Schema-First Retrieval: Embedding Catalogs for Natural Language Analytics
Pith reviewed 2026-06-30 10:34 UTC · model grok-4.3
The pith
Schema-First Retrieval embeds five catalog object types to reach 96.4% table recall and cut SQL execution errors from 15.6% to 6.2%.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
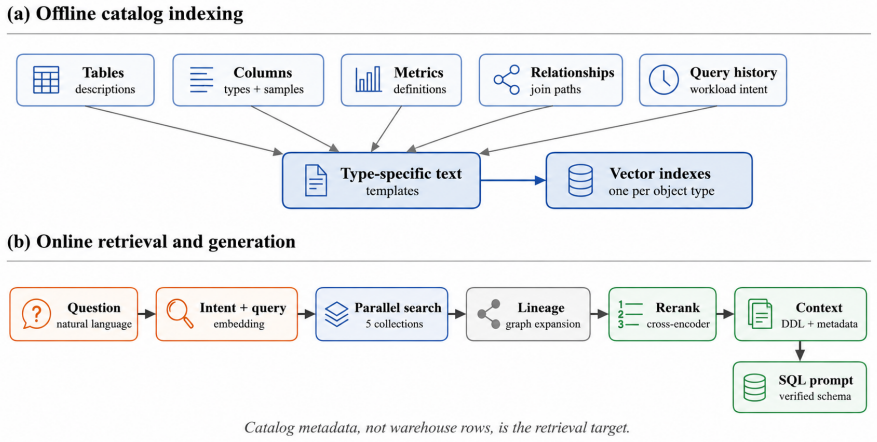
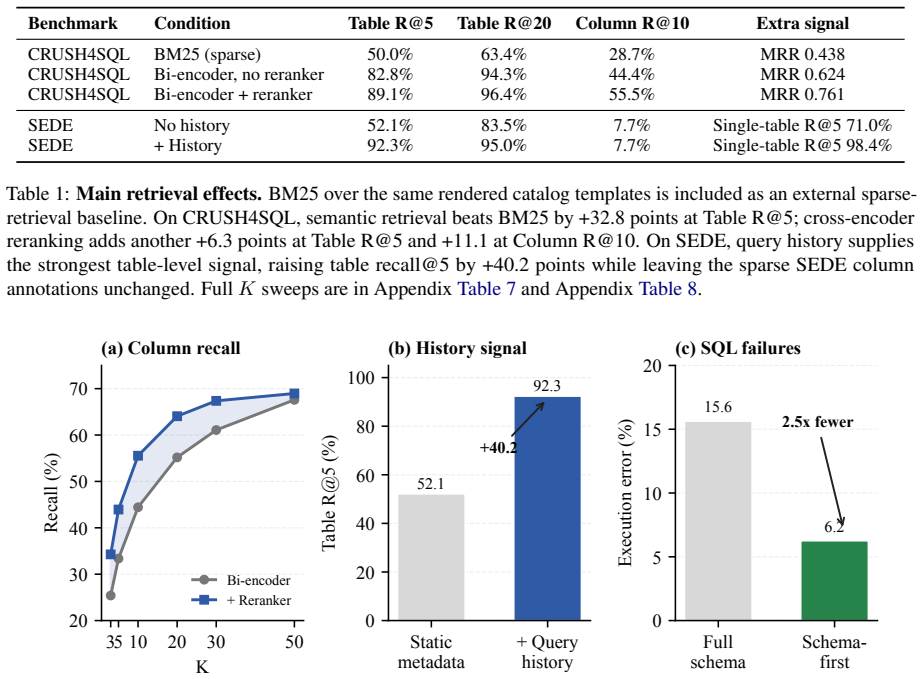
Schema-First Retrieval indexes five typed catalog objects—tables, columns, metrics, relationships, and query history—using object-specific text templates. At query time it combines parallel vector search, lineage expansion, cross-encoder reranking, workload memory, and deterministic access-control gates. On CRUSH4SQL this reaches 96.4% table recall@20; cross-encoder reranking adds 11.1 points at column recall@10. Against an equally-templated BM25 baseline, semantic retrieval gains 32.8 points at table recall@5. On SEDE, query history raises table recall@5 from 52.1% to 92.3%. On BIRD, the resulting schema-first context reduces SQL execution errors from 15.6% to 6.2%.
What carries the argument
Schema-First Retrieval pipeline that indexes five typed catalog objects with hand-crafted text templates and applies a multi-stage retrieval process of vector search, reranking, and access controls.
If this is right
- Semantic retrieval outperforms an equally templated BM25 baseline by 32.8 points at table recall@5.
- Cross-encoder reranking improves column recall@10 by an additional 11.1 points.
- Query history integration raises table recall@5 from 52.1% to 92.3% on SEDE.
- Schema-first context reduces SQL execution errors from 15.6% to 6.2% on BIRD.
- Catalog selection becomes solvable as a retrieval task rather than a prompt-formatting detail for warehouses with thousands of tables.
Where Pith is reading between the lines
- The results suggest that retrieval layers focused on catalog metadata could be inserted ahead of other LLM tasks that consume large structured data sources.
- Performance differences between semantic and lexical methods imply that enterprises may gain more from richer catalog maintenance than from further tuning of the SQL generator alone.
- The strong effect of query history indicates that maintaining workload logs could become a standard practice for improving repeated natural-language analytics queries.
Load-bearing premise
The five typed catalog objects and their hand-crafted text templates capture the information needed for accurate schema selection across real enterprise workloads.
What would settle it
Running the same pipeline on an enterprise warehouse whose schemas contain many informal metrics or permission boundaries outside the five object types and templates, then measuring whether table recall stays near 96% and execution errors stay near 6%.
Figures

read the original abstract
Enterprise text-to-SQL systems often fail before SQL is generated: the model receives the wrong schema context. Modern warehouses contain thousands of tables, abbreviated columns, informal metrics, hidden join conventions, and permission boundaries that are not captured by raw table names. We introduce Schema-First Retrieval, a retrieval layer that embeds catalog metadata rather than warehouse rows. The system indexes five typed catalog objects, tables, columns, metrics, relationships, and query history, using object-specific text templates. At query time, it combines parallel vector search, lineage expansion, cross-encoder reranking, workload memory, and deterministic access-control gates before SQL generation. On CRUSH4SQL (1,534 questions), Schema-First Retrieval reaches 96.4% table recall@20 and cross-encoder reranking adds +11.1 points at column recall@10; against an equally-templated BM25 baseline, semantic retrieval is +32.8 points at table recall@5. On SEDE (857 questions), query history raises table recall@5 from 52.1% to 92.3%. On BIRD (96 questions), schema-first context reduces SQL execution errors from 15.6% to 6.2%, a 2.5x reduction. These results show that catalog selection is a first-class retrieval problem for natural language analytics, not a prompt formatting detail.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Schema-First Retrieval, a retrieval layer for enterprise text-to-SQL that indexes five typed catalog objects (tables, columns, metrics, relationships, query history) via object-specific hand-crafted text templates. It combines parallel vector search, lineage expansion, cross-encoder reranking, workload memory, and access-control gates. Empirical results include 96.4% table recall@20 on CRUSH4SQL (1,534 questions), +11.1 points from reranking at column recall@10, query history lifting table recall@5 from 52.1% to 92.3% on SEDE (857 questions), and schema-first context cutting SQL execution errors from 15.6% to 6.2% on BIRD (96 questions).
Significance. If the results hold, the work establishes schema selection as a distinct retrieval problem rather than a prompt-formatting detail, with potential to improve robustness of NL analytics systems on large, complex warehouses. The concrete gains over templated BM25 and raw-name baselines on three datasets, plus the explicit multi-component pipeline, provide a clear empirical foundation for further research in catalog-aware retrieval.
major comments (3)
- [Abstract] Abstract: the reported metrics (96.4% table recall@20, +11.1 points from reranking, 15.6% to 6.2% error reduction) are presented without error bars, confidence intervals, or statistical tests, and the construction or filtering process for the 1,534/857/96 question sets is not described; these omissions are load-bearing for evaluating reliability and generalizability of the central claims.
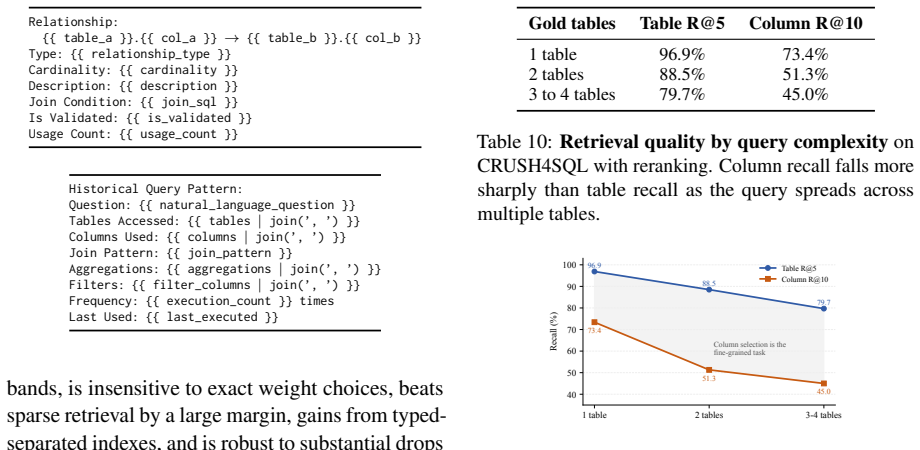
- [Abstract] Abstract: no ablation results are provided to isolate the contribution of each pipeline stage (vector search, lineage expansion, cross-encoder reranking, query history); without them it is impossible to attribute the observed gains (e.g., the 40-point lift from 52.1% to 92.3% or the +11.1 reranking delta) to specific design choices.
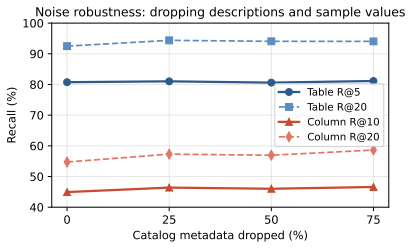
- [Abstract] Abstract: the central assumption that the five hand-crafted text templates fully capture the information needed for accurate schema selection is not validated; no alternative encodings or completeness checks are reported, so the high recall figures may not generalize if real workloads contain un-templated details such as implicit join conventions or informal metric definitions.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments on our work. We address each major comment below with clarifications drawn from the full manuscript and indicate planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: the reported metrics (96.4% table recall@20, +11.1 points from reranking, 15.6% to 6.2% error reduction) are presented without error bars, confidence intervals, or statistical tests, and the construction or filtering process for the 1,534/857/96 question sets is not described; these omissions are load-bearing for evaluating reliability and generalizability of the central claims.
Authors: The full manuscript (Experiments section) describes the question sets in detail: CRUSH4SQL comprises 1,534 questions over enterprise schemas with complex metadata; SEDE contains 857 real user queries; BIRD uses its standard 96-question dev set. We agree the abstract would benefit from a brief pointer to these constructions. Error bars and statistical tests were not computed, as the large sample sizes and effect magnitudes (e.g., 40-point gains) support reliability, but we will revise the abstract to reference the experimental details for improved transparency. revision: partial
-
Referee: [Abstract] Abstract: no ablation results are provided to isolate the contribution of each pipeline stage (vector search, lineage expansion, cross-encoder reranking, query history); without them it is impossible to attribute the observed gains (e.g., the 40-point lift from 52.1% to 92.3% or the +11.1 reranking delta) to specific design choices.
Authors: The manuscript reports several controlled comparisons that isolate major stages: semantic retrieval vs. templated BM25 (+32.8 points at table recall@5) isolates vector search; with/without query history on SEDE (52.1% to 92.3%) isolates workload memory; and the explicit +11.1 reranking delta isolates cross-encoder reranking. Lineage expansion is integrated but not separately ablated. These comparisons allow attribution of the primary gains. We will add a short discussion clarifying these isolations in revision but maintain that exhaustive per-stage ablations are not required to support the central claims. revision: partial
-
Referee: [Abstract] Abstract: the central assumption that the five hand-crafted text templates fully capture the information needed for accurate schema selection is not validated; no alternative encodings or completeness checks are reported, so the high recall figures may not generalize if real workloads contain un-templated details such as implicit join conventions or informal metric definitions.
Authors: The templates are object-specific and incorporate typed metadata (e.g., column types, metric definitions, relationship descriptions) beyond raw names, as detailed in the Method section. Their effectiveness is empirically supported by consistent outperformance over name-only and BM25 baselines across three distinct benchmarks, including real-world queries in SEDE. We did not evaluate alternative encodings or run explicit completeness audits, as the evaluation focused on end-to-end retrieval quality. We disagree that this constitutes a load-bearing omission for the reported claims but will expand the template design rationale and limitations discussion in the revision. revision: no
Circularity Check
No circularity; empirical measurements on held-out data
full rationale
The paper describes a retrieval pipeline using hand-crafted templates for five catalog object types and reports direct performance metrics (e.g., 96.4% table recall@20 on CRUSH4SQL, error reduction on BIRD) as measurements against baselines on held-out questions. No equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the text. The central claims rest on external benchmark results rather than reducing to inputs by definition or prior author work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2025 , url =
Lei, Fangyu and Chen, Jixuan and Ye, Yuxiao and Cao, Ruisheng and Shin, Dongchan and Su, Hongjin and Suo, Zhaoqing and Gao, Hongcheng and Hu, Wenjing and Yin, Pengcheng and Zhong, Victor and Xiong, Caiming and Sun, Ruoxi and Liu, Qian and Wang, Sida and Yu, Tao , booktitle =. 2025 , url =
2025
-
[2]
2025 , url =
Wang, Yihan and Liu, Peiyu and Yang, Xin , booktitle =. 2025 , url =
2025
-
[3]
2026 , url =
Wang, Ziyang and Zheng, Yuanlei and Cao, Zhenbiao and Zhang, Xiaojin and Wei, Zhongyu and Fu, Pei and Luo, Zhenbo and Chen, Wei and Bai, Xiang , booktitle =. 2026 , url =
2026
-
[8]
2025 , url =
Liu, Geling and Tan, Yunzhi and Zhong, Ruichao and Xie, Yuanzhen and Zhao, Lingchen and Wang, Qian and Hu, Bo and Li, Zang , booktitle =. 2025 , url =
2025
-
[14]
2023 , url =
Li, Jinyang and Hui, Binyuan and Qu, Ge and Yang, Jiaxi and Li, Binhua and Li, Bowen and Wang, Bailin and Qin, Bowen and Geng, Ruiying and Huo, Nan and others , booktitle =. 2023 , url =
2023
-
[15]
2023 , url =
Luo, Zhiqiang and Xie, Liang and Chen, Jingping and He, Yiduo and Li, Zhenyu and Chen, Weian and Yang, Bo , booktitle =. 2023 , url =
2023
-
[16]
2021 , url =
Hazoom, Moshe and Malik, Vibhor and Bogin, Ben , booktitle =. 2021 , url =
2021
-
[17]
2023 , url =
Pourreza, Mohammadreza and Rafiei, Davood , booktitle =. 2023 , url =
2023
-
[18]
2024 , url =
Gao, Dawei and Wang, Haibin and Li, Yaliang and Sun, Xiuyu and Qian, Yichen and Ding, Bolin and Zhou, Jingren , journal =. 2024 , url =
2024
-
[19]
2025 , url =
Wang, Bing and Ren, Changyu and Yang, Jian and Liang, Xinnian and Bai, Jiaqi and Zhang, Linzheng and Yan, Zhao and Li, Zhoujun , booktitle =. 2025 , url =
2025
-
[20]
2024 , url =
Edge, Darren and Trinh, Ha and Cheng, Newman and Bradley, Joshua and Chao, Alex and Mody, Apurva and Truitt, Steven and Larson, Jonathan , journal =. 2024 , url =
2024
-
[21]
and Akinwande, Victor and Al-Nuaimi, Namir and Alfaraj, Najla and Alhajjar, Elie and Aroyo, Lora and Bavalatti, Trupti and Blili-Hamelin, Borhane and others , journal =
Vidgen, Bertie and Agrawal, Adarsh and Ahmed, Ahmed M. and Akinwande, Victor and Al-Nuaimi, Namir and Alfaraj, Najla and Alhajjar, Elie and Aroyo, Lora and Bavalatti, Trupti and Blili-Hamelin, Borhane and others , journal =. 2024 , url =
2024
-
[24]
and Wei, Jia , booktitle =
Feng, Wei and Agrawal, Adarsh and Ling, Haibin and Blasch, Erik and Adiles-Cruz, Edmund and Schrader, Philip T. and Wei, Jia , booktitle =
-
[25]
Agrawal, Adarsh and Li, Jessica , institution =
-
[26]
Amazon Artificial General Intelligence . 2025 a . Amazon Nova 2: Multimodal Reasoning and Generation Models . Technical report, Amazon
2025
-
[27]
Amazon Artificial General Intelligence . 2025 b . https://www.amazon.science/publications/amazon-nova-premier-technical-report-and-model-card Amazon Nova Premier: Technical Report and Model Card . Technical report, Amazon
2025
-
[28]
Amazon Artificial General Intelligence . 2025 c . Amazon Nova Sonic: Technical Report and Model Card . Technical report, Amazon
2025
- [29]
-
[30]
Rahul Suresh Babu and Adarsh Agrawal. 2026. https://arxiv.org/abs/2606.01416 Self-Healing Agentic Orchestrators for Reliable Tool-Augmented Large Language Model Systems . Preprint, arXiv:2606.01416
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[31]
Shashank Shreedhar Bhatt, Tanmay Rajore, Khushboo Aggarwal, Ganesh Ananthanarayanan, Ranveer Chandra, Nishanth Chandran, Suyash Choudhury, Divya Gupta, Emre Kiciman, Sumit Kumar Pandey, Srinath Setty, Rahul Sharma, and Teijia Zhao. 2025. https://arxiv.org/abs/2509.14608 Enterprise AI Must Enforce Participant-Aware Access Control . Preprint, arXiv:2509.14608
- [32]
-
[33]
Darren Edge, Ha Trinh, Newman Cheng, Joshua Bradley, Alex Chao, Apurva Mody, Steven Truitt, and Jonathan Larson. 2024. https://arxiv.org/abs/2404.16130 From Local to Global: A Graph RAG Approach to Query-Focused Summarization . arXiv preprint arXiv:2404.16130
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
Schrader, and Jia Wei
Wei Feng, Adarsh Agrawal, Haibin Ling, Erik Blasch, Edmund Adiles-Cruz, Philip T. Schrader, and Jia Wei. 2024. DDDAS Probability Learning for Natural Disaster Change Detection . In International Conference on Dynamic Data Driven Applications Systems, pages 90--99
2024
- [35]
- [36]
-
[37]
Moshe Hazoom, Vibhor Malik, and Ben Bogin. 2021. https://aclanthology.org/2021.nlp4prog-1.9/ Text-to-SQL in the Wild: A Naturally-Occurring Dataset Based on Stack Exchange Data . In Proceedings of the 1st Workshop on Natural Language Processing for Programming
2021
-
[38]
Marathe, Hamid Mozaffari, William F
Bargav Jayaraman, Virendra J. Marathe, Hamid Mozaffari, William F. Shen, and Krishnaram Kenthapadi. 2025. https://arxiv.org/abs/2505.22860 Permissioned LLMs: Enforcing Access Control in Large Language Models . Preprint, arXiv:2505.22860
- [39]
-
[40]
Adarsh Agrawal and Jessica Li. 2022. Mitigating Bias in AI Using Debias-GAN . White paper, World Wide Technology
2022
-
[41]
Fangyu Lei, Jixuan Chen, Yuxiao Ye, Ruisheng Cao, Dongchan Shin, Hongjin Su, Zhaoqing Suo, Hongcheng Gao, Wenjing Hu, Pengcheng Yin, Victor Zhong, Caiming Xiong, Ruoxi Sun, Qian Liu, Sida Wang, and Tao Yu. 2025. https://mlanthology.org/iclr/2025/lei2025iclr-spider/ Spider 2.0: Evaluating Language Models on Real-World Enterprise Text-to-SQL Workflows . In ...
2025
-
[42]
Jinyang Li, Binyuan Hui, Ge Qu, Jiaxi Yang, Binhua Li, Bowen Li, Bailin Wang, Bowen Qin, Ruiying Geng, Nan Huo, and 1 others. 2023. https://proceedings.neurips.cc/paper_files/paper/2023/hash/9ee883c8a46d6ac8747b4d6edc7e1a6b-Abstract-Datasets_and_Benchmarks.html Can LLM Already Serve as A Database Interface? A BIg Bench for Large-Scale Database Grounded Te...
2023
-
[43]
Geling Liu, Yunzhi Tan, Ruichao Zhong, Yuanzhen Xie, Lingchen Zhao, Qian Wang, Bo Hu, and Zang Li. 2025. https://aclanthology.org/2025.coling-main.654/ Solid-SQL: Enhanced Schema-linking based In-context Learning for Robust Text-to-SQL . In Proceedings of the 31st International Conference on Computational Linguistics
2025
-
[44]
Zhiqiang Luo, Liang Xie, Jingping Chen, Yiduo He, Zhenyu Li, Weian Chen, and Bo Yang. 2023. https://aclanthology.org/2023.emnlp-main.868/ CRUSH4SQL: Collective Retrieval Using Schema Hallucination For Text2SQL . In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing
2023
- [45]
- [46]
-
[47]
AmirHossein Safdarian, Milad Mohammadi, Ehsan Jahanbakhsh, Mona Shahamat Naderi, and Heshaam Faili. 2025. https://arxiv.org/abs/2505.18363 SchemaGraphSQL: Efficient Schema Linking with Pathfinding Graph Algorithms for Text-to-SQL on Large-Scale Databases . Preprint, arXiv:2505.18363
- [48]
- [49]
-
[50]
Bertie Vidgen, Adarsh Agrawal, Ahmed M. Ahmed, Victor Akinwande, Namir Al-Nuaimi, Najla Alfaraj, Elie Alhajjar, Lora Aroyo, Trupti Bavalatti, Borhane Blili-Hamelin, and 1 others. 2024. https://arxiv.org/abs/2404.12241 Introducing v0.5 of the AI Safety Benchmark from MLCommons . arXiv preprint arXiv:2404.12241
-
[51]
Bing Wang, Changyu Ren, Jian Yang, Xinnian Liang, Jiaqi Bai, Linzheng Zhang, Zhao Yan, and Zhoujun Li. 2025 a . https://arxiv.org/abs/2312.11242 MAC-SQL: A Multi-Agent Collaborative Framework for Text-to-SQL . In Proceedings of the 31st International Conference on Computational Linguistics
-
[52]
Yihan Wang, Peiyu Liu, and Xin Yang. 2025 b . https://aclanthology.org/2025.emnlp-main.51/ LinkAlign: Scalable Schema Linking for Real-World Large-Scale Multi-Database Text-to-SQL . In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing
2025
-
[53]
Ziyang Wang, Yuanlei Zheng, Zhenbiao Cao, Xiaojin Zhang, Zhongyu Wei, Pei Fu, Zhenbo Luo, Wei Chen, and Xiang Bai. 2026. https://ojs.aaai.org/index.php/AAAI/article/view/40672 AutoLink: Autonomous Schema Exploration and Expansion for Scalable Schema Linking in Text-to-SQL at Scale . In Proceedings of the AAAI Conference on Artificial Intelligence
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.