E-PMQ: Expert-Guided Post-Merge Quantization with Merged-Weight Anchoring
Pith reviewed 2026-05-19 20:56 UTC · model grok-4.3
pith:MSLFK6E5 Add to your LaTeX paper
What is a Pith Number?\usepackage{pith}
\pithnumber{MSLFK6E5}
Prints a linked pith:MSLFK6E5 badge after your title and writes the identifier into PDF metadata. Compiles on arXiv with no extra files. Learn more
The pith
Expert-guided calibration with source experts and merged-weight anchoring makes post-merge quantization reliable for multi-task models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
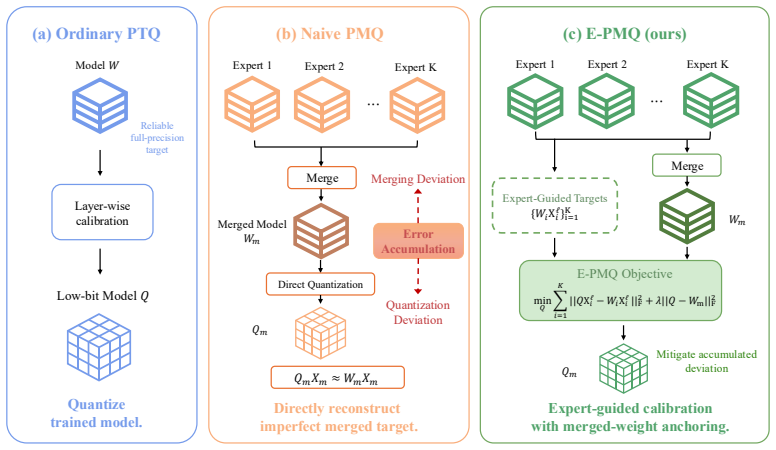
E-PMQ formulates the post-merge quantization setting and demonstrates that expert-guided output targets during layer-wise calibration, paired with merged-weight anchoring, mitigate both the quantization deviation and the expert-relative merging deviation, producing large accuracy gains on merged vision and language models.
What carries the argument
Expert-guided output targets from source experts during layer-wise calibration together with merged-weight anchoring to preserve integrated merged behavior.
If this is right
- On eight-task CLIP-ViT-B/32 merging, 4-bit E-PMQ raises accuracy from 65.0% to 73.6% under Task Arithmetic and from 69.1% to 74.8% under TIES-Merging.
- On the harder 20-task CLIP-ViT-L/14 setting, E-PMQ raises accuracy from 34.8% to 76.7%.
- On FLAN-T5-base GLUE merging, E-PMQ improves from 78.26% to 83.34%.
- The same anchoring and expert-target technique applies across different merging methods without requiring joint retraining.
Where Pith is reading between the lines
- If original experts are routinely discarded after merging, the method would require either keeping them or regenerating equivalent targets, limiting plug-and-play use.
- The same separation of merging deviation from quantization deviation could be tested on other post-processing steps such as pruning or distillation of merged models.
- Layer-wise calibration guided by experts may generalize to new merging algorithms beyond Task Arithmetic and TIES.
- The approach implies that post-merge pipelines benefit from retaining some access to source models specifically for calibration stages.
Load-bearing premise
Source expert weights remain available after merging and can supply reliable output targets during calibration without introducing distribution shift or extra bias relative to the merged model's integrated behavior.
What would settle it
Running the same layer-wise calibration but replacing expert outputs with outputs sampled from the merged model itself and observing no accuracy gain or even degradation.
Figures


read the original abstract
Low-resource deployment constraints have made model quantization essential for deploying neural networks while preserving performance. Meanwhile, model merging has become an increasingly practical low-resource strategy for integrating multiple task- or domain-specialized experts into a single model without joint training or multi-model serving. Together, quantization and model merging enable an efficient low-resource deployment pipeline by integrating multiple experts into one low-bit model. We formulate this setting as Post-Merge Quantization (PMQ). We show that directly applying post-training quantization (PTQ) to a merged model is unreliable because two distinct deviations are coupled: the quantization deviation introduced by low-bit reconstruction and the expert-relative merging deviation inherited from model merging. To mitigate these deviations, we propose E-PMQ, an expert-guided PMQ framework that uses source expert weights to provide expert- guided output targets during layer-wise calibration, together with merged-weight anchoring to stabilize the calibration and preserve the integrated behavior of the merged model. On CLIP-ViT-B/32 eight-task merging, E-PMQ improves 4-bit GPTQ from 65.0% to 73.6% under Task Arithmetic and from 69.1% to 74.8% under TIES-Merging. On harder settings, E-PMQ improves GPTQ from 34.8% to 76.7% on 20-task CLIP-ViT-L/14 and from 78.26% to 83.34% on FLAN-T5- base GLUE. These results demonstrate that E-PMQ enables effective post-merge quantization and low-bit deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces E-PMQ, a framework for post-merge quantization (PMQ) of models formed by merging multiple task- or domain-specialized experts. It identifies that standard post-training quantization applied to merged models suffers from coupled quantization deviation and expert-relative merging deviation. To mitigate this, E-PMQ uses source expert weights to supply expert-guided output targets during layer-wise calibration, combined with merged-weight anchoring to stabilize calibration and preserve the merged model's integrated behavior. Experiments report substantial accuracy gains over baseline 4-bit GPTQ, including lifts from 65.0% to 73.6% on 8-task CLIP-ViT-B/32 Task Arithmetic merging, from 69.1% to 74.8% under TIES-Merging, from 34.8% to 76.7% on 20-task CLIP-ViT-L/14, and from 78.26% to 83.34% on FLAN-T5-base GLUE.
Significance. If the central claims hold and the method generalizes beyond the reported settings, this work would be significant for practical low-resource deployment pipelines that combine model merging with quantization. It provides a concrete approach to handling the interaction between merging and low-bit reconstruction without requiring joint retraining, with reported gains that could enable more reliable multi-expert models on constrained hardware. The explicit separation of deviations and use of anchoring represent a targeted extension of existing PTQ techniques.
major comments (2)
- [Abstract] Abstract: The abstract reports concrete accuracy lifts (e.g., 34.8% to 76.7% on 20-task CLIP-ViT-L/14) but provides no error bars, ablation details, or full experimental protocol; this makes it difficult to assess reliability and isolate whether gains stem from mitigating coupled deviations or other factors.
- [Method] Method section (around the description of expert-guided targets and anchoring): The method supplies layer-wise calibration targets from individual source experts rather than from the merged model itself. Because merging (Task Arithmetic or TIES) produces a non-linear combination of expert behaviors, the expert outputs on a given input can differ systematically from the merged model's outputs; if this mismatch is large, the quantization optimizes toward expert-specific distributions instead of the integrated merged distribution, and merged-weight anchoring may only partially compensate.
minor comments (2)
- [Experiments] Experiments: Clarify the calibration dataset size, sampling strategy, and any steps taken to ensure the expert targets do not introduce distribution shift relative to the merged model.
- [Notation] Notation and figures: Ensure consistent use of symbols for merged weights versus expert weights and add legends or captions that explicitly distinguish the anchoring mechanism in any diagrams.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address each major comment below and indicate the corresponding revisions to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract reports concrete accuracy lifts (e.g., 34.8% to 76.7% on 20-task CLIP-ViT-L/14) but provides no error bars, ablation details, or full experimental protocol; this makes it difficult to assess reliability and isolate whether gains stem from mitigating coupled deviations or other factors.
Authors: We agree that the abstract would benefit from additional context on reliability. Due to length constraints, we have revised the abstract to note that reported accuracies are means over three random seeds with standard deviations provided in the experimental results (Section 4). Full protocols, ablation studies, and analysis isolating the contribution of coupled-deviation mitigation appear in Sections 3 and 5 of the revised manuscript. revision: yes
-
Referee: [Method] Method section (around the description of expert-guided targets and anchoring): The method supplies layer-wise calibration targets from individual source experts rather than from the merged model itself. Because merging (Task Arithmetic or TIES) produces a non-linear combination of expert behaviors, the expert outputs on a given input can differ systematically from the merged model's outputs; if this mismatch is large, the quantization optimizes toward expert-specific distributions instead of the integrated merged distribution, and merged-weight anchoring may only partially compensate.
Authors: We acknowledge the referee's point on potential output mismatch arising from non-linear merging. Our design intentionally uses expert outputs as calibration targets to supply specialized, high-fidelity signals while merged-weight anchoring explicitly penalizes deviation from the merged weights during the quantization optimization. This combination is intended to preserve integrated behavior. We have expanded the method section with a new paragraph discussing the rationale, added a quantitative comparison of expert versus merged output distributions on calibration data, and included an ablation isolating the anchoring term to demonstrate its compensatory effect. revision: yes
Circularity Check
No significant circularity: empirical method using independent expert targets
full rationale
The paper proposes E-PMQ as a practical framework that supplies layer-wise calibration targets from source expert weights and applies merged-weight anchoring. These are external inputs to the merged model rather than quantities defined in terms of the final quantized output or fitted directly to the reported accuracy gains. The claimed improvements (e.g., 34.8% to 76.7% on 20-task ViT-L/14) are measured outcomes on held-out benchmarks after applying the procedure; no equation or step equates the result to a self-defined fit, a renamed known pattern, or a load-bearing self-citation chain. The approach remains falsifiable against external data and standard PTQ baselines.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
min_Q sum_i ||Q X_i^ℓ - W_i X_i^ℓ||_F² + λ ||Q - W_m||_F² with adaptive λ from activation energy
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Post-Merge Quantization couples quantization deviation and expert-relative merging deviation
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Alexander, James A. and Mozer, Michael C. , title =. Advances in Neural Information Processing Systems 7 , editor =
- [2]
-
[3]
and Schnell, Eric and Barkai, Edi , title =
Hasselmo, Michael E. and Schnell, Eric and Barkai, Edi , title =. Journal of Neuroscience , volume =
-
[4]
Journal of Modern Power Systems and Clean Energy , volume=
Model Fusion for Scalable and Sustainable Artificial Intelligence: A Review and Outlook , author=. Journal of Modern Power Systems and Clean Energy , volume=. 2026 , publisher=
work page 2026
-
[5]
Democratizing AI through model fusion: A comprehensive review and future directions , author=. Nexus , year=
-
[6]
MergePipe: A Budget-Aware Parameter Management System for Scalable LLM Merging , author=. 2026 , eprint=
work page 2026
-
[7]
Model Merging Scaling Laws in Large Language Models
Model merging scaling laws in large language models , author=. arXiv preprint arXiv:2509.24244 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
arXiv preprint arXiv:2505.13878 , year=
InfiFPO: Implicit model fusion via preference optimization in large language models , author=. arXiv preprint arXiv:2505.13878 , year=
-
[9]
arXiv preprint arXiv:2505.13893 , year=
Infigfusion: Graph-on-logits distillation via efficient gromov-wasserstein for model fusion , author=. arXiv preprint arXiv:2505.13893 , year=
-
[10]
arXiv preprint arXiv:2602.08229 , year=
InfiCoEvalChain: A Blockchain-Based Decentralized Framework for Collaborative LLM Evaluation , author=. arXiv preprint arXiv:2602.08229 , year=
-
[11]
InfiR2: A Comprehensive FP8 Training Recipe for Reasoning-Enhanced Language Models , author=. 2025 , eprint=
work page 2025
-
[12]
Journal of Machine Learning Research , volume=
FusionBench: A Unified Library and Comprehensive Benchmark for Deep Model Fusion , author=. Journal of Machine Learning Research , volume=
-
[13]
International Conference on Machine Learning , pages=
Learning Transferable Visual Models From Natural Language Supervision , author=. International Conference on Machine Learning , pages=
-
[14]
Journal of Machine Learning Research , volume=
Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer , author=. Journal of Machine Learning Research , volume=
-
[15]
International Conference on Learning Representations , year=
Finetuned Language Models are Zero-Shot Learners , author=. International Conference on Learning Representations , year=
-
[16]
Journal of Machine Learning Research , volume=
Scaling Instruction-Finetuned Language Models , author=. Journal of Machine Learning Research , volume=
-
[17]
International Conference on Learning Representations , year=
GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding , author=. International Conference on Learning Representations , year=
-
[18]
International Conference on Machine Learning , year=
Model soups: averaging weights of multiple fine-tuned models improves accuracy without increasing inference time , author=. International Conference on Machine Learning , year=
-
[19]
Advances in Neural Information Processing Systems , year=
Merging Models with Fisher-Weighted Averaging , author=. Advances in Neural Information Processing Systems , year=
-
[20]
International Conference on Learning Representations , year=
Editing Models with Task Arithmetic , author=. International Conference on Learning Representations , year=
-
[21]
Advances in Neural Information Processing Systems , year=
TIES-Merging: Resolving Interference When Merging Models , author=. Advances in Neural Information Processing Systems , year=
-
[22]
Language Models are Super Mario: Absorbing Abilities from Homologous Models as a Free Lunch , author=. 2024 , eprint=
work page 2024
-
[23]
International Conference on Machine Learning , year=
Up or Down? Adaptive Rounding for Post-Training Quantization , author=. International Conference on Machine Learning , year=
-
[24]
International Conference on Learning Representations , year=
BRECQ: Pushing the Limit of Post-Training Quantization by Block Reconstruction , author=. International Conference on Learning Representations , year=
-
[25]
International Conference on Learning Representations , year=
GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers , author=. International Conference on Learning Representations , year=
-
[26]
Proceedings of Machine Learning and Systems , year=
AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration , author=. Proceedings of Machine Learning and Systems , year=
-
[27]
International Conference on Machine Learning , year=
SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models , author=. International Conference on Machine Learning , year=
-
[28]
Advances in Neural Information Processing Systems , year=
ZeroQuant: Efficient and Affordable Post-Training Quantization for Large-Scale Transformers , author=. Advances in Neural Information Processing Systems , year=
-
[29]
IEEE Conference on Computer Vision and Pattern Recognition , year=
SUN Database: Large-scale Scene Recognition from Abbey to Zoo , author=. IEEE Conference on Computer Vision and Pattern Recognition , year=
-
[30]
IEEE International Conference on Computer Vision Workshops , year=
3D Object Representations for Fine-Grained Categorization , author=. IEEE International Conference on Computer Vision Workshops , year=
-
[31]
Proceedings of the IEEE , volume=
Remote Sensing Image Scene Classification: Benchmark and State of the Art , author=. Proceedings of the IEEE , volume=
-
[32]
IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing , volume=
EuroSAT: A Novel Dataset and Deep Learning Benchmark for Land Use and Land Cover Classification , author=. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing , volume=
-
[33]
NeurIPS Workshop on Deep Learning and Unsupervised Feature Learning , year=
Reading Digits in Natural Images with Unsupervised Feature Learning , author=. NeurIPS Workshop on Deep Learning and Unsupervised Feature Learning , year=
-
[34]
International Joint Conference on Neural Networks , year=
The German Traffic Sign Recognition Benchmark: A multi-class classification competition , author=. International Joint Conference on Neural Networks , year=
-
[35]
Proceedings of the IEEE , volume=
Gradient-Based Learning Applied to Document Recognition , author=. Proceedings of the IEEE , volume=
-
[36]
IEEE Conference on Computer Vision and Pattern Recognition , year=
Describing Textures in the Wild , author=. IEEE Conference on Computer Vision and Pattern Recognition , year=
-
[37]
Indian Conference on Computer Vision, Graphics and Image Processing , year=
Automated Flower Classification over a Large Number of Classes , author=. Indian Conference on Computer Vision, Graphics and Image Processing , year=
-
[38]
Medical Image Computing and Computer Assisted Intervention , year=
Rotation Equivariant CNNs for Digital Pathology , author=. Medical Image Computing and Computer Assisted Intervention , year=
-
[39]
Challenges in Representation Learning: A Report on Three Machine Learning Contests , author=. Neural Networks , volume=
-
[40]
IEEE Conference on Computer Vision and Pattern Recognition , year=
Cats and Dogs , author=. IEEE Conference on Computer Vision and Pattern Recognition , year=
-
[41]
International Conference on Artificial Intelligence and Statistics , year=
An Analysis of Single-Layer Networks in Unsupervised Feature Learning , author=. International Conference on Artificial Intelligence and Statistics , year=
-
[42]
Learning Multiple Layers of Features from Tiny Images , author=
-
[43]
European Conference on Computer Vision , year=
Food-101 -- Mining Discriminative Components with Random Forests , author=. European Conference on Computer Vision , year=
-
[44]
Fashion-MNIST: a Novel Image Dataset for Benchmarking Machine Learning Algorithms
Fashion-MNIST: A Novel Image Dataset for Benchmarking Machine Learning Algorithms , author=. arXiv preprint arXiv:1708.07747 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[45]
International Joint Conference on Neural Networks , year=
EMNIST: Extending MNIST to handwritten letters , author=. International Joint Conference on Neural Networks , year=
-
[46]
Deep Learning for Classical Japanese Literature
Deep Learning for Classical Japanese Literature , author=. arXiv preprint arXiv:1812.01718 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[47]
Conference on Empirical Methods in Natural Language Processing , year=
Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank , author=. Conference on Empirical Methods in Natural Language Processing , year=
-
[48]
Proceedings of the 42nd International Conference on Machine Learning , series=
Whoever Started the Interference Should End It: Guiding Data-Free Model Merging via Task Vectors , author=. Proceedings of the 42nd International Conference on Machine Learning , series=. 2025 , publisher=
work page 2025
-
[49]
Representation Surgery for Multi-Task Model Merging , author=. 2024 , eprint=
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.