Encoder-Decoder Manifold Alignment for Idempotent Generation
Pith reviewed 2026-06-26 11:17 UTC · model grok-4.3
The pith
Aligning encoder and decoder manifolds produces stable fixed points under repeated generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
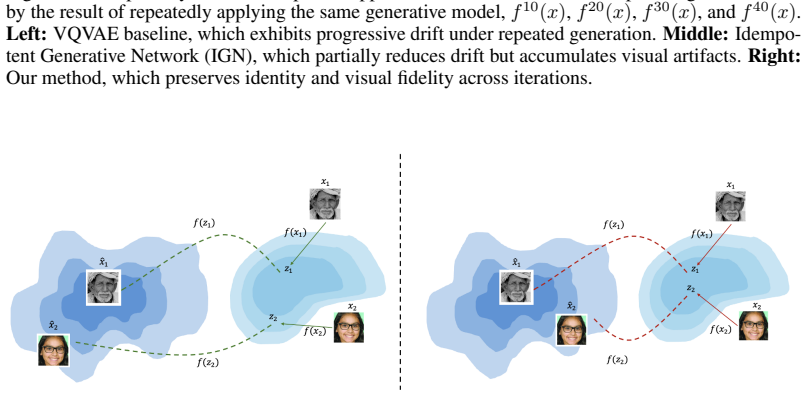
The central claim is that a geometric mismatch between the manifold learned by the encoder and the manifold implicitly learned by the decoder prevents true fixed points. By explicitly closing this gap through training that forces consistent representations of the same data manifold, the model learns stable projections where repeated application leaves samples unchanged.
What carries the argument
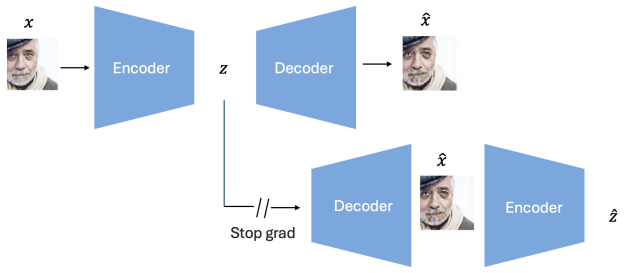
Encoder-decoder manifold alignment, which enforces geometric consistency between the encoder's latent projections and the decoder's reconstructions during training.
If this is right
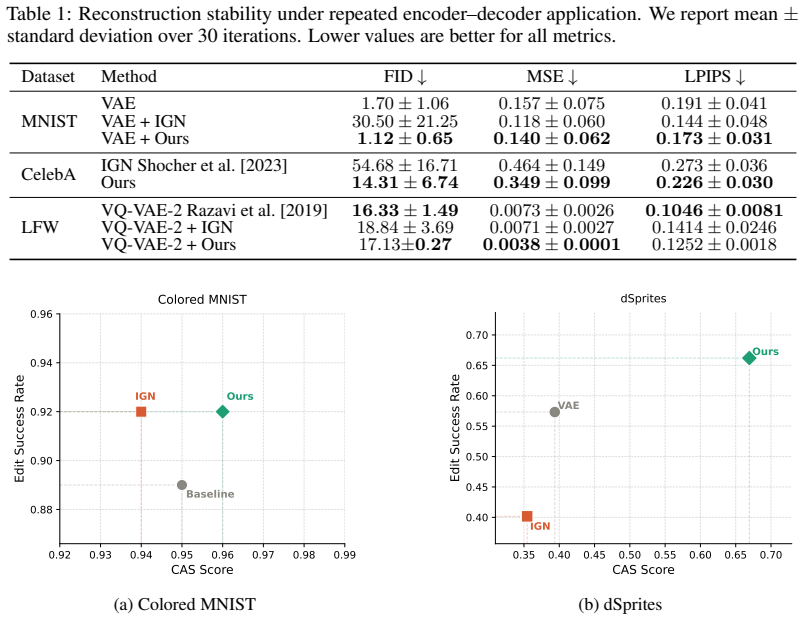
- The method achieves significantly lower idempotency error than existing approaches.
- Repeated application of the model regenerates identical outputs once a sample lies on the target manifold.
- Identity preservation and information stability improve in image editing tasks.
- The framework applies to both image generation and image editing tasks.
Where Pith is reading between the lines
- The alignment objective could be combined with other regularization techniques to further reduce error in high-dimensional domains.
- Similar consistency constraints might apply to sequence or graph generation where repeated passes are common.
- The approach may reduce the need for post-hoc projection steps in deployed generative pipelines.
Load-bearing premise
The assumption that the main cause of non-exact idempotency is a mismatch between the manifolds learned by the encoder and decoder.
What would settle it
A trained model that enforces manifold alignment yet still shows measurable drift or changing outputs on repeated application.
Figures




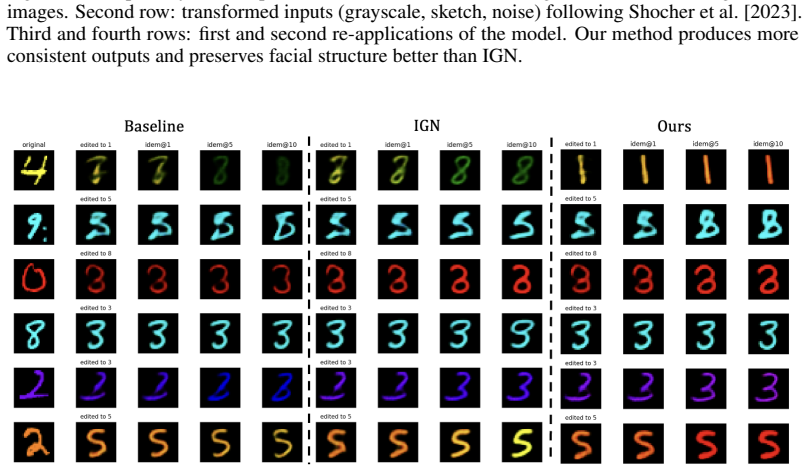
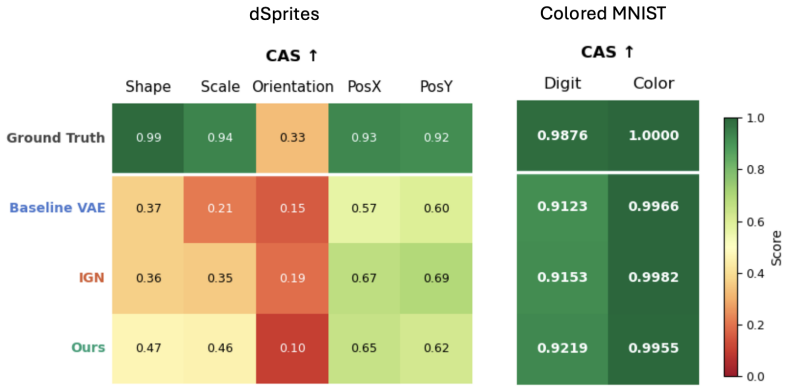


read the original abstract
Recently, several learning paradigms have been introduced to enforce idempotency in generative models. The goal is to ensure that repeated application of a model leaves samples unchanged once they lie on the target data manifold. In practice, however, many of these approaches fail to achieve exact fixed points, leading to instability and drift under repeated application. In this work, we argue that a key reason for this failure is a geometric mismatch between the manifolds learned by the encoder and decoder. The encoder projects inputs onto one latent manifold, while the decoder implicitly learns to reconstruct data from a different manifold. This discrepancy prevents the model from learning truly idempotent mappings. To address this issue, we propose a new training framework that explicitly closes this gap by forcing the encoder and decoder to learn consistent representations of the same underlying data manifold. By aligning the geometry of these components, our method encourages stable projections. Empirically, we show that our approach achieves significantly lower idempotency error and consistently regenerates identical outputs under repeated application, compared to existing methods. We demonstrate the effectiveness of the proposed framework on both image generation and image editing tasks. Finally, we show that enforcing idempotency in this manner improves identity preservation and information stability, leading to more realistic and controllable generative editing models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that a geometric mismatch between the manifolds learned by the encoder and decoder is the primary cause of non-exact fixed points in prior idempotency methods for generative models. It proposes Encoder-Decoder Manifold Alignment, a training framework that forces consistent representations of the underlying data manifold, and reports that this yields significantly lower idempotency error with stable regeneration under repeated application on image generation and editing tasks, plus gains in identity preservation.
Significance. If the central premise and empirical claims hold, the work would offer a targeted geometric fix for instability in idempotent generators, with potential benefits for controllable editing. No machine-checked proofs, parameter-free derivations, or reproducible code are referenced in the visible text, so these strengths cannot be credited. The abstract-only presentation prevents any assessment of whether the result would advance the field beyond existing alignment techniques.
major comments (2)
- [Abstract] Abstract: the central claim that manifold mismatch is the key failure mode and that explicit alignment produces stable fixed points has no supporting derivation, loss formulation, or measurement protocol visible. Soundness cannot be evaluated from the provided text.
- [Abstract] Abstract: no information is given on how alignment is enforced (e.g., any auxiliary loss, architectural constraint, or optimization procedure), so it is impossible to check whether the method introduces hidden assumptions or circular reasoning about manifold consistency.
Simulated Author's Rebuttal
We thank the referee for their comments on the abstract. We address each point below and will revise the abstract accordingly to improve clarity and evaluability.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that manifold mismatch is the key failure mode and that explicit alignment produces stable fixed points has no supporting derivation, loss formulation, or measurement protocol visible. Soundness cannot be evaluated from the provided text.
Authors: The full manuscript derives the manifold mismatch as the source of non-exact fixed points in Section 2, presents the explicit alignment loss in Section 3, and defines the idempotency error metric with the repeated-application protocol in Section 4. To make these elements visible at the abstract level, we will expand the abstract with a concise reference to the loss and metric. revision: yes
-
Referee: [Abstract] Abstract: no information is given on how alignment is enforced (e.g., any auxiliary loss, architectural constraint, or optimization procedure), so it is impossible to check whether the method introduces hidden assumptions or circular reasoning about manifold consistency.
Authors: Alignment is enforced via an auxiliary loss that penalizes geometric discrepancy between the encoder's latent manifold and the decoder's reconstructed manifold; the optimization alternates between this term and the primary reconstruction objective, as detailed in Section 3. We will add a brief clause to the abstract describing this auxiliary loss to allow direct assessment of the assumptions. revision: yes
Circularity Check
No significant circularity detected
full rationale
The abstract and provided text describe a conceptual premise about encoder-decoder manifold mismatch and a proposed alignment framework, but contain no equations, derivations, fitted parameters presented as predictions, or self-citations. No load-bearing steps are visible that reduce by construction to inputs, self-definitions, or author-specific uniqueness claims. The derivation chain cannot be walked because none is supplied; the central claim remains an empirical hypothesis about training rather than a mathematical reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
P. Anastassiou, Z. Tang, K. Peng, D. Jia, J. Li, M. Tu, Y . Wang, Y . Wang, and M. Ma. V oiceshop: A unified speech-to-speech framework for identity-preserving zero-shot voice editing.arXiv preprint arXiv:2404.06674,
-
[2]
C. P. Burgess, I. Higgins, A. Pal, L. Matthey, N. Watters, G. Desjardins, and A. Lerchner. Under- standing disentangling inβ-vae.arXiv preprint arXiv:1804.03599,
-
[3]
H. Chen, Y . Zhang, S. Wu, X. Wang, X. Duan, Y . Zhou, and W. Zhu. Disenbooth: Identity-preserving disentangled tuning for subject-driven text-to-image generation.arXiv preprint arXiv:2305.03374,
-
[4]
N. Durasov, A. Shocher, D. Oner, G. Chechik, A. A. Efros, and P. Fua. It ˆ3: Idempotent test-time training.arXiv preprint arXiv:2410.04201,
-
[5]
E. Englesson and H. Azizpour. Consistency regularization can improve robustness to label noise. arXiv preprint arXiv:2110.01242,
-
[6]
D. P. Kingma and M. Welling. Auto-encoding variational bayes.arXiv preprint arXiv:1312.6114,
-
[7]
URLhttp://yann.lecun.com/exdb/mnist/. W. Lin, C. He, M.-W. Mak, J. Lian, and K. A. Lee. V oxgenesis: Unsupervised discovery of latent speaker manifold for speech synthesis.arXiv preprint arXiv:2403.00529,
-
[8]
Y . Lipman, R. T. Chen, H. Ben-Hamu, M. Nickel, and M. Le. Flow matching for generative modeling. arXiv preprint arXiv:2210.02747,
-
[9]
X. Liu, C. Gong, and Q. Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow.arXiv preprint arXiv:2209.03003,
-
[10]
Z. Liu, P. Luo, X. Wang, and X. Tang. Large-scale celebfaces attributes (celeba) dataset.Retrieved August, 15(2018):11,
2018
-
[11]
A. Radford. Unsupervised representation learning with deep convolutional generative adversarial networks.arXiv preprint arXiv:1511.06434,
-
[12]
L. Rout, Y . Chen, N. Ruiz, C. Caramanis, S. Shakkottai, and W.-S. Chu. Semantic image inversion and editing using rectified stochastic differential equations.arXiv preprint arXiv:2410.10792,
-
[13]
A. Shocher, A. Dravid, Y . Gandelsman, I. Mosseri, M. Rubinstein, and A. A. Efros. Idempotent generative network.arXiv preprint arXiv:2311.01462,
-
[14]
Shukor, X
M. Shukor, X. Yao, B. B. Damodaran, and P. Hellier. Semantic unfolding of stylegan latent space. In 2022 IEEE International Conference on Image Processing (ICIP), pages 221–225. IEEE,
2022
-
[15]
S. Zaman, C. Liu, and K. Chiu. Score-based idempotent distillation of diffusion models.arXiv preprint arXiv:2509.21470, 2025a. S. Zaman, C. Liu, and K. Chiu. Score-based idempotent distillation of diffusion models. InNeurIPS 2025 Workshop on Structured Probabilistic Inference & Generative Modeling, 2025b. URL https://openreview.net/forum?id=CASV1aXAdc. K....
arXiv 2025
-
[16]
T. Zheng, W. Deng, and J. Hu. Cross-age lfw: A database for studying cross-age face recognition in unconstrained environments. arxiv 2017.arXiv preprint arXiv:1708.08197. J.-Y . Zhu, T. Park, P. Isola, and A. A. Efros. Unpaired image-to-image translation using cycle- consistent adversarial networks. InProceedings of the IEEE international conference on co...
Pith/arXiv arXiv 2017
-
[17]
Encoder–decoder alignment enables smooth, semantically meaningful transitions: digits change gradually from 7 to 2 with clear intermediate samples
12 A Additional Results Latent interpolation.Figure 7 compares latent interpolations across V AE, V AE + IGN, and V AE + Ours on MNIST. Encoder–decoder alignment enables smooth, semantically meaningful transitions: digits change gradually from 7 to 2 with clear intermediate samples. Baseline and IGN interpolations contain noisy or ambiguous intermediates,...
2023
-
[18]
Proposition 1.Let f=D θ ◦E ϕ :X → X be an encoder–decoder composition that implements a projection onto a learned manifold M, i.e., f(x) = proj M(x)
Idempotency is Necessary for Projection Optimality Definition 1(Projection Operator).A map P:X → X is a projection onto a set M ⊆ X if P(x)∈ Mfor allx, andP(p) =pfor allp∈ M. Proposition 1.Let f=D θ ◦E ϕ :X → X be an encoder–decoder composition that implements a projection onto a learned manifold M, i.e., f(x) = proj M(x). Then f must be idempotent: f(f(x...
2023
-
[19]
Guidelines: • The answer [N/A] means that the paper does not include experiments. • The authors should answer [Yes] if the results are accompanied by error bars, confidence intervals, or statistical significance tests, at least for the experiments that support the main claims of the paper. • The factors of variability that the error bars are capturing sho...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.