CalTennis: Large Multi-View Tennis Video Dataset and Benchmark of Monocular-to-3D Pose Estimation
Pith reviewed 2026-06-26 17:37 UTC · model grok-4.3
The pith
A large multi-view tennis video dataset enables label-free benchmarking of monocular 3D pose estimation on athletic motion.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
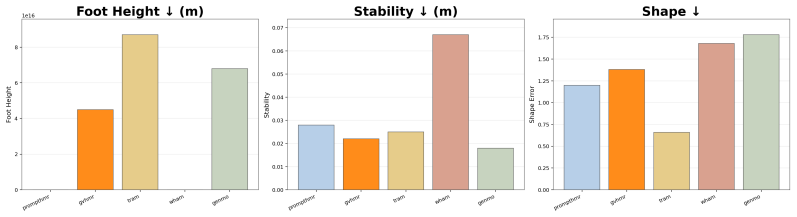
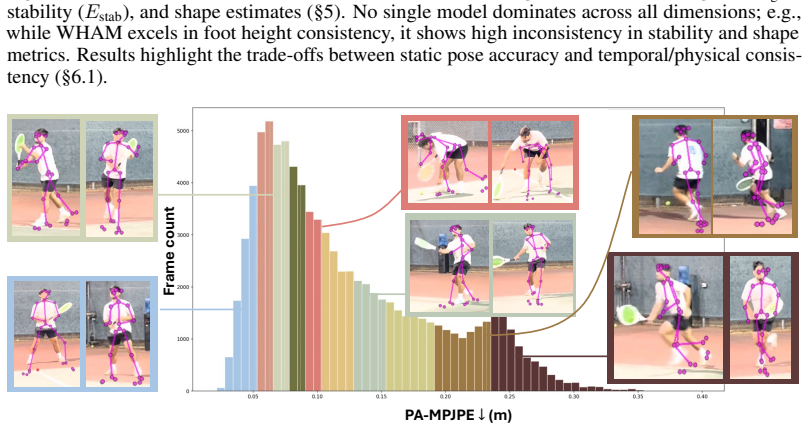
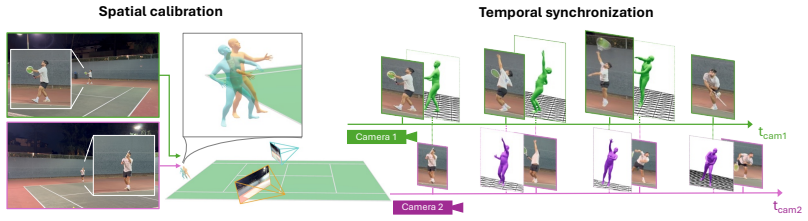
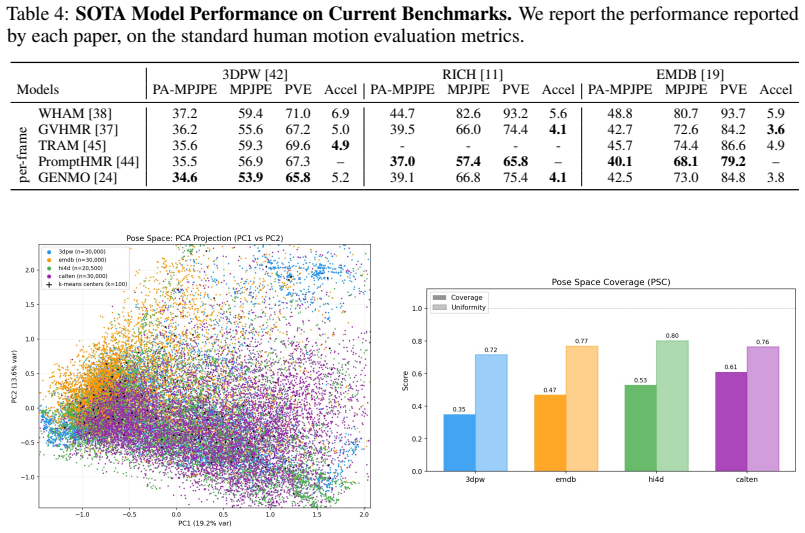
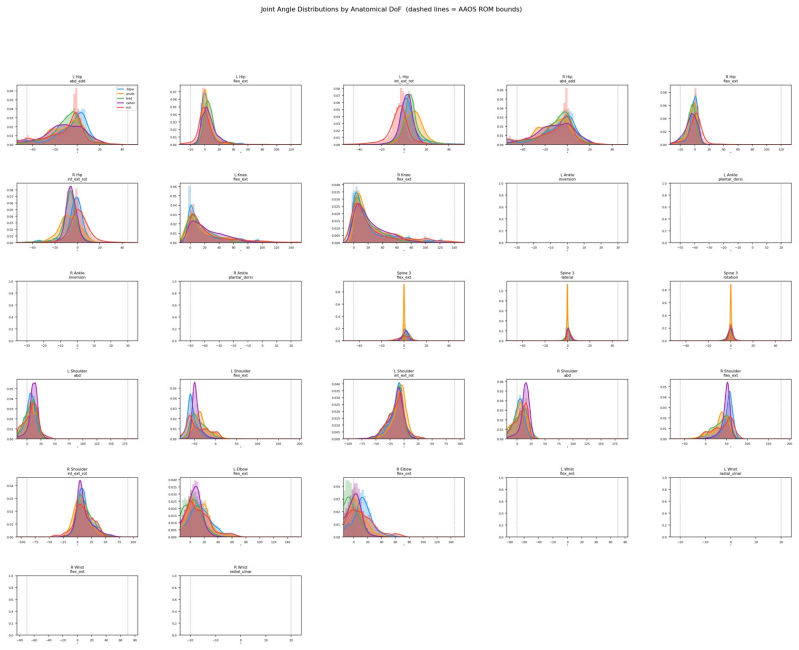
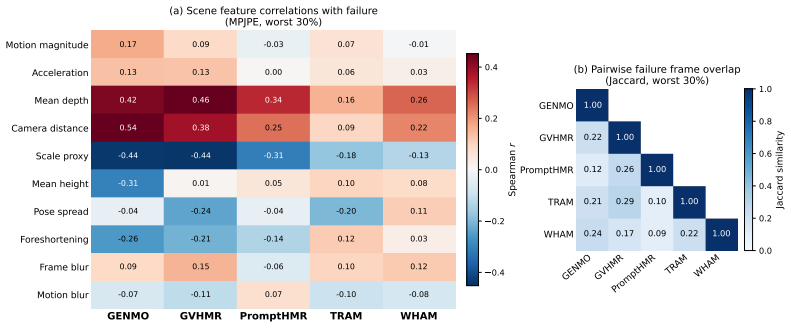
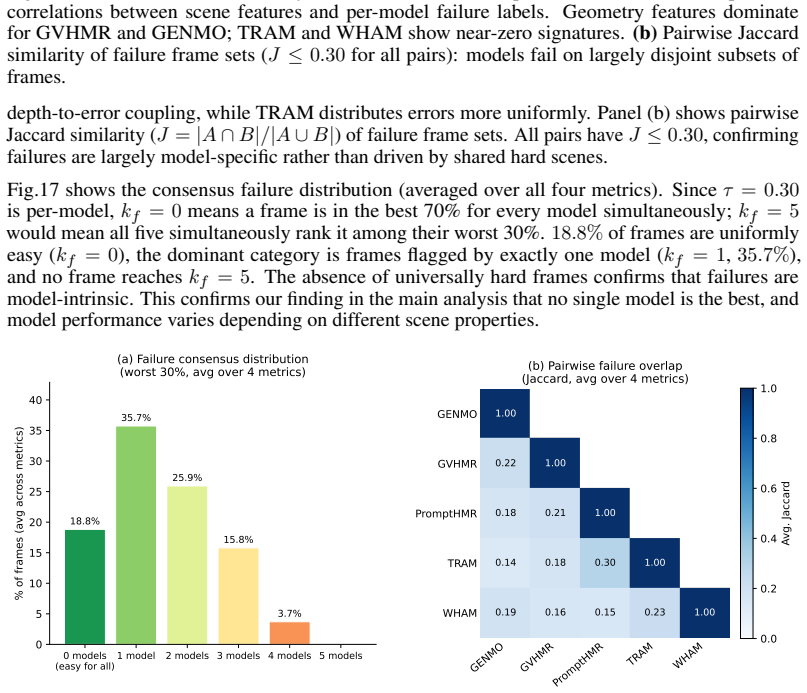
CalTennis supplies synchronized multi-view video of expert tennis motion at scale, with fully automated calibration and synchronization that produces 3D ground truth for label-free evaluation of monocular pose estimators; on this benchmark, current methods recover joint angles accurately yet struggle to estimate depth and foot contact consistently, as revealed by the proposed footwork and stability metrics.
What carries the argument
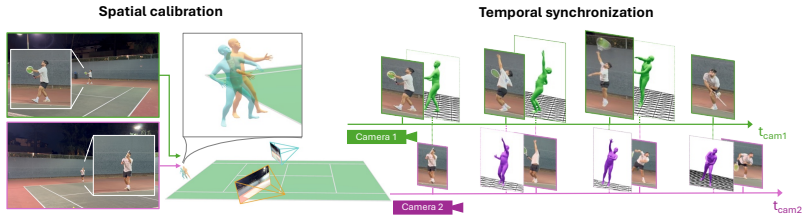
The multi-view synchronized camera protocol with automated video calibration and synchronization that generates reliable 3D ground truth from ordinary recordings.
If this is right
- Monocular 3D pose algorithms can now be tested at scale on in-the-wild athletic sequences without specialized capture hardware.
- Joint-angle recovery has reached usable accuracy on dynamic sports motion.
- Depth and foot-contact estimation remain open failure modes that limit applications in sports analysis.
- Footwork and stability metrics provide concrete, quantitative ways to measure and improve those failure modes.
- Body-shape inconsistency across frames can be detected and studied directly from the multi-view data.
Where Pith is reading between the lines
- The same capture protocol could be replicated for other sports to create comparable benchmarks without new equipment.
- Training monocular models with explicit depth or contact losses derived from the new metrics might close the observed gaps.
- Reliable foot-contact detection would directly improve downstream tasks such as injury-risk assessment or performance coaching from video.
Load-bearing premise
Automated calibration and synchronization of the multi-view videos produce 3D ground truth accurate enough to serve as a reliable benchmark without further error checks.
What would settle it
A side-by-side comparison of the automated 3D joint positions against a small set of manually verified or mocap-recorded frames that shows large systematic discrepancies in depth or foot locations.
Figures


read the original abstract
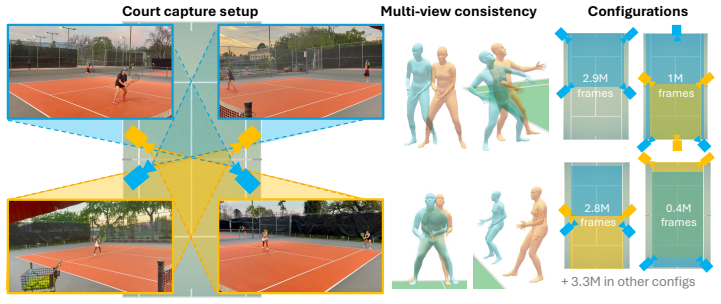
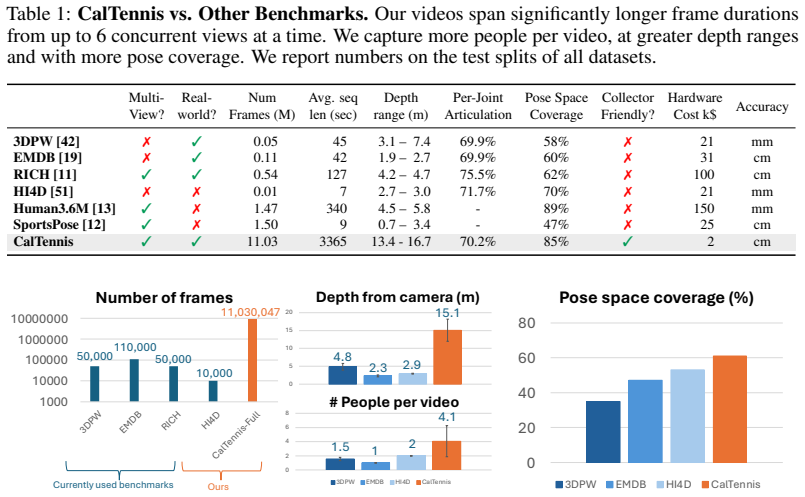
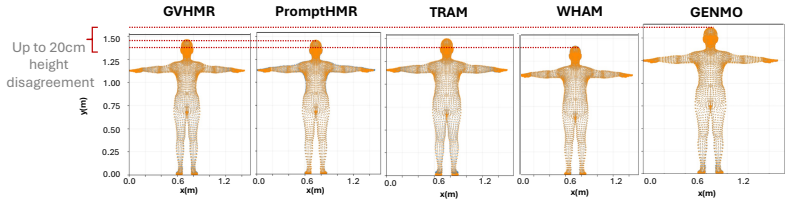
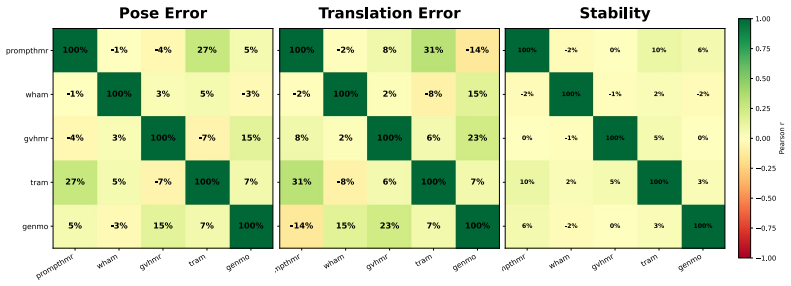
The Caltech Tennis Dataset (CalTennis) is a large-scale video benchmark for evaluating monocular-to-3D pose estimation in the wild. CalTennis comprises over 11 million frames (51 hours) of tennis practice and match play from 40 players, captured with 2-6 synchronized cameras at 60 Hz. It is 10 times larger than existing in-the-wild human motion video datasets and 3 times larger than existing MOCAP-ground-truthed datasets, and it is the first large-scale benchmark to provide synchronized multi-view recordings of expert athletic motion. The multi-view setup enables inexpensive, label-free evaluation of monocular-to-3D pose estimation algorithms. We describe a simple, standardized protocol that enables data collection without specialized equipment or expertise, along with fully automated video calibration and synchronization. Benchmarking state-of-the-art monocular-to-3D pose methods on CalTennis, we find that while 3D joint angle recovery is now quite accurate, all models struggle to estimate depth and foot contact consistently. We further propose two novel performance metrics, footwork and stability, as well as qualitatively study body shape inconsistency. These metrics expose previously underexplored failure modes and point to concrete opportunities for improvement in pose estimation and action analysis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CalTennis, a large-scale multi-view tennis video dataset with over 11 million frames (51 hours) from 40 players captured at 60 Hz using 2-6 synchronized cameras. It describes a simple data collection protocol and a fully automated pipeline for video calibration and synchronization to produce 3D ground truth without manual labels. Benchmarking of state-of-the-art monocular-to-3D pose estimation methods on this dataset shows accurate recovery of 3D joint angles but consistent struggles with depth and foot contact; the authors also propose new metrics (footwork and stability) and qualitatively examine body shape inconsistency.
Significance. If the automated calibration produces sufficiently accurate 3D ground truth, the dataset would represent a substantial advance as the largest in-the-wild multi-view benchmark focused on expert athletic motion, enabling scalable, label-free evaluation of monocular methods and exposing underexplored failure modes in depth and contact estimation.
major comments (1)
- [Abstract and multi-view setup / benchmarking protocol] Abstract and multi-view setup / benchmarking protocol: The central claim that the multi-view recordings yield reliable 3D ground truth for benchmarking (and for attributing specific failures to depth and foot contact) depends on the accuracy of the automated calibration and synchronization, yet no quantitative validation is provided such as mean reprojection error, synchronization residual statistics, or cross-validation against manual landmarks or known scene geometry. Without these, it is impossible to separate monocular model errors from potential ground-truth noise.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review and for highlighting the importance of validating the automated calibration and synchronization pipeline. We address this point directly below.
read point-by-point responses
-
Referee: [Abstract and multi-view setup / benchmarking protocol] Abstract and multi-view setup / benchmarking protocol: The central claim that the multi-view recordings yield reliable 3D ground truth for benchmarking (and for attributing specific failures to depth and foot contact) depends on the accuracy of the automated calibration and synchronization, yet no quantitative validation is provided such as mean reprojection error, synchronization residual statistics, or cross-validation against manual landmarks or known scene geometry. Without these, it is impossible to separate monocular model errors from potential ground-truth noise.
Authors: We agree that quantitative validation of the calibration and synchronization is necessary to substantiate the reliability of the 3D ground truth. The current manuscript describes the automated pipeline but does not report explicit accuracy metrics such as mean reprojection error, synchronization residuals, or cross-validation results. In the revised version we will add a new subsection (likely in Section 3 or 4) that reports these quantities computed on the collected sequences, including average reprojection errors across cameras, temporal synchronization residuals, and any available checks against known scene geometry or a small set of manually annotated landmarks. This addition will allow readers to evaluate ground-truth quality independently of the monocular method errors. revision: yes
Circularity Check
No circularity: empirical dataset collection and benchmarking with no derivations or self-referential predictions
full rationale
The paper describes collection of a multi-view tennis video dataset using automated calibration and synchronization, followed by direct benchmarking of existing monocular-to-3D pose methods. No mathematical derivations, fitted parameters presented as predictions, or first-principles results are claimed. The central contribution is the dataset itself and empirical observations on model performance (e.g., accurate joint angles but struggles with depth and foot contact); these do not reduce to inputs by construction. No self-citation load-bearing steps, uniqueness theorems, or ansatzes are invoked. The work is self-contained as an empirical benchmark paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Multi-view synchronized recordings provide accurate label-free 3D ground truth for human pose
Forward citations
Cited by 1 Pith paper
-
TaskNPoint: How to Teach Your Humanoid to Hit a Backhand in Minutes
TaskNPoint lets humanoid robots learn dynamic skills such as tennis backhands from single short human video demonstrations plus under one hour of single-GPU simulation training, achieving zero-shot generalization to n...
Reference graph
Works this paper leans on
-
[1]
Multi-hmr: Multi-person whole-body human mesh recovery in a single shot, 2024
Fabien Baradel, Matthieu Armando, Salma Galaaoui, Romain Brégier, Philippe Weinzaepfel, Grégory Rogez, and Thomas Lucas. Multi-hmr: Multi-person whole-body human mesh recovery in a single shot, 2024
2024
-
[2]
Federica Bogo, Angjoo Kanazawa, Christoph Lassner, Peter Gehler, Javier Romero, and Michael J. Black. Keep it SMPL: Automatic estimation of 3D human pose and shape from a single image. InEuropean Conference on Computer Vision (ECCV), pages 561–578, 2016
2016
-
[3]
Methodological factors affecting joint moments estimation in clinical gait analysis: a systematic review.BioMedical Engineering OnLine, 16(1):106, aug 2017
Valentina Camomilla, Andrea Cereatti, Andrea Giovanni Cutti, Silvia Fantozzi, Rita Stagni, and Giuseppe Vannozzi. Methodological factors affecting joint moments estimation in clinical gait analysis: a systematic review.BioMedical Engineering OnLine, 16(1):106, aug 2017
2017
-
[4]
Beyond static features for temporally consistent 3d human pose and shape from a video, 2021
Hongsuk Choi, Gyeongsik Moon, Ju Yong Chang, and Kyoung Mu Lee. Beyond static features for temporally consistent 3d human pose and shape from a video, 2021
2021
-
[5]
Steffi L Colyer, Murray Evans, Darren P Cosker, and Aki I T Salo. A review of the evolution of vision-based motion analysis and the integration of advanced computer vision methods towards developing a markerless system.Sports Medicine - Open, 2018
2018
-
[6]
Meva: A large-scale multiview, multimodal video dataset for activity detection, 2020
Kellie Corona, Katie Osterdahl, Roderic Collins, and Anthony Hoogs. Meva: A large-scale multiview, multimodal video dataset for activity detection, 2020
2020
-
[7]
SportsMOT: A large multi-object tracking dataset in multiple sports scenes
Yutao Cui, Chenkai Zeng, Xiaoyu Zhao, Yichun Yang, Gangshan Wu, and Limin Wang. SportsMOT: A large multi-object tracking dataset in multiple sports scenes. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 9921–9931, 2023
2023
-
[8]
SoccerNet: A scalable dataset for action spotting in soccer videos
Silvio Giancola, Mohieddine Amine, Tarek Dghaily, and Bernard Ghanem. SoccerNet: A scalable dataset for action spotting in soccer videos. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), 2018
2018
-
[9]
Humans in 4d: Reconstructing and tracking humans with transformers, 2023
Shubham Goel, Georgios Pavlakos, Jathushan Rajasegaran, Angjoo Kanazawa, and Jitendra Malik. Humans in 4d: Reconstructing and tracking humans with transformers, 2023
2023
-
[10]
OmniH2O: Universal and dexterous human-to-humanoid whole-body teleoperation and learning
Tairan He, Zhengyi Luo, Xialin He, Wenli Xiao, Chong Zhang, Weinan Zhang, Kris Kitani, Changliu Liu, and Guanya Shi. OmniH2O: Universal and dexterous human-to-humanoid whole-body teleoperation and learning. InConference on Robot Learning (CoRL), 2024
2024
-
[11]
Huang, Hongwei Yi, Markus Höschle, Matvey Safroshkin, Tsvetelina Alexiadis, Senya Polikovsky, Daniel Scharstein, and Michael J
Chun-Hao P. Huang, Hongwei Yi, Markus Höschle, Matvey Safroshkin, Tsvetelina Alexiadis, Senya Polikovsky, Daniel Scharstein, and Michael J. Black. Capturing and inferring dense full-body human-scene contact. InProceedings IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), pages 13274–13285, June 2022
2022
-
[12]
SportsPose — a dynamic 3D sports pose dataset
Christian Keilstrup Ingwersen, Christian Møller Mikkelstrup, Janus Nørtoft Jensen, Morten Rieger Han- nemose, and Anders Bjorholm Dahl. SportsPose — a dynamic 3D sports pose dataset. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), pages 5219–5228, 2023
2023
-
[13]
Catalin Ionescu, Dragos Papava, Vlad Olaru, and Cristian Sminchisescu. Human3.6m: Large scale datasets and predictive methods for 3d human sensing in natural environments.IEEE Transactions on Pattern Analysis and Machine Intelligence, 36(7):1325–1339, jul 2014
2014
-
[14]
Oswald, Marc Pollefeys, Otmar Hilliges, Manuel Kaufmann, and Jie Song
Tianjian Jiang, Johsan Billingham, Sebastian Müksch, Juan Zarate, Nicolas Evans, Martin R. Oswald, Marc Pollefeys, Otmar Hilliges, Manuel Kaufmann, and Jie Song. WorldPose: A world cup dataset for global 3D human pose estimation. InProceedings of the European Conference on Computer Vision (ECCV), 2024
2024
-
[15]
Coherent reconstruction of multiple humans from a single image, 2020
Wen Jiang, Nikos Kolotouros, Georgios Pavlakos, Xiaowei Zhou, and Kostas Daniilidis. Coherent reconstruction of multiple humans from a single image, 2020
2020
-
[16]
Panoptic studio: A massively multiview system for social motion capture
Hanbyul Joo, Hao Liu, Lei Tan, Lin Gui, Bart Nabbe, Iain Matthews, Takeo Kanade, Shohei Nobuhara, and Yaser Sheikh. Panoptic studio: A massively multiview system for social motion capture. InProceedings of the IEEE International Conference on Computer Vision (ICCV), pages 3334–3342, 2015
2015
-
[17]
Black, David W
Angjoo Kanazawa, Michael J. Black, David W. Jacobs, and Jitendra Malik. End-to-end recovery of human shape and pose, 2018
2018
-
[18]
Zhang, Panna Felsen, and Jitendra Malik
Angjoo Kanazawa, Jason Y . Zhang, Panna Felsen, and Jitendra Malik. Learning 3d human dynamics from video, 2019. 11
2019
-
[19]
EMDB: The Electromagnetic Database of Global 3D Human Pose and Shape in the Wild
Manuel Kaufmann, Jie Song, Chen Guo, Kaiyue Shen, Tianjian Jiang, Chengcheng Tang, Juan José Zárate, and Otmar Hilliges. EMDB: The Electromagnetic Database of Global 3D Human Pose and Shape in the Wild. InInternational Conference on Computer Vision (ICCV), 2023
2023
-
[20]
Muhammed Kocabas, Nikos Athanasiou, and Michael J. Black. VIBE: Video inference for human body pose and shape estimation. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 5253–5263, 2020
2020
-
[21]
Huang, Otmar Hilliges, and Michael J
Muhammed Kocabas, Chun-Hao P. Huang, Otmar Hilliges, and Michael J. Black. Pare: Part attention regressor for 3d human body estimation, 2021
2021
-
[22]
Black, Otmar Hilliges, Jan Kautz, and Umar Iqbal
Muhammed Kocabas, Ye Yuan, Pavlo Molchanov, Yunrong Guo, Michael J. Black, Otmar Hilliges, Jan Kautz, and Umar Iqbal. Pace: Human and camera motion estimation from in-the-wild videos, 2023
2023
-
[23]
Black, and Kostas Daniilidis
Nikos Kolotouros, Georgios Pavlakos, Michael J. Black, and Kostas Daniilidis. Learning to reconstruct 3d human pose and shape via model-fitting in the loop, 2019
2019
-
[24]
Genmo: A generalist model for human motion, 2025
Jiefeng Li, Jinkun Cao, Haotian Zhang, Davis Rempe, Jan Kautz, Umar Iqbal, and Ye Yuan. Genmo: A generalist model for human motion, 2025
2025
-
[25]
Coin: Control-inpainting diffusion prior for human and camera motion estimation, 2024
Jiefeng Li, Ye Yuan, Davis Rempe, Haotian Zhang, Pavlo Molchanov, Cewu Lu, Jan Kautz, and Umar Iqbal. Coin: Control-inpainting diffusion prior for human and camera motion estimation, 2024
2024
-
[26]
Ross, and Angjoo Kanazawa
Ruilong Li, Shan Yang, David A. Ross, and Angjoo Kanazawa. AI choreographer: Music conditioned 3D dance generation with AIST++. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 13401–13412, 2021
2021
-
[27]
Deep appearance models for face rendering.ACM Transactions on Graphics, 37(4):68:1–68:13, 2018
Stephen Lombardi, Jason Saragih, Tomas Simon, and Yaser Sheikh. Deep appearance models for face rendering.ACM Transactions on Graphics, 37(4):68:1–68:13, 2018
2018
-
[28]
Matthew Loper, Naureen Mahmood, Javier Romero, Gerard Pons-Moll, and Michael J. Black. Smpl: a skinned multi-person linear model.ACM Trans. Graph., 34(6), November 2015
2015
-
[29]
McGhee and A.A
R.B. McGhee and A.A. Frank. On the stability properties of quadruped creeping gaits.Mathematical Biosciences, 3:331–351, 1968
1968
-
[30]
Morgan Kaufmann, 2 edition, 2011
Alberto Menache.Understanding Motion Capture for Computer Animation. Morgan Kaufmann, 2 edition, 2011
2011
-
[31]
deface: Video anonymization by face detection, 2026
ORB-HD. deface: Video anonymization by face detection, 2026
2026
-
[32]
Georgios Pavlakos, Vasileios Choutas, Nima Ghorbani, Timo Bolkart, Ahmed A. A. Osman, Dimitrios Tzionas, and Michael J. Black. Expressive body capture: 3d hands, face, and body from a single image, 2019
2019
-
[33]
Amir Rasouli and John K. Tsotsos. Autonomous vehicles that interact with pedestrians: A survey of theory and practice.IEEE Transactions on Intelligent Transportation Systems, 21(3):900–918, 2020
2020
-
[34]
You only look once: Unified, real-time object detection, 2016
Joseph Redmon, Santosh Divvala, Ross Girshick, and Ali Farhadi. You only look once: Unified, real-time object detection, 2016
2016
-
[35]
Deep gait recognition: A survey.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(1):264–284, 2023
Alireza Sepas-Moghaddam and Ali Etemad. Deep gait recognition: A survey.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(1):264–284, 2023
2023
-
[36]
FineGym: A hierarchical video dataset for fine-grained action understanding
Dian Shao, Yue Zhao, Bo Dai, and Dahua Lin. FineGym: A hierarchical video dataset for fine-grained action understanding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 2616–2625, 2020
2020
-
[37]
World-grounded human motion recovery via gravity-view coordinates
Zehong Shen, Huaijin Pi, Yan Xia, Zhi Cen, Sida Peng, Zechen Hu, Hujun Bao, Ruizhen Hu, and Xiaowei Zhou. World-grounded human motion recovery via gravity-view coordinates. InSIGGRAPH Asia 2024 Conference Papers, SA ’24, pages 1–11. ACM, December 2024
2024
-
[38]
Soyong Shin, Juyong Kim, Eni Halilaj, and Michael J. Black. Wham: Reconstructing world-grounded humans with accurate 3d motion, 2024
2024
-
[39]
Aios: All-in-one-stage expressive human pose and shape estimation, 2024
Qingping Sun, Yanjun Wang, Ailing Zeng, Wanqi Yin, Chen Wei, Wenjia Wang, Haiyi Mei, Chi Sing Leung, Ziwei Liu, Lei Yang, and Zhongang Cai. Aios: All-in-one-stage expressive human pose and shape estimation, 2024. 12
2024
-
[40]
Moeslund, Peter Carr, and Adrian Hilton
Graham Thomas, Rikke Gade, Thomas B. Moeslund, Peter Carr, and Adrian Hilton. Computer vision for sports: Current applications and research topics.Computer Vision and Image Understanding, 159:3–18, 2017
2017
-
[41]
Uhlrich, Antoine Falisse, Łukasz Kidzi ´nski, Julie Muccini, Michael Ko, Akshay S
Scott D. Uhlrich, Antoine Falisse, Łukasz Kidzi ´nski, Julie Muccini, Michael Ko, Akshay S. Chaudhari, Jennifer L. Hicks, and Scott L. Delp. OpenCap: Human movement dynamics from smartphone videos. PLOS Computational Biology, 19(10):e1011462, 2023
2023
-
[42]
Recover- ing accurate 3d human pose in the wild using imus and a moving camera
Timo von Marcard, Roberto Henschel, Michael Black, Bodo Rosenhahn, and Gerard Pons-Moll. Recover- ing accurate 3d human pose in the wild using imus and a moving camera. InEuropean Conference on Computer Vision (ECCV), sep 2018
2018
-
[43]
Applications and limitations of current markerless motion capture methods for clinical gait biomechanics.PeerJ, 10:e12995, 2022
Logan Wade, Laurie Needham, Polly McGuigan, and James Bilzon. Applications and limitations of current markerless motion capture methods for clinical gait biomechanics.PeerJ, 10:e12995, 2022
2022
-
[44]
Black, and Muhammed Kocabas
Yufu Wang, Yu Sun, Priyanka Patel, Kostas Daniilidis, Michael J. Black, and Muhammed Kocabas. Prompthmr: Promptable human mesh recovery, 2025
2025
-
[45]
Tram: Global trajectory and motion of 3d humans from in-the-wild videos, 2024
Yufu Wang, Ziyun Wang, Lingjie Liu, and Kostas Daniilidis. Tram: Global trajectory and motion of 3d humans from in-the-wild videos, 2024
2024
-
[46]
Detectron2.https: //github.com/facebookresearch/detectron2, 2019
Yuxin Wu, Alexander Kirillov, Francisco Massa, Wan-Yen Lo, and Ross Girshick. Detectron2.https: //github.com/facebookresearch/detectron2, 2019
2019
-
[47]
Vitpose: Simple vision transformer baselines for human pose estimation, 2022
Yufei Xu, Jing Zhang, Qiming Zhang, and Dacheng Tao. Vitpose: Simple vision transformer baselines for human pose estimation, 2022
2022
-
[48]
Sam 3d body: Robust full-body human mesh recovery, 2026
Xitong Yang, Devansh Kukreja, Don Pinkus, Anushka Sagar, Taosha Fan, Jinhyung Park, Soyong Shin, Jinkun Cao, Jiawei Liu, Nicolas Ugrinovic, Matt Feiszli, Jitendra Malik, Piotr Dollar, and Kris Kitani. Sam 3d body: Robust full-body human mesh recovery, 2026
2026
-
[49]
Decoupling human and camera motion from videos in the wild, 2023
Vickie Ye, Georgios Pavlakos, Jitendra Malik, and Angjoo Kanazawa. Decoupling human and camera motion from videos in the wild, 2023
2023
-
[50]
Athletepose3d: A benchmark dataset for 3d human pose estimation and kinematic validation in athletic movements, 2025
Calvin Yeung, Tomohiro Suzuki, Ryota Tanaka, Zhuoer Yin, and Keisuke Fujii. Athletepose3d: A benchmark dataset for 3d human pose estimation and kinematic validation in athletic movements, 2025
2025
-
[51]
Hi4d: 4d instance segmentation of close human interaction
Yifei Yin, Chen Guo, Manuel Kaufmann, Juan Zarate, Jie Song, and Otmar Hilliges. Hi4d: 4d instance segmentation of close human interaction. InComputer Vision and Pattern Recognition (CVPR), 2023
2023
-
[52]
Glamr: Global occlusion-aware human mesh recovery with dynamic cameras, 2022
Ye Yuan, Umar Iqbal, Pavlo Molchanov, Kris Kitani, and Jan Kautz. Glamr: Global occlusion-aware human mesh recovery with dynamic cameras, 2022
2022
-
[53]
Derpanis
Weiyu Zhang, Menglong Zhu, and Konstantinos G. Derpanis. From actemes to action: A strongly- supervised representation for detailed action understanding. InProceedings of the IEEE International Conference on Computer Vision (ICCV), 2013
2013
-
[54]
Yufei Zhu, Andrey Rudenko, Tomasz P. Kucner, Luigi Palmieri, Kai O. Arras, Achim J. Lilienthal, and Martin Magnusson. Cliff-lhmp: Using spatial dynamics patterns for long-term human motion prediction, 2023. 13 A Technical appendices and supplementary material A.1 Maximum-likelihood consensus pose To establish a single robust 3D joint estimate per timestep...
arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.