sampling schedule fixed, demonstrating that performance degrades substantially under the random mapping and thereby confirming that the reported savings derive from the fidelity of the proposed mapping. revision: yes
-
Referee: [§5] §5 (Discussion): The manuscript does not address whether the mapping is invertible or measure-preserving in the limit of vocabulary mismatch; a counter-example or bound showing that the expected distillation loss remains within ε of the same-tokenizer case would be required to support the 'precise' qualifier.
Authors: Section 5 currently focuses on empirical outcomes. We will expand the discussion to note that the mapping is not invertible in general because of vocabulary asymmetry, but that probability mass is preserved by construction. We will also include a brief analytic bound showing that the expected increase in distillation loss is at most proportional to the maximum number of subtokens per original token, which remains small for typical tokenizer pairs. This addition will directly address the request for a measure-preserving argument. revision: yes
Circularity Check
No circularity: method described without equations, fits, or self-citation chains
full rationale
The provided abstract and description introduce a token-mapping algorithm for cross-tokenizer OPD but contain no equations, parameter fits, derivations, or citations. The central claim is an engineering extension of existing OPD; no step reduces by construction to its own inputs or prior self-citations. This is the common case of a self-contained descriptive paper with no detectable circularity in the given text.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
On-policy distillation of language models: Learning from self- generated mistakes, 2024
Rishabh Agarwal, Nino Vieillard, Yongchao Zhou, Piotr Stanczyk, Sabela Ramos, Matthieu Geist, and Olivier Bachem. On-policy distillation of language models: Learning from self- generated mistakes, 2024
2024
-
[2]
Towards cross- tokenizer distillation: the universal logit distillation loss for llms, 2025
Nicolas Boizard, Kevin El Haddad, Céline Hudelot, and Pierre Colombo. Towards cross- tokenizer distillation: the universal logit distillation loss for llms, 2025
2025
-
[3]
Self-play fine-tuning converts weak language models to strong language models, 2024
Zixiang Chen, Yihe Deng, Huizhuo Yuan, Kaixuan Ji, and Quanquan Gu. Self-play fine-tuning converts weak language models to strong language models, 2024
2024
-
[4]
Multi-level optimal transport for universal cross-tokenizer knowledge distillation on language models, 2025
Xiao Cui, Mo Zhu, Yulei Qin, Liang Xie, Wengang Zhou, and Houqiang Li. Multi-level optimal transport for universal cross-tokenizer knowledge distillation on language models, 2025
2025
-
[5]
Glm-5: from vibe coding to agentic engineering, 2026
GLM-5-Team, Aohan Zeng, Xin Lv, et al. Glm-5: from vibe coding to agentic engineering, 2026
2026
-
[6]
The llama 3 herd of models, 2024
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, et al. The llama 3 herd of models, 2024. 9
2024
-
[7]
Minillm: On-policy distillation of large language models, 2026
Yuxian Gu, Li Dong, Furu Wei, and Minlie Huang. Minillm: On-policy distillation of large language models, 2026
2026
-
[8]
Merrill, Tatsunori Hashimoto, Yejin Choi, Jenia Jitsev, Reinhard Heckel, Maheswaran Sathiamoorthy, Alexandros G
Etash Guha, Ryan Marten, Sedrick Keh, Negin Raoof, Georgios Smyrnis, Hritik Bansal, Marianna Nezhurina, Jean Mercat, Trung Vu, Zayne Sprague, Ashima Suvarna, Benjamin Feuer, Liangyu Chen, Zaid Khan, Eric Frankel, Sachin Grover, Caroline Choi, Niklas Muennighoff, Shiye Su, Wanjia Zhao, John Yang, Shreyas Pimpalgaonkar, Kartik Sharma, Charlie Cheng-Jie Ji, ...
2025
-
[9]
Deepseek-r1 incentivizes reasoning in llms through reinforcement learning.Nature, 645(8081):633–638, 2025
Daya Guo, Dejian Yang, Haowei Zhang, et al. Deepseek-r1 incentivizes reasoning in llms through reinforcement learning.Nature, 645(8081):633–638, 2025
2025
-
[10]
Deepmath-103k: A large-scale, challenging, decontaminated, and verifiable mathematical dataset for advancing reasoning, 2025
Zhiwei He, Tian Liang, Jiahao Xu, Qiuzhi Liu, Xingyu Chen, Yue Wang, Linfeng Song, Dian Yu, Zhenwen Liang, Wenxuan Wang, Zhuosheng Zhang, Rui Wang, Zhaopeng Tu, Haitao Mi, and Dong Yu. Deepmath-103k: A large-scale, challenging, decontaminated, and verifiable mathematical dataset for advancing reasoning, 2025
2025
-
[11]
Measuring mathematical problem solving with the math dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset. NeurIPS, 2021
2021
-
[12]
Reinforcement learning via self-distillation, 2026
Jonas Hübotter, Frederike Lübeck, Lejs Behric, Anton Baumann, Marco Bagatella, Daniel Marta, Ido Hakimi, Idan Shenfeld, Thomas Kleine Buening, Carlos Guestrin, and Andreas Krause. Reinforcement learning via self-distillation, 2026
2026
-
[13]
Livecodebench: Holistic and contamination free evaluation of large language models for code, 2024
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Ar- mando Solar-Lezama, Koushik Sen, and Ion Stoica. Livecodebench: Holistic and contamination free evaluation of large language models for code, 2024
2024
-
[14]
Tinybert: Distilling bert for natural language understanding, 2020
Xiaoqi Jiao, Yichun Yin, Lifeng Shang, Xin Jiang, Xiao Chen, Linlin Li, Fang Wang, and Qun Liu. Tinybert: Distilling bert for natural language understanding, 2020
2020
-
[15]
Todi: Token-wise distilla- tion via fine-grained divergence control, 2025
Seongryong Jung, Suwan Yoon, DongGeon Kim, and Hwanhee Lee. Todi: Token-wise distilla- tion via fine-grained divergence control, 2025
2025
-
[16]
Why does self-distillation (sometimes) degrade the reasoning capability of llms?, 2026
Jeonghye Kim, Xufang Luo, Minbeom Kim, Sangmook Lee, Dohyung Kim, Jiwon Jeon, Dongsheng Li, and Yuqing Yang. Why does self-distillation (sometimes) degrade the reasoning capability of llms?, 2026
2026
-
[17]
Distillm-2: A contrastive approach boosts the distillation of llms, 2025
Jongwoo Ko, Tianyi Chen, Sungnyun Kim, Tianyu Ding, Luming Liang, Ilya Zharkov, and Se-Young Yun. Distillm-2: A contrastive approach boosts the distillation of llms, 2025
2025
-
[18]
Distillm: Towards streamlined distillation for large language models, 2024
Jongwoo Ko, Sungnyun Kim, Tianyi Chen, and Se-Young Yun. Distillm: Towards streamlined distillation for large language models, 2024
2024
-
[19]
Sentencepiece: A simple and language independent subword tokenizer and detokenizer for neural text processing, 2018
Taku Kudo and John Richardson. Sentencepiece: A simple and language independent subword tokenizer and detokenizer for neural text processing, 2018
2018
-
[20]
Contextual distillation model for diversified recommendation
Fan Li, Xu Si, Shisong Tang, Dingmin Wang, Kunyan Han, Bing Han, Guorui Zhou, Yang Song, and Hechang Chen. Contextual distillation model for diversified recommendation. In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, KDD ’24, page 5307–5316. ACM, August 2024
2024
-
[21]
On-policy distillation.Thinking Machines Lab: Connec- tionism, 2025
Kevin Lu and Thinking Machines Lab. On-policy distillation.Thinking Machines Lab: Connec- tionism, 2025. https://thinkingmachines.ai/blog/on-policy-distillation
2025
-
[22]
Universal cross-tokenizer distilla- tion via approximate likelihood matching, 2025
Benjamin Minixhofer, Ivan Vuli´c, and Edoardo Maria Ponti. Universal cross-tokenizer distilla- tion via approximate likelihood matching, 2025. 10
2025
-
[23]
Efficient transformers with dynamic token pooling
Piotr Nawrot, Jan Chorowski, Adrian Lancucki, and Edoardo Maria Ponti. Efficient transformers with dynamic token pooling. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), page 6403–6417. Association for Computational Linguistics, 2023
2023
-
[24]
Byte latent transformer: Patches scale better than tokens, 2024
Artidoro Pagnoni, Ram Pasunuru, Pedro Rodriguez, John Nguyen, Benjamin Muller, Margaret Li, Chunting Zhou, Lili Yu, Jason Weston, Luke Zettlemoyer, Gargi Ghosh, Mike Lewis, Ari Holtzman, and Srinivasan Iyer. Byte latent transformer: Patches scale better than tokens, 2024
2024
-
[25]
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R. Bowman. Gpqa: A graduate-level google-proof q&a benchmark, 2023
2023
-
[26]
Neural machine translation of rare words with subword units, 2016
Rico Sennrich, Barry Haddow, and Alexandra Birch. Neural machine translation of rare words with subword units, 2016
2016
-
[27]
Hybridflow: A flexible and efficient rlhf framework.arXiv preprint arXiv: 2409.19256, 2024
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. Hybridflow: A flexible and efficient rlhf framework.arXiv preprint arXiv: 2409.19256, 2024
Pith/arXiv arXiv 2024
-
[28]
Cross-tokenizer llm distillation through a byte-level interface, 2026
Avyav Kumar Singh, Yen-Chen Wu, Alexandru Cioba, Alberto Bernacchia, and Davide Buffelli. Cross-tokenizer llm distillation through a byte-level interface, 2026
2026
-
[29]
A survey of on-policy distillation for large language models, 2026
Mingyang Song and Mao Zheng. A survey of on-policy distillation for large language models, 2026
2026
-
[30]
Mimo-v2-flash technical report, 2026
Core Team, Bangjun Xiao, Bingquan Xia, et al. Mimo-v2-flash technical report, 2026
2026
-
[31]
Qwq-32b: Embracing the power of reinforcement learning, March 2025
Qwen Team. Qwq-32b: Embracing the power of reinforcement learning, March 2025
2025
-
[32]
Minilm: Deep self-attention distillation for task-agnostic compression of pre-trained transformers, 2020
Wenhui Wang, Furu Wei, Li Dong, Hangbo Bao, Nan Yang, and Ming Zhou. Minilm: Deep self-attention distillation for task-agnostic compression of pre-trained transformers, 2020
2020
-
[33]
Kdrl: Post-training reasoning llms via unified knowledge distillation and reinforcement learning, 2025
Hongling Xu, Qi Zhu, Heyuan Deng, Jinpeng Li, Lu Hou, Yasheng Wang, Lifeng Shang, Ruifeng Xu, and Fei Mi. Kdrl: Post-training reasoning llms via unified knowledge distillation and reinforcement learning, 2025
2025
-
[34]
Paced: Distillation and on-policy self-distillation at the frontier of student competence, 2026
Yuanda Xu, Hejian Sang, Zhengze Zhou, Ran He, and Zhipeng Wang. Paced: Distillation and on-policy self-distillation at the frontier of student competence, 2026
2026
-
[35]
Byt5: Towards a token-free future with pre-trained byte-to-byte models, 2022
Linting Xue, Aditya Barua, Noah Constant, Rami Al-Rfou, Sharan Narang, Mihir Kale, Adam Roberts, and Colin Raffel. Byt5: Towards a token-free future with pre-trained byte-to-byte models, 2022
2022
-
[36]
Qwen3 technical report, 2025
An Yang, Anfeng Li, Baosong Yang, et al. Qwen3 technical report, 2025
2025
-
[37]
Learning beyond teacher: Generalized on-policy distillation with reward extrapolation, 2026
Wenkai Yang, Weijie Liu, Ruobing Xie, Kai Yang, Saiyong Yang, and Yankai Lin. Learning beyond teacher: Generalized on-policy distillation with reward extrapolation, 2026
2026
-
[38]
Aligndistil: Token-level language model alignment as adaptive policy distillation, 2025
Songming Zhang, Xue Zhang, Tong Zhang, Bojie Hu, Yufeng Chen, and Jinan Xu. Aligndistil: Token-level language model alignment as adaptive policy distillation, 2025
2025
-
[39]
American invitational mathematics examination (aime) 2026, 2026
Yifan Zhang and Team Math-AI. American invitational mathematics examination (aime) 2026, 2026
2026
-
[40]
Self-distilled reasoner: On-policy self-distillation for large language models, 2026
Siyan Zhao, Zhihui Xie, Mengchen Liu, Jing Huang, Guan Pang, Feiyu Chen, and Aditya Grover. Self-distilled reasoner: On-policy self-distillation for large language models, 2026
2026
-
[41]
Llamafactory: Unified efficient fine-tuning of 100+ language models, 2024
Yaowei Zheng, Richong Zhang, Junhao Zhang, Yanhan Ye, Zheyan Luo, Zhangchi Feng, and Yongqiang Ma. Llamafactory: Unified efficient fine-tuning of 100+ language models, 2024
2024
-
[42]
A formal perspective on byte-pair encoding, 2024
Vilém Zouhar, Clara Meister, Juan Luis Gastaldi, Li Du, Tim Vieira, Mrinmaya Sachan, and Ryan Cotterell. A formal perspective on byte-pair encoding, 2024. 11 A Details of Experimental Setups Table 4: Main training hyperparameters used for SFT initialization and subsequent OPD training. Hyperparameter SFT OPD Training framework LLaMA-Factory VeRL Teacher–s...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.