OmniDance: Multimodal Driven Dance Video Generation with Large-scale Internet Data
Pith reviewed 2026-06-30 06:33 UTC · model grok-4.3
The pith
OmniDance adds music conditioning to text-image-to-video models through specialized architecture and training, using a new 300k-clip dance dataset.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
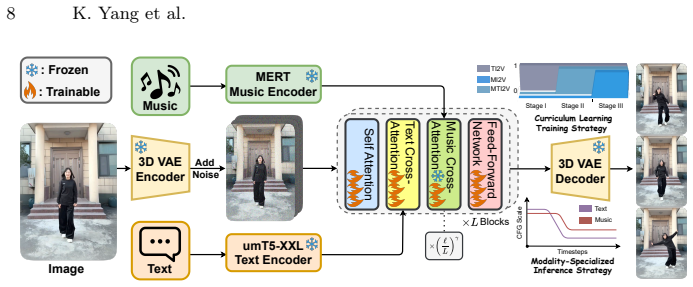
OmniDance co-designs a depth-aware specialization architecture, an anchored easy-to-hard curriculum learning strategy, and a modality-specialized time-dependent CFG strategy to integrate music into a TI2V foundation model, enabling unified TI2V, MI2V, and MTI2V dance video generation that achieves state-of-the-art performance on the CIPE-Dance dataset of 300k high-quality clips spanning 400 hours.
What carries the argument
The depth-aware specialization architecture together with anchored easy-to-hard curriculum learning and modality-specialized time-dependent CFG, which lets music supply high-frequency temporal alignment without eroding text controllability or visual fidelity.
If this is right
- A single model can now perform text-driven, music-driven, or joint multimodal dance video generation without separate retraining or loss of original capabilities.
- Training on 300k internet-sourced clips with expert text annotations produces measurable improvements across all three task variants.
- The complementary-frequency view of text and music leads to concrete architectural and scheduling choices that maintain robustness when modalities are combined or ablated.
- The same framework-level recipe can be applied to any TI2V foundation model while keeping its original controllability intact.
Where Pith is reading between the lines
- The curriculum and CFG specialization pattern could transfer to other temporal signals such as speech or environmental audio in general video generation.
- The expert-annotation pipeline for internet video may reduce reliance on synthetic data for other motion-centric domains like sports or sign language.
- If the high-frequency role of music generalizes, similar modality splitting might improve efficiency in training large multimodal models for non-dance tasks.
Load-bearing premise
The CIPE-Dance dataset built through the progressive expert pipeline supplies sufficiently high-quality and unbiased training data that the reported gains come from the framework rather than hidden dataset artifacts or domain shifts.
What would settle it
An independent replication on a fresh dance video test set collected outside the CIPE-Dance pipeline where OmniDance fails to exceed prior methods on quantitative measures of music-motion alignment, visual fidelity, and multimodal controllability.
Figures


read the original abstract
Music-driven dance video generation aims to synthesize expressive human motion that is temporally aligned with music while maintaining high visual fidelity. Despite recent progress, existing methods still face two key limitations: the lack of large-scale, high-quality dance video datasets, and the absence of principled frameworks for integrating music as a complementary conditioning signal into Video Generation Foundation Models. To address these limitations, we introduce CIPE-Dance, a large-scale Internet-sourced dance video dataset with choreography-informed text annotations, constructed via a progressive expert pipeline. To the best of our knowledge, CIPE-Dance is the largest dataset for dance video generation to date, comprising 300k high-quality clips over 400 hours and covering diverse dancers, environments, and dance genres. We further propose OmniDance, a framework-level recipe for integrating music into a TI2V foundation model without sacrificing its original controllability or visual fidelity. Motivated by the complementary roles of text as low-frequency semantics and music as high-frequency temporal dynamics, OmniDance co-designs a depth-aware specialization architecture, an anchored easy-to-hard curriculum learning strategy, and a modality-specialized time-dependent CFG strategy, enabling unified TI2V, MI2V, and MTI2V generation. Extensive experiments on CIPE-Dance demonstrate that OmniDance achieves state-of-the-art performance across all three tasks and exhibits robust multimodal integration capability. Project is available at https://github.com/AMAP-ML/OmniDance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces CIPE-Dance, a 300k-clip (400-hour) Internet-sourced dance video dataset with choreography-informed text annotations built via a progressive expert pipeline, and proposes OmniDance, a framework that augments a TI2V foundation model with music conditioning through depth-aware specialization, an anchored easy-to-hard curriculum, and modality-specialized time-dependent classifier-free guidance. This enables unified TI2V, MI2V, and MTI2V generation while preserving base-model controllability. Extensive experiments on the CIPE-Dance test split are reported to establish state-of-the-art performance across all three tasks together with robust multimodal integration.
Significance. If the results hold under broader scrutiny, the work supplies the largest public dance-video resource to date and a concrete co-design recipe for injecting high-frequency temporal signals (music) into existing video-generation backbones without catastrophic forgetting of text controllability. The explicit motivation linking text to low-frequency semantics and music to high-frequency dynamics, combined with the dataset scale, could serve as a useful reference point for subsequent multimodal video synthesis research.
major comments (2)
- [Experiments] Experiments section: All reported SOTA margins for TI2V/MI2V/MTI2V are obtained exclusively on the internal CIPE-Dance test split whose distribution, motion statistics, and annotation style are defined by the same progressive expert pipeline used for training data. No quantitative results on prior public dance corpora (e.g., AIST++) nor re-evaluation of published baselines on CIPE-Dance are supplied, leaving open the possibility that the observed gains arise from alignment between the three co-designed components and dataset-specific biases rather than intrinsic superiority of the multimodal integration strategy.
- [§4 and Experiments] §4 (Method) and Experiments: The central claim that the depth-aware specialization, anchored curriculum, and time-dependent CFG together enable “robust multimodal integration” without sacrificing original controllability rests on the joint training/inference recipe, yet no isolated ablation tables quantify the marginal contribution of each component (or their interactions) to the final metrics. This is load-bearing for attributing performance gains to the proposed framework rather than to dataset scale alone.
minor comments (2)
- [Abstract] The abstract states that CIPE-Dance is “the largest dataset … to date” but supplies no explicit comparison table against prior dance-video corpora in terms of total duration, genre coverage, or annotation granularity.
- [Introduction] Notation for the three tasks (TI2V, MI2V, MTI2V) is introduced without an early definition or diagram clarifying the exact input modalities for each.
Simulated Author's Rebuttal
We thank the referee for the constructive and insightful comments. We address each major comment point by point below.
read point-by-point responses
-
Referee: [Experiments] Experiments section: All reported SOTA margins for TI2V/MI2V/MTI2V are obtained exclusively on the internal CIPE-Dance test split whose distribution, motion statistics, and annotation style are defined by the same progressive expert pipeline used for training data. No quantitative results on prior public dance corpora (e.g., AIST++) nor re-evaluation of published baselines on CIPE-Dance are supplied, leaving open the possibility that the observed gains arise from alignment between the three co-designed components and dataset-specific biases rather than intrinsic superiority of the multimodal integration strategy.
Authors: We agree that this is a substantive concern. CIPE-Dance is presented as the largest public dance video dataset, and the experiments were designed to evaluate on its held-out test split to demonstrate performance at scale. However, the absence of cross-dataset results and baseline re-evaluations on CIPE-Dance does leave open the possibility of dataset-specific effects. In the revised manuscript we will add (i) re-evaluation of the published baselines on the CIPE-Dance test split and (ii) quantitative results of OmniDance on AIST++ (where motion and annotation differences permit direct comparison). These additions will allow readers to better assess whether the reported gains are attributable to the proposed multimodal integration strategy. revision: yes
-
Referee: [§4 and Experiments] §4 (Method) and Experiments: The central claim that the depth-aware specialization, anchored curriculum, and time-dependent CFG together enable “robust multimodal integration” without sacrificing original controllability rests on the joint training/inference recipe, yet no isolated ablation tables quantify the marginal contribution of each component (or their interactions) to the final metrics. This is load-bearing for attributing performance gains to the proposed framework rather than to dataset scale alone.
Authors: We concur that isolated ablations are necessary to attribute performance to the individual components rather than to dataset scale. The current manuscript reports only the full-model results. In the revision we will insert a dedicated ablation subsection that quantifies the marginal contribution of depth-aware specialization, the anchored easy-to-hard curriculum, and modality-specialized time-dependent CFG, together with their pairwise and triple interactions, using the same metrics and test split. revision: yes
Circularity Check
No derivation chain present; claims are empirical outcomes of dataset construction and training
full rationale
The paper introduces CIPE-Dance via a progressive expert pipeline and proposes OmniDance as a co-designed framework for multimodal integration. All performance claims are presented as results of 'extensive experiments on CIPE-Dance' with no equations, first-principles derivations, fitted parameters renamed as predictions, or load-bearing self-citations that reduce the central result to its inputs by construction. The evaluation is internal to the new dataset, which is a common empirical limitation but does not match any enumerated circularity pattern (self-definitional, fitted-input-called-prediction, etc.). The derivation chain is therefore self-contained as standard ML experimentation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Advances in neural information processing systems33, 12449–12460 (2020)
Baevski, A., Zhou, Y., Mohamed, A., Auli, M.: wav2vec 2.0: A framework for self-supervised learning of speech representations. Advances in neural information processing systems33, 12449–12460 (2020)
2020
-
[2]
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., Ge, W., Guo, Z., Huang, Q., Huang, J., Huang, F., Hui, B., Jiang, S., Li, Z., Li, M., Li, M., Li, K., Lin, Z., Lin, J., Liu, X., Liu, J., Liu, C., Liu, Y., Liu, D., Liu, S., Lu, D., Luo, R., Lv, C., Men, R., Meng, L., Ren, X., Ren, X., Song, S., Sun, Y., Tang, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Research in dance education5(1), 45–67 (2004)
Butterworth*, J.: Teaching choreography in higher education: A process continuum model. Research in dance education5(1), 45–67 (2004)
2004
-
[4]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Chen, C., Hu, S., Zhu, J., Wu, M., Chen, J., Li, Y., Huang, N., Fang, C., Wu, J., Chu, X., et al.: Taming preference mode collapse via directional decoupling alignment in diffusion reinforcement learning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 12775–12786 (2026)
2026
-
[5]
arXiv preprint arXiv:2508.12880 (2025)
Chen, C., Zhu, J., Feng, X., Huang, N., Wu, M., Mao, F., Wu, J., Chu, X., Li, X.: S2-Guidance: Stochastic self guidance for training-free enhancement of diffusion models. arXiv preprint arXiv:2508.12880 (2025)
-
[6]
In: Proceedings of the 33rd ACM International Conference on Multimedia
Chen, R., Sun, L., Tang, J., Li, G., Chu, X.: Finger: Content aware fine-grained evaluation with reasoning for ai-generated videos. In: Proceedings of the 33rd ACM International Conference on Multimedia. pp. 3517–3526 (2025)
2025
-
[7]
arXiv preprint arXiv:2502.17414 (2025)
Chen,Z.,Xu,H.,Song,G.,Xie,Y.,Zhang,C.,Chen,X.,Wang,C.,Chang,D.,Luo, L.: X-dancer: Expressive music to human dance video generation. arXiv preprint arXiv:2502.17414 (2025)
-
[8]
arXiv preprint arXiv:2509.14055 (2025)
Cheng, G., Gao, X., Hu, L., Hu, S., Huang, M., Ji, C., Li, J., Meng, D., Qi, J., Qiao, P., et al.: Wan-animate: Unified character animation and replacement with holistic replication. arXiv preprint arXiv:2509.14055 (2025)
-
[9]
arXiv preprint arXiv:2410.07718 (2024)
Cui, J., Li, H., Yao, Y., Zhu, H., Shang, H., Cheng, K., Zhou, H., Zhu, S., Wang, J.: Hallo2: Long-duration and high-resolution audio-driven portrait image animation. arXiv preprint arXiv:2410.07718 (2024)
-
[10]
arXiv preprint arXiv:2501.18801 (2025)
Dong, Z., Hao, W., Wang, J.C., Zhang, P., Polak, P.: Every image listens, ev- ery image dances: Music-driven image animation. arXiv preprint arXiv:2501.18801 (2025)
-
[11]
arXiv e-prints pp
Feng, X., Yu, H., Wu, M., Hu, S., Chen, J., Zhu, C., Wu, J., Chu, X., Huang, K.: Narrlv: Towards a comprehensive narrative-centric evaluation for long video generation models. arXiv e-prints pp. arXiv–2507 (2025)
2025
-
[12]
arXiv preprint arXiv:2508.18621 (2025)
Gao, X., Hu, L., Hu, S., Huang, M., Ji, C., Meng, D., Qi, J., Qiao, P., Shen, Z., Song, Y., et al.: Wan-s2v: Audio-driven cinematic video generation. arXiv preprint arXiv:2508.18621 (2025)
-
[13]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Gong, K., Lian, D., Chang, H., Guo, C., Jiang, Z., Zuo, X., Mi, M.B., Wang, X.: Tm2d: Bimodality driven 3d dance generation via music-text integration. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 9942–9952 (2023)
2023
-
[14]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Hong, S., Kemelmacher-Shlizerman, I., Curless, B., Seitz, S.M.: Musicinfuser: Mak- ing video diffusion listen and dance. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 43751–43761 (June 2026)
2026
-
[15]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Hu, L.: Animate anyone: Consistent and controllable image-to-video synthesis for character animation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 8153–8163 (2024)
2024
-
[16]
Embedding-perturbed Exploration Preference Optimization for Flow Models
Hu, S., Chen, C., Zhu, J., Wu, J., Chu, X., Li, X.: Embedding-perturbed explo- ration preference optimization for flow models. arXiv preprint arXiv:2605.15803 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[17]
Jia, T., Yang, K., Yang, X., Tang, X., Qiu, K., Wei, S., Zhao, Y.: Bitdiff: Fine- grained3dconductingmotiongenerationviabimamba-transformerdiffusion.arXiv preprint arXiv:2604.04395 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[18]
Kong, W., Tian, Q., Zhang, Z., Min, R., Dai, Z., Zhou, J., Xiong, J., Li, X., Wu, B., Zhang, J., Wu, K., Lin, Q., Yuan, J., Long, Y., Wang, A., Wang, A., Li, C., Huang, D., Yang, F., Tan, H., Wang, H., Song, J., Bai, J., Wu, J., Xue, J., Wang, OmniDance 17 J., Wang, K., Liu, M., Li, P., Li, S., Wang, W., Yu, W., Deng, X., Li, Y., Chen, Y., Cui, Y., Peng, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
arXiv preprint arXiv:2510.12586 (2025)
Lei, J., Liu, K., Berner, J., Yu, H., Zheng, H., Wu, J., Chu, X.: There is no vae: End-to-end pixel-space generative modeling via self-supervised pre-training. arXiv preprint arXiv:2510.12586 (2025)
-
[20]
In: Pro- ceedings of the IEEE/CVF International Conference on Computer Vision
Li, H., Wang, Y., Huang, T., Huang, H., Wang, H., Chu, X.: Ld-rps: Zero-shot unified image restoration via latent diffusion recurrent posterior sampling. In: Pro- ceedings of the IEEE/CVF International Conference on Computer Vision. pp. 13684–13694 (2025)
2025
-
[21]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Li, K., Wang, Y., He, Y., Li, Y., Wang, Y., Liu, Y., Wang, Z., Xu, J., Chen, G., Luo, P., et al.: Mvbench: A comprehensive multi-modal video understanding benchmark. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 22195–22206 (2024)
2024
-
[22]
In: Proceed- ings of the IEEE/CVF International Conference on Computer Vision
Li, R., Zhao, J., Zhang, Y., Su, M., Ren, Z., Zhang, H., Tang, Y., Li, X.: Finedance: A fine-grained choreography dataset for 3d full body dance generation. In: Proceed- ings of the IEEE/CVF International Conference on Computer Vision. pp. 10234– 10243 (2023)
2023
-
[23]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Li, R., Yang, S., Ross, D.A., Kanazawa, A.: Ai choreographer: Music conditioned 3d dance generation with aist++. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 13401–13412 (2021)
2021
-
[24]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Ling, X., Zhu, C., Wu, M., Li, H., Feng, X., Yang, C., Hao, A., Zhu, J., Wu, J., Chu, X.: Vmbench: A benchmark for perception-aligned video motion generation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 13087–13098 (2025)
2025
-
[25]
arXiv preprint arXiv:2507.03905 (2025)
Meng, R., Wang, Y., Wu, W., Zheng, R., Li, Y., Ma, C.: Echomimicv3: 1.3 b pa- rameters are all you need for unified multi-modal and multi-task human animation. arXiv preprint arXiv:2507.03905 (2025)
-
[26]
In: Proceedings of the 33rd ACM International Conference on Multimedia
Park, N.T.: M2pe-diff: Music-to-pose encoder for dance video generation lever- aging latent diffusion framework. In: Proceedings of the 33rd ACM International Conference on Multimedia. pp. 2419–2428 (2025)
2025
-
[27]
arXiv preprint arXiv:2512.19546 (2025)
Peng, Z., Chen, Y., Ma, Y., Zhang, G., Sun, Z., Zhou, Z., Zhang, Y., Zhou, Z., Fan, Z., Liu, H., et al.: Actavatar: Temporally-aware precise action control for talking avatars. arXiv preprint arXiv:2512.19546 (2025)
-
[28]
arXiv preprint arXiv:2506.14742 (2025)
Peng, Z., Hu, W., Ma, J., Zhu, X., Zhang, X., Zhao, H., Tian, H., He, J., Liu, H., Fan, Z.: Synctalk++: High-fidelity and efficient synchronized talking heads synthesis using gaussian splatting. arXiv preprint arXiv:2506.14742 (2025)
-
[29]
In: Pro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion
Peng, Z., Hu, W., Shi, Y., Zhu, X., Zhang, X., Zhao, H., He, J., Liu, H., Fan, Z.: Synctalk: The devil is in the synchronization for talking head synthesis. In: Pro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion. pp. 666–676 (2024)
2024
-
[30]
arXiv preprint arXiv:2505.21448 (2025)
Peng, Z., Liu, J., Zhang, H., Liu, X., Tang, S., Wan, P., Zhang, D., Liu, H., He, J.: Omnisync: Towards universal lip synchronization via diffusion transformers. arXiv preprint arXiv:2505.21448 (2025)
-
[31]
In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Siyao, L., Yu, W., Gu, T., Lin, C., Wang, Q., Qian, C., Loy, C.C., Liu, Z.: Bailando: 3d dance generation by actor-critic gpt with choreographic memory. In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 11050–11059 (2022) 18 K. Yang et al
2022
-
[32]
arXiv preprint arXiv:2410.10306 (2024)
Tan, S., Gong, B., Wang, X., Zhang, S., Zheng, D., Zheng, R., Zheng, K., Chen, J., Yang, M.: Animate-x: Universal character image animation with enhanced motion representation. arXiv preprint arXiv:2410.10306 (2024)
-
[33]
IEEE transactions on pattern anal- ysis and machine intelligence (2025)
Tang, H., Shao, L., Zhang, Z., Van Gool, L., Sebe, N.: Spatial-temporal graph mamba for music-guided dance video synthesis. IEEE transactions on pattern anal- ysis and machine intelligence (2025)
2025
-
[34]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Tseng, J., Castellon, R., Liu, K.: Edge: Editable dance generation from music. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 448–458 (2023)
2023
-
[35]
Wan, T., Wang, A., Ai, B., Wen, B., Mao, C., Xie, C.W., Chen, D., Yu, F., Zhao, H., Yang, J., Zeng, J., Wang, J., Zhang, J., Zhou, J., Wang, J., Chen, J., Zhu, K., Zhao, K., Yan, K., Huang, L., Feng, M., Zhang, N., Li, P., Wu, P., Chu, R., Feng, R., Zhang, S., Sun, S., Fang, T., Wang, T., Gui, T., Weng, T., Shen, T., Lin, W., Wang, W., Wang, W., Zhou, W.,...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
In: Proceedings of the 33rd ACM International Conference on Multimedia
Wang, X., Wang, H., Cai, W.: Choreomuse: Robust music-to-dance video gener- ation with style transfer and beat-adherent motion. In: Proceedings of the 33rd ACM International Conference on Multimedia. pp. 7912–7921 (2025)
2025
-
[37]
In: 2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)
Wang, X., Wang, H., Liu, D., Cai, W.: Dance any beat: Blending beats with visuals in dance video generation. In: 2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV). pp. 5136–5146. IEEE (2025)
2025
-
[38]
Advances in neural information processing systems35, 38571–38584 (2022)
Xu, Y., Zhang, J., Zhang, Q., Tao, D.: Vitpose: Simple vision transformer baselines for human pose estimation. Advances in neural information processing systems35, 38571–38584 (2022)
2022
-
[39]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Xu, Z., Zhang, J., Liew, J.H., Yan, H., Liu, J.W., Zhang, C., Feng, J., Shou, M.Z.: Magicanimate: Temporally consistent human image animation using diffu- sion model. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 1481–1490 (2024)
2024
-
[40]
In: Proceedings of the 2024 International Conference on Multimedia Retrieval
Yang, K., Tang, X., Diao, R., Liu, H., He, J., Fan, Z.: Codancers: Music-driven coherent group dance generation with choreographic unit. In: Proceedings of the 2024 International Conference on Multimedia Retrieval. pp. 675–683 (2024)
2024
-
[41]
arXiv preprint arXiv:2505.14222 (2025)
Yang, K., Tang, X., Hu, Y., Yang, J., Liu, H., Zhang, Q., He, J., Fan, Z.: Match- dance: Collaborative mamba-transformer architecture matching for high-quality 3d dance synthesis. arXiv preprint arXiv:2505.14222 (2025)
-
[42]
arXiv preprint arXiv:2505.17543 (2025)
Yang, K., Tang, X., Peng, Z., Hu, Y., He, J., Liu, H.: Megadance: Mixture- of-experts architecture for genre-aware 3d dance generation. arXiv preprint arXiv:2505.17543 (2025)
-
[43]
FlowerDance: MeanFlow for Efficient and Refined 3D Dance Generation
Yang, K., Tang, X., Peng, Z., Zhang, X., Wang, P., He, J., Liu, H.: Flower- dance: Meanflow for efficient and refined 3d dance generation. arXiv preprint arXiv:2511.21029 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
arXiv preprint arXiv:2412.19123 (2024)
Yang, K., Tang, X., Wu, H., Xue, Q., Qin, B., Liu, H., Fan, Z.: Cohedancers: Enhancing interactive group dance generation through music-driven coherence de- composition. arXiv preprint arXiv:2412.19123 (2024)
-
[45]
In: Proceedings of the 2024 International Conference on Multimedia Retrieval
Yang, K., Zhou, X., Tang, X., Diao, R., Liu, H., He, J., Fan, Z.: Beatdance: A beat- based model-agnostic contrastive learning framework for music-dance retrieval. In: Proceedings of the 2024 International Conference on Multimedia Retrieval. pp. 11–19 (2024) OmniDance 19
2024
-
[46]
MACE-Dance: Motion-Appearance Cascaded Experts for Music-Driven Dance Video Generation
Yang, K., Zhu, J., Tang, X., Peng, Z., Zhang, X., Wang, P., Wu, J., Chu, X., Liu, H., He, J.: Mace-dance: Motion-appearance cascaded experts for music-driven dance video generation. arXiv preprint arXiv:2512.18181 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[47]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Yang, Z., Teng, J., Zheng, W., Ding, M., Huang, S., Xu, J., Yang, Y., Hong, W., Zhang, X., Feng, G., et al.: Cogvideox: Text-to-video diffusion models with an expert transformer. arXiv preprint arXiv:2408.06072 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[48]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Yang, Z., Yang, K., Tang, X.: Tokendance: Token-to-token music-to-dance gener- ation with bidirectional mamba. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 5520–5529 (2026)
2026
-
[49]
PersonaGesture: Single-Reference Co-Speech Gesture Personalization for Unseen Speakers
Zhang, X., Cai, Y., Li, K., Yang, K., Zhou, Y., Li, Z., Chu, X., Zhang, J., Liu, H.: Personagesture: Single-reference co-speech gesture personalization for unseen speakers. arXiv preprint arXiv:2605.06064 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[50]
IEEE Transactions on Circuits and Systems for Video Technology (2025)
Zhang, X., Jia, Y., Zhang, J., Yang, Y., Tu, Z.: Robust 2d skeleton action recogni- tion via decoupling and distilling 3d latent features. IEEE Transactions on Circuits and Systems for Video Technology (2025)
2025
-
[51]
In: Pro- ceedings of the AAAIConference on Artificial Intelligence.vol
Zhang, X., Li, J., Ren, J., Zhang, J.: Mitigating error accumulation in co-speech motion generation via global rotation diffusion and multi-level constraints. In: Pro- ceedings of the AAAIConference on Artificial Intelligence.vol. 40, pp. 12834–12842 (2026)
2026
-
[52]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Zhang, X., Li, J., Zhang, J., Dang, Z., Ren, J., Bo, L., Tu, Z.: Semtalk: Holistic co-speech motion generation with frame-level semantic emphasis. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 13761–13771 (2025)
2025
-
[53]
In: Pro- ceedings of the 33rd ACM International Conference on Multimedia
Zhang, X., Li, J., Zhang, J., Ren, J., Bo, L., Tu, Z.: Echomask: Speech-queried attention-based mask modeling for holistic co-speech motion generation. In: Pro- ceedings of the 33rd ACM International Conference on Multimedia. pp. 10827– 10836 (2025)
2025
-
[54]
arXiv preprint arXiv:2603.29655 (2026)
Zhou, P., Zhang, X., Shen, X., Hu, Y.: Not all frames are equal: Complexity- aware masked motion generation via motion spectral descriptors. arXiv preprint arXiv:2603.29655 (2026)
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.