Second-Order Least Squares as a Special Case of the Polynomial Maximization Method
Pith reviewed 2026-06-27 12:09 UTC · model grok-4.3
The pith
Optimally weighted second-order least squares equals degree-two polynomial maximization for linear regression under conditional homoskedasticity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
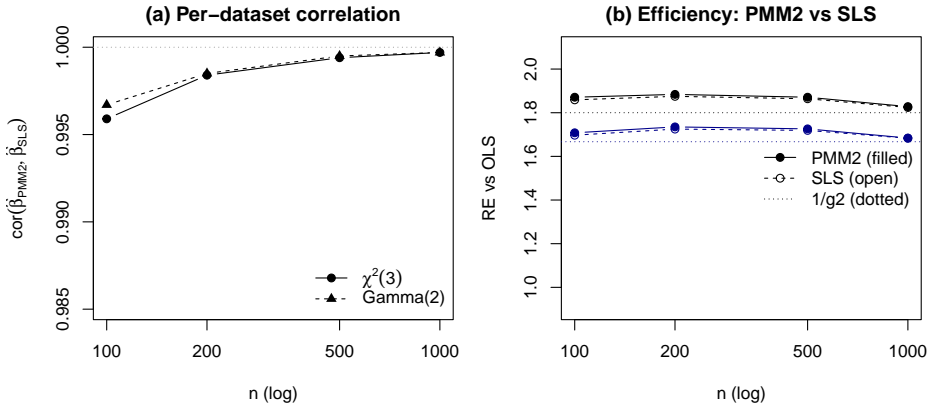
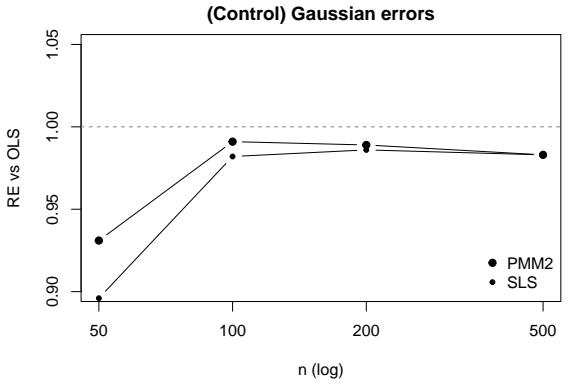
Optimally weighted second-order least squares (SLS) and the degree-two generalized polynomial maximization method (PMM) are the same population estimating equation for linear regression with conditionally homoskedastic non-Gaussian errors: they choose the same optimal linear combination of the first two centered residual moments, solve one population normal system, share one influence function, and attain the common asymptotic variance c2 g2 / N -- the ordinary-least-squares slope-variance factor c2 scaled by the PMM variance-reduction coefficient g2=1-γ3²/(2+γ4).
What carries the argument
The shared population estimating equation formed by the optimal linear combination of the first two centered residual moments under conditional homoskedasticity.
If this is right
- Feasible plug-in implementations of optimally weighted SLS and degree-two PMM are first-order equivalent.
- Under heteroskedasticity the unconditional PMM and conditional SLS weighting separate, costing efficiency for symmetric errors and consistency for asymmetric errors.
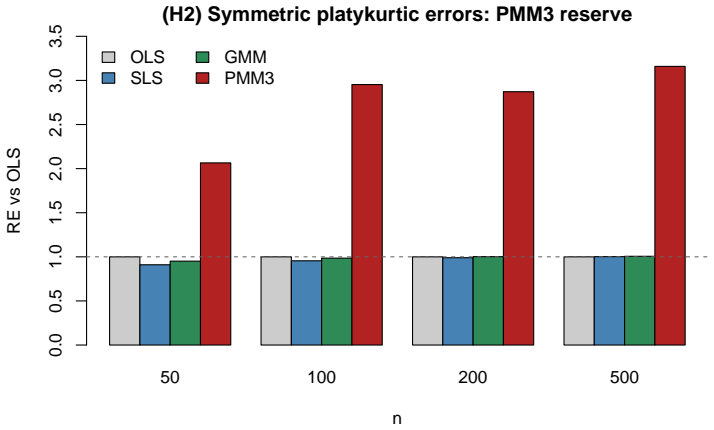
- Beyond degree two, PMM holds an efficiency reserve unreachable by SLS within its second-moment span.
- For symmetric platykurtic errors SLS collapses to ordinary least squares for the slope while degree-three PMM exploits kurtosis information outside the SLS moment span.
Where Pith is reading between the lines
- Researchers applying either method to gain efficiency with non-normal errors are using equivalent procedures at the population level when conditional homoskedasticity holds.
- The separation under heteroskedasticity suggests that tests for conditional variance constancy may be needed before relying on either estimator for efficiency gains.
- Higher-degree PMM versions could be examined for further efficiency gains in settings where SLS remains restricted to second moments.
Load-bearing premise
The regression errors have constant conditional variance given the predictors.
What would settle it
An empirical or simulated dataset with heteroskedastic errors where the two methods produce statistically different slope estimates or where one is consistent and the other is not.
Figures
read the original abstract
We prove that optimally weighted second-order least squares (SLS) and the degree-two generalized polynomial maximization method (PMM) are the same population estimating equation for linear regression with conditionally homoskedastic non-Gaussian errors: they choose the same optimal linear combination of the first two centered residual moments, solve one population normal system, share one influence function, and attain the common asymptotic variance $c_2g_2/N$ -- the ordinary-least-squares slope-variance factor $c_2$ scaled by the PMM variance-reduction coefficient $g_2=1-\gamma_3^2/(2+\gamma_4)$ (with $\gamma_3,\gamma_4$ the error skewness and excess kurtosis). Feasible plug-in implementations are therefore first-order equivalent, with only higher-order finite-sample differences. The identity is sharp: under heteroskedasticity the unconditional PMM body and the conditional SLS weighting separate, costing efficiency for symmetric errors and consistency for asymmetric errors. Beyond degree two, PMM holds an efficiency reserve that SLS cannot reach within its second-moment span. For symmetric platykurtic errors SLS collapses to ordinary least squares for the slope, while degree-three PMM exploits kurtosis information outside the SLS moment span through a closed-form coefficient $g_3$; for canonical asymmetric laws this reserve is $30$--$50\%$ within the degree-three polynomial moment class. The Lean 4 development machine-checks the degree-specific algebraic core -- the closed forms for $g_2$ and $g_3$, the $g_2\le1$ result, the design cancellations, and the symmetric collapse -- while the general monotonicity $g_{S+1}\le g_S\le1$ is proved analytically by nesting. A Monte Carlo study illustrates the equivalence, the reserve, and the heteroskedastic boundary at finite samples.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proves that optimally weighted second-order least squares (SLS) and the degree-two generalized polynomial maximization method (PMM) coincide as population estimating equations for linear regression under conditional homoskedasticity with non-Gaussian errors. They select the same optimal linear combination of the first two centered residual moments, solve identical normal equations, share an influence function, and attain the common asymptotic variance c₂g₂/N where g₂ = 1 - γ₃²/(2 + γ₄). The equivalence is shown to be sharp under heteroskedasticity (where unconditional PMM and conditional SLS weighting diverge), while higher-degree PMM retains efficiency reserves beyond the SLS second-moment span. The algebraic core (closed forms for g₂, g₃, g₂ ≤ 1, design cancellations, symmetric collapse) is machine-checked in Lean 4; monotonicity g_{S+1} ≤ g_S ≤ 1 is proved analytically by nesting; a Monte Carlo study illustrates finite-sample behavior and the heteroskedastic boundary.
Significance. If the result holds, the paper unifies two moment-based estimators by exhibiting an explicit algebraic identity at the population level, with the machine-checked Lean 4 proofs of the closed forms for g₂ and g₃, the g₂ ≤ 1 bound, design cancellations, and symmetric collapse constituting a verifiable strength. The analytic nesting proof for monotonicity and the Monte Carlo confirmation of the equivalence, reserve, and heteroskedasticity caveat further support the contribution. This clarifies when SLS is a special case of PMM and quantifies the efficiency gains available from higher polynomial moments for non-Gaussian errors.
minor comments (1)
- §3, after Eq. (12): the notation for the feasible plug-in estimators could be clarified by explicitly distinguishing the population g₂ from its sample analogue ĝ₂ in the statement of first-order equivalence.
Simulated Author's Rebuttal
We thank the referee for the careful reading of the manuscript and for the positive assessment. We are pleased that the referee recommends acceptance.
Circularity Check
No significant circularity
full rationale
The paper presents a direct population-level algebraic proof that optimally weighted SLS and degree-2 PMM coincide as estimating equations under conditional homoskedasticity, deriving the shared influence function, normal equations, and asymptotic variance c2 g2/N from the same linear combination of centered residual moments. The derivation relies on explicit moment conditions and design cancellations without fitted parameters renamed as predictions or self-referential definitions. The Lean 4 machine-check verifies the closed forms for g2, g3, the g2 ≤ 1 bound, and symmetric collapse, while the general monotonicity is proved by analytic nesting; these are independent verifications rather than load-bearing self-citations. The heteroskedasticity caveat is stated as a boundary condition with Monte Carlo confirmation. No step reduces to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Linear regression model Y = Xβ + ε with E(ε|X) = 0 and Var(ε|X) = σ² (conditional homoskedasticity)
- domain assumption Existence of third and fourth moments of the error distribution (skewness γ3 and excess kurtosis γ4)
Reference graph
Works this paper leans on
-
[1]
Peter J. Bickel. On adaptive estimation.The Annals of Statistics, 10(3):647–671, 1982. doi: 10.1214/aos/1176345863
-
[2]
Asymptotic efficiency in estimation with conditional moment restrictions
Gary Chamberlain. Asymptotic efficiency in estimation with conditional moment restrictions. Journal of Econometrics, 34(3):305–334, 1987
1987
-
[3]
On linear and quadratic estimating functions.Biometrika, 74(3):591–597,
Martin Crowder. On linear and quadratic estimating functions.Biometrika, 74(3):591–597,
-
[4]
doi: 10.1093/biomet/74.3.591
-
[5]
V. P. Godambe. An optimum property of regular maximum likelihood estimation.The Annals of Mathematical Statistics, 31(4):1208–1211, 1960
1960
-
[6]
V. P. Godambe and M. E. Thompson. An extension of quasi-likelihood estimation.Journal of Statistical Planning and Inference, 22(2):137–152, 1989
1989
-
[7]
Large sample properties of generalized method of moments estimators
Lars Peter Hansen. Large sample properties of generalized method of moments estimators. Econometrica, 50(4):1029–1054, 1982
1982
-
[8]
Heyde.Quasi-Likelihood and Its Application: A General Approach to Optimal Parameter Estimation
Christopher C. Heyde.Quasi-Likelihood and Its Application: A General Approach to Optimal Parameter Estimation. Springer, New York, 1997
1997
-
[9]
J. R. M. Hosking. L-moments: analysis and estimation of distributions using linear combi- nations of order statistics.Journal of the Royal Statistical Society, Series B, 52(1):105–124, 1990
1990
-
[10]
Huber.Robust Statistics
Peter J. Huber.Robust Statistics. Wiley, 1981
1981
-
[11]
The efficiency of the second-order nonlinear least squares estimator and its extension.Annals of the Institute of Statistical Mathematics, 64:751–764,
Mijeong Kim and Yanyuan Ma. The efficiency of the second-order nonlinear least squares estimator and its extension.Annals of the Institute of Statistical Mathematics, 64:751–764,
-
[12]
doi: 10.1007/s10463-011-0332-y
-
[13]
Kunchenko.Polynomial Parameter Estimations of Close to Gaussian Random Vari- ables
Yuriy P. Kunchenko.Polynomial Parameter Estimations of Close to Gaussian Random Vari- ables. Shaker Verlag, Aachen, 2002
2002
-
[14]
Jerry M. Mendel. Tutorial on higher-order statistics (spectra) in signal processing and system theory.Proceedings of the IEEE, 79(3):278–305, 1991
1991
-
[15]
Whitney K. Newey. Efficient estimation of models with conditional moment restrictions. In G. S. Maddala, C. R. Rao, and H. D. Vinod, editors,Handbook of Statistics, Vol. 11: Econo- metrics, pages 419–454. North-Holland, Amsterdam, 1993
1993
-
[16]
Annie Qu, Bruce G. Lindsay, and Bing Li. Improving generalised estimating equations using quadratic inference functions.Biometrika, 87(4):823–836, 2000. doi: 10.1093/biomet/87.4.823
-
[17]
Estimation of nonlinear Berkson-type measurement error models.Statistica Sinica, 13:1201–1210, 2003
Liqun Wang. Estimation of nonlinear Berkson-type measurement error models.Statistica Sinica, 13:1201–1210, 2003. 25
2003
-
[18]
Liqun Wang and Alexandre Leblanc. Second-order nonlinear least squares estimation.Annals of the Institute of Statistical Mathematics, 60:883–900, 2008. doi: 10.1007/s10463-007-0139-z
-
[19]
EstemPMM: Polynomial maximization method estimation.https://cran
Serhii Zabolotnii. EstemPMM: Polynomial maximization method estimation.https://cran. r-project.org/package=EstemPMM, 2026. R package version 0.4.0
2026
-
[20]
Warsza, and Oleksandr Tkachenko
Serhii Zabolotnii, Zygmunt L. Warsza, and Oleksandr Tkachenko. Polynomial estimation of linear regression parameters for the asymmetric PDF of errors. InAutomation 2018, Advances in Intelligent Systems and Computing, pages 758–772, Cham, 2018. Springer. doi: 10.1007/ 978-3-319-77179-3_75
2018
-
[21]
Warsza, and Oleksandr Tkachenko
Serhii Zabolotnii, Zygmunt L. Warsza, and Oleksandr Tkachenko. Estimation of linear re- gression parameters of symmetric non-Gaussian errors by polynomial maximization method. InAutomation 2019, Advances in Intelligent Systems and Computing, pages 636–649, Cham,
2019
-
[22]
doi: 10.1007/978-3-030-13273-6_59
Springer. doi: 10.1007/978-3-030-13273-6_59
-
[23]
Serhii Zabolotnii, Oleksandr Tkachenko, Waldemar Nowakowski, and Zygmunt L. Warsza. Ap- plication of the polynomial maximization method for estimating nonlinear regression param- eters with non-Gaussian asymmetric errors. InAutomation 2024, Lecture Notes in Networks and Systems, pages 342–356, Cham, 2024. Springer. doi: 10.1007/978-3-031-78266-4_30. 26
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.