Diagnosis Is Not Prescription: Linguistic Co-Adaptation Explains Patching Hazards in LLM Pipelines
Pith reviewed 2026-05-22 06:51 UTC · model grok-4.3
The pith
Fixing the diagnosed bottleneck module in LLM agent pipelines often harms performance rather than helping it.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
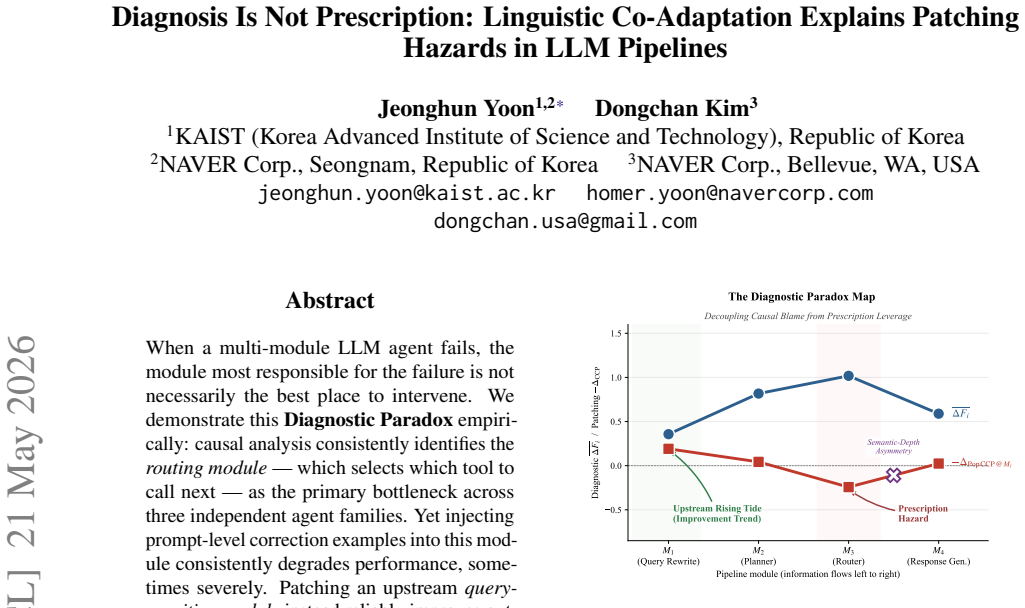
Causal analysis consistently identifies the routing module as the primary bottleneck across three independent agent families. Yet injecting prompt-level correction examples into this module consistently degrades performance, sometimes severely. Patching an upstream query-rewriting module instead reliably improves outcomes. The effect holds with statistical significance on two agent families and directional consistency on a third. Alternative repair strategies at the routing module are neutral, confirming that the harm is specific to correction-injection patching. The asymmetry is explained by the Linguistic Contract hypothesis that each downstream module implicitly adapts to its upstream's 1
What carries the argument
The Linguistic Contract: the implicit adaptation of each downstream module to the characteristic error distribution produced by its upstream module.
If this is right
- Upstream corrections are safer and more effective than direct bottleneck corrections in co-adapted pipelines.
- The per-agent co-adaptation measure, computed from diagnosis alone, predicts whether a given patch will harm or help.
- Instruction rewriting and model upgrades at the routing module leave performance unchanged, unlike correction injection.
- The co-adaptation effect appears consistently across three distinct agent families.
Where Pith is reading between the lines
- Pipeline designers may need to measure co-adaptation explicitly when deciding where to insert repair logic.
- The same adaptation logic could apply to other modular AI systems beyond language agents.
- Debugging methods that ignore co-adaptation may systematically recommend counterproductive fixes.
Load-bearing premise
The observed patching asymmetry arises specifically because downstream modules have adapted to the upstream module's characteristic error distribution rather than from prompt sensitivity, model choice, or the form of the correction examples.
What would settle it
Finding a set of agents where the co-adaptation measure is high yet routing-module corrections produce no performance drop, or where the measure is low yet corrections still harm results, would undermine the hypothesis.
Figures


read the original abstract
When a multi-module LLM agent fails, the module most responsible for the failure is not necessarily the best place to intervene. We demonstrate this Diagnostic Paradox empirically: causal analysis consistently identifies the routing module -- which selects which tool to call next -- as the primary bottleneck across three independent agent families. Yet injecting prompt-level correction examples into this module consistently degrades performance, sometimes severely. Patching an upstream query-rewriting module instead reliably improves outcomes. The effect holds with statistical significance on two agent families and directional consistency on a third; alternative repair strategies at the routing module (instruction rewriting, model upgrade) are neutral, confirming that the harm is specific to correction-injection patching. We explain this asymmetry through the Linguistic Contract hypothesis: each downstream module implicitly adapts to its upstream's characteristic error distribution, so correcting the bottleneck breaks this implicit alignment in a way that upstream corrections do not. We operationalize this via a per-agent co-adaptation measure, derived from diagnosis alone, and show it is consistently associated with patching harm across agent families: higher co-adaptation co-occurs with harm, lower with safety. This trend holds across all three agent families, providing preliminary support for the hypothesis beyond a single-agent observation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that in multi-module LLM agent pipelines, causal analysis identifies the routing module as the primary bottleneck across three agent families, yet injecting prompt-level correction examples into this module degrades performance while patching an upstream query-rewriting module improves outcomes. The authors explain this Diagnostic Paradox via the Linguistic Contract hypothesis—that downstream modules implicitly adapt to upstream error distributions—and operationalize it with a diagnosis-derived co-adaptation measure that correlates with observed patching harm (higher co-adaptation with harm, lower with safety). The effect is statistically significant in two families and directionally consistent in the third, with alternative routing repairs shown to be neutral.
Significance. If the results hold, this work offers a practically important caution for debugging and repairing modular LLM systems: direct intervention at diagnosed bottlenecks can be counterproductive due to inter-module co-adaptations. The multi-family empirical scope, the introduction of a quantifiable co-adaptation metric, and the contrast with neutral alternative repairs provide a useful framework for understanding patching hazards beyond single-agent observations.
major comments (2)
- [Section describing the co-adaptation measure and its association with harm] The co-adaptation measure is described as derived from diagnosis alone and then shown to associate with patching harm; however, without explicit details on its construction (e.g., feature selection, example sampling, or independence from patching outcome data), there is a risk that the measure inadvertently incorporates information correlated with the very harm it is used to explain, weakening support for the Linguistic Contract as a causal account.
- [Patching experiments and alternative repair strategies] The patching asymmetry is attributed to downstream adaptation to upstream error distributions, but the manuscript should more rigorously rule out confounds such as prompt sensitivity, the specific form of correction examples, or model choice; the current controls (neutrality of instruction rewriting and model upgrade) are helpful but may not fully isolate the co-adaptation mechanism.
minor comments (2)
- [Abstract] The abstract states statistical significance on two families and directional consistency on the third but does not report exact p-values, sample sizes, or multiple-comparison corrections; adding these would improve transparency.
- [Causal analysis section] Clarify the precise causal identification procedure used to designate the routing module as the primary bottleneck, including any assumptions or sensitivity checks.
Simulated Author's Rebuttal
We thank the referee for their constructive and insightful comments, which have helped us clarify and strengthen the presentation of our results. We address each major comment in detail below, providing additional methodological transparency and expanded controls where appropriate. All revisions will be incorporated into the next version of the manuscript.
read point-by-point responses
-
Referee: [Section describing the co-adaptation measure and its association with harm] The co-adaptation measure is described as derived from diagnosis alone and then shown to associate with patching harm; however, without explicit details on its construction (e.g., feature selection, example sampling, or independence from patching outcome data), there is a risk that the measure inadvertently incorporates information correlated with the very harm it is used to explain, weakening support for the Linguistic Contract as a causal account.
Authors: We appreciate this observation and agree that greater transparency is warranted. The co-adaptation measure is constructed exclusively from the outputs of the causal diagnosis phase: it quantifies the degree of distributional alignment between upstream error patterns (identified via do-interventions on the routing module) and the linguistic features to which downstream modules have adapted. No patching experiment data, outcome labels, or performance metrics enter the measure's computation at any stage. In the revised manuscript we have added a dedicated subsection (Section 3.3) that specifies (i) the exact linguistic features extracted (token-level error type distributions and syntactic divergence scores), (ii) the deterministic sampling procedure used to select representative error examples from the diagnosis traces, and (iii) an explicit independence statement together with pseudocode confirming that the measure is computed prior to and without reference to any patching runs. These additions make the construction fully reproducible and eliminate the possibility of inadvertent leakage from patching outcomes. revision: yes
-
Referee: [Patching experiments and alternative repair strategies] The patching asymmetry is attributed to downstream adaptation to upstream error distributions, but the manuscript should more rigorously rule out confounds such as prompt sensitivity, the specific form of correction examples, or model choice; the current controls (neutrality of instruction rewriting and model upgrade) are helpful but may not fully isolate the co-adaptation mechanism.
Authors: We acknowledge that the original controls, while informative, leave room for further isolation of the mechanism. In the revision we have added two new sets of experiments. First, we vary the surface form of the correction examples by (a) using paraphrased versions that preserve semantics but alter lexical and syntactic structure and (b) modulating the number of shots (1-shot vs. 5-shot). Second, we repeat the patching protocol on an additional model variant within each agent family (different temperature settings and a second base model of comparable scale). The asymmetry persists across these variations: correction injection at the routing module remains harmful while upstream patching remains beneficial, and the co-adaptation measure continues to predict the direction and magnitude of the effect. We have also expanded the discussion to explicitly address prompt sensitivity and model choice as potential confounds, noting that the observed pattern is robust to these factors. While we cannot claim exhaustive isolation in every conceivable LLM configuration, the expanded controls provide stronger evidence that the harm is tied to the disruption of learned linguistic alignment rather than to the particular prompting or model details tested. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper's core derivation proceeds from independent causal diagnosis of module bottlenecks, separate patching-intervention experiments that measure performance changes, and a co-adaptation measure explicitly derived from the diagnosis data alone. This measure is then tested for association with the patching outcomes across agent families. Because the measure construction does not incorporate the patching results it is later correlated against, and no self-citation, ansatz smuggling, or definitional equivalence is present in the provided text, the chain remains non-circular and self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Downstream modules implicitly adapt to the characteristic error distribution of their upstream modules
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Linguistic Contract hypothesis: each downstream module implicitly adapts to its upstream’s characteristic error distribution... compensator rate as proxy for Contract strength
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Causal contribution ∆Fi and NIEi mediation analysis on four-module pipeline
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
- [1]
-
[2]
Joshi, Hanna Moazam, Heather Miller, Matei Zaharia, and Christopher Potts
Omar Khattab, Arnav Singhvi, Paridhi Maheshwari, Zhiyuan Zhang, Keshav Santhanam, Sri Vardhamanan, Saiful Haq, Ashutosh Sharma, Thomas T. Joshi, Hanna Moazam, Heather Miller, Matei Zaharia, and Christopher Potts. 2024. DSPy : Compiling declarative language model calls into self-improving pipelines. In International Conference on Learning Representations (ICLR)
work page 2024
-
[3]
Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. 2023. Let's verify step by step. arXiv preprint arXiv:2305.20050
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. 2023. G-Eval : NLG evaluation using GPT-4 with better human alignment. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP)
work page 2023
-
[5]
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, Shashank Gupta, Bodhisattwa Prasad Majumder, Katherine Hermann, Sean Welleck, Amir Yazdanbakhsh, and Peter Clark. 2023. Self-refine: Iterative refinement with self-feedback. In Advances in Neural Information Process...
work page 2023
-
[6]
Judea Pearl. 2009. Causality: Models, Reasoning and Inference, 2nd edition. Cambridge University Press
work page 2009
-
[7]
Judea Pearl. 2014. Interpretation and identification of causal mediation. Psychological Methods, 19(4):459--481
work page 2014
-
[8]
Noah Shinn, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. 2023. Reflexion: Language agents with verbal reinforcement learning. In Advances in Neural Information Processing Systems (NeurIPS)
work page 2023
-
[9]
Alessandro Stolfo, Yonatan Belinkov, and Mrinmaya Sachan. 2023. A mechanistic interpretation of arithmetic reasoning in language models using causal mediation analysis. In Proceedings of EMNLP
work page 2023
-
[10]
Jesse Vig, Sebastian Gehrmann, Yonatan Belinkov, Sharon Qian, Daniel Nevo, Yaron Singer, and Stuart Shieber. 2020. Investigating gender bias in language models using causal mediation analysis. In Advances in Neural Information Processing Systems (NeurIPS)
work page 2020
-
[11]
Le, Denny Zhou, and Xinyun Chen
Chengrun Yang, Xuezhi Wang, Yifeng Lu, Hanxiao Liu, Quoc V. Le, Denny Zhou, and Xinyun Chen. 2024. Large language models as optimizers. In International Conference on Learning Representations (ICLR)
work page 2024
-
[12]
Shunyu Yao, Noah Shinn, Pedram Razavi, and Karthik Narasimhan. 2024. -bench : A benchmark for tool-agent-user interaction in real-world domains. In Advances in Neural Information Processing Systems (NeurIPS)
work page 2024
-
[13]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2023. ReAct : Synergizing reasoning and acting in language models. In International Conference on Learning Representations (ICLR)
work page 2023
-
[14]
Mert Yuksekgonul, Federico Bianchi, Joseph Boen, Sheng Liu, Zhi Huang, Carlos Guestrin, and James Zou. 2024. TextGrad : Automatic ``differentiation'' via text. arXiv preprint arXiv:2406.07496
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Yongchao Zhou, Andrei Ioan Muresanu, Ziwen Han, Keiran Paster, Silviu Pitis, Harris Chan, and Jimmy Ba. 2023. Large language models are human-level prompt engineers. In International Conference on Learning Representations (ICLR)
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.