WHET: Welding Homomorphic Encryption to Accelerator Architectures
Pith reviewed 2026-06-27 09:43 UTC · model grok-4.3
The pith
WHET applies memory-centric transformations to shrink FHE working sets and deliver 1.38-8.74x per-area speedups plus sub-millisecond CKKS bootstrapping.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
WHET identifies conventional FHE constructions as the main sources of excessive working sets and off-chip memory traffic in accelerators. It proposes three accelerator-specific techniques—fine-grained coefficient-to-slot transformation, plaintext compression, and intermediate modulus raising—to minimize temporary ciphertexts and plaintext loads. These software changes create opportunities for lightweight hardware refinements, including a special-purpose buffer and functional-unit extensions, that together yield 1.38-8.74× per-area performance improvements over prior FHE accelerators and enable the first sub-millisecond CKKS bootstrapping.
What carries the argument
Memory-footprint reductions through coefficient-to-slot transformation, plaintext compression, and intermediate modulus raising, paired with a special-purpose on-chip buffer.
If this is right
- Per-area throughput rises between 1.38× and 8.74× compared with existing FHE accelerators.
- CKKS bootstrapping latency drops below one millisecond for the first time.
- Temporary ciphertext and plaintext loads decrease enough to keep more data on-chip.
- Specialized buffers and functional units become effective once the software data footprint shrinks.
Where Pith is reading between the lines
- The same memory-reduction pattern could be tested on other lattice-based schemes beyond CKKS.
- Future accelerator designs might allocate more area to buffers sized for compressed ciphertexts.
- Co-design of crypto primitives with hardware could be applied to other privacy mechanisms such as secure multi-party computation.
- Sub-millisecond bootstrapping may open encrypted workloads that require frequent noise refresh, such as real-time private inference.
Load-bearing premise
Conventional FHE schemes are the dominant cause of large working sets and memory traffic, and the listed transformations keep correctness and security intact when mapped to accelerators.
What would settle it
An experiment that applies the three transformations to a standard CKKS accelerator and measures either increased total on-chip data volume or a security break would falsify the central claim.
Figures


read the original abstract
Fully homomorphic encryption (FHE) enables computations on encrypted data without decryption, offering strong data privacy at the expense of substantial computational and memory overheads. Prior efforts have steadily improved FHE performance through cryptographic and algorithmic enhancements or hardware acceleration, yet these two directions have progressed largely in isolation, hindering the full exploitation of available hardware capabilities. This work presents WHET, which introduces memory-centric, architecture-aware optimizations to better align cryptographic and algorithmic constructions with FHE accelerator architectures. We identify conventional FHE constructions as major sources of excessive working sets and heavy off-chip memory traffic. We propose accelerator-specific techniques, including fine-grained coefficient-to-slot transformation, plaintext compression, and intermediate modulus raising, to reduce the on-chip data footprint by minimizing temporary ciphertexts and plaintext loads. With these techniques applied, we observe additional opportunities to improve on-chip memory efficiency; hence, we introduce lightweight architectural refinements, including a special-purpose buffer and functional unit extensions. With these optimizations, WHET achieves 1.38-8.74$\times$ per-area performance improvements over state-of-the-art FHE accelerators and the first-ever sub-millisecond CKKS bootstrapping.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents WHET, which applies memory-centric, architecture-aware optimizations to FHE accelerators. It identifies conventional FHE constructions as sources of excessive working sets and off-chip traffic, and proposes accelerator-specific techniques including fine-grained coefficient-to-slot transformation, plaintext compression, and intermediate modulus raising to minimize temporary ciphertexts and plaintext loads. These are paired with lightweight architectural refinements such as a special-purpose buffer and functional unit extensions. The claimed outcomes are 1.38-8.74× per-area performance improvements over state-of-the-art FHE accelerators and the first sub-millisecond CKKS bootstrapping.
Significance. If the results hold, the work is significant for demonstrating the value of co-design between cryptographic constructions and accelerator architectures in FHE, a domain where these efforts have largely remained separate. The explicit parameter sets, area-normalized comparisons, and focus on reducing on-chip data footprint address a key practical bottleneck. The empirical results on accelerator models with implementation-level arguments for the transformations constitute a strength.
major comments (1)
- [Evaluation] Evaluation section: while the manuscript supplies implementation-level arguments and empirical results with explicit parameter sets for the performance claims, the abstract (and any corresponding high-level summary) does not detail the evaluation methodology, baseline accelerator configurations, error bars, or verification steps for the reported speedups and sub-millisecond bootstrapping latency; this detail is load-bearing for assessing the central quantitative claims.
minor comments (2)
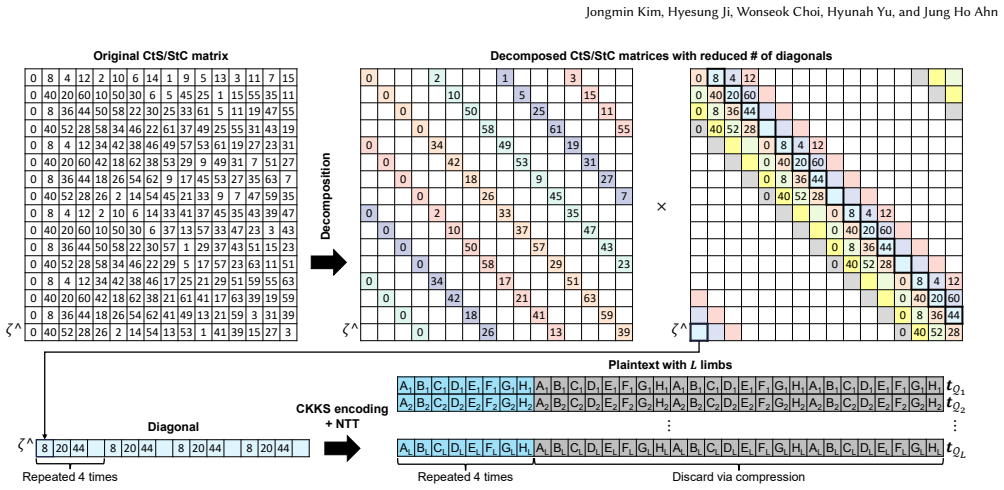
- [Optimizations] The description of the coefficient-to-slot transformation in the optimizations section would benefit from an explicit small example showing before/after data layout to clarify the fine-grained aspect.
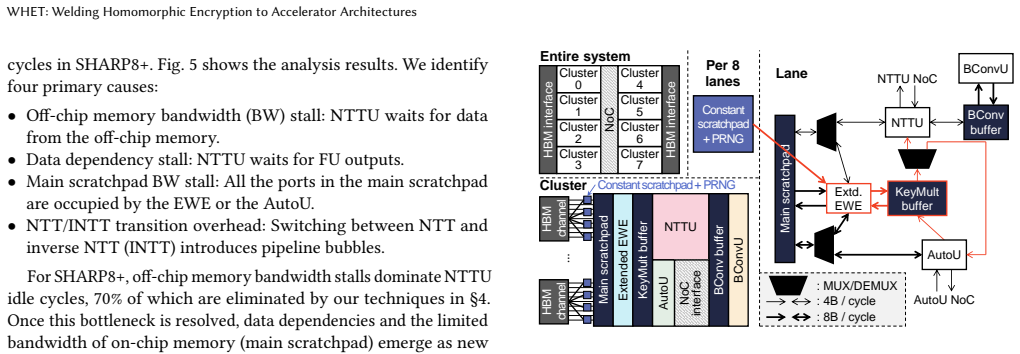
- [Architecture] Figure captions for the architectural diagrams should explicitly state the area and power models used for the per-area normalization.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive assessment of the work. We address the single major comment below.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: while the manuscript supplies implementation-level arguments and empirical results with explicit parameter sets for the performance claims, the abstract (and any corresponding high-level summary) does not detail the evaluation methodology, baseline accelerator configurations, error bars, or verification steps for the reported speedups and sub-millisecond bootstrapping latency; this detail is load-bearing for assessing the central quantitative claims.
Authors: We agree that the abstract would benefit from a concise statement of the evaluation methodology to better support the central claims. In the revised version we will expand the abstract to briefly note the accelerator models and baselines used, the explicit parameter sets, the area-normalized comparison methodology, and the verification approach (cycle-accurate simulation cross-checked against RTL-level estimates) employed for the reported speedups and sub-millisecond CKKS bootstrapping latency. The detailed evaluation section already contains these elements; the change is limited to surfacing a high-level summary in the abstract. revision: yes
Circularity Check
No significant circularity
full rationale
The manuscript describes memory-centric optimizations (coefficient-to-slot transformation, plaintext compression, intermediate modulus raising) and lightweight architectural refinements for FHE accelerators, then reports measured per-area speedups (1.38-8.74×) and sub-millisecond CKKS bootstrapping as empirical outcomes of those techniques on explicit parameter sets. No derivation chain, fitted-parameter prediction, or first-principles result is claimed; the central claims rest on implementation-level arguments and area-normalized comparisons against prior accelerators rather than any self-referential reduction or self-citation load-bearing step. The evaluation methodology is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The listed transformations preserve the homomorphic properties and security of CKKS and similar schemes
Reference graph
Works this paper leans on
-
[1]
Rashmi Agrawal, Jung Ho Ahn, Flavio Bergamaschi, Ro Cammarota, Jung Hee Cheon, Fillipe D. M. de Souza, Huijing Gong, Minsik Kang, Duhyeong Kim, Jong- min Kim, Hubert de Lassus, Jai Hyun Park, Michael Steiner, and Wen Wang. 2023. High-Precision RNS-CKKS on Fixed but Smaller Word-Size Architectures: Theory and Application. InWorkshop on Encrypted Computing ...
-
[2]
Rashmi Agrawal, Leo de Castro, Chiraag Juvekar, Anantha Chandrakasan, Vinod Vaikuntanathan, and Ajay Joshi. 2023. MAD: Memory-Aware Design Techniques for Accelerating Fully Homomorphic Encryption. InMICRO. doi:10.1145/3613424. 3614302
-
[3]
Rashmi Agrawal, Leo de Castro, Guowei Yang, Chiraag Juvekar, Rabia Yazicigil, Anantha Chandrakasan, Vinod Vaikuntanathan, and Ajay Joshi. 2023. FAB: An FPGA-based Accelerator for Bootstrappable Fully Homomorphic Encryption. In HPCA. doi:10.1109/HPCA56546.2023.10070953
-
[4]
Martin Albrecht, Melissa Chase, Hao Chen, Jintai Ding, Shafi Goldwasser, Sergey Gorbunov, Shai Halevi, Jeffrey Hoffstein, Kim Laine, Kristin Lauter, Satya Lokam, Daniele Micciancio, Dustin Moody, Travis Morrison, Amit Sahai, and Vinod Vaikuntanathan. 2021. Homomorphic Encryption Standard. InProtecting Privacy through Homomorphic Encryption. Springer, 31–6...
-
[5]
Albrecht, Rachel Player, and Sam Scott
Martin R. Albrecht, Rachel Player, and Sam Scott. 2015. On the Concrete Hardness of Learning with Errors.Journal of Mathematical Cryptology9, 3 (2015), 169–203. doi:10.1515/jmc-2015-0016
-
[6]
Jason Ansel, Edward Yang, Horace He, Natalia Gimelshein, Animesh Jain, Michael Voznesensky, Bin Bao, Peter Bell, David Berard, Evgeni Burovski, Geeta Chauhan, Anjali Chourdia, Will Constable, Alban Desmaison, Zachary DeVito, Elias Ellison, Will Feng, Jiong Gong, Michael Gschwind, Brian Hirsh, Sherlock Huang, Kshiteej Kalambarkar, Laurent Kirsch, Michael L...
-
[7]
PyTorch 2: Faster Machine Learning Through Dynamic Python Bytecode Transformation and Graph Compilation. InASPLOS. doi:10.1145/3620665.3640366
-
[8]
Apple. 2024. Combining Machine Learning and Homomorphic Encryption in the Apple Ecosystem. https://machinelearning.apple.com/research/homomorphic- encryption
2024
-
[9]
Ahmad Al Badawi and Yuriy Polyakov. 2023. Demystifying Bootstrapping in Fully Homomorphic Encryption.IACR Cryptology ePrint Archive149 (2023). https://eprint.iacr.org/2023/149
2023
-
[10]
David H. Bailey. 1989. FFTs in External or Hierarchical Memory. InACM/IEEE Conference on Supercomputing. doi:10.1145/76263.76288
-
[11]
Laszlo A. Belady. 1966. A Study of Replacement Algorithms for a Virtual-Storage Computer.IBM Systems Journal5, 2 (1966), 78–101. doi:10.1147/sj.52.0078
-
[12]
Fabian Boemer, Sejun Kim, Gelila Seifu, Fillipe D. M. de Souza, and Vinodh Gopal. 2021. Intel HEXL: Accelerating Homomorphic Encryption with Intel AVX512-IFMA52. InWorkshop on Encrypted Computing & Applied Homomorphic Cryptography. doi:10.1145/3474366.3486926
-
[13]
Jean-Philippe Bossuat, Rosario Cammarota, Jung Hee Cheon, Ilaria Chillotti, Benjamin R. Curtis, Wei Dai, Huijing Gong, Erin Hales, Duhyeong Kim, Bryan Kumara, Changmin Lee, Xianhui Lu, Carsten Maple, Alberto Pedrouzo-Ulloa, Rachel Player, Luis Antonio Ruiz Lopez, Yongsoo Song, Donggeon Yhee, and Bahattin Yildiz. 2024. Security Guidelines for Implementing ...
2024
-
[14]
Jean-Philippe Bossuat, Christian Mouchet, Juan Ramón Troncoso-Pastoriza, and Jean-Pierre Hubaux. 2021. Efficient Bootstrapping for Approximate Homo- morphic Encryption with Non-sparse Keys. InAnnual International Confer- ence on the Theory and Applications of Cryptographic Techniques (Eurocrypt). doi:10.1007/978-3-030-77870-5_21
-
[15]
Jean-Philippe Bossuat, Juan Troncoso-Pastoriza, and Jean-Pierre Hubaux. 2022. Bootstrapping for Approximate Homomorphic Encryption with Negligible Failure-Probability by Using Sparse-Secret Encapsulation. InApplied Cryptogra- phy and Network Security. doi:10.1007/978-3-031-09234-3_26
-
[16]
Jonathan Chang, Yen-Huei Chen, Wei-Min Chan, Sahil Preet Singh, Hank Cheng, Hidehiro Fujiwara, Jih-Yu Lin, Kao-Cheng Lin, John Hung, Robin Lee, Hung-Jen Liao, Jhon-Jhy Liaw, Quincy Li, Chih-Yung Lin, Mu-Chi Chiang, and Shien-Yang Wu. 2017. A 7nm 256Mb SRAM in High-K Metal-Gate FinFET Technology with Write-Assist Circuitry for Low-VMIN Applications. InIEEE...
-
[17]
Hao Chen, Ilaria Chillotti, and Yongsoo Song. 2019. Improved Bootstrapping for Approximate Homomorphic Encryption. InAnnual International Conference on the Theory and Applications of Cryptographic Techniques (Eurocrypt). doi:10. 1007/978-3-030-17656-3_2
2019
-
[18]
Xinhua Chen, Jiangbin Dong, Hongren Zheng, Tian Tang, and Mingyu Gao
-
[19]
CROPHE: Cross-Operator Dataflow Optimization for Fully Homomorphic 11 Jongmin Kim, Hyesung Ji, Wonseok Choi, Hyunah Yu, and Jung Ho Ahn Encryption Accelerators. InHPCA. doi:10.1109/HPCA68181.2026.11408486
-
[20]
Jung Hee Cheon, Hyeongmin Choe, Minsik Kang, Jaehyung Kim, Seonghak Kim, Johannes Mono, and Taeyeong Noh. 2025. Grafting: Decoupled Scale Factors and Modulus in RNS-CKKS. InACM Conference on Computer and Communications Security. doi:10.1145/3719027.3765083
-
[22]
InSelected Areas in Cryptography
A Full RNS Variant of Approximate Homomorphic Encryption. InSelected Areas in Cryptography. doi:10.1007/978-3-030-10970-7_16
-
[23]
Jung Hee Cheon, Kyoohyung Han, Andrey Kim, Miran Kim, and Yongsoo Song
-
[24]
Bootstrapping for Approximate Homomorphic Encryption. InAnnual Inter- national Conference on the Theory and Applications of Cryptographic Techniques (Eurocrypt). doi:10.1007/978-3-319-78381-9_14
-
[25]
Jung Hee Cheon, Andrey Kim, Miran Kim, and Yongsoo Song. 2017. Homo- morphic Encryption for Arithmetic of Approximate Numbers. InInternational Conference on the Theory and Applications of Cryptology and Information Security (Asiacrypt). doi:10.1007/978-3-319-70694-8_15
-
[26]
Seonyoung Cheon, Yongwoo Lee, Dongkwan Kim, Ju Min Lee, Sunchul Jung, Taekyung Kim, Dongyoon Lee, and Hanjun Kim. 2024. DaCapo: Automatic Boot- strapping Management for Efficient Fully Homomorphic Encryption. InUSENIX Security Symposium. https://www.usenix.org/conference/usenixsecurity24/ presentation/cheon
2024
-
[27]
Seonyoung Cheon, Yongwoo Lee, Hoyun Youm, Dongkwan Kim, Sungwoo Yun, Kunmo Jeong, Dongyoon Lee, and Hanjun Kim. 2025. HALO: Loop-aware Bootstrapping Management for Fully Homomorphic Encryption. InASPLOS. doi:10.1145/3669940.3707275
-
[28]
Ilaria Chillotti, Nicolas Gama, Mariya Georgieva, and Malika Izabachène. 2020. TFHE: Fast Fully Homomorphic Encryption Over the Torus.Journal of Cryptology 33, 1 (2020), 34–91. doi:10.1007/s00145-019-09319-x
-
[29]
Wonseok Choi, Jongmin Kim, and Jung Ho Ahn. 2026. Cheddar: A Swift Fully Homomorphic Encryption Library Designed for GPU Architectures. InASPLOS. doi:10.1145/3760250.3762223
-
[30]
Lawrence T Clark, Vinay Vashishtha, Lucian Shifren, Aditya Gujja, Saurabh Sinha, Brian Cline, Chandarasekaran Ramamurthy, and Greg Yeric. 2016. ASAP7: A 7-nm FinFET Predictive Process Design Kit.Microelectronics Journal53 (2016), 105–115. doi:10.1016/j.mejo.2016.04.006
-
[31]
Mathematics of Computation , year = 1965, month = jan, volume =
James W. Cooley and John W. Tukey. 1965. An Algorithm for the Machine Calculation of Complex Fourier Series.Math. Comp.19, 90 (1965), 297–301. doi:10.1090/s0025-5718-1965-0178586-1
-
[32]
William J. Dally, C. Thomas Gray, John Poulton, Brucek Khailany, John Wilson, and Larry Dennison. 2018. Hardware-Enabled Artificial Intelligence. In2018 IEEE Symposium on VLSI Circuits. doi:10.1109/VLSIC.2018.8502368
-
[33]
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. 2009. Ima- geNet: A Large-Scale Hierarchical Image Database. InIEEE Conference on Com- puter Vision and Pattern Recognition. doi:10.1109/CVPR.2009.5206848
-
[34]
Xianglong Deng, Shengyu Fan, Zhicheng Hu, Zhuoyu Tian, Zihao Yang, Jiangrui Yu, Dingyuan Cao, Dan Meng, Rui Hou, Meng Li, Qian Lou, and Mingzhe Zhang
-
[35]
Trinity: A General Purpose FHE Accelerator. InMICRO. doi:10.1109/ MICRO61859.2024.00033
arXiv 2024
-
[36]
DESILO. 2023. Liberate.FHE: A New FHE Library for Bridging the Gap between Theory and Practice with a Focus on Performance and Accuracy. https://github. com/Desilo/liberate-fhe
2023
-
[37]
Austin Ebel, Karthik Garimella, and Brandon Reagen. 2025. Orion: A Fully Homomorphic Encryption Framework for Deep Learning. InASPLOS. doi:10. 1145/3676641.3716008
arXiv 2025
-
[38]
Guang Fan, Mingzhe Zhang, Fangyu Zheng, Shengyu Fan, Tian Zhou, Xianglong Deng, Wenxu Tang, Liang Kong, Yixuan Song, and Shoumeng Yan. 2025. Warp- Drive: GPU-Based Fully Homomorphic Encryption Acceleration Leveraging Tensor and CUDA Cores. InHPCA. doi:10.1109/HPCA61900.2025.00091
-
[39]
Shengyu Fan, Xianglong Deng, Liang Kong, Guiming Shi, Guang Fan, Dan Meng, Rui Hou, and Mingzhe Zhang. 2025. FAST: An FHE Accelerator for Scalable- parallelism with Tunable-bit. InISCA. doi:10.1145/3695053.3731407
-
[40]
Shengyu Fan, Zhiwei Wang, Weizhi Xu, Rui Hou, Dan Meng, and Mingzhe Zhang
-
[41]
TensorFHE: Achieving Practical Computation on Encrypted Data Using GPGPU. InHPCA. doi:10.1109/HPCA56546.2023.10071017
-
[42]
Craig Gentry. 2009. Fully Homomorphic Encryption Using Ideal Lattices. In ACM Symposium on Theory of Computing. doi:10.1145/1536414.1536440
-
[43]
Gutierrez, Ernesto Zamora Ramos, Won- hee Cho, Jose M
Anupam Golder, Raghavan Kumar, Sachin Taneja, Kylan Race, Paolo Aseron, James Greensky, Wen Wang, Huijing Gong, Lalith Kethareswaran, Vikram Suresh, Adish Vartak, AppaRao Challagundla, Jeremy Casas, Poornima Lal- waney, Duhyeong Kim, Christopher N. Gutierrez, Ernesto Zamora Ramos, Won- hee Cho, Jose M. Rojas Chaves, Michael Steiner, Dan Lake, Nataraj Yenn...
-
[44]
Shai Halevi and Victor Shoup. 2018. Faster Homomorphic Linear Transformations in HElib. InAnnual International Cryptology Conference (CRYPTO). doi:10.1007/ 978-3-319-96884-1_4
2018
-
[45]
Kyoohyung Han, Minki Hhan, and Jung Hee Cheon. 2019. Improved Homomor- phic Discrete Fourier Transforms and FHE Bootstrapping.IEEE Access7 (2019), 57361–57370. doi:10.1109/ACCESS.2019.2913850
-
[46]
Kyoohyung Han, Seungwan Hong, Jung Hee Cheon, and Daejun Park. 2019. Lo- gistic Regression on Homomorphic Encrypted Data at Scale. InAAAI Conference on Artificial Intelligence. doi:10.1609/aaai.v33i01.33019466
-
[47]
Kyoohyung Han and Dohyeong Ki. 2020. Better Bootstrapping for Approximate Homomorphic Encryption. InCryptographers’ Track at the RSA Conference. doi:10. 1007/978-3-030-40186-3_16
2020
-
[48]
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. Deep Residual Learning for Image Recognition. InIEEE Conference on Computer Vision and Pattern Recognition. doi:10.1109/CVPR.2016.90
-
[49]
Seungwan Hong, Seunghong Kim, Jiheon Choi, Younho Lee, and Jung Hee Cheon
-
[50]
Efficient Sorting of Homomorphic Encrypted Data With k-Way Sorting Network.IEEE Transactions on Information Forensics and Security16 (2021), 4389–4404. doi:10.1109/TIFS.2021.3106167
-
[51]
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
Andrew G. Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, and Hartwig Adam. 2017. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications.arXiv preprint(2017). doi:10.48550/arXiv.1704.04861
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1704.04861 2017
-
[52]
Yi Huang, Xinsheng Gong, Xiangyu Kong, Dibei Chen, Jianfeng Zhu, Wenping Zhu, Liangwei Li, Mingyu Gao, Shaojun Wai, Aoyang Zhang, and Leibo Liu. 2025. EFFACT: A Highly Efficient Full-Stack FHE Acceleration Platform. InHPCA. doi:10.1109/HPCA61900.2025.00088
-
[53]
2018.International Roadmap for Devices and Systems: 2018
IEEE. 2018.International Roadmap for Devices and Systems: 2018. Technical Report
2018
-
[54]
Siddharth Jayashankar, Edward Chen, Tom Tang, Wenting Zheng, and Dimitrios Skarlatos. 2025. Cinnamon: A Framework for Scale-Out Encrypted AI. InASPLOS. doi:10.1145/3669940.3707260
-
[55]
Sullivan, Wenting Zheng, and Dimitrios Skarlatos
Siddharth Jayashankar, Joshua Kim, Michael B. Sullivan, Wenting Zheng, and Dimitrios Skarlatos. 2025. A Scalable Multi-GPU Framework for Encrypted Large-Model Inference.arXiv preprint(2025). doi:10.48550/arXiv.2512.11269
-
[56]
2022.High Bandwidth Memory DRAM (HBM3)
JEDEC. 2022.High Bandwidth Memory DRAM (HBM3). Technical Report JESD238
2022
-
[57]
2025.High Bandwidth Memory (HBM4) DRAM
JEDEC. 2025.High Bandwidth Memory (HBM4) DRAM. Technical Report JESD270- 4
2025
-
[58]
W.C. Jeong, S. Maeda, H.J. Lee, K.W. Lee, T.J. Lee, D.W. Park, B.S. Kim, J.H. Do, T. Fukai, D.J. Kwon, K.J. Nam, W.J. Rim, M.S. Jang, H.T. Kim, Y.W. Lee, J.S. Park, E.C. Lee, D.W. Ha, C.H. Park, H.J. Cho, S.M. Jung, and H.K. Kang. 2018. True 7nm Platform Technology featuring Smallest FinFET and Smallest SRAM cell by EUV, Special Constructs and 3rd Generat...
-
[59]
Dian Jiao, Xianglong Deng, Zhiwei Wang, Shengyu Fan, Yi Chen, Dan Meng, Rui Hou, and Mingzhe Zhang. 2025. Neo: Towards Efficient Fully Homomorphic En- cryption Acceleration using Tensor Core. InISCA. doi:10.1145/3695053.3731408
-
[60]
Jouppi, Doe Hyun Yoon, Matthew Ashcraft, Mark Gottscho, Thomas B
Norman P. Jouppi, Doe Hyun Yoon, Matthew Ashcraft, Mark Gottscho, Thomas B. Jablin, George Kurian, James Laudon, Sheng Li, Peter C. Ma, Xiaoyu Ma, Thomas Norrie, Nishant Patil, Sushma Prasad, Cliff Young, Zongwei Zhou, and David A. Patterson. 2021. Ten Lessons From Three Generations Shaped Google’s TPUv4i: Industrial Product. InISCA. doi:10.1109/ISCA52012...
-
[61]
Jae Hyung Ju, Jaiyoung Park, Jongmin Kim, Minsik Kang, Donghwan Kim, Jung Hee Cheon, and Jung Ho Ahn. 2024. NeuJeans: Private Neural Network Inference with Joint Optimization of Convolution and FHE Bootstrapping. In ACM Conference on Computer and Communications Security. doi:10.1145/3658644. 3690375
-
[62]
Wonkyung Jung, Sangpyo Kim, Jung Ho Ahn, Jung Hee Cheon, and Younho Lee
-
[63]
Over 100x Faster Bootstrapping in Fully Homomorphic Encryption through Memory-centric Optimization with GPUs.IACR Transactions on Cryptographic Hardware and Embedded Systems2021, 4 (2021), 114–148. doi:10.46586/tches. v2021.i4.114-148
-
[64]
Wonkyung Jung, Eojin Lee, Sangpyo Kim, Jongmin Kim, Namhoon Kim, Keewoo Lee, Chohong Min, Jung Hee Cheon, and Jung Ho Ahn. 2021. Accelerating Fully Homomorphic Encryption Through Architecture-Centric Analysis and Optimization.IEEE Access9 (2021), 98772–98789. doi:10.1109/ACCESS.2021. 3096189
-
[65]
Mayank Kabra, Rakesh Nadig, Harshita Gupta, Rahul Bera, Manos Frouzakis, Vamanan Arulchelvan, Yu Liang, Haiyu Mao, Mohammad Sadrosadati, and Onur Mutlu. 2025. CIPHERMATCH: Accelerating Homomorphic Encryption-Based String Matching via Memory-Efficient Data Packing and In-Flash Processing. In ASPLOS. doi:10.1145/3676641.3716251
-
[66]
Dongwoo Kim and Cyril Guyot. 2023. Optimized Privacy-Preserving CNN Inference With Fully Homomorphic Encryption.IEEE Transactions on Information Forensics and Security18 (2023), 2175–2187. doi:10.1109/TIFS.2023.3263631 12 WHET: Welding Homomorphic Encryption to Accelerator Architectures
-
[67]
Donghwan Kim, Jaiyoung Park, Jongmin Kim, Sangpyo Kim, and Jung Ho Ahn
-
[68]
doi:10.1109/ACCESS.2023.3348170
HyPHEN: A Hybrid Packing Method and Its Optimizations for Homo- morphic Encryption-Based Neural Networks.IEEE Access12 (2024), 3024–3038. doi:10.1109/ACCESS.2023.3348170
-
[69]
Jihwan Kim, Jung Hee Cheon, and Yongdong Yeo. 2025. OverModRaise: Reduc- ing Modulus Consumption of CKKS Bootstrapping.IACR Communications in Cryptology2, 3 (2025). doi:10.62056/a3n5qjp10
-
[70]
Jongmin Kim, Sangpyo Kim, Jaewan Choi, Jaiyoung Park, Donghwan Kim, and Jung Ho Ahn. 2023. SHARP: A Short-Word Hierarchical Accelerator for Robust and Practical Fully Homomorphic Encryption. InISCA. doi:10.1145/3579371. 3589053
-
[71]
Jongmin Kim, Gwangho Lee, Sangpyo Kim, Gina Sohn, Minsoo Rhu, John Kim, and Jung Ho Ahn. 2022. ARK: Fully Homomorphic Encryption Accelerator with Runtime Data Generation and Inter-Operation Key Reuse. InMICRO. doi:10. 1109/MICRO56248.2022.00086
arXiv 2022
-
[72]
Jongmin Kim, Sungmin Yun, Hyesung Ji, Wonseok Choi, Sangpyo Kim, and Jung Ho Ahn. 2025. Anaheim: Architecture and Algorithms for Processing Fully Homomorphic Encryption in Memory. InHPCA. doi:10.1109/HPCA61900.2025. 00089
-
[73]
Miran Kim, Dongwon Lee, Jinyeong Seo, and Yongsoo Song. 2023. Accelerating HE Operations from Key Decomposition Technique. InAnnual International Cryptology Conference (CRYPTO). doi:10.1007/978-3-031-38551-3_3
-
[74]
Sangpyo Kim, Jongmin Kim, Jaeyoung Choi, and Jung Ho Ahn. 2024. CiFHER: A Chiplet-Based FHE Accelerator with a Resizable Structure. InInternational Symposium on Secure and Private Execution Environment Design (SEED). doi:10. 1109/SEED61283.2024.00022
arXiv 2024
-
[75]
Sangpyo Kim, Jongmin Kim, Michael Jaemin Kim, Wonkyung Jung, John Kim, Minsoo Rhu, and Jung Ho Ahn. 2022. BTS: An Accelerator for Bootstrappable Fully Homomorphic Encryption. InISCA. doi:10.1145/3470496.3527415
-
[76]
Liang Kong, Shengyu Fan, Xianglong Deng, Lei Chen, Guang Fan, Guiming Shi, Yilan Zhu, Geng Yang, Shoumeng Yan, and Mingzhe Zhang. 2025. HAWK: Fully Homomorphic Encryption Accelerator with Fixed-Word Key Decomposition Switching. InMICRO. doi:10.1145/3725843.3756123
-
[77]
2009.Learning Multiple Layers of Features from Tiny Images
Alex Krizhevsky and Geoffrey Hinton. 2009.Learning Multiple Layers of Features from Tiny Images. Technical Report. University of Toronto. https://www.cs. toronto.edu/~kriz/learning-features-2009-TR.pdf
2009
-
[78]
Ya Le and Xuan Yang. 2015. Tiny ImageNet Visual Recognition Challenge. https://cs231n.stanford.edu/reports/2015/pdfs/yle_project.pdf
2015
-
[79]
Eunsang Lee, Joon-Woo Lee, Junghyun Lee, Young-Sik Kim, Yongjune Kim, Jong-Seon No, and Woosuk Choi. 2022. Low-Complexity Deep Convolutional Neural Networks on Fully Homomorphic Encryption Using Multiplexed Par- allel Convolutions. InInternational Conference on Machine Learning. https: //proceedings.mlr.press/v162/lee22e.html
2022
-
[80]
Sheng Li, Jung Ho Ahn, Richard D. Strong, Jay B. Brockman, Dean M. Tullsen, and Norman P. Jouppi. 2009. McPAT: An Integrated Power, Area, and Timing Modeling Framework for Multicore and Manycore Architectures. InMICRO. doi:10.1145/1669112.1669172
-
[81]
Yan Liu, Jianxin Lai, Long Li, Tianxiang Sui, Linjie Xiao, Peng Yuan, Xiaojing Zhang, Qing Zhu, Wenguang Chen, and Jingling Xue. 2025. ReSBM: Region- based Scale and Minimal-Level Bootstrapping Management for FHE via Min-Cut. InASPLOS. doi:10.1145/3669940.3707276
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.