EGOSTREAM: A Diagnostic Benchmark for Streaming Episodic Memory in Egocentric Vision
Pith reviewed 2026-06-28 22:37 UTC · model grok-4.3
The pith
Egostream benchmark shows memory techniques in streaming vision models retain different episodic details despite similar overall scores.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
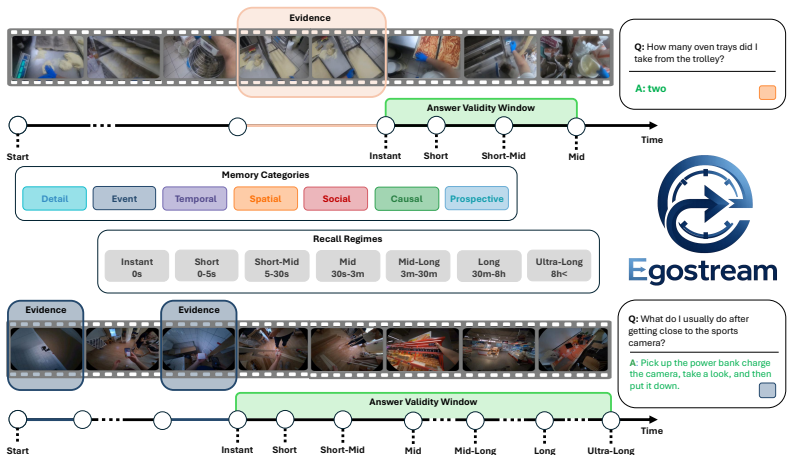
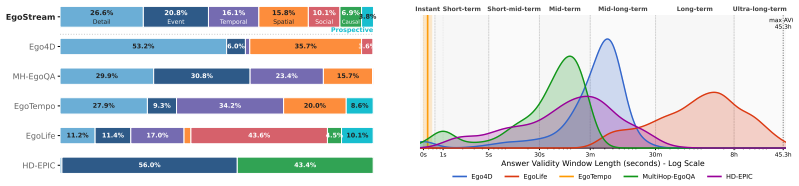
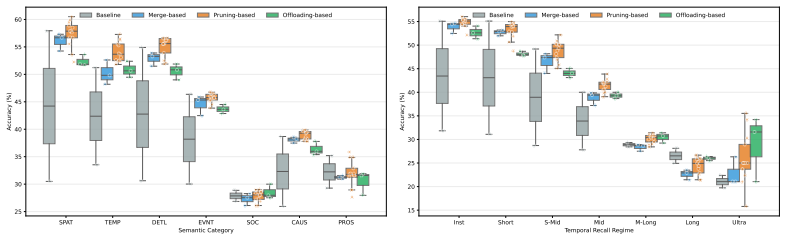
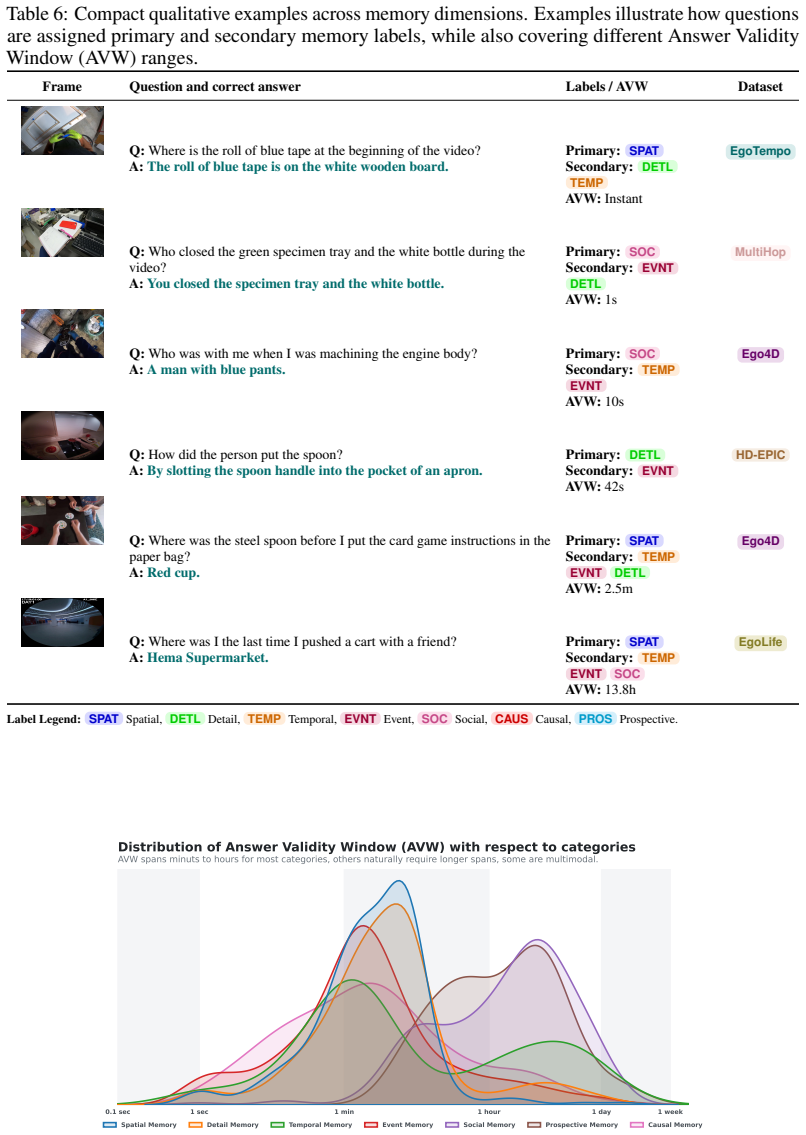
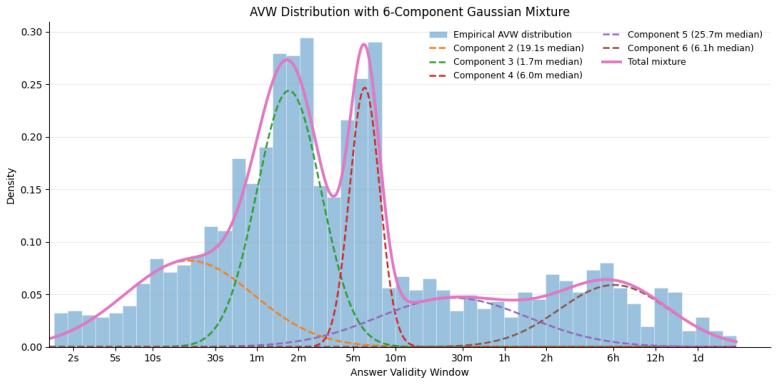
Egostream organizes 2250 curated questions along seven cognitive dimensions and applies the Answer Validity Window to produce 8528 recall-conditioned evaluations. Unified tests on a Qwen3-VL backbone demonstrate that token pruning preserves fine-grained details and temporal structure significantly better than token merging, quantized offloading rescues ultra-long-term recall, yet every mechanism exceeds one second per frame and the best methods reach only about 45 percent accuracy.
What carries the argument
The Answer Validity Window, which marks the time span an answer stays valid as the scene evolves, allowing controlled tests of forgetting versus natural change across memory timescales.
If this is right
- Token pruning is preferable to token merging when fine details and temporal order must be retained.
- Quantized offloading provides a practical route to better ultra-long-term recall.
- Current memory mechanisms cannot support real-time operation on streaming video.
- Top accuracy on the benchmark remains near 45 percent, leaving clear room for architectural improvement.
Where Pith is reading between the lines
- Combining pruning for short-term precision with offloading for distant facts could produce higher overall retention than any single method.
- Gains measured on Egostream may predict better behavior in continuous tasks such as robot navigation through changing environments.
- The seven dimensions could be extended if real deployments reveal memory failures outside the current question set.
- Repeating the comparison on additional model families would clarify whether the observed profile differences depend on the specific backbone.
Load-bearing premise
The 2250 questions and seven cognitive dimensions form a representative probe of the episodic memory demands that appear in real streaming egocentric video.
What would settle it
A memory mechanism that scores below the current 45 percent ceiling on Egostream yet maintains accurate long-term recall during extended real-world egocentric recordings would indicate the benchmark misses key failure modes.
Figures



read the original abstract
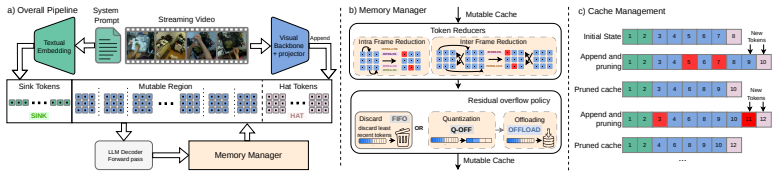
Continuous episodic memory is a core capability for autonomous agents operating in dynamic, real-world environments, yet current streaming video benchmarks provide limited tools for diagnosing what models remember and for how long. We introduce Egostream, a diagnostic benchmark for streaming episodic memory evaluation in egocentric vision. \egostream organizes 2,250 curated questions along seven cognitive dimensions: detail, spatial, temporal, event, social, causal, and prospective memory. We introduce the Answer Validity Window (AVW), which specifies the temporal span an answer remains valid as the observed scene evolves. This allows us to expand the questions into 8,528 recall-conditioned evaluations, enabling controlled testing from instant to ultra-long-term recall while separating genuine model forgetting from natural world-state changes. We rigorously establish baseline performance through a unified streaming MLLM framework that compares several state-of-the-art memory-management mechanisms, covering sliding windows, attention sinks, KV-cache pruning, merging, and offloading. Experiments within a unified Qwen3-VL backbone reveal that comparable aggregate accuracies mask starkly different memory profiles. For instance, token pruning preserves fine-grained details and temporal structure significantly better than token merging, while quantized offloading rescues ultra-long-term recall. Ultimately, all mechanisms operate well below real-time (>1s per frame), and top performing methods ceil at about 45% accuracy, exposing critical gaps in current architectures. Egostream provides the diagnostic testbed needed to close these gaps. Project website, news and updates at: https://saroo25.github.io/Egostream/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces EGOSTREAM, a diagnostic benchmark for streaming episodic memory in egocentric vision. It curates 2,250 questions across seven cognitive dimensions (detail, spatial, temporal, event, social, causal, prospective memory), defines the Answer Validity Window (AVW) to expand them into 8,528 recall-conditioned evaluations, and evaluates memory mechanisms (sliding windows, attention sinks, KV-cache pruning, merging, offloading) on a unified Qwen3-VL backbone. The central empirical finding is that comparable aggregate accuracies mask distinct memory profiles (e.g., pruning better preserves details than merging; offloading aids ultra-long-term recall), yet all methods exceed 1s per frame and top out at ~45% accuracy.
Significance. If the benchmark's questions prove representative of real-world failure modes, the work would offer a useful diagnostic testbed for streaming MLLM memory, with the unified backbone enabling fair mechanism comparisons and the AVW providing a controlled way to separate forgetting from scene evolution. The exposure of the ~45% accuracy ceiling and real-time shortfall highlights concrete gaps for the field.
major comments (3)
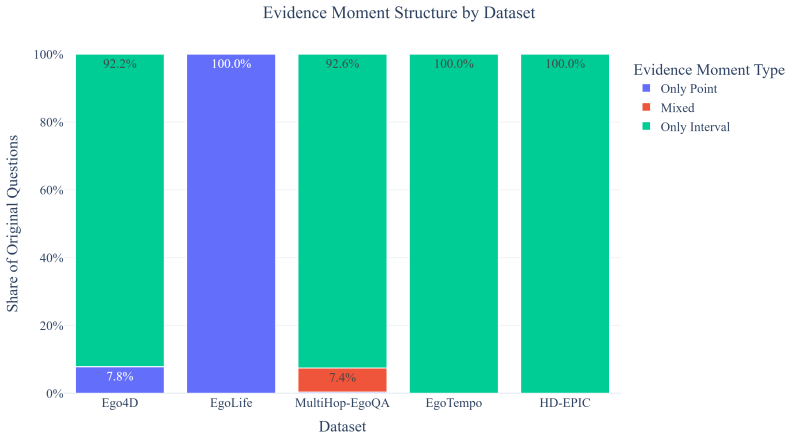
- [§3] Benchmark construction (described in abstract and §3): No details are supplied on the question curation process, inter-annotator agreement, dimension balance statistics, or external validation (e.g., coverage against Ego4D or similar corpora). This is load-bearing for the central claim that the 2,250 questions and seven dimensions form a representative probe of streaming episodic memory demands.
- [§5] §5 (Experiments): The claim that 'token pruning preserves fine-grained details and temporal structure significantly better than token merging' is presented without per-dimension breakdowns, error bars, or statistical significance tests on the 8,528 evaluations, making it impossible to verify whether the reported profile differences are robust or probe-dependent.
- [§4] Abstract and §4: The AVW is introduced as enabling separation of 'genuine model forgetting from natural world-state changes,' but the manuscript provides no implementation details, sensitivity analysis, or validation that AVW-conditioned questions induce the intended forgetting behaviors rather than artifacts of the curation.
minor comments (2)
- [Abstract] The abstract states 'all mechanisms operate well below real-time (>1s per frame)' but does not specify the hardware, batching, or exact measurement protocol used for latency.
- [§3] Notation for the seven cognitive dimensions is introduced without a table summarizing question counts or AVW statistics per dimension.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which identify areas where additional clarity and evidence will strengthen the manuscript. We respond to each major comment below and commit to the indicated revisions.
read point-by-point responses
-
Referee: [§3] Benchmark construction (described in abstract and §3): No details are supplied on the question curation process, inter-annotator agreement, dimension balance statistics, or external validation (e.g., coverage against Ego4D or similar corpora). This is load-bearing for the central claim that the 2,250 questions and seven dimensions form a representative probe of streaming episodic memory demands.
Authors: We agree that the current description of benchmark construction is insufficiently detailed. In the revised manuscript we will expand §3 to include: (i) the full question curation pipeline (source video selection, question generation protocol, and filtering criteria), (ii) inter-annotator agreement statistics, (iii) explicit dimension-balance tables, and (iv) a coverage analysis comparing the 2,250 questions against Ego4D and other egocentric corpora. These additions will directly support the representativeness claim. revision: yes
-
Referee: [§5] §5 (Experiments): The claim that 'token pruning preserves fine-grained details and temporal structure significantly better than token merging' is presented without per-dimension breakdowns, error bars, or statistical significance tests on the 8,528 evaluations, making it impossible to verify whether the reported profile differences are robust or probe-dependent.
Authors: The referee correctly notes the absence of these supporting analyses. We will revise §5 to report per-dimension accuracy tables for all mechanisms, include error bars (via bootstrapping or multiple seeds), and add statistical significance tests (paired t-tests or Wilcoxon tests) on the 8,528 evaluations to substantiate the pruning-versus-merging differences. revision: yes
-
Referee: [§4] Abstract and §4: The AVW is introduced as enabling separation of 'genuine model forgetting from natural world-state changes,' but the manuscript provides no implementation details, sensitivity analysis, or validation that AVW-conditioned questions induce the intended forgetting behaviors rather than artifacts of the curation.
Authors: We will augment §4 with: (i) precise implementation details of how AVW temporal spans are computed from the video and question metadata, (ii) a sensitivity analysis varying AVW width and offset, and (iii) validation experiments that compare model behavior on AVW-conditioned versus non-conditioned questions to confirm the intended separation of forgetting from scene evolution. revision: yes
Circularity Check
No circularity: empirical benchmark with no derivations or reductions to inputs
full rationale
The paper introduces Egostream as a new benchmark via curation of 2,250 questions across seven cognitive dimensions plus AVW-conditioned evaluations, then reports direct empirical results on memory mechanisms (pruning, merging, offloading) using a unified Qwen3-VL backbone. No equations, parameter fittings, self-definitional constructs, or load-bearing self-citations appear in the provided text. All claims rest on new data collection and straightforward experimental comparison rather than any derivation chain that reduces outputs to inputs by construction. This is a standard self-contained benchmark paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard assumptions in egocentric vision benchmarks that curated questions reflect real-world memory demands and that scene evolution can be separated from model forgetting via temporal validity windows.
invented entities (1)
-
Answer Validity Window (AVW)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Working memory: looking back and looking forward.Nature reviews neuro- science, 4(10):829–839, 2003
Alan Baddeley. Working memory: looking back and looking forward.Nature reviews neuro- science, 4(10):829–839, 2003
2003
-
[2]
Qwen3-vl technical report, 2025
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Junyang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shixuan ...
2025
-
[3]
Where did i leave my keys? episodic-memory-based question answering on egocentric videos
Leonard Bärmann and Alex Waibel. Where did i leave my keys? episodic-memory-based question answering on egocentric videos. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, 2022
2022
-
[4]
Token merging: Your vit but faster
Daniel Bolya, Cheng-Yang Fu, Xiaoliang Dai, Peizhao Zhang, Christoph Feichtenhofer, and Judy Hoffman. Token merging: Your vit but faster. InThe Eleventh International Conference on Learning Representations, 2023
2023
-
[5]
The human hippocampus and spatial and episodic memory.Neuron, 35(4):625–641, 2002
Neil Burgess, Eleanor A Maguire, and John O’Keefe. The human hippocampus and spatial and episodic memory.Neuron, 35(4):625–641, 2002
2002
-
[6]
Grounded multi-hop videoqa in long-form egocentric videos.arXiv preprint arXiv:2408.14469, 2025
Qirui Chen, Shangzhe Di, and Weidi Xie. Grounded multi-hop videoqa in long-form egocentric videos.arXiv preprint arXiv:2408.14469, 2025
-
[7]
Available: https://arxiv.org/abs/2510.18269
Xueyi Chen, Keda Tao, Kele Shao, and Huan Wang. Streamingtom: Streaming token compres- sion for efficient video understanding.arXiv preprint arXiv:2510.18269, 2025
-
[8]
Elements of episodic–like memory in animals.Philosophical Transactions of the Royal Society of London
Nicola S Clayton, Daniel P Griffiths, Nathan J Emery, and Anthony Dickinson. Elements of episodic–like memory in animals.Philosophical Transactions of the Royal Society of London. Series B: Biological Sciences, 356(1413):1483–1491, 2001
2001
-
[9]
What are the differences between long-term, short-term, and working memory? Progress in Brain Research, 169:323–338, 2008
Nelson Cowan. What are the differences between long-term, short-term, and working memory? Progress in Brain Research, 169:323–338, 2008
2008
-
[10]
Grounded question-answering in long egocentric videos
Shangzhe Di and Weidi Xie. Grounded question-answering in long egocentric videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024
2024
-
[11]
Shangzhe Di, Zhelun Yu, Guanghao Zhang, Haoyuan Li, Tao Zhong, Hao Cheng, Bolin Li, Wanggui He, Fangxun Shu, and Hao Jiang. Streaming video question-answering with in-context video kv-cache retrieval.arXiv preprint arXiv:2503.00540, 2025
-
[12]
The neurobiology of consolidations, or, how stable is the engram?Annu
Yadin Dudai. The neurobiology of consolidations, or, how stable is the engram?Annu. Rev. Psychol., 55(1):51–86, 2004
2004
-
[13]
Teachers College, Columbia University, New York, 1885
Hermann Ebbinghaus.Memory: A contribution to experimental psychology. Teachers College, Columbia University, New York, 1885
-
[14]
Embodied videoagent: Persistent memory from egocentric videos and embodied sensors enables dynamic scene understanding
Yue Fan, Xiaojian Ma, Rongpeng Su, Jun Guo, Rujie Wu, Xi Chen, and Qing Li. Embodied videoagent: Persistent memory from egocentric videos and embodied sensors enables dynamic scene understanding. In2025 IEEE/CVF International Conference on Computer Vision (ICCV), pages 6342–6352. IEEE, 2025
2025
-
[15]
Memory for the time of past events.Psychological bulletin, 113(1):44, 1993
William J Friedman. Memory for the time of past events.Psychological bulletin, 113(1):44, 1993
1993
-
[16]
Amego: Active memory from long egocentric videos
Gabriele Goletto, Tushar Nagarajan, Giuseppe Averta, and Dima Damen. Amego: Active memory from long egocentric videos. InEuropean Conference on Computer Vision, pages 92–110. Springer, 2024. 10
2024
-
[17]
Ego4d: Around the world in 3,000 hours of egocentric video
Kristen Grauman, Andrew Westbury, Eugene Byrne, Zachary Chavis, Antonino Furnari, Rohit Girdhar, et al. Ego4d: Around the world in 3,000 hours of egocentric video. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022
2022
-
[18]
Episodic memory differences in social and non- social contexts.Plos one, 21(4):e0342919, 2026
Karina Grunewald and Susanne Schweizer. Episodic memory differences in social and non- social contexts.Plos one, 21(4):e0342919, 2026
2026
-
[19]
Single-stage visual query localization in egocentric videos.Advances in Neural Information Processing Systems, 36:24143–24157, 2023
Hanwen Jiang, Santhosh Kumar Ramakrishnan, and Kristen Grauman. Single-stage visual query localization in egocentric videos.Advances in Neural Information Processing Systems, 36:24143–24157, 2023
2023
-
[20]
Infinipot-v: Memory- constrained kv cache compression for streaming video understanding
Minsoo Kim, Kyuhong Shim, Jungwook Choi, and Simyung Chang. Infinipot-v: Memory- constrained kv cache compression for streaming video understanding. InAdvances in Neural Information Processing Systems, 2025
2025
-
[21]
SnapKV: LLM knows what you are looking for before generation
Yuhong Li, Yingbing Huang, Bowen Yang, Bharat Venkitesh, Acyr Locatelli, Hanchen Ye, Tianle Cai, Patrick Lewis, and Deming Chen. SnapKV: LLM knows what you are looking for before generation. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024
2024
-
[22]
Streamingbench: Assessing the gap for mllms to achieve streaming video understanding,
Junming Lin, Zheng Fang, Chi Chen, Zihao Wan, Fuwen Luo, Peng Li, Yang Liu, and Maosong Sun. Streamingbench: Assessing the gap for mllms to achieve streaming video understanding. arXiv preprint arXiv:2411.03628, 2024
-
[23]
Scissorhands: Exploiting the persistence of importance hypothesis for LLM KV cache compression at test time
Zichang Liu, Aditya Desai, Fangshuo Liao, Weitao Wang, Victor Xie, Zhaozhuo Xu, Anastasios Kyrillidis, and Anshumali Shrivastava. Scissorhands: Exploiting the persistence of importance hypothesis for LLM KV cache compression at test time. InThirty-seventh Conference on Neural Information Processing Systems, 2023
2023
-
[24]
Egoschema: A diagnostic benchmark for very long-form video language understanding
Karttikeya Mangalam, Raiymbek Akshulakov, and Jitendra Malik. Egoschema: A diagnostic benchmark for very long-form video language understanding. In A. Oh, T. Naumann, A. Glober- son, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neural Information Processing Systems, volume 36, pages 46212–46244. Curran Associates, Inc., 2023
2023
-
[25]
Online episodic memory visual query localization with egocentric streaming object memory
Zaira Manigrasso, Matteo Dunnhofer, Antonino Furnari, Moritz Nottebaum, Antonio Finoc- chiaro, Davide Marana, Rosario Forte, Giovanni Maria Farinella, and Christian Micheloni. Online episodic memory visual query localization with egocentric streaming object memory. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2026
2026
-
[26]
Sage Publications, 2007
Mark A McDaniel and Gilles O Einstein.Prospective memory: An overview and synthesis of an emerging field. Sage Publications, 2007
2007
-
[27]
Memory–a century of consolidation.Science, 287(5451):248–251, 2000
James L McGaugh. Memory–a century of consolidation.Science, 287(5451):248–251, 2000
2000
-
[28]
The cognitive neuroscience of remote episodic, semantic and spatial memory.Current Opinion in Neurobiology, 16(2):179–190, 2006
Morris Moscovitch, Lynn Nadel, Gordon Winocur, Asaf Gilboa, and R Shayna Rosenbaum. The cognitive neuroscience of remote episodic, semantic and spatial memory.Current Opinion in Neurobiology, 16(2):179–190, 2006
2006
-
[29]
The cognitive neuroscience of remote episodic, semantic and spatial memory.Current opinion in neurobiology, 16(2):179–190, 2006
Morris Moscovitch, Lynn Nadel, Gordon Winocur, Asaf Gilboa, and R Shayna Rosenbaum. The cognitive neuroscience of remote episodic, semantic and spatial memory.Current opinion in neurobiology, 16(2):179–190, 2006
2006
-
[30]
Replication and analysis of ebbinghaus’ forgetting curve.PLoS One, 10(7):e0120644, 2015
Jaap MJ Murre and Joeri Dros. Replication and analysis of ebbinghaus’ forgetting curve.PLoS One, 10(7):e0120644, 2015
2015
-
[31]
Ovo-bench: How far is your video-llms from real-world online video understanding? InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025
Junbo Niu, Yifei Li, Ziyang Miao, Chunjiang Ge, Yuanhang Zhou, Qihao He, Xiaoyi Dong, Haodong Duan, Shuangrui Ding, Rui Qian, Pan Zhang, Yuhang Zang, Yuhang Cao, Conghui He, and Jiaqi Wang. Ovo-bench: How far is your video-llms from real-world online video understanding? InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025. 11
2025
-
[32]
Hd-epic: A highly-detailed egocentric video dataset.arXiv preprint arXiv:2502.04144, 2025
Toby Perrett, Ahmad Darkhalil, Saptarshi Sinha, Omar Emara, Sam Pollard, Kranti Parida, Kaiting Liu, Prajwal Gatti, Siddhant Bansal, Kevin Flanagan, Jacob Chalk, Zhifan Zhu, Rho- dri Guerrier, Fahd Abdelazim, Bin Zhu, Davide Moltisanti, Michael Wray, Hazel Doughty, and Dima Damen. Hd-epic: A highly-detailed egocentric video dataset.arXiv preprint arXiv:25...
-
[33]
An Outlook into the Future of Egocentric Vision.International Journal of Computer Vision, 132(11):4880–4936, November 2024
Chiara Plizzari, Gabriele Goletto, Antonino Furnari, Siddhant Bansal, Francesco Ragusa, Giovanni Maria Farinella, Dima Damen, and Tatiana Tommasi. An Outlook into the Future of Egocentric Vision.International Journal of Computer Vision, 132(11):4880–4936, November 2024
2024
-
[34]
Ren, W., Ma, W., Yang, H., Wei, C., Zhang, G., and Chen, W
Chiara Plizzari, Alessio Tonioni, Yongqin Xian, Achin Kulshrestha, and Federico Tombari. Omnia de egotempo: Benchmarking temporal understanding of multi-modal llms in egocentric videos.arXiv preprint arXiv:2503.13646, 2025
-
[35]
Oxford University Press, 2014
Gabriel A Radvansky and Jeffrey M Zacks.Event cognition. Oxford University Press, 2014
2014
-
[36]
Moviechat: From dense token to sparse memory for long video understanding.2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 18221–18232, 2023
Enxin Song, Wenhao Chai, Guanhong Wang, Yucheng Zhang, Haoyang Zhou, Feiyang Wu, Xun Guo, Tianbo Ye, Yang Lu, Jenq-Neng Hwang, and Gaoang Wang. Moviechat: From dense token to sparse memory for long video understanding.2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 18221–18232, 2023
2024
-
[37]
Episodic memory through a social and emotional lens.Emotion, 23(4):961, 2023
Charlotte I Stewardson, Michelle C Hunsche, Victoria Wardell, Daniela J Palombo, and Con- nor M Kerns. Episodic memory through a social and emotional lens.Emotion, 23(4):961, 2023
2023
-
[38]
Gemini: A family of highly capable multimodal models, 2025
Gemini Team. Gemini: A family of highly capable multimodal models, 2025
2025
-
[39]
Causal thinking and the representation of narrative events.Journal of memory and language, 24(5):612–630, 1985
Tom Trabasso and Paul Van Den Broek. Causal thinking and the representation of narrative events.Journal of memory and language, 24(5):612–630, 1985
1985
-
[40]
Episodic memory: From mind to brain.Annual review of psychology, 53(1):1–25, 2002
Endel Tulving. Episodic memory: From mind to brain.Annual review of psychology, 53(1):1–25, 2002
2002
-
[41]
Episodic and semantic memory.Organization of memory, 1(381-403):1, 1972
Endel Tulving et al. Episodic and semantic memory.Organization of memory, 1(381-403):1, 1972
1972
-
[42]
Yuxuan Wang, Yueqian Wang, Bo Chen, Tong Wu, Dongyan Zhao, and Zilong Zheng. Omn- immi: A comprehensive multi-modal interaction benchmark in streaming video contexts.arXiv preprint arXiv:2503.22952, 2025
-
[43]
Model tells you where to merge: Adaptive KV cache merging for LLMs on long-context tasks, 2025
Zheng Wang, Boxiao Jin, Yuming Chang, Zhongzhi Yu, and Minjia Zhang. Model tells you where to merge: Adaptive KV cache merging for LLMs on long-context tasks, 2025
2025
-
[44]
Efficient streaming language models with attention sinks
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. Efficient streaming language models with attention sinks. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[45]
Streaming video understanding and multi-round interaction with memory-enhanced knowledge,
Haomiao Xiong, Zongxin Yang, Jiazuo Yu, Yunzhi Zhuge, Lu Zhang, Jiawen Zhu, and Huchuan Lu. Streaming video understanding and multi-round interaction with memory-enhanced knowl- edge.arXiv preprint arXiv:2501.13468, 2025
-
[46]
StreamingVLM: Real-Time Understanding for Infinite Video Streams
Ruyi Xu, Guangxuan Xiao, Yukang Chen, Liuning He, Kelly Peng, Yao Lu, and Song Han. Streamingvlm: Real-time understanding for infinite video streams.arXiv preprint arXiv:2510.09608, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[47]
Egolife: Towards egocentric life assistant
Jingkang Yang, Shuai Liu, Hongming Guo, Yuhao Dong, Xiamengwei Zhang, Sicheng Zhang, Pengyun Wang, Zitang Zhou, Binzhu Xie, Ziyue Wang, Bei Ouyang, Zhengyu Lin, Marco Cominelli, Zhongang Cai, Yuanhan Zhang, Peiyuan Zhang, Fangzhou Hong, Joerg Widmer, Francesco Gringoli, Lei Yang, Bo Li, and Ziwei Liu. Egolife: Towards egocentric life assistant. InProceedi...
2025
-
[48]
Streammem: Query-agnostic kv cache memory for streaming video understanding, 2025
Yanlai Yang, Zhuokai Zhao, Satya Narayan Shukla, Aashu Singh, Shlok Kumar Mishra, Lizhu Zhang, and Mengye Ren. Streammem: Query-agnostic kv cache memory for streaming video understanding, 2025
2025
-
[49]
MMEgo: Towards building egocentric multimodal LLMs for video QA
Hanrong Ye, Haotian Zhang, Erik Daxberger, Lin Chen, Zongyu Lin, Yanghao Li, Bowen Zhang, Haoxuan You, Dan Xu, Zhe Gan, Jiasen Lu, and Yinfei Yang. MMEgo: Towards building egocentric multimodal LLMs for video QA. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[50]
Flash-vstream: Efficient real-time understanding for long video streams
Haoji Zhang, Yiqin Wang, Yansong Tang, Yong Liu, Jiashi Feng, and Xiaojie Jin. Flash-vstream: Efficient real-time understanding for long video streams. InProceedings of the IEEE/CVF International Conference on Computer Vision, 2025
2025
-
[51]
HERMES: KV Cache as Hierarchical Memory for Efficient Streaming Video Understanding
Haowei Zhang, Shudong Yang, Jinlan Fu, See-Kiong Ng, and Xipeng Qiu. Hermes: Kv cache as hierarchical memory for efficient streaming video understanding.arXiv preprint arXiv:2601.14724, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[52]
Cam: Cache merging for memory-efficient LLMs inference
Yuxin Zhang, Yuxuan Du, Gen Luo, Yunshan Zhong, Zhenyu Zhang, Shiwei Liu, and Rongrong Ji. Cam: Cache merging for memory-efficient LLMs inference. InForty-first International Conference on Machine Learning, 2024
2024
-
[53]
H2o: Heavy-hitter oracle for efficient generative inference of large language models
Zhenyu Zhang, Ying Sheng, Tianyi Zhou, Tianlong Chen, Lianmin Zheng, Ruisi Cai, Zhao Song, Yuandong Tian, Christopher Re, Clark Barrett, Zhangyang Wang, and Beidi Chen. H2o: Heavy-hitter oracle for efficient generative inference of large language models. InThirty-seventh Conference on Neural Information Processing Systems, 2023
2023
-
[54]
You connected the cable to [object] and [object]
Sheng Zhou, Junbin Xiao, Qingyun Li, Yicong Li, Xun Yang, Dan Guo, Meng Wang, Tat-Seng Chua, and Angela Yao. Egotextvqa: Towards egocentric scene-text aware video question answering. InProceedings of the Computer Vision and Pattern Recognition Conference (CVPR), pages 3363–3373, June 2025. 13 A The EGOSTREAMBenchmark This appendix reports additional detai...
2025
-
[55]
It is clearly different in factual content from the ground-truth answer.,→
-
[56]
It preserves the same answer format/structure as the ground-truth answer.,→
-
[57]
It preserves similar granularity/detail level as the ground-truth answer.,→
-
[58]
It is plausible for the scene/question context
-
[59]
It is not a trivial or obviously easy distractor
-
[60]
valid": true,
It should be confusable with the ground-truth by structure/style, but not by factual content.,→ Question: {question} Ground-truth answer: {gt_answer} Candidate negative: {candidate} Return ONLY one JSON object: { "valid": true, "content_changed": true, "structure_preserved": true, "granularity_preserved": true, "plausible": true, "too_easy": false, "reaso...
-
[61]
The used prompt is reported in Prompt 1
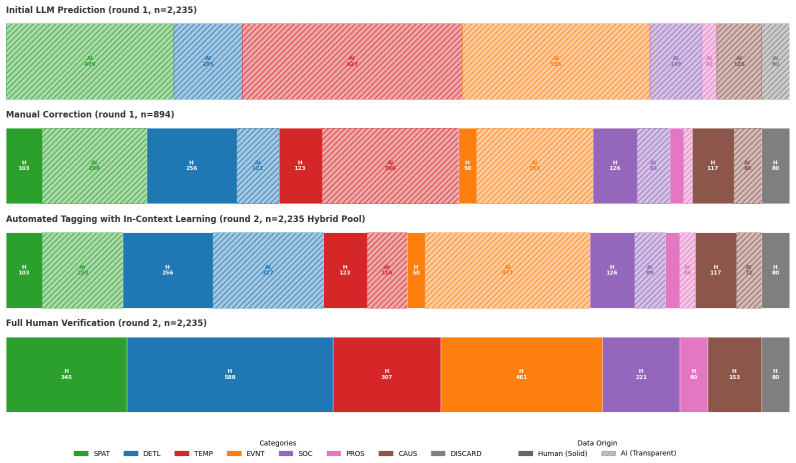
Initial LLM Prediction (round 1):A Large Language Model (Gemini 2.5 Pro) was prompted to assign initial memory categories based on early rule drafts. The used prompt is reported in Prompt 1
-
[62]
During this phase, critical ambiguities were identified and resolved (e.g., distinguishing between a question asking for a spatial location vs
Manual Correction (round 1):Human expert annotators then manually reviewed and corrected a large subset of these predictions ( 847 questions). During this phase, critical ambiguities were identified and resolved (e.g., distinguishing between a question asking for a spatial location vs. a question using a spatial phrase merely to identify an object). If so...
-
[63]
This guided a subsequent round of LLM labeling (Gemini 2.5 Pro), significantly reducing the 21 Figure 10: Interface used to refine category annotations for questions
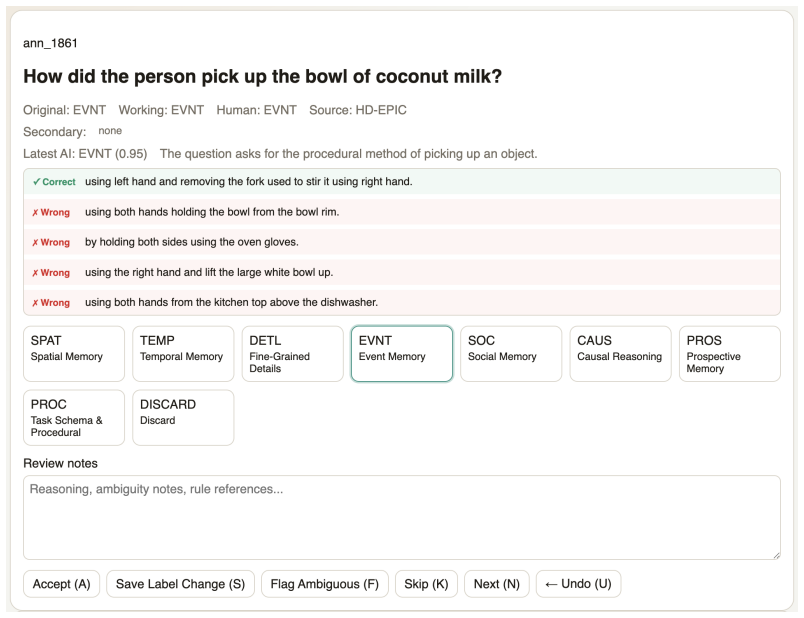
Automated Tagging with In-Context Learning (round 2):The manually corrected, high- quality seed set was then used to craft a refined prompt defining precise cascade rules and include few-shot, in-context examples to make automated tagging more accurate. This guided a subsequent round of LLM labeling (Gemini 2.5 Pro), significantly reducing the 21 Figure 1...
-
[64]
How do I usually buy tickets?
Full Human Verification (round 2):At this stage, human annotators used the interface introduced in Figure 10 to 1) revise old questions where human and AI disagreed and and 2) revise new questions with no human labels. At this stage, labeling is faster, as annotators just have to confirm automated labels in most cases. Figure 11 shows the evolution of AI-...
-
[65]
Never change the primary label
-
[66]
Secondary labels can be empty
-
[67]
Never include the primary label inside`secondaryLabels`
-
[68]
Use only the question text and primary label
-
[69]
If`primaryLabel`is`DISCARD`,`secondaryLabels`must be empty
-
[70]
id": "ann_1
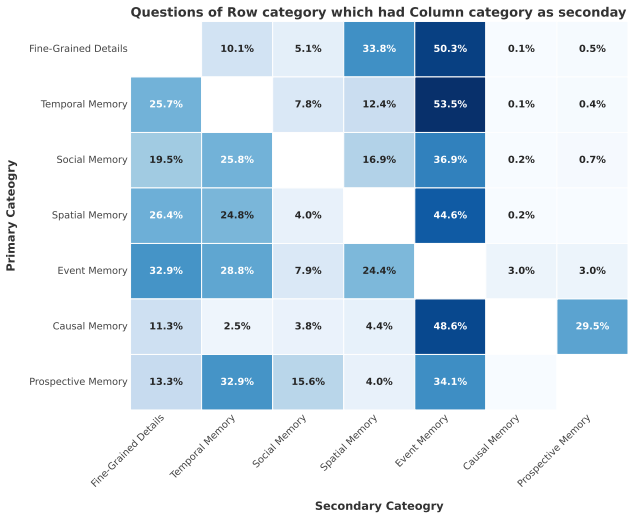
Return labels as a set (no duplicates). ## Semantics for secondary labeling - Add`DETL`when fine-grained item identity/count/text/color is truly required.,→ - Add`SPAT`when location or spatial relation is essential. - Add`TEMP`when order/time anchors (before/after/last/first/when) are essential.,→ - Add`EVNT`when whether/how an action happened is a meanin...
-
[71]
[OPTION_4] Reply with number only. A.8 Text Baseline To assess whether the base QA set can be solved by exploiting textual priors alone, we additionally evaluated a text-only configuration in which the model receives only the question and answer options, without access to the corresponding video (see Figure 7). As shown below, performance is close to rand...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.