PashtoTTS-Bench: automated screening for low-resource non-Latin-script text-to-speech
Pith reviewed 2026-06-29 18:41 UTC · model grok-4.3
The pith
The INSV framework separates intelligibility, script fidelity, and language identification for automated Pashto TTS screening beyond single WER.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
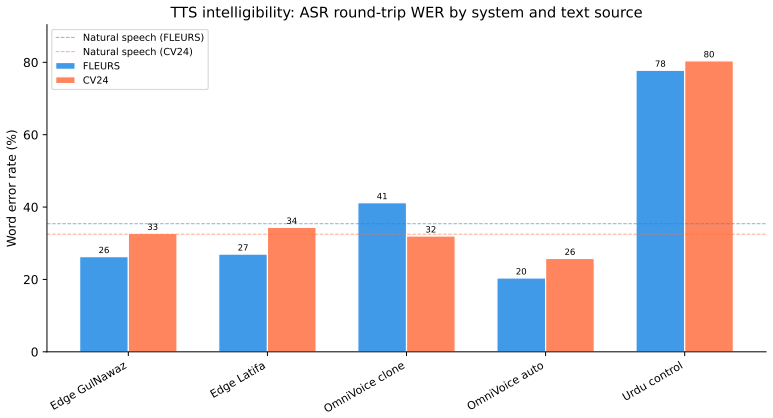
We introduce INSV (Intelligibility, Naturalness, Script fidelity, and Verification), a reporting framework that separates these cases. This paper reports INSV-A, the automated screening subset: synthesis completion, ASR WER/CER, transcript Script Fidelity Rate, and audio language identification. Native MOS and phonetic annotation are specified but not claimed in this release. We instantiate INSV-A as PashtoTTS-Bench, a dated benchmark for Pashto TTS. The April-May 2026 run evaluates Edge GulNawaz, Edge Latifa, OmniVoice clone, OmniVoice auto, and an Urdu negative control on 200 FLEURS and 200 filtered Common Voice 24 prompts.
What carries the argument
INSV-A, the automated screening subset of the INSV framework that combines synthesis completion, ASR WER/CER, transcript Script Fidelity Rate, and audio language identification via independent models.
If this is right
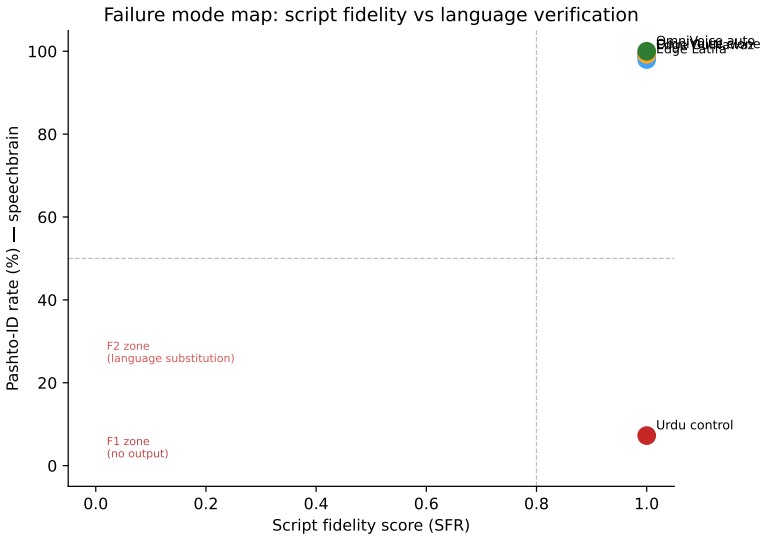
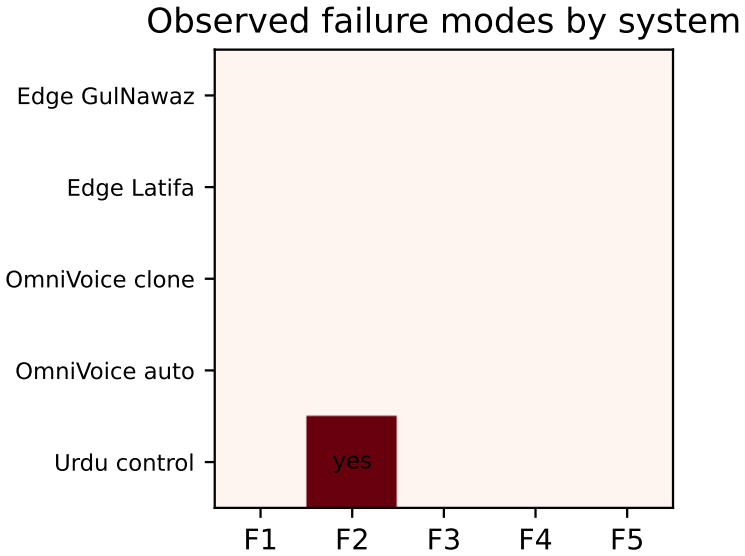
- Different systems exhibit distinct failure modes that separate metrics can detect, such as low WER but zero Pashto LID labels.
- Whisper Large V3 returns 0.0% Pashto labels on checked Pashto TTS audio while MMS-LID-4017 and SpeechBrain VoxLingua107 separate Pashto outputs from the Urdu control.
- WER below the natural-speech baseline reflects clean synthetic audio and should not be read as better than native speech.
- The benchmark release supplies provider metadata, per-sentence scores, LID audits, failure logs, and scripts for adding new systems.
Where Pith is reading between the lines
- The same INSV-A checks could be rerun on later model versions to track whether improvements in one metric affect others.
- Extending the benchmark to additional non-Latin low-resource languages would test whether the framework generalizes beyond Pashto.
- The separation of metrics makes it possible to prioritize development effort on the weakest dimension for each system.
Load-bearing premise
The independent omniASR_CTC_300M_v2, Whisper Large V3, MMS-LID-4017, and SpeechBrain VoxLingua107 models provide reliable signals for Pashto-specific intelligibility, script fidelity, and language identification without systematic bias on synthetic audio.
What would settle it
A set of human native listener ratings on the same audio that reverses the automated WER and LID rankings or shows high mismatch with the Script Fidelity Rate.
Figures
read the original abstract
Text-to-speech (TTS) evaluation for low-resource non-Latin-script languages can fail when it relies on a single ASR round-trip word error rate (WER). A system may produce no audio, speak a neighbouring language, preserve target script text only in an ASR transcript, or sound unnatural to native listeners. We introduce INSV (Intelligibility, Naturalness, Script fidelity, and Verification), a reporting framework that separates these cases. This paper reports INSV-A, the automated screening subset: synthesis completion, ASR WER/CER, transcript Script Fidelity Rate, and audio language identification. Native MOS and phonetic annotation are specified but not claimed in this release. We instantiate INSV-A as PashtoTTS-Bench, a dated benchmark for Pashto TTS. The April-May 2026 run evaluates Edge GulNawaz, Edge Latifa, OmniVoice clone, OmniVoice auto, and an Urdu negative control on 200 FLEURS and 200 filtered Common Voice 24 prompts. Under the independent omniASR_CTC_300M_v2, OmniVoice auto has the lowest WER (24.1% FLEURS, 27.4% CV24), followed by Edge GulNawaz (32.8%, 39.5%), Edge Latifa (35.6%, 47.7%), and OmniVoice clone (45.4%, 34.8%). WER below the natural-speech baseline reflects clean synthetic audio and should not be read as better than native speech. Whisper Large V3 returns 0.0% Pashto labels on checked Pashto TTS audio, while MMS-LID-4017 and SpeechBrain VoxLingua107 separate Pashto outputs from the Urdu control. The release provides provider metadata, per-sentence scores, LID audits, failure logs, and scripts for adding systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the INSV-A automated screening subset of the INSV framework for TTS evaluation in low-resource non-Latin-script languages. It instantiates PashtoTTS-Bench on five systems (Edge GulNawaz, Edge Latifa, OmniVoice clone/auto, Urdu control) using 400 prompts, reporting synthesis completion, WER/CER from omniASR_CTC_300M_v2 (e.g., 24.1%/27.4% for OmniVoice auto on FLEURS/CV24), transcript Script Fidelity Rate, and LID outcomes from Whisper Large V3 (0% Pashto), MMS-LID-4017, and SpeechBrain VoxLingua107, while releasing per-sentence scores, metadata, failure logs, and addition scripts.
Significance. If the chosen ASR and LID models yield low-bias signals on Pashto synthetic audio, INSV-A supplies a practical, reproducible automated benchmark that separates synthesis failure modes without requiring native listeners; this is valuable for low-resource TTS research. The explicit release of scripts, per-sentence data, and provider metadata strengthens reproducibility and extensibility.
major comments (3)
- [Abstract] Abstract (results reporting paragraph): The WER ordering and LID separation are presented as direct evidence supporting INSV-A utility, yet no Pashto-specific validation, calibration on real Pashto speech, or error analysis of omniASR_CTC_300M_v2, Whisper Large V3, MMS-LID-4017, or SpeechBrain VoxLingua107 on synthetic audio is reported. This assumption is load-bearing for interpreting all numerical claims, as the models were likely trained with minimal Pashto data and Whisper already returns 0% Pashto labels on the evaluated audio.
- [Abstract] Abstract (results reporting paragraph): No error bars, confidence intervals, or statistical tests accompany the WER/CER figures (e.g., 24.1%, 32.8%, 35.6%, 45.4%), so the reported differences between systems cannot be assessed for reliability or robustness to prompt sampling variation.
- [Abstract] Abstract: The prompt filtering procedure for the 200 Common Voice 24 items and any ablation of ASR model choice are not described, leaving the robustness of the INSV-A scores and the cross-system comparisons dependent on unstated selection criteria.
minor comments (2)
- [Abstract] Abstract: The exact definition and computation of 'transcript Script Fidelity Rate' is not illustrated with an example or formula, which would clarify how it contributes to case separation in INSV-A.
- The manuscript would benefit from a summary table listing each INSV-A component, the model(s) used, and the intended failure mode it detects.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report recommending major revision. We address each major comment point by point below.
read point-by-point responses
-
Referee: [Abstract] Abstract (results reporting paragraph): The WER ordering and LID separation are presented as direct evidence supporting INSV-A utility, yet no Pashto-specific validation, calibration on real Pashto speech, or error analysis of omniASR_CTC_300M_v2, Whisper Large V3, MMS-LID-4017, or SpeechBrain VoxLingua107 on synthetic audio is reported. This assumption is load-bearing for interpreting all numerical claims, as the models were likely trained with minimal Pashto data and Whisper already returns 0% Pashto labels on the evaluated audio.
Authors: We agree this is a substantive limitation: the manuscript provides no dedicated Pashto validation set or error analysis for the proxy ASR/LID models on synthetic audio. INSV-A is explicitly positioned as an automated screening framework that uses off-the-shelf models to separate failure modes (no audio, wrong language, script mismatch) without native listeners; the 0 % Whisper Pashto label is reported precisely to surface one such limitation rather than to claim model reliability. The per-sentence scores and failure logs are released to enable exactly the calibration the referee requests. We will add a limitations subsection that states the low-resource training data issue for all four models and notes that native validation remains future work. This is a partial revision. revision: partial
-
Referee: [Abstract] Abstract (results reporting paragraph): No error bars, confidence intervals, or statistical tests accompany the WER/CER figures (e.g., 24.1%, 32.8%, 35.6%, 45.4%), so the reported differences between systems cannot be assessed for reliability or robustness to prompt sampling variation.
Authors: We accept the point. The current release reports point estimates only. In the revised manuscript we will add bootstrap confidence intervals (1,000 resamples) for all WER/CER values and a brief statement on sampling robustness. revision: yes
-
Referee: [Abstract] Abstract: The prompt filtering procedure for the 200 Common Voice 24 items and any ablation of ASR model choice are not described, leaving the robustness of the INSV-A scores and the cross-system comparisons dependent on unstated selection criteria.
Authors: The filtering criteria (utterance length, automatic language verification, and removal of low-quality or code-switched items) appear in the methods section of the full manuscript, but the abstract does not repeat them. We will move a concise description of the Common Voice filtering procedure into the abstract and add a short paragraph on ASR model selection rationale. No ablation of ASR choice was performed; we will state this explicitly. revision: yes
Circularity Check
No circularity: direct empirical measurements on external models
full rationale
The paper defines INSV-A as a reporting framework and instantiates it via straightforward application of independent external models (omniASR_CTC_300M_v2, Whisper Large V3, MMS-LID-4017, SpeechBrain VoxLingua107) to compute WER/CER, script fidelity rate, and LID labels on TTS outputs. No equations, fitted parameters, predictions, or derivations are present. No self-citations are invoked as load-bearing premises. All reported numbers are direct outputs from the cited off-the-shelf models; the framework itself is a taxonomy of measurement categories rather than a derived result. This matches the default case of self-contained empirical benchmarking against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Selected ASR and LID models (omniASR_CTC_300M_v2, Whisper Large V3, MMS-LID-4017, SpeechBrain VoxLingua107) produce reliable Pashto-specific signals on synthetic audio.
Reference graph
Works this paper leans on
-
[1]
Automatic speech recognition for under-resourced languages: A survey
Besacier, L., Barnard, E., Karpov, A., Schultz, T., 2014. Automatic speech recognition for under-resourced languages: A survey. Speech Communi- cation 56, 85–100. doi: 10.1016/j.specom.2013.07.008 . foundational low-resource ASR survey; most directly analogous prior survey to this pa- per
-
[2]
Conneau, A., Ma, M., Khanuja, S., Zhang, Y., Axelrod, V., Dalmia, S., Riesa, J., Rivera, C., Bapna, A., 2023. FLEURS: Few-shot learning evaluation of universal representations of speech, in: 2022 IEEE Spoken Language Tech- nology Workshop (SLT), pp. 798–805. URL: https://doi.org/10.1109/ SLT54892.2023.10023141, doi:10.1109/SLT54892.2023.10023141
-
[3]
The zero resource speech challenge 2021: Spoken language modelling, in: Interspeech 2021, pp
Dunbar, E., Bernard, M., Hamilakis, N., Nguyen, T.A., de Seyssel, M., Rozé, P., Rivière, M., Kharitonov, E., Dupoux, E., 2021. The zero resource speech challenge 2021: Spoken language modelling, in: Interspeech 2021, pp. 1574–
2021
-
[4]
URL: https://doi.org/10.21437/Interspeech.2021-1755 , doi:10.21437/Interspeech.2021-1755
-
[5]
Dunbar, E., Cao, X.N., Benjumea, J., Karadayi, J., Bernard, M., Besacier, L., Anguera, X., Dupoux, E., 2017. The zero resource speech challenge 2017, in: 2017 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), pp. 323–330. URL: https://doi.org/10.1109/ASRU.2017.82 68953, doi:10.1109/ASRU.2017.8268953. 32
-
[6]
VoiceMOS challenge 2022, in: Interspeech 2022, pp
Huang, W.C., Cooper, E., Tsao, Y., Wang, H.M., Toda, T., Yamagishi, J., 2022. VoiceMOS challenge 2022, in: Interspeech 2022, pp. 4536–4540. URL: http s://doi.org/10.21437/Interspeech.2022-970, doi:10.21437/Inter speech.2022-970
-
[7]
Recommendation P.800: Methods for subjective determination of transmission quality
ITU-T, 1996. Recommendation P.800: Methods for subjective determination of transmission quality. URL: https://www.itu.int/rec/T-REC-P.800 -199608-I. international Telecommunication Union, in force
1996
-
[8]
Recommendation P.808: Subjective evaluation of speech qual- ity with a crowdsourcing approach
ITU-T, 2021. Recommendation P.808: Subjective evaluation of speech qual- ity with a crowdsourcing approach. URL: https://www.itu.int/itu-t /recommendations/rec.aspx?rec=P.808 . international Telecommuni- cation Union, in force
2021
-
[9]
Omnilingual asr: Open-source multilingual speech recognition for 1600+ languages,
Keren, G., Kozhevnikov, A., Meng, Y., Ropers, C., Setzler, M., Wang, S., Adebara, I., Auli, M., Balioglu, C., Chan, K., Cheng, C., Chuang, J., Droof, C., Duppenthaler, M., Duquenne, P.A., Erben, A., Gao, C., Gonzalez, G.M., Lyu, K., Miglani, S., Pratap, V., Sadagopan, K.R., Saleem, S., Turkatenko, A., Ventayol-Boada, A., Yong, Z.X., Chung, Y.A., Maillard,...
-
[10]
Multilingual spoken words corpus
Mazumder, M., Chitlangia, S., Banbury, C., Kang, Y., Ciro, J., Achorn, K., Galvez, D., Sabini, M., Mattson, P., Kanter, D., Diamos, G., Warden, P., Meyer, J., Janapa Reddi, V., 2021. Multilingual spoken words corpus. Pro- ceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks. URL: https://datasets-benchmarks-proceedings .n...
2021
-
[11]
Orthography and phonemes in Pashto (Afghan)
Penzl, H., 1954. Orthography and phonemes in Pashto (Afghan). Journal of the American Oriental Society 74, 74–81. URL: https://doi.org/10.2 307/596206, doi:10.2307/596206
-
[12]
The blizzard challenge 2014, in: The Blizzard Challenge 2014, pp
Prahallad, K., Vadapalli, A., Kesiraju, S., Murthy, H.A., Lata, S., Nagarajan, T., Prasanna, M., Patil, H., Sao, A.K., King, S., Black, A.W., Tokuda, K., 2014. The blizzard challenge 2014, in: The Blizzard Challenge 2014, pp. 1–14. URL: https://doi.org/10.21437/Blizzard.2014-1 , doi:10.21437/Blizz ard.2014-1. 33
-
[13]
Scaling speech technology to 1,000+ languages
Pratap, V., Tjandra, A., Shi, B., Tomasello, P., Babu, A., Kundu, S., Elkahky, A., Ni, Z., Vyas, A., Fazel-Zarandi, M., Baevski, A., Adi, Y., Zhang, X., Hsu, W.N., Conneau, A., Auli, M., 2024. Scaling speech technology to 1,000+ languages. Journal of Machine Learning Research 25, 1–52. URL: https: //jmlr.org/papers/v25/23-1318.html . includes the MMS-LID-...
2024
-
[14]
Radford, A., Kim, J.W., Xu, T., Brockman, G., McLeavey, C., Sutskever, I.,
-
[15]
Robust speech recognition via large-scale weak supervision, in: Pro- ceedings of the 40th International Conference on Machine Learning, PMLR. pp. 28492–28518. URL: https://proceedings.mlr.press/v202/radfo rd23a.html
-
[16]
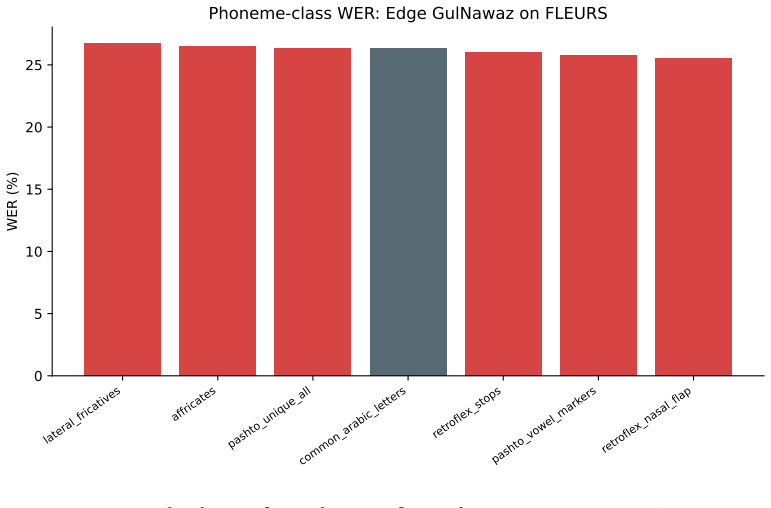
Rahman, H., 2026a. Benchmarking multilingual speech models on Pashto: Zero-shot ASR, script failure, and cross-domain evaluation. arXiv preprint arXiv:2604.04598. URL: https://arxiv.org/abs/2604.04598 . 10 mod- els zero-shot + 5 fine-tuned cross-domain; script failure audit; phoneme- class WER; companion benchmark to this survey
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Script collapse in multilingual ASR: A reference-free metric and 100-pair benchmark
Rahman, H., 2026b. Script collapse in multilingual ASR: A reference- free metric and 100-pair benchmark. arXiv preprint arXiv:2604.08786. URL: https://arxiv.org/abs/2604.08786 . script Fidelity Rate metric; 6 languages x 9 models on FLEURS; package at github.com/the- mechanism/script-fidelity-metric
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
ihanif/pashto-asr-v3: W2V-BERT 2.0 fine-tuned for Pashto ASR
Rahman, H.u., 2024. ihanif/pashto-asr-v3: W2V-BERT 2.0 fine-tuned for Pashto ASR. https://huggingface.co/ihanif/pashto-asr-v3 . Fine- tuned from facebook/w2v-bert-2.0 (600M parameters; CTC decoder); trained on FLEURS Pashto training split; published WER 13.96%; model weights publicly available on HuggingFace Hub
2024
-
[19]
SpeechBrain: A general- purpose speech toolkit
Ravanelli, M., Parcollet, T., Plantinga, P., Rouhe, A., Cornell, S., Lu- gosch, L., Subakan, C., Dawalatabad, N., Heba, A., Zhong, J., Chou, J.C., Yeh, S.L., Fu, S.W., Liao, C.F., Rastorgueva, E., Grondin, F., Aris, W., Na, H., Gao, Y., De Mori, R., Bengio, Y., 2021. SpeechBrain: A general- purpose speech toolkit. URL: https://arxiv.org/abs/2106.04624 , a...
-
[20]
Saeki, T., Xin, D., Nakata, W., Koriyama, T., Takamichi, S., Saruwatari, H.,
-
[21]
UTMOS: Utokyo-sarulab system for voicemos challenge 2022, in: In- 34 terspeech 2022, pp. 4521–4525. URL: https://doi.org/10.21437/Int erspeech.2022-439, doi:10.21437/Interspeech.2022-439
-
[22]
Mean opinion score (mos) re- visited: Methods and applications, limitations and alternatives
Streijl, R.C., Winkler, S., Hands, D.S., 2016. Mean opinion score (mos) re- visited: Methods and applications, limitations and alternatives. Multimedia Systems 22, 213–227. URL: https://doi.org/10.1007/s00530-014-0 446-1, doi:10.1007/s00530-014-0446-1
-
[23]
Confidence intervals for ASR-based TTS evaluation, in: Interspeech 2021, pp
Taylor, J., Richmond, K., 2021. Confidence intervals for ASR-based TTS evaluation, in: Interspeech 2021, pp. 2791–2795. URL: https://doi.org/ 10.21437/Interspeech.2021-2203 , doi:10.21437/Interspeech.202 1-2203
-
[24]
A Reference Grammar of Pashto
Tegey, H., Robson, B., 1996. A Reference Grammar of Pashto. Center for Applied Linguistics, Washington, D.C. Foundational Pashto grammar; phoneme inventory; morphology
1996
-
[25]
Valk, J., Alumäe, T., 2021. VoxLingua107: a dataset for spoken language recognition, in: Proceedings of the IEEE Spoken Language Technology Workshop (SLT), pp. 652–658. doi: 10.1109/SLT48900.2021.9383459 . 107-language YouTube-scraped corpus; XLS-R uses this as one of five pre- training data sources. Supplementary material §A: MOS rater instructions Engli...
-
[26]
You may replay once if unsure
Listen to the recording once before rating. You may replay once if unsure
-
[27]
Rate the recording using the 1–5 scale
-
[28]
Answer whether the clip is Pashto speech: yes, no, or unsure
-
[29]
Do not go back and change previous ratings
Work through the recordings in order. Do not go back and change previous ratings
-
[30]
If the recording is silent or in a language other than Pashto, rate it 1. Pashto version ॴధ ൌ৭ ߓߵﺍߓߵّ۬ ܔިﺉ.݁۬ ﺩࡇﻩ ﺩ ل؇݁أٷ؇ﺩ ﻭﺭܔިﺉ.݁۬ﺩﺭ ྵ ޗٴ٭ ޗٴ٭ ଫଃ༚ ଫଃ༚ ﺩﯼؗ ेू ཇ ﻭﺭ ቕሹ ࢻࣖܳިﺉ.݁۬ﺩﺭ ﻭٙ؇ 36 Rater demographics The published summary must report rater count, L1 status, dialect back- ground, age range (when consented), gender breakdown (when consented), col-...
-
[31]
Add a provider implementation with four methods: synthesize, supports_pashto, get_metadata, get_provider_name
-
[32]
Run synthesis and automated metrics on both prompt sets
-
[33]
Run multi-model LID (MMS-LID, SpeechBrain; Whisper as diagnostic only); mark disagreement as unresolved until native adjudication is collected
-
[34]
For MOS evaluation, use scripts/export\_mos\_survey.py and the rater instructions in Supplementary §A
Record per-sentence CSVs, provider metadata, run logs, and redistribution terms for generated audio. For MOS evaluation, use scripts/export\_mos\_survey.py and the rater instructions in Supplementary §A. Report rater counts, dialect metadata, and Krippendorff’s α alongside MOS means. 37 Audio integrity Commercial audio is not redistributed when provider t...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.