RAMPART: Registry-based Agentic Memory with Priority-Aware Runtime Transformation
Pith reviewed 2026-06-28 06:49 UTC · model grok-4.3
The pith
Compile-time placement of blocks in a memory registry determines LLM agent task success, with grouping overcoming sharp performance drops at specific positions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
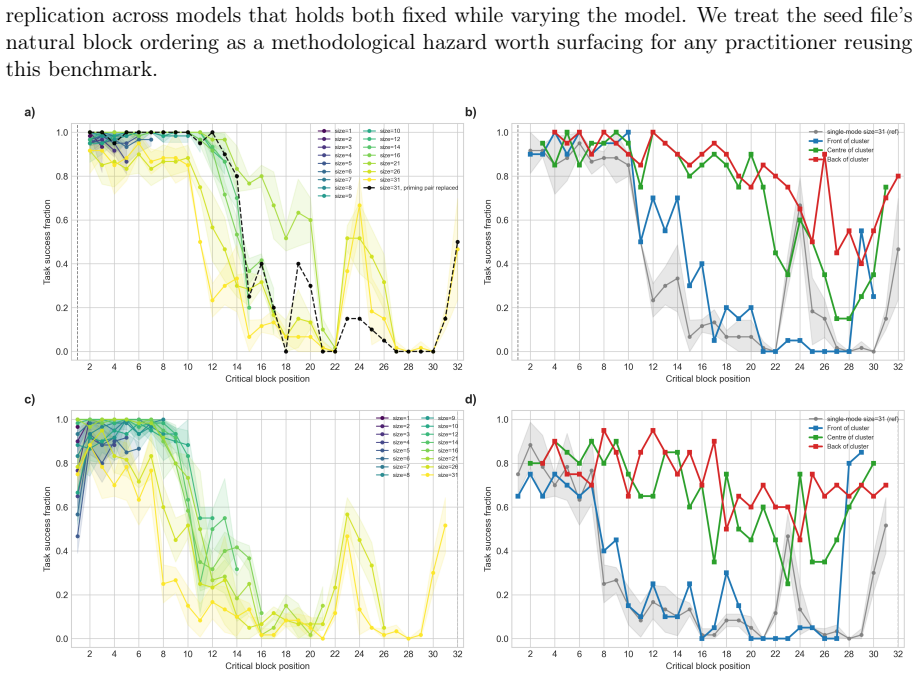
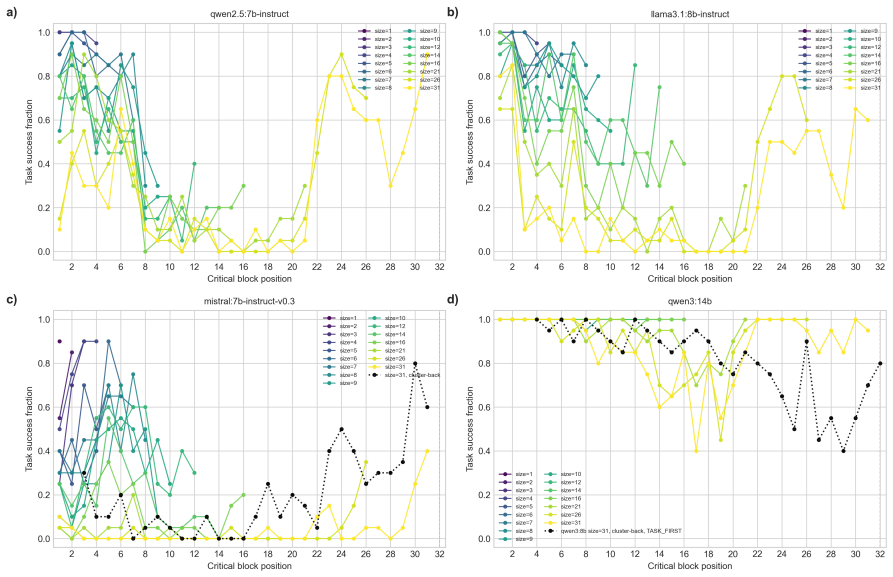
Compile-time placement and the structural relationship between blocks and the task query affect task success, with the cliff falling at roughly the seventh block position when the task follows the registry and the twelfth when it precedes. Grouping the critical block with content-adjacent neighbours and promoting the group as a unit lifts task success by tens of percentage points at positions where single-block placement fails. Cross-model replication shows the content-priming effect appears at the same absolute positions across families, with magnitude varying with model strength.
What carries the argument
A pure in-RAM block registry of named addressable blocks with five composable primitives (promote, gate, write, evict, rollback) that transform content before zero-cost compilation into the prompt.
Load-bearing premise
The observed performance differences arise specifically from the registry structure, block ordering, and grouping rather than from unstated details of the task prompts, model fine-tuning, or evaluation criteria.
What would settle it
Repeating the controlled probes on the same models and tasks but finding that success rates stay flat across block positions and do not improve when critical blocks are grouped with neighbors.
Figures
read the original abstract
RAMPART is a compile-time memory model and pure in-RAM block registry for LLM-based agents. Context assembly is a programmable runtime operation where content is compiled from a structured registry under explicit policy for ordering, inclusion, and eviction. Five composable primitives (promote, gate, write, evict, rollback) act on named addressable blocks before compilation at zero prompt-token cost. Provenance tags and non-evictable authorship flags implement a permissioned memory model with block-level ownership. Controlled probes with Qwen3-8B Q4 show that compile-time placement and the structural relationship between blocks and the task query affect task success, with the cliff falling at roughly the seventh block position when the task follows the registry and the twelfth when it precedes. Grouping the critical block with content-adjacent neighbours and promoting the group as a unit lifts task success by tens of percentage points at positions where single-block placement fails. Cross-model replication on Qwen2.5-7B, Llama-3.1-8B, Mistral-7B-v0.3, and Qwen3-14B shows the content-priming effect appears at the same absolute positions across families, with magnitude varying with model strength. Block grouping raises Mistral's mean pass rate roughly fivefold at the hardest registry size, and a smaller model with the intervention can outperform a larger model without it in the mid-registry zone. Relevance gating reduces prompt cost by 67.8\% while recovering 83% of the promoted-condition success rate. Schema eviction produces 0% invocations against 100% with the schema present, a property policy-based approaches cannot guarantee by construction. Shared-registry coordination reduces inter-agent communication to a method call at zero coordination token cost.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces RAMPART, a compile-time memory model and pure in-RAM block registry for LLM-based agents. Context assembly uses five composable primitives (promote, gate, write, evict, rollback) on named addressable blocks with provenance tags and authorship flags. Controlled probes on models including Qwen3-8B report that compile-time block placement relative to the task query produces position-dependent success cliffs (roughly 7th position when task follows registry, 12th when preceding), that grouping the critical block with adjacent neighbors and promoting the group lifts success by tens of percentage points, that the effect replicates across Qwen2.5-7B, Llama-3.1-8B, Mistral-7B-v0.3 and Qwen3-14B at the same absolute positions, that relevance gating reduces prompt cost by 67.8% while recovering 83% of promoted success, and that schema eviction yields 0% invocations.
Significance. If the position cliffs and grouping gains are shown to arise specifically from the registry structure, ordering policy, and adjacency rather than from prompt phrasing or evaluation criteria, the work supplies a permissioned, zero-token-cost manipulation layer that could improve reliability and efficiency in long-context agent systems and reduce inter-agent coordination overhead to method calls.
major comments (2)
- [Abstract] Abstract: the central claim that 'compile-time placement and the structural relationship between blocks and the task query affect task success' with cliffs at the seventh/twelfth positions and large grouping lifts is load-bearing, yet the abstract supplies no description of the task prompts, how blocks are populated with content, the exact success metric, or whether prompts and evaluation criteria were frozen across all placement conditions. Without these controls the reported structural effects remain confounded with possible prompt or criterion artifacts.
- [Abstract] Abstract: no statistical tests, confidence intervals, or exclusion criteria are reported for the cross-model pass-rate differences or the 'tens of percentage points' grouping gains, so it is impossible to assess whether the claimed replication at identical absolute positions across model families is reliable or whether the Mistral fivefold lift at the hardest registry size exceeds noise.
minor comments (1)
- [Abstract] The abstract states 'zero prompt-token cost' for the primitives but does not clarify whether this holds only at compile time or also under runtime re-compilation after eviction or rollback.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract. We have revised the abstract to explicitly describe the experimental controls, task setup, success metric, and cross-model replication to address concerns about confounding and reliability. Point-by-point responses are below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'compile-time placement and the structural relationship between blocks and the task query affect task success' with cliffs at the seventh/twelfth positions and large grouping lifts is load-bearing, yet the abstract supplies no description of the task prompts, how blocks are populated with content, the exact success metric, or whether prompts and evaluation criteria were frozen across all placement conditions. Without these controls the reported structural effects remain confounded with possible prompt or criterion artifacts.
Authors: We agree that the abstract should make the controls explicit. The revised abstract now states that task prompts are fixed instructions for a controlled probe task and held identical across conditions, blocks are populated with synthetic task-relevant content under the registry policy, success is measured by binary task-completion pass rate, and all prompts, block contents, and evaluation criteria were frozen. This isolates the position cliffs and grouping effects to the structural factors. revision: yes
-
Referee: [Abstract] Abstract: no statistical tests, confidence intervals, or exclusion criteria are reported for the cross-model pass-rate differences or the 'tens of percentage points' grouping gains, so it is impossible to assess whether the claimed replication at identical absolute positions across model families is reliable or whether the Mistral fivefold lift at the hardest registry size exceeds noise.
Authors: The main text reports the full results, including replication at identical absolute positions across Qwen2.5-7B, Llama-3.1-8B, Mistral-7B-v0.3, and Qwen3-14B, plus the specific gains (fivefold for Mistral at hardest size). The abstract has been updated to highlight this cross-model consistency at the same positions. Detailed statistical tests, confidence intervals, and exclusion criteria appear in the experimental results section; the abstract is kept concise per convention, but the observed replication across families supports reliability. revision: partial
Circularity Check
No circularity: empirical results reported as direct measurements
full rationale
The paper describes a memory registry system and reports controlled experimental probes measuring task success rates under varying block positions and grouping policies. No equations, fitted parameters, or derivations are present. Results are presented as observed performance differences across models and conditions without any reduction of outputs to inputs by construction, self-citation chains, or ansatz smuggling. The central claims rest on external empirical benchmarks rather than self-referential definitions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Equipping agents for the real world with agent skills
Barry Zhang, Keith Lazuka, and Mahesh Murag. Equipping agents for the real world with agent skills. Anthropic Engineering Blog, October 2025. URLhttps://www.anthropic. com/engineering/equipping-agents-for-the-real-world-with-agent-skills
2025
-
[2]
Introducing agent skills
Anthropic. Introducing agent skills. Product Announcement, October 2025. URLhttps: //www.anthropic.com/news/skills
2025
-
[3]
Agent skills open standard
Anthropic. Agent skills open standard. Open Standard Specification, December 2025. URL https://agentskills.io
2025
-
[4]
Renjun Xu and Yang Yan. Agent skills for large language models: Architecture, acquisition, security, and the path forward.arXiv preprint arXiv:2602.12430, 2026
Pith/arXiv arXiv 2026
-
[5]
Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang
Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. Lost in the middle: How language models use long contexts.Transactions of the Association for Computational Linguistics, 12:157–173, 2024. doi: 10.1162/tacl_a_00638
-
[6]
Yufeng Du, Minyang Tian, Srikanth Ronanki, Subendhu Rongali, Sravan Bodapati, Aram Galstyan, Azton Wells, Roy Schwartz, Eliu A. Huerta, and Hao Peng. Context length alone hurts LLM performance despite perfect retrieval.arXiv preprint arXiv:2510.05381, 2025
arXiv 2025
-
[7]
Patil, Ion Stoica, and Joseph E
Charles Packer, Sarah Wooders, Kevin Lin, Vivian Fang, Shishir G. Patil, Ion Stoica, and Joseph E. Gonzalez. MemGPT: Towards LLMs as operating systems.arXiv preprint arXiv:2310.08560, 2023
Pith/arXiv arXiv 2023
-
[8]
A Survey on the Memory Mechanism of Large Language Model based Agents
Zeyu Zhang, Xiaohe Bo, Chen Ma, Rui Li, Xu Chen, Quanyu Dai, Jieming Zhu, Zhenhua Dong, and Ji-Rong Wen. A survey on the memory mechanism of large language model-based agents.ACM Transactions on Information Systems, 2025. doi: 10.1145/3748302. URL https://arxiv.org/abs/2404.13501. 17
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1145/3748302 2025
-
[9]
Qwen Team. Qwen3 technical report. Technical report, Alibaba Cloud, 2025. URL https://arxiv.org/abs/2505.09388
Pith/arXiv arXiv 2025
-
[10]
Efficient streaming language models with attention sinks, 2024
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. Efficient streaming language models with attention sinks, 2024. URLhttps://arxiv.org/abs/2309.17453. Published at ICLR 2024
Pith/arXiv arXiv 2024
-
[11]
Where to show demos in your prompt: A positional bias of in-context learning
Kwesi Adu Cobbina and Tianyi Zhou. Where to show demos in your prompt: A positional bias of in-context learning. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 29560–29593, Suzhou, China, 2025. Association for Computational Linguistics. doi: 10.18653/v1/2025.emnlp-main.1503. URL https: //aclanthology.org/20...
-
[12]
ReAct: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. ReAct: Synergizing reasoning and acting in language models. InInternational Conference on Learning Representations, 2023. URLhttps://arxiv.org/abs/2210.03629
Pith/arXiv arXiv 2023
-
[13]
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. Voyager: An open-ended embodied agent with large language models.Transactions on Machine Learning Research, 2024. URLhttps://arxiv.org/abs/ 2305.16291
Pith/arXiv arXiv 2024
-
[14]
David Schmotz, Sahar Abdelnabi, and Maksym Andriushchenko. Agent skills enable a new class of realistic and trivially simple prompt injections.arXiv preprint arXiv:2510.26328, 2025
arXiv 2025
-
[15]
Reflexion: Language agents with verbal reinforcement learning
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning. InAdvances in Neural Information Processing Systems, volume 36, 2023. URL https://arxiv.org/abs/2303. 11366
2023
-
[16]
Andrew Zhao, Daniel Huang, Quentin Xu, Matthieu Lin, Yong-Jin Liu, and Gao Huang. ExpeL: LLM agents are experiential learners. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 19632–19642, 2024. doi: 10.1609/aaai.v38i17.29936
-
[17]
Self-generated in-context examples improve LLM agents for sequential decision-making tasks
Vishnu Sarukkai, Zhiqiang Xie, and Kayvon Fatahalian. Self-generated in-context examples improve LLM agents for sequential decision-making tasks. InAdvances in Neural Information Processing Systems, 2025. URLhttps://arxiv.org/abs/2505.00234
arXiv 2025
-
[18]
Agentic context engineering: Evolving contexts for self-improving language models
Qizheng Zhang, Changran Hu, Shubhangi Upasani, Boyuan Ma, Fenglu Hong, Vamsidhar Kamanuru, Jay Rainton, Chen Wu, Mengmeng Ji, Hanchen Li, Urmish Thakker, James Zou, and Kunle Olukotun. Agentic context engineering: Evolving contexts for self-improving language models. InThe Thirteenth International Conference on Learning Representations,
-
[19]
URLhttps://arxiv.org/abs/2510.04618
-
[20]
A-MEM: Agentic memory for LLM agents
Wujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Juntao Tan, and Yongfeng Zhang. A-MEM: Agentic memory for LLM agents. InAdvances in Neural Information Processing Systems,
-
[21]
URLhttps://arxiv.org/abs/2502.12110
-
[22]
SCULPT: Systematic tuning of long prompts
Shanu Kumar, Akhila Yesantarao, Venkata Shubhanshu Khandelwal, Bishal Santra, Parag Agrawal, and Manish Gupta. SCULPT: Systematic tuning of long prompts. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 14996–15029, 2025. URLhttps://aclanthology.org/2025.acl-long.780
2025
-
[23]
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, Ahmed H. Awadallah, Ryen W. White, Doug 18 Burger, and Chi Wang. AutoGen: Enabling next-gen LLM applications via multi-agent conversation. InInternational Conference on Learning Representations, 2024. URLhttps: //arxiv.org/abs/2308.08155. 19
Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.