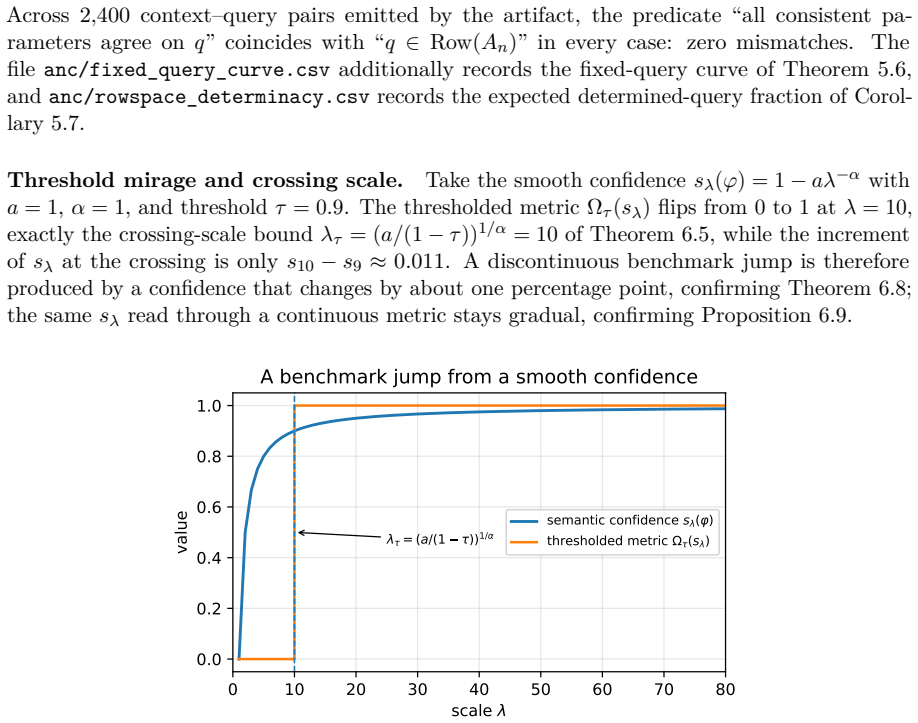
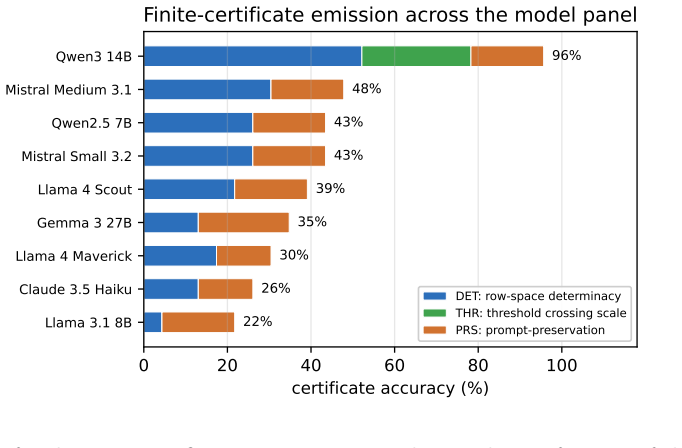
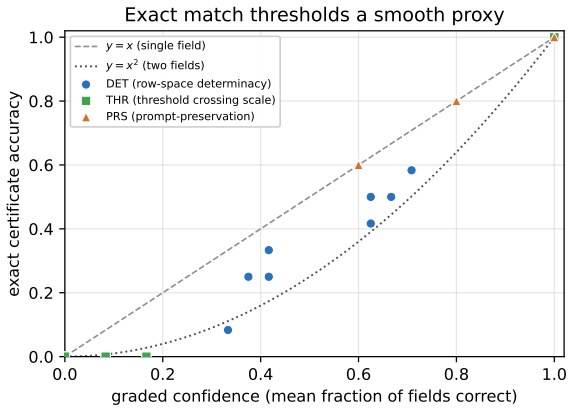
Finite Certificates for In-Context Determinacy and a Threshold Theory of Emergence in Language Models
Pith reviewed 2026-06-28 19:06 UTC · model grok-4.3
The pith
A model-theoretic confidence functional yields finite certificates for when contexts determine language model answers and separates threshold jumps from semantic transitions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In finite-field linear task families an exact row-space criterion determines when a context forces the answer to a query without parameter changes; the same framework yields an anti-mirage theorem that separates thresholded metrics from semantic confidence, with the common object being a confidence functional that is a Boolean probability measure equivalently a Keisler measure whose measure-one formulas form a proper filter and whose Stone-space representation is invariant under definitional expansion.
What carries the argument
The confidence functional on definable events, which the paper proves is a Boolean probability measure (Keisler measure) whose measure-one formulas form a proper filter.
If this is right
- A context forces the model answer exactly when the query vector lies in the row space spanned by the context examples.
- The number of remaining consistent hypotheses after any finite context can be computed directly from the linear algebra.
- Extracting a smallest forcing subcontext is NP-complete even when outputs are binary.
- A rate-sensitive crossing bound tells when latent commitments become visible above any chosen threshold.
- The same calculus supplies pair-separator hitting sets, query teaching dimension, prompt-preservation criteria, and scale-limit witnesses.
Where Pith is reading between the lines
- The same row-space test could be applied to any model whose internal representations admit a linear algebraic description over a finite field.
- Prompt designers could use the NP-completeness result to justify heuristic search rather than exhaustive enumeration when selecting examples.
- If real language models deviate from the Keisler-measure properties, the anti-mirage separation would no longer hold and apparent emergence might remain entangled with scoring artifacts.
- The framework suggests checking whether the Stone-space invariance survives when models are scaled or fine-tuned.
Load-bearing premise
Language model behavior on definable events can be faithfully captured by a model-theoretic structure whose confidence functional is a Boolean probability measure on the relevant type space.
What would settle it
An explicit language model and definable event where the confidence values on formulas fail to satisfy the axioms of a Boolean probability measure, for instance by producing a collection of measure-one formulas that does not form a proper filter.
Figures

read the original abstract
This paper develops a model-theoretic framework for verifying context-conditioned language-model behavior by replacing benchmark labels with finite semantic certificates. The first problem is finite determinacy: when do examples in a context force the answer to a query without changing model parameters? In finite-field linear task families, we prove an exact row-space criterion, compute the residual hypothesis count, derive full and query-local identification curves, and show that extracting a smallest forcing subcontext is NP-complete even for binary outputs. The second problem is threshold emergence: when does an apparent benchmark jump reflect a semantic transition rather than a discontinuity of the scoring map? We prove an anti-mirage theorem separating thresholded metrics from semantic confidence and give a rate-sensitive crossing bound for latent commitments becoming visible above threshold. The common semantic object is a confidence functional on definable events. We show that it is a Boolean probability measure, equivalently a Keisler measure on the relevant type space, whose measure-one formulas form a proper filter and whose Stone-space representation is invariant under definitional expansion. The resulting calculus provides finite context certificates, pair-separator hitting sets, query teaching dimension, prompt-preservation criteria, and scale-limit witnesses. Exact-arithmetic ancillary scripts reproduce the finite-field and threshold calculations and generate the data used by the figures.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops a model-theoretic framework for finite semantic certificates in language-model in-context behavior. In finite-field linear task families it proves an exact row-space criterion for determinacy, computes residual hypothesis counts, derives identification curves, shows NP-completeness of the smallest forcing subcontext problem, and proves an anti-mirage theorem separating thresholded metrics from semantic confidence. The central semantic object is a confidence functional shown to be a Boolean probability measure (equivalently a Keisler measure on the type space) whose measure-one formulas form a proper filter; the framework yields pair-separator hitting sets, query teaching dimension, prompt-preservation criteria and scale-limit witnesses. Exact-arithmetic ancillary scripts are supplied to reproduce the finite-field and threshold calculations.
Significance. If the derivations hold, the work supplies a parameter-free, finite-certificate calculus that distinguishes genuine semantic transitions from scoring discontinuities and furnishes verifiable certificates for context-conditioned determinacy. The explicit provision of machine-reproducible exact-arithmetic scripts is a clear strength, permitting direct verification of the linear-algebraic claims and the anti-mirage bound. The identification of the confidence functional with a Keisler measure and the Stone-space invariance result give the framework a clean model-theoretic grounding that could be useful for formal analysis of in-context learning.
minor comments (2)
- [Abstract] The abstract and introduction state multiple distinct theorems (row-space criterion, NP-completeness, anti-mirage bound) in rapid succession; a short roadmap paragraph listing the section numbers in which each appears would improve navigation.
- [§2] Notation for the confidence functional and the associated filter is introduced without an explicit comparison table to standard probability or Keisler-measure terminology; adding such a table in §2 would clarify the Boolean-probability claim.
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation of minor revision. The recognition of the row-space criterion, NP-completeness result, anti-mirage theorem, reproducible scripts, and Keisler-measure interpretation is appreciated. As the report lists no specific major comments under the MAJOR COMMENTS section, we have no points requiring rebuttal or revision.
Circularity Check
No significant circularity identified
full rationale
The paper derives its central results—an exact row-space criterion for finite determinacy, residual hypothesis counts, identification curves, NP-completeness of smallest forcing subcontext, and an anti-mirage theorem—directly from model-theoretic assumptions on a confidence functional (Boolean probability measure / Keisler measure) combined with finite-field linear algebra. These steps are presented as proofs rather than quantities defined in terms of themselves, with no fitted parameters renamed as predictions, no self-citation load-bearing the core claims, and no ansatz or uniqueness theorem imported circularly. Ancillary exact-arithmetic scripts are supplied for reproduction, confirming the derivations stand independently of the target results. The modeling choice that the confidence functional is a Keisler measure is an explicit assumption, not a self-referential reduction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Language-model behavior on definable events can be modeled by structures admitting a Boolean probability measure (Keisler measure) on the type space.
- standard math The row-space criterion and NP-completeness hold inside finite-field linear task families.
Reference graph
Works this paper leans on
-
[1]
Richard M. Karp. Reducibility among combinatorial problems. In Raymond E. Miller and James W. Thatcher, editors,Complexity of Computer Computations, pages 85–103. Plenum Press, 1972
1972
-
[2]
Alchourrón, Peter Gärdenfors, and David Makinson
Carlos E. Alchourrón, Peter Gärdenfors, and David Makinson. On the logic of theory change: Partial meet contraction and revision functions.Journal of Symbolic Logic, 50(2):510–530, 1985
1985
-
[3]
Transformers learn to implement preconditioned gradient descent for in-context learning , url =
Kwangjun Ahn, Xiang Cheng, Hadi Daneshmand, and Suvrit Sra. Transformers learn to implement preconditioned gradient descent for in-context learning.arXiv preprint arXiv:2306.00297, 2023
-
[4]
What learning algorithm is in-context learning? Investigations with linear models
Ekin Akyürek, Dale Schuurmans, Jacob Andreas, Tengyu Ma, and Denny Zhou. What learning algorithm is in-context learning? Investigations with linear models. InInternational Conference on Learning Representations, 2023
2023
-
[5]
Brown et al
Tom B. Brown et al. Language models are few-shot learners.Advances in Neural Information Processing Systems, 33:1877–1901, 2020
1901
-
[6]
PaLM: Scaling Language Modeling with Pathways
Aakanksha Chowdhery et al. PaLM: Scaling language modeling with pathways.arXiv preprint arXiv:2204.02311, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[7]
Frank and Noah D
Michael C. Frank and Noah D. Goodman. Predicting pragmatic reasoning in language games.Science, 336(6084):998–998, 2012
2012
-
[8]
What can transformers learn in-context? A case study of simple function classes.Advances in Neural Information Processing Systems, 35:30583–30598, 2022
Shivam Garg, Dimitris Tsipras, Percy Liang, and Gregory Valiant. What can transformers learn in-context? A case study of simple function classes.Advances in Neural Information Processing Systems, 35:30583–30598, 2022
2022
-
[9]
Goodman and Andreas Stuhlmüller
Noah D. Goodman and Andreas Stuhlmüller. Knowledge and implicature: Modeling language understanding as social cognition.Topics in Cognitive Science, 5(1):173–184, 2013
2013
-
[10]
Paul Grice.Studies in the Way of Words
H. Paul Grice.Studies in the Way of Words. Harvard University Press, 1989. 38
1989
-
[11]
PhD thesis, University of Massachusetts Amherst, 1982
Irene Heim.The Semantics of Definite and Indefinite Noun Phrases. PhD thesis, University of Massachusetts Amherst, 1982
1982
-
[12]
Cambridge University Press, 1993
Wilfrid Hodges.Model Theory. Cambridge University Press, 1993
1993
-
[13]
Training Compute-Optimal Large Language Models
Jordan Hoffmann et al. Training compute-optimal large language models.arXiv preprint arXiv:2203.15556, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[14]
Scaling Laws for Neural Language Models
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models.arXiv preprint arXiv:2001.08361, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[15]
Nonmonotonic reasoning, preferen- tial models and cumulative logics.Artificial Intelligence, 44(1–2):167–207, 1990
Sarit Kraus, Daniel Lehmann, and Menachem Magidor. Nonmonotonic reasoning, preferen- tial models and cumulative logics.Artificial Intelligence, 44(1–2):167–207, 1990
1990
-
[16]
Scorekeeping in a language game.Journal of Philosophical Logic, 8(1):339–359, 1979
David Lewis. Scorekeeping in a language game.Journal of Philosophical Logic, 8(1):339–359, 1979
1979
-
[17]
Springer, 2002
David Marker.Model Theory: An Introduction. Springer, 2002
2002
-
[18]
The proper treatment of quantification in ordinary English
Richard Montague. The proper treatment of quantification in ordinary English. In Jaakko Hintikka, Julius M. E. Moravcsik, and Patrick Suppes, editors,Approaches to Natural Language, pages 221–242. Reidel, 1973
1973
-
[19]
In-context Learning and Induction Heads
Catherine Olsson et al. In-context learning and induction heads.arXiv preprint arXiv:2209.11895, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[20]
OpenAI. GPT-4 technical report.arXiv preprint arXiv:2303.08774, 2023.https://cdn. openai.com/papers/gpt-4.pdf
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[21]
Introducing GPT-4.1 in the API
OpenAI. Introducing GPT-4.1 in the API. OpenAI technical release, 2025. https:// openai.com/index/gpt-4-1/.https://openai.com/index/gpt-4-1/
2025
-
[22]
Introducing GPT-5 for developers
OpenAI. Introducing GPT-5 for developers. OpenAI technical release, 2025. https: //openai.com/index/introducing-gpt-5-for-developers/. https://openai.com/ index/introducing-gpt-5-for-developers/
2025
-
[23]
Introducing GPT-5.5
OpenAI. Introducing GPT-5.5. OpenAI technical release, 2026. https://openai.com/ index/introducing-gpt-5-5/.https://openai.com/index/introducing-gpt-5-5/
2026
-
[24]
A logic for default reasoning.Artificial Intelligence, 13(1–2):81–132, 1980
Raymond Reiter. A logic for default reasoning.Artificial Intelligence, 13(1–2):81–132, 1980
1980
-
[25]
Are emergent abilities of large language models a mirage?, 2023
Rylan Schaeffer, Brando Miranda, and Sanmi Koyejo. Are emergent abilities of large language models a mirage?arXiv preprint arXiv:2304.15004, 2023
-
[26]
Stalnaker
Robert C. Stalnaker. Assertion. In Peter Cole, editor,Syntax and Semantics 9: Pragmatics, pages 315–332. Academic Press, 1978
1978
-
[27]
arXiv preprint arXiv:2212.07677 , year=
Johannes von Oswald et al. Transformers learn in-context by gradient descent.arXiv preprint arXiv:2212.07677, 2022
-
[28]
Emergent abilities of large language models.Transactions on Machine Learning Research, 2022
Jason Wei et al. Emergent abilities of large language models.Transactions on Machine Learning Research, 2022
2022
-
[29]
An explanation of in-context learning as implicit Bayesian inference
Sang Michael Xie, Aditi Raghunathan, Percy Liang, and Tengyu Ma. An explanation of in-context learning as implicit Bayesian inference. InInternational Conference on Learning Representations, 2022. 39
2022
-
[30]
Goldman and Michael J
Sally A. Goldman and Michael J. Kearns. On the complexity of teaching.Journal of Computer and System Sciences, 50(1):20–31, 1995
1995
-
[31]
Jerome Keisler
H. Jerome Keisler. Measures and forking.Annals of Pure and Applied Logic, 34(2):119–169, 1987
1987
-
[32]
Learning quickly when irrelevant attributes abound: A new linear-threshold algorithm.Machine Learning, 2:285–318, 1988
Nick Littlestone. Learning quickly when irrelevant attributes abound: A new linear-threshold algorithm.Machine Learning, 2:285–318, 1988
1988
-
[33]
Fantastically ordered prompts and where to find them: Overcoming few-shot prompt order sensitivity
Yao Lu, Max Bartolo, Alastair Moore, Sebastian Riedel, and Pontus Stenetorp. Fantastically ordered prompts and where to find them: Overcoming few-shot prompt order sensitivity. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics, pages 8086–8098, 2022
2022
-
[34]
Cambridge University Press, 2015
Pierre Simon.A Guide to NIP Theories. Cambridge University Press, 2015. 40
2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.