EvoArena: Tracking Memory Evolution for Robust LLM Agents in Dynamic Environments
Pith reviewed 2026-06-27 06:26 UTC · model grok-4.3
The pith
LLM agents gain from tracking memory changes as patches in dynamic settings
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a patch-based memory paradigm recording structured update histories lets agents preserve complete evolving environment states, producing measurable gains in accuracy on both single tasks and consecutive evolutionary sequences.
What carries the argument
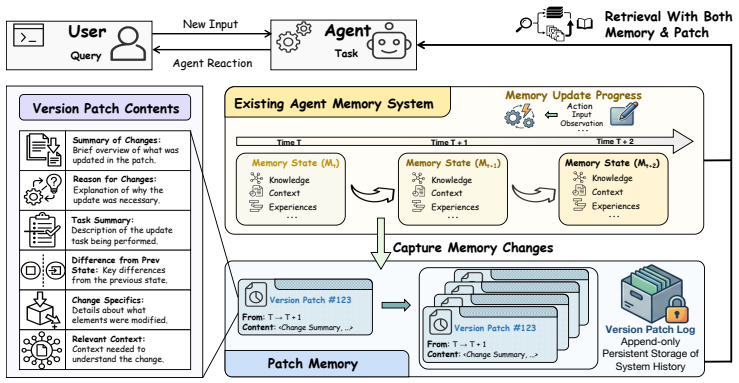
EvoMem, the patch-based memory paradigm that records memory evolution as structured update histories, enabling reasoning about environmental changes through memory patches.
Load-bearing premise
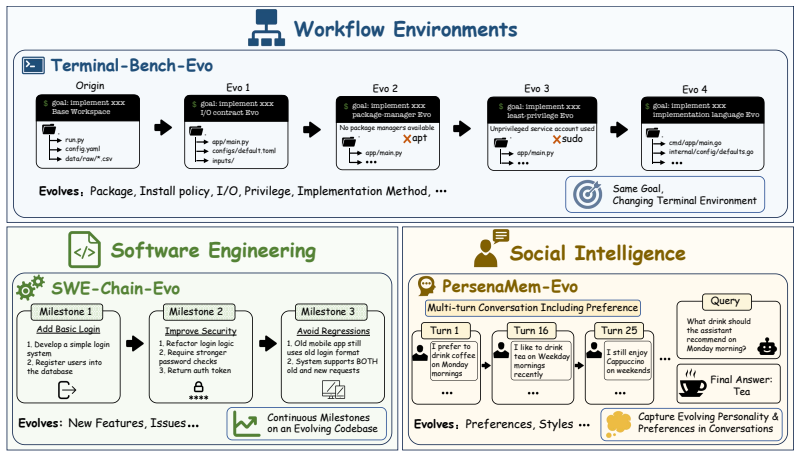
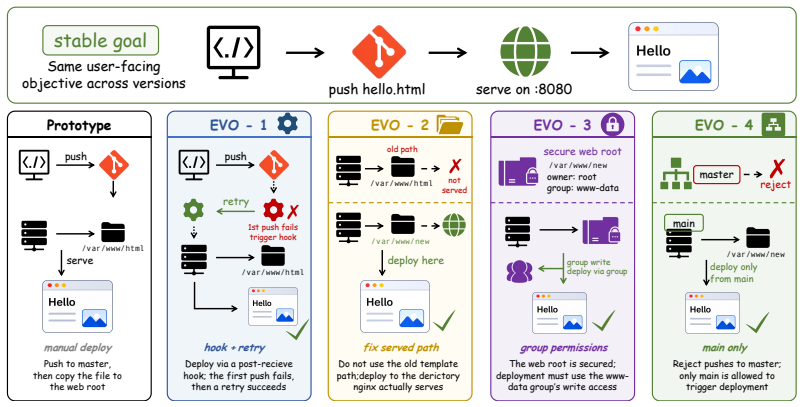
The progressive update sequences in EvoArena represent the kinds of environment changes that matter for real-world agent reliability.
What would settle it
Testing whether the reported accuracy gains disappear when agents face environment changes drawn from domains or update patterns outside the terminal, software, and social-preference sequences used in EvoArena.
Figures
read the original abstract
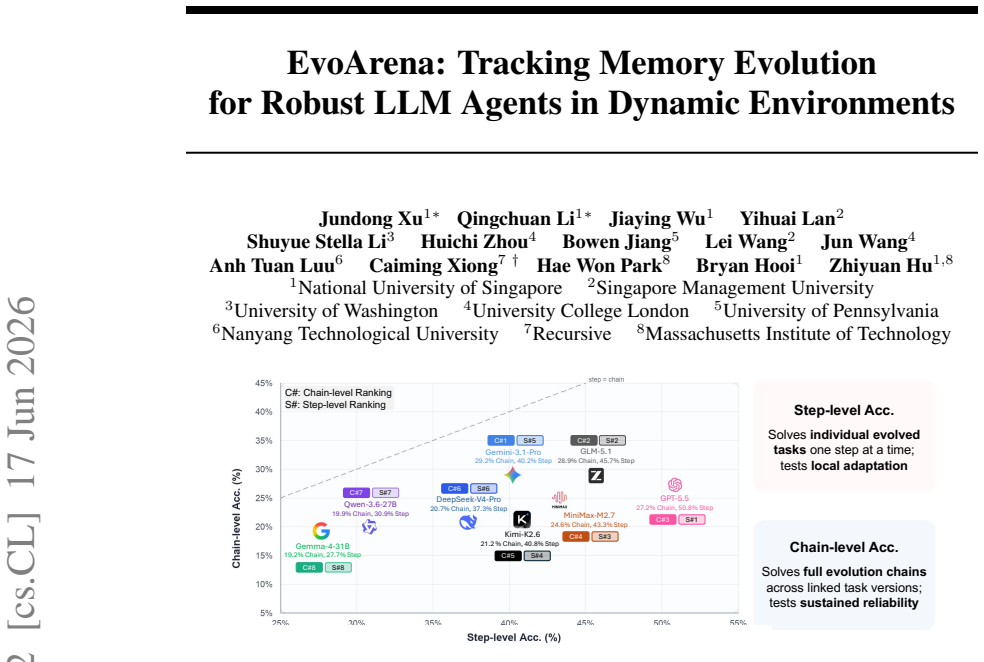
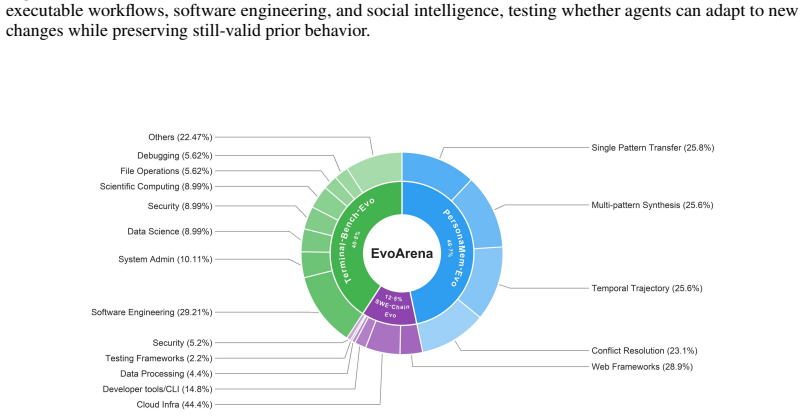
Large language model (LLM) agents have achieved strong performance on a wide range of benchmarks, yet most evaluations assume static environments. In contrast, real-world deployment is inherently dynamic, requiring agents to continually align their knowledge, skills, and behavior with changing environments and updated task conditions. To address this gap, we introduce EvoArena, a benchmark suite that models environment changes as sequences of progressive updates across terminal, software, and social domains. We further propose EvoMem, a patch-based memory paradigm that records memory evolution as structured update histories, enabling agents to reason about environmental evolution through changes in their memory. Experiments show that current agents struggle on EvoArena, achieving an average accuracy of 39.6% across evolving terminal, software, and social-preference domains. EvoMem consistently improves performance, yielding an average gain of 1.5% on EvoArena and also improving standard benchmarks such as GAIA and LoCoMo by 6.1% and 4.8%. Beyond individual tasks, EvoMem further improves chain-level accuracy by 3.7% on EvoArena, where success requires completing a consecutive sequence of related evolutionary subtasks. Mechanistic analysis shows that EvoMem improves evidence capture in the memory, indicating better preservation of complete evolving environment states. Our results highlight the importance of modeling evolution in both evaluation and memory for reliable agent deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces EvoArena, a benchmark modeling dynamic environments via sequences of progressive updates in terminal, software, and social-preference domains. It proposes EvoMem, a patch-based memory paradigm that records structured update histories to allow agents to reason about environmental evolution. Current agents achieve 39.6% average accuracy on EvoArena; EvoMem yields 1.5% average gain on EvoArena, 6.1% on GAIA, 4.8% on LoCoMo, and 3.7% on chain-level accuracy, with mechanistic analysis indicating improved evidence capture.
Significance. If the reported gains and mechanistic findings hold under detailed scrutiny, the work usefully extends agent evaluation beyond static benchmarks and demonstrates a concrete memory mechanism for handling change. The transfer improvements to GAIA and LoCoMo are a strength worth confirming.
major comments (2)
- [Abstract] Abstract: the central performance claims (1.5% EvoArena gain, 3.7% chain-level gain, transfers to GAIA/LoCoMo) are stated without any description of baselines, number of runs, error bars, statistical tests, or ablation controls, rendering the numeric results unverifiable from the provided text.
- [Abstract] Abstract: no construction details, validation against external logs, or ablation on update predictability/noise/branching are supplied for the progressive update sequences; without these, it is impossible to assess whether the benchmark instantiates the real-world dynamics needed to support the claim that EvoMem improves robustness rather than benchmark-specific artifacts.
minor comments (1)
- [Abstract] The abstract would benefit from a one-sentence statement of how EvoMem differs from standard retrieval or summarization memory baselines used in LLM agents.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We agree that additional details are needed to make performance claims and benchmark construction more verifiable at a glance. We will revise the abstract accordingly while preserving its conciseness, and ensure cross-references to the full experimental details in the main text. Responses to each major comment are provided below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central performance claims (1.5% EvoArena gain, 3.7% chain-level gain, transfers to GAIA/LoCoMo) are stated without any description of baselines, number of runs, error bars, statistical tests, or ablation controls, rendering the numeric results unverifiable from the provided text.
Authors: We agree that the abstract would benefit from explicit context on the experimental protocol. In the revised version we will add a concise clause specifying the baselines (standard LLM agents without EvoMem), the number of runs (five independent runs per task), and that results are reported as averages with standard deviations. Full statistical tests, ablation controls, and per-domain breakdowns already appear in Section 4 and the appendix; we will add a parenthetical reference to these sections in the abstract. This change directly addresses verifiability without exceeding typical abstract length constraints. revision: yes
-
Referee: [Abstract] Abstract: no construction details, validation against external logs, or ablation on update predictability/noise/branching are supplied for the progressive update sequences; without these, it is impossible to assess whether the benchmark instantiates the real-world dynamics needed to support the claim that EvoMem improves robustness rather than benchmark-specific artifacts.
Authors: We acknowledge that the abstract currently omits high-level construction information. The revised abstract will include a brief sentence describing how the progressive update sequences are generated across the three domains (terminal, software, social-preference) to simulate incremental environmental change. Detailed construction methodology, including controlled variability in update timing and content, appears in Section 3; we will add an explicit pointer to this section. Validation against external logs is not applicable because EvoArena is a synthetic benchmark designed to isolate evolutionary dynamics rather than replicate specific real-world traces; however, we will expand the abstract to note that the sequences incorporate controlled noise and branching factors, with corresponding ablations reported in Section 4.3 and the appendix. If the referee considers additional external validation necessary, we are prepared to discuss its feasibility. revision: yes
Circularity Check
No circularity; purely empirical benchmark and method evaluation
full rationale
The paper introduces EvoArena as a new benchmark suite and EvoMem as a patch-based memory paradigm, then reports experimental accuracy numbers (39.6% baseline, +1.5% with EvoMem on EvoArena, plus transfers to GAIA/LoCoMo). No equations, derivations, fitted parameters, or self-citation chains appear in the provided text. All load-bearing claims rest on direct performance measurements against the introduced tasks and external benchmarks, with no reduction of outputs to inputs by construction. This is the standard non-circular case for an empirical systems paper.
Axiom & Free-Parameter Ledger
invented entities (1)
-
EvoMem
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Workarena++: Towards compositional planning and reasoning-based common knowledge work tasks
Léo Boisvert, Megh Thakkar, Maxime Gasse, Massimo Caccia, Thibault Le Sellier de Chezelles, Quentin Cappart, Nicolas Chapados, Alexandre Lacoste, and Alexandre Drouin. Workarena++: Towards compositional planning and reasoning-based common knowledge work tasks. InThe Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks T...
2024
-
[2]
Mem0: Building production-ready AI agents with scalable long-term memory
Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Yadav. Mem0: Building production-ready AI agents with scalable long-term memory. InECAI 2025 - 28th European Conference on Artificial Intelligence, 25-30 October 2025, Bologna, Italy - Including 14th Conference on Prestigious Applications of Intelligent Systems (PAIS 2025), pages 2993–...
2025
-
[3]
Gaia2: Benchmarking LLM agents on dynamic and asynchronous environments
Romain Froger, Pierre Andrews, Matteo Bettini, Amar Budhiraja, Ricardo Silveira Cabral, Virginie Do, Emilien Garreau, Jean-Baptiste Gaya, Hugo Laurençon, Maxime Lecanu, Kunal Malkan, Dheeraj Mekala, Pierre Menard, Gerard Moreno-Torres Bertran, Ulyana Piterbarg, Mikhail Plekhanov, Mathieu Rita, Andrey Rusakov, Vladislav V orotilov, Mengjue Wang, Ian Yu, Am...
2026
-
[4]
Scaling synthetic data creation with 1,000,000,000 personas.arXiv preprint arXiv:2406.20094, 2024
Tao Ge, Xin Chan, Xiaoyang Wang, Dian Yu, Haitao Mi, and Dong Yu. Scaling synthetic data creation with 1,000,000,000 personas.arXiv preprint arXiv:2406.20094, 2024
Pith/arXiv arXiv 2024
-
[5]
Gemini 3.1 pro: A smarter model for your most complex tasks
Google. Gemini 3.1 pro: A smarter model for your most complex tasks. https: //blog.google/innovation-and-ai/models-and-research/gemini-models/ gemini-3-1-pro/, 2026
2026
-
[6]
Bowen Jiang, Yuan Yuan, Maohao Shen, Zhuoqun Hao, Zhangchen Xu, Zichen Chen, Ziyi Liu, Anvesh Rao Vijjini, Jiashu He, Hanchao Yu, et al. Personamem-v2: Towards person- alized intelligence via learning implicit user personas and agentic memory.arXiv preprint arXiv:2512.06688, 2025
arXiv 2025
-
[7]
SWE-bench: Can language models resolve real-world github issues? In The Twelfth International Conference on Learning Representations, 2024
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R Narasimhan. SWE-bench: Can language models resolve real-world github issues? In The Twelfth International Conference on Learning Representations, 2024
2024
-
[8]
Langgraph documentation
LangChain. Langgraph documentation. https://docs.langchain.com/oss/python/ langgraph, 2024. Accessed: 2026-05-05
2024
-
[9]
Kenan Li, Rongzhi Li, Linghao Zhang, Qirui Jin, Liao Zhu, Xiaosong Huang, Geng Zhang, Yikai Zhang, Shilin He, Chengxing Xie, et al. Repolaunch: Automating build&test pipeline of code repositories on any language and any platform.arXiv preprint arXiv:2603.05026, 2026
Pith/arXiv arXiv 2026
-
[10]
Shuyue Stella Li, Bhargavi Paranjape, Kerem Oktar, Zhongyao Ma, Gelin Zhou, Lin Guan, Na Zhang, Sem Park, Lin Chen, Diyi Yang, et al. Horizonbench: Long-horizon personalization with evolving preferences.arXiv preprint arXiv:2604.17283, 2026
Pith/arXiv arXiv 2026
-
[11]
Agentbench: Evaluating LLMs as agents
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, Shudan Zhang, Xiang Deng, Aohan Zeng, Zhengxiao Du, Chenhui Zhang, Sheng Shen, Tianjun Zhang, Yu Su, Huan Sun, Minlie Huang, Yuxiao Dong, and Jie Tang. Agentbench: Evaluating LLMs as agents. InThe Twelfth International Conference on Learning R...
2024
-
[12]
Evaluating very long-term conversational memory of LLM agents
Adyasha Maharana, Dong-Ho Lee, Sergey Tulyakov, Mohit Bansal, Francesco Barbieri, and Yuwei Fang. Evaluating very long-term conversational memory of LLM agents. InProceedings of the Annual Meeting of the Association for Computational Linguistics, pages 13851–13870, 2024
2024
-
[13]
Terminal-bench: Benchmarking agents on hard, realistic tasks in command line interfaces
Mike A Merrill, Alexander G Shaw, Nicholas Carlini, Boxuan Li, Harsh Raj, Ivan Bercovich, Lin Shi, Jeong Yeon Shin, Thomas Walshe, E Kelly Buchanan, et al. Terminal-bench: Benchmarking agents on hard, realistic tasks in command line interfaces. InThe Fourteenth International Conference on Learning Representations, 2026. 18
2026
-
[14]
GAIA: a benchmark for general AI assistants
Grégoire Mialon, Clémentine Fourrier, Thomas Wolf, Yann LeCun, and Thomas Scialom. GAIA: a benchmark for general AI assistants. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[15]
Kimi k2.6.https://www.kimi.com/ai-models/kimi-k2-6, 2026
Moonshot AI. Kimi k2.6.https://www.kimi.com/ai-models/kimi-k2-6, 2026
2026
-
[16]
Introducing gpt-5.4 mini and nano
OpenAI. Introducing gpt-5.4 mini and nano. https://openai.com/index/ introducing-gpt-5-4-mini-and-nano/, 2026
2026
-
[17]
Introducing gpt-5.5
OpenAI. Introducing gpt-5.5. https://openai.com/index/introducing-gpt-5-5/ , 2026
2026
-
[18]
Qwen3.6-27b: Flagship-level coding in a 27b dense model
Qwen Team. Qwen3.6-27b: Flagship-level coding in a 27b dense model. https://qwen.ai/ blog?id=qwen3.6-27b, 2026
2026
-
[19]
Androidworld: A dynamic benchmarking environment for autonomous agents
Christopher Rawles, Sarah Clinckemaillie, Yifan Chang, Jonathan Waltz, Gabrielle Lau, Mary- beth Fair, Alice Li, William E Bishop, Wei Li, Folawiyo Campbell-Ajala, Daniel Kenji Toyama, Robert James Berry, Divya Tyamagundlu, Timothy P Lillicrap, and Oriana Riva. Androidworld: A dynamic benchmarking environment for autonomous agents. InThe Thirteenth Intern...
2025
-
[20]
Reflexion: language agents with verbal reinforcement learning
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik R Narasimhan, and Shunyu Yao. Reflexion: language agents with verbal reinforcement learning. InThirty-seventh Conference on Neural Information Processing Systems, 2023
2023
-
[21]
V oyager: An open-ended embodied agent with large language models
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. V oyager: An open-ended embodied agent with large language models. Transactions on Machine Learning Research, 2024
2024
-
[22]
Benchmark self-evolving: A multi-agent framework for dynamic LLM evaluation
Siyuan Wang, Zhuohan Long, Zhihao Fan, Xuanjing Huang, and Zhongyu Wei. Benchmark self-evolving: A multi-agent framework for dynamic LLM evaluation. InProceedings of the International Conference on Computational Linguistics, pages 3310–3328, 2025
2025
-
[23]
Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, Hoang H
Xingyao Wang, Boxuan Li, Yufan Song, Frank F. Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, Hoang H. Tran, Fuqiang Li, Ren Ma, Mingzhang Zheng, Bill Qian, Yanjun Shao, Niklas Muennighoff, Yizhe Zhang, Binyuan Hui, Junyang Lin, Robert Brennan, Hao Peng, Heng Ji, and Graham Neubig. Openhands: An open platform for AI soft...
2025
-
[24]
A-mem: Agentic memory for LLM agents
Wujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Juntao Tan, and Yongfeng Zhang. A-mem: Agentic memory for LLM agents. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[25]
React: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InThe Eleventh International Conference on Learning Representations, 2023
2023
-
[26]
Memento-skills: Let agents design agents
Huichi Zhou, Siyuan Guo, Anjie Liu, Zhongwei Yu, Ziqin Gong, Bowen Zhao, Zhixun Chen, Menglong Zhang, Yihang Chen, Jinsong Li, et al. Memento-skills: Let agents design agents. arXiv preprint arXiv:2603.18743, 2026
arXiv 2026
-
[27]
Shuyan Zhou, Frank F Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Yonatan Bisk, Daniel Fried, Uri Alon, et al. Webarena: A realistic web environment for building autonomous agents.arXiv preprint arXiv:2307.13854, 2023. 19 List of Appendices A Limitations and Future Directions 22 B Broader Impact 22 C Declaration of LLM Usage 23 D Add...
Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.