The Scientific Contribution Graph: Automated Literature-based Technological Roadmapping at Scale
Pith reviewed 2026-06-30 20:38 UTC · model grok-4.3
The pith
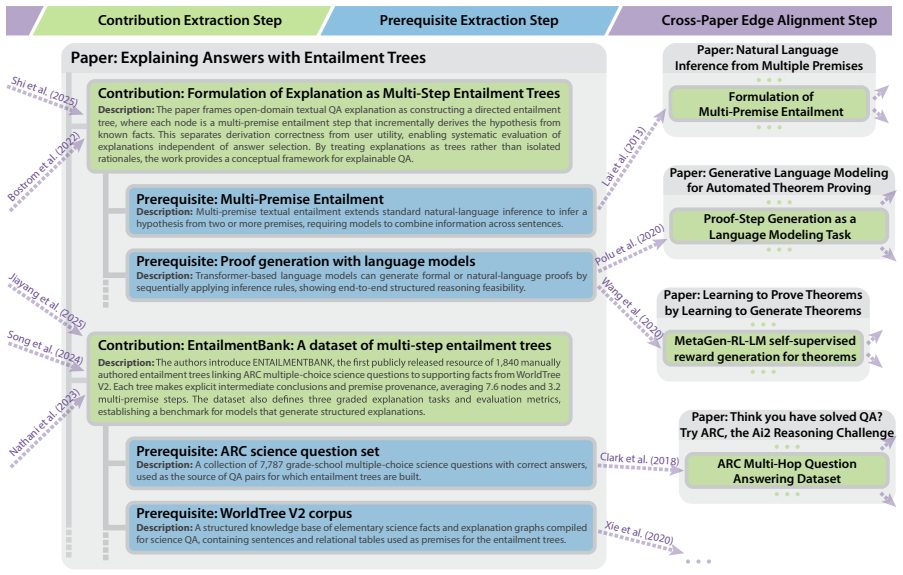
The Scientific Contribution Graph extracts 2 million contributions from 230k papers and connects them with 12.5 million prerequisite edges to enable automated technological roadmapping.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We present the Scientific Contribution Graph, a large-scale AI/NLP-domain resource containing 2 million detailed scientific contributions extracted from 230k open-access papers and connected by 12.5 million prerequisite edges. We introduce scientific prerequisite prediction, a task in which models predict which existing technologies can enable future discoveries, and show that contemporary models reach 0.48 MAP when evaluated using temporally filtered backtesting.
What carries the argument
The Scientific Contribution Graph, which stores extracted contributions as nodes and prerequisite relationships extracted from paper text as directed edges.
If this is right
- The graph directly supports scientific impact assessment by tracing how contributions build on one another.
- It provides training data for models that predict which technologies will enable new discoveries.
- Temporally filtered backtesting shows measurable improvement in prerequisite prediction performance.
- Resources of this form can be used to automate portions of the scientific discovery process.
Where Pith is reading between the lines
- The same extraction approach could be applied to domains outside AI and NLP to build comparable roadmapping graphs.
- The graph structure might reveal clusters of contributions that have no clear prerequisites, highlighting potential independent breakthroughs.
- Combining the graph with citation or usage data could produce new metrics for forecasting long-term scientific influence.
- Live deployment of the prediction models on newly published papers would test whether the backtested performance holds in practice.
Load-bearing premise
Automatically extracting individual contributions and their prerequisite links from scholarly text yields a graph accurate enough for roadmapping and prediction tasks.
What would settle it
A manual audit of several thousand extracted nodes and edges that finds the majority of prerequisite links do not correspond to actual enabling relationships in the source papers.
Figures
read the original abstract
Scientific contributions rarely develop in isolation, but instead build upon prior discoveries. We formulate the task of automated technological roadmapping as extracting scientific contributions from scholarly articles and linking them to their prerequisites. We present the Scientific Contribution Graph, a large-scale AI/NLP-domain resource containing 2 million detailed scientific contributions extracted from 230k open-access papers and connected by 12.5 million prerequisite edges. We further introduce scientific prerequisite prediction, a scientific discovery task in which models predict which existing technologies can enable future discoveries, and show that contemporary models are rapidly improving on this task, reaching 0.48 MAP when evaluated using temporally filtered backtesting. We anticipate technological roadmapping resources such as this will support scientific impact assessment and automated scientific discovery.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formulates automated technological roadmapping as the task of extracting scientific contributions from scholarly articles and linking them to their prerequisites. It presents the Scientific Contribution Graph, a resource with 2 million detailed contributions extracted from 230k open-access AI/NLP papers and connected by 12.5 million prerequisite edges. It introduces the scientific prerequisite prediction task and reports that contemporary models reach 0.48 MAP under temporally filtered backtesting.
Significance. A validated large-scale graph of this form could support impact assessment and discovery applications. The use of temporal backtesting is a methodological strength that reduces forward-leakage risk. However, the central claims rest entirely on the unvalidated quality of the automated extraction pipeline.
major comments (2)
- [Abstract] Abstract: the abstract states the size of the resource (2M contributions, 12.5M edges) and the MAP number but supplies no information on extraction accuracy, validation procedures, or error analysis, so the data cannot be checked against the claims.
- [No section] No section: no held-out human annotation study is described that measures precision, recall, or inter-annotator agreement for either contribution span extraction or directed prerequisite edges; without such metrics the 0.48 MAP result cannot be interpreted as evidence that the graph supports the claimed roadmapping applications.
minor comments (1)
- [Methods] The extraction pipeline and any parameters used in edge construction should be described with sufficient detail to allow reproduction and error analysis.
Simulated Author's Rebuttal
We thank the referee for the detailed review and for highlighting the importance of validating the automated extraction pipeline. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the abstract states the size of the resource (2M contributions, 12.5M edges) and the MAP number but supplies no information on extraction accuracy, validation procedures, or error analysis, so the data cannot be checked against the claims.
Authors: We agree that the abstract would be strengthened by additional context on the extraction process. In the revised manuscript we will expand the abstract to briefly outline the contribution extraction and prerequisite linking pipeline and to note that the primary empirical validation of the resulting graph is provided by the temporally filtered backtesting of the prerequisite prediction task. revision: yes
-
Referee: [No section] No section: no held-out human annotation study is described that measures precision, recall, or inter-annotator agreement for either contribution span extraction or directed prerequisite edges; without such metrics the 0.48 MAP result cannot be interpreted as evidence that the graph supports the claimed roadmapping applications.
Authors: We acknowledge that a held-out human annotation study with precision, recall, and IAA metrics would provide stronger direct evidence for the quality of the extracted contributions and edges. The manuscript focuses on releasing the large-scale resource and introducing the scientific prerequisite prediction task, with evaluation performed via temporal backtesting to minimize forward leakage. Conducting a comprehensive human study at the scale of 2 million contributions was outside the scope of the present work. We will add a dedicated limitations section that explicitly discusses reliance on automated extraction, the absence of human validation metrics, and the need for future annotation efforts. The reported 0.48 MAP still demonstrates that contemporary models can exploit the graph for the defined prediction task under the stated evaluation protocol. revision: partial
- Quantitative precision, recall, and inter-annotator agreement figures from a held-out human annotation study on contribution spans and prerequisite edges, as no such study was conducted.
Circularity Check
No significant circularity detected
full rationale
The paper constructs the Scientific Contribution Graph via automated extraction from 230k papers and defines a downstream prerequisite prediction task evaluated with temporally filtered backtesting on external models (reaching 0.48 MAP). No equations, self-definitional steps, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided abstract or description. The derivation chain is self-contained: the graph serves as an independent resource, and the reported model performance is not forced by construction from the extraction process itself.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Waleed Ammar, Dirk Groeneveld, Chandra Bhagavatula, Iz Beltagy, Miles Crawford, Doug Downey, Jason Dunkelberger, Ahmed Elgohary, Sergey Feldman, Vu Ha, Rodney Kinney, Sebastian Kohlmeier, Kyle Lo, Tyler Murray, Hsu-Han Ooi, Matthew Peters, Joanna Power, Sam Skjonsberg, Lucy Lu Wang, and 4 others. 2018. https://doi.org/10.18653/v1/N18-3011 Construction of ...
-
[2]
Jinheon Baek, Sujay Kumar Jauhar, Silviu Cucerzan, and Sung Ju Hwang. 2025. https://doi.org/10.18653/v1/2025.naacl-long.342 R esearch A gent: Iterative research idea generation over scientific literature with large language models . In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistic...
-
[3]
Michael Balzer and Adhen Benlahlou. 2025. Mitigating consequences of prestige in citations of publications. Scientometrics, pages 1--28
2025
-
[4]
Eugenio Cesario, Carmela Comito, and Ester Zumpano. 2024. A survey of the recent trends in deep learning for literature based discovery in the biomedical domain. Neurocomputing, 568:127079
2024
-
[5]
Gamal Crichton, Simon Baker, Yufan Guo, and Anna Korhonen. 2020. Neural networks for open and closed literature-based discovery. PloS one, 15(5):e0232891
2020
-
[6]
John Dagdelen, Alexander Dunn, Sanghoon Lee, Nicholas Walker, Andrew S Rosen, Gerbrand Ceder, Kristin A Persson, and Anubhav Jain. 2024. Structured information extraction from scientific text with large language models. Nature communications, 15(1):1418
2024
-
[7]
Abhipsha Das, Nicholas Lourie, Siavash Golkar, and Mariel Pettee. 2025. https://api.semanticscholar.org/CorpusID:276961662 What's in your field? mapping scientific research with knowledge graphs and large language models . ArXiv, abs/2503.09894
arXiv 2025
-
[8]
Dess \'i , Francesco Osborne, D
D. Dess \'i , Francesco Osborne, D. Recupero, D. Buscaldi, and E. Motta. 2022. https://doi.org/10.1016/j.knosys.2022.109945 Scicero: A deep learning and nlp approach for generating scientific knowledge graphs in the computer science domain . Knowl. Based Syst., 258:109945
-
[9]
Danilo Dess \' , Francesco Osborne, Davide Buscaldi, Diego Reforgiato Recupero, and Enrico Motta. 2025. Cs-kg 2.0: A large-scale knowledge graph of computer science. Scientific Data, 12(1):964
2025
-
[10]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. https://doi.org/10.18653/v1/N19-1423 BERT : Pre-training of deep bidirectional transformers for language understanding . In Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long a...
-
[11]
Jennifer D ' Souza, S \"o ren Auer, and Ted Pedersen. 2021. https://doi.org/10.18653/v1/2021.semeval-1.44 S em E val-2021 task 11: NLPC ontribution G raph - structuring scholarly NLP contributions for a research knowledge graph . In Proceedings of the 15th International Workshop on Semantic Evaluation (SemEval-2021), pages 364--376, Online. Association fo...
-
[12]
Joy He-Yueya, Anikait Singh, Ge Gao, Michael Y Li, Sherry Yang, Chelsea Finn, Emma Brunskill, and Noah D Goodman. 2026. Giants: Generative insight anticipation from scientific literature. arXiv preprint arXiv:2604.09793
Pith/arXiv arXiv 2026
-
[13]
Sarthak Jain, Madeleine van Zuylen, Hannaneh Hajishirzi, and Iz Beltagy. 2020. https://doi.org/10.18653/v1/2020.acl-main.670 S ci REX : A challenge dataset for document-level information extraction . In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 7506--7516, Online. Association for Computational Linguistics
-
[14]
Peter Jansen, Samiah Hassan, and Ruoyao Wang. 2025 a . https://aclanthology.org/2025.emnlp-main.203/ Matter-of-fact: A benchmark for verifying the feasibility of literature-supported claims in materials science . In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 4090--4102, Suzhou, China. Association for Comp...
2025
-
[15]
Peter Jansen, Oyvind Tafjord, Marissa Radensky, Pao Siangliulue, Tom Hope, Bhavana Dalvi Mishra, Bodhisattwa Prasad Majumder, Daniel S Weld, and Peter Clark. 2025 b . https://doi.org/10.18653/v1/2025.findings-acl.692 C ode S cientist: End-to-end semi-automated scientific discovery with code-based experimentation . In Findings of the Association for Comput...
-
[16]
Vincent Larivi \`e re and Yves Gingras. 2010. The impact factor's matthew effect: A natural experiment in bibliometrics. Journal of the American society for information science and technology, 61(2):424--427
2010
-
[17]
u ttler, Mike Lewis, Wen-tau Yih, Tim Rockt \
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich K \"u ttler, Mike Lewis, Wen-tau Yih, Tim Rockt \"a schel, Sebastian Riedel, and Douwe Kiela. 2020. Retrieval-augmented generation for knowledge-intensive nlp tasks. In NeurIPS
2020
-
[18]
Long Li, Weiwen Xu, Jiayan Guo, Ruochen Zhao, Xingxuan Li, Yuqian Yuan, Boqiang Zhang, Yuming Jiang, Yifei Xin, Ronghao Dang, Yu Rong, Deli Zhao, Tian Feng, and Lidong Bing. 2025. https://aclanthology.org/2025.findings-emnlp.477/ Chain of ideas: Revolutionizing research via novel idea development with LLM agents . In Findings of the Association for Comput...
2025
-
[19]
Xiangci Li, Biswadip Mandal, and Jessica Ouyang. 2022. https://doi.org/10.18653/v1/2022.naacl-main.397 CORWA : A citation-oriented related work annotation dataset . In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 5426--5440, Seattle, United States. Ass...
-
[20]
Xiangci Li and Jessica Ouyang. 2024. https://doi.org/10.18653/v1/2024.emnlp-main.767 Related work and citation text generation: A survey . In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 13846--13864, Miami, Florida, USA. Association for Computational Linguistics
-
[21]
Kyle Lo, Lucy Lu Wang, Mark Neumann, Rodney Kinney, and Daniel Weld. 2020. https://doi.org/10.18653/v1/2020.acl-main.447 S 2 ORC : The semantic scholar open research corpus . In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 4969--4983, Online. Association for Computational Linguistics
-
[22]
Chris Lu, Cong Lu, Robert Tjarko Lange, Jakob Foerster, Jeff Clune, and David Ha. 2024. https://arxiv.org/abs/2408.06292 The ai scientist: Towards fully automated open-ended scientific discovery . Preprint, arXiv:2408.06292
Pith/arXiv arXiv 2024
-
[23]
Yi Luan, Luheng He, Mari Ostendorf, and Hannaneh Hajishirzi. 2018. https://doi.org/10.18653/v1/D18-1360 Multi-task identification of entities, relations, and coreference for scientific knowledge graph construction . In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 3219--3232, Brussels, Belgium. Association f...
-
[24]
Valenzuela-Esc \'a rcega, Gus Hahn-Powell, and Mihai Surdeanu
Fan Luo, Marco A. Valenzuela-Esc \'a rcega, Gus Hahn-Powell, and Mihai Surdeanu. 2018. https://doi.org/10.18653/v1/W18-1701 Scientific discovery as link prediction in influence and citation graphs . In Proceedings of the Twelfth Workshop on Graph-Based Methods for Natural Language Processing ( T ext G raphs-12) , pages 1--6, New Orleans, Louisiana, USA. A...
-
[25]
Ian Magnusson and Scott Friedman. 2021. https://doi.org/10.18653/v1/2021.emnlp-main.381 Extracting fine-grained knowledge graphs of scientific claims: Dataset and transformer-based results . In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 4651--4658, Online and Punta Cana, Dominican Republic. Association fo...
-
[26]
Manning, Prabhakar Raghavan, and Hinrich Sch \"u tze
Christopher D. Manning, Prabhakar Raghavan, and Hinrich Sch \"u tze. 2008. Introduction to Information Retrieval. Cambridge University Press
2008
-
[27]
Ishani Mondal, Yufang Hou, and Charles Jochim. 2021. https://doi.org/10.18653/v1/2021.findings-acl.165 End-to-end construction of NLP knowledge graph . In Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, pages 1885--1895, Online. Association for Computational Linguistics
-
[28]
Afzal, and Hanan Aljuaid
Shahzad Nazir, Muhammad Asif, Shahbaz Ahmad, Faisal Bukhari, M. Afzal, and Hanan Aljuaid. 2020. https://api.semanticscholar.org/CorpusId:212565209 Important citation identification by exploiting content and section-wise in-text citation count . PLoS ONE, 15
2020
-
[29]
Wolfgang Otto, Matth \"a us Zloch, Lu Gan, Saurav Karmakar, and Stefan Dietze. 2023. https://doi.org/10.18653/v1/2023.findings-emnlp.548 GSAP - NER : A novel task, corpus, and baseline for scholarly entity extraction focused on machine learning models and datasets . In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 8166--8176...
-
[30]
Aniket Pramanick, Yufang Hou, Saif M. Mohammad, and Iryna Gurevych. 2025. https://doi.org/10.18653/v1/2025.acl-long.1224 The nature of NLP : Analyzing contributions in NLP papers . In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 25169--25191, Vienna, Austria. Association for Computa...
-
[31]
Yiyuan Pu, Daniel Beck, and Karin Verspoor. 2023. Graph embedding-based link prediction for literature-based discovery in alzheimer’s disease. Journal of Biomedical Informatics, 145:104464
2023
-
[32]
Marissa Radensky, Simra Shahid, Raymond Fok, Pao Siangliulue, Tom Hope, and Daniel S Weld. 2024. Scideator: Human-llm scientific idea generation grounded in research-paper facet recombination. arXiv preprint arXiv:2409.14634
Pith/arXiv arXiv 2024
-
[33]
Mahsa Shamsabadi, Jennifer D ' Souza, and S \"o ren Auer. 2024. https://aclanthology.org/2024.findings-eacl.26/ Large language models for scientific information extraction: An empirical study for virology . In Findings of the Association for Computational Linguistics: EACL 2024, pages 374--392, St. Julian ' s, Malta. Association for Computational Linguistics
2024
-
[34]
Chenglei Si, Diyi Yang, and Tatsunori Hashimoto. 2025. https://openreview.net/forum?id=M23dTGWCZy Can LLM s generate novel research ideas? a large-scale human study with 100+ NLP researchers . In The Thirteenth International Conference on Learning Representations
2025
-
[35]
Ilya Sutskever, Oriol Vinyals, and Quoc V. Le. 2014. Sequence to sequence learning with neural networks. In Advances in Neural Information Processing Systems, volume 27
2014
-
[36]
Don R. Swanson. 1986. https://doi.org/10.1353/pbm.1986.0087 Fish oil, raynaud's syndrome, and undiscovered public knowledge . Perspectives in Biology and Medicine, 30(1):7--18
-
[37]
Don R Swanson. 1988. Migraine and magnesium: eleven neglected connections. Perspectives in biology and medicine, 31(4):526--557
1988
-
[38]
Misha Teplitskiy, Eamon Duede, Michael Menietti, and Karim R Lakhani. 2022. How status of research papers affects the way they are read and cited. Research policy, 51(4):104484
2022
-
[39]
Ha, and Oren Etzioni
Marco Valenzuela, Vu A. Ha, and Oren Etzioni. 2015. https://api.semanticscholar.org/CorpusID:2538517 Identifying meaningful citations . In AAAI Workshop: Scholarly Big Data
2015
-
[40]
Rosni Vasu, Chandrayee Basu, Bhavana Dalvi Mishra, Cristina Sarasua, Peter Clark, and Abraham Bernstein. 2025. https://aclanthology.org/2025.emnlp-main.1292/ H yp ER : Literature-grounded hypothesis generation and distillation with provenance . In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 25424--25449, S...
2025
-
[41]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In Advances in Neural Information Processing Systems, volume 30
2017
-
[42]
Yifan Wang, Yiping Song, Shuai Li, Chaoran Cheng, Wei Ju, Ming Zhang, and Sheng Wang. 2022. https://api.semanticscholar.org/CorpusId:250289362 Disencite: Graph-based disentangled representation learning for context-specific citation generation . In AAAI Conference on Artificial Intelligence
2022
-
[43]
Smith, Daniel Khashabi, and Hannaneh Hajishirzi
Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A. Smith, Daniel Khashabi, and Hannaneh Hajishirzi. 2023. https://doi.org/10.18653/v1/2023.acl-long.754 Self-instruct: Aligning language models with self-generated instructions . In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), p...
-
[44]
Fang Zhang and Shengli Wu. 2021. https://api.semanticscholar.org/CorpusId:236150770 Measuring academic entities’ impact by content-based citation analysis in a heterogeneous academic network . Scientometrics, 126:7197 -- 7222
2021
-
[45]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[46]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.