Bounding-Box Trajectories Matter for Video Anomaly Detection
Pith reviewed 2026-05-22 07:02 UTC · model grok-4.3
The pith
Bounding-box trajectories alone can model normal video motion well enough to detect anomalies better than pose-based approaches.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
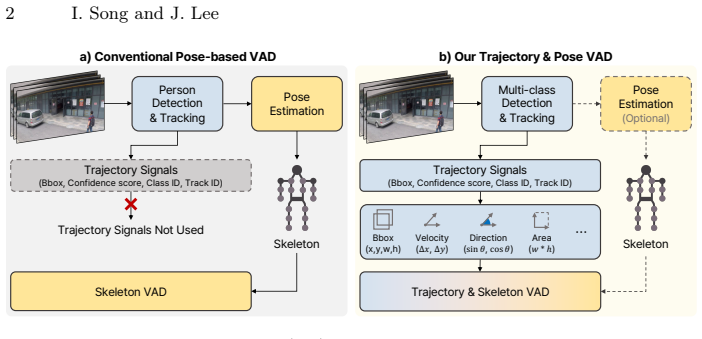
We present TrajVAD, a framework that models multi-class bounding-box trajectories using normalizing flows to learn normal kinematic patterns. Its trajectory-only variant (TrajVAD-T) eliminates pose estimation and surpasses all compared pose-based methods on ShanghaiTech in AP (87.7%), while achieving the best results on MSAD. An extended version (TrajVAD-P) incorporates pose information and further improves performance to 88.6% AUROC and 90.9% AP on ShanghaiTech.
What carries the argument
Normalizing flows for modeling multi-class bounding-box trajectories as a way to capture normal kinematic patterns in videos.
Load-bearing premise
Bounding-box trajectories contain enough information about motion to distinguish normal from anomalous events across the tested video datasets.
What would settle it
Evaluating the trajectory-only model on a new dataset featuring anomalies that change body pose but keep the same bounding box path, such as a person suddenly waving arms abnormally while staying in place, and checking if detection rates fall below those of pose-based methods.
Figures



read the original abstract
Video anomaly detection is critical for public safety and security, yet remains highly challenging despite extensive research due to large variations in appearance, viewpoint, and scene dynamics. Among existing approaches, human pose-based methods have emerged as a major line of research, showing strong performance since many anomalies in public datasets involve humans and pose representations are robust to appearance changes while providing compact motion descriptions. However, these methods often overlook bounding-box trajectories, although such information is inherently available in pose-based pipelines. In this paper, we explicitly leverage these trajectories as a primary anomaly cue. We present TrajVAD, a framework that models multi-class bounding-box trajectories using normalizing flows to learn normal kinematic patterns. Its trajectory-only variant (TrajVAD-T) eliminates pose estimation and surpasses all compared pose-based methods on ShanghaiTech in AP (87.7%), while achieving the best results on MSAD. An extended version (TrajVAD-P) incorporates pose information and further improves performance to 88.6% AUROC and 90.9% AP on ShanghaiTech, highlighting bounding-box trajectories as an effective yet underexplored modality for video anomaly detection.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces TrajVAD, a framework for video anomaly detection that models multi-class bounding-box trajectories with normalizing flows to capture normal kinematic patterns. Its trajectory-only variant (TrajVAD-T) eliminates pose estimation and reports outperforming all compared pose-based methods on ShanghaiTech (87.7% AP) while achieving the best results on MSAD; the pose-augmented variant (TrajVAD-P) further improves to 88.6% AUROC and 90.9% AP on ShanghaiTech.
Significance. If the empirical results hold under detailed scrutiny, the work establishes bounding-box trajectories as a sufficient and high-performing modality for VAD, reducing dependence on pose estimation while maintaining competitive or superior accuracy on standard benchmarks. The normalizing-flow density estimation on trajectories is a technically appropriate choice for modeling normal patterns, and the provision of both T and P variants enables direct assessment of the trajectories' contribution.
major comments (2)
- [§4] §4 (Experiments) and associated tables: the claim that TrajVAD-T surpasses all pose-based methods with 87.7% AP on ShanghaiTech requires explicit listing of the AP scores for every cited baseline (including re-implementation details) so that the ranking can be independently verified; without these numbers the superiority statement cannot be assessed.
- [§3.2] §3.2 (multi-class modeling): the assumption that bounding-box trajectories contain sufficient kinematic information is load-bearing for the central claim, yet the paper provides no ablation on class granularity or on trajectory-only versus appearance-augmented inputs; this leaves open whether performance gains are truly attributable to the trajectory modality.
minor comments (1)
- [Abstract] Abstract: performance numbers are stated without accompanying dataset statistics (e.g., number of normal/anomalous frames or trajectory counts), which should be added for context.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important aspects of clarity and experimental rigor that we will address in the revision. We respond to each major comment below.
read point-by-point responses
-
Referee: [§4] §4 (Experiments) and associated tables: the claim that TrajVAD-T surpasses all pose-based methods with 87.7% AP on ShanghaiTech requires explicit listing of the AP scores for every cited baseline (including re-implementation details) so that the ranking can be independently verified; without these numbers the superiority statement cannot be assessed.
Authors: We agree that explicit numerical comparison strengthens the claim. In the revised manuscript we will add a dedicated table in Section 4 that reports the AP scores of every cited pose-based baseline on ShanghaiTech, together with a short note on any re-implementation settings used. This will allow direct verification of the reported ranking and of the 87.7% AP achieved by TrajVAD-T. revision: yes
-
Referee: [§3.2] §3.2 (multi-class modeling): the assumption that bounding-box trajectories contain sufficient kinematic information is load-bearing for the central claim, yet the paper provides no ablation on class granularity or on trajectory-only versus appearance-augmented inputs; this leaves open whether performance gains are truly attributable to the trajectory modality.
Authors: We recognize the value of additional ablations. The manuscript already contrasts the trajectory-only variant (TrajVAD-T) with the pose-augmented variant (TrajVAD-P), which isolates the contribution of trajectories versus an additional kinematic cue. To further address class granularity we will include a new ablation that compares single-class versus multi-class normalizing-flow modeling on ShanghaiTech. Regarding appearance-augmented inputs, we will add a brief discussion clarifying that our design deliberately avoids appearance features to isolate kinematic information; if space permits we will also report a lightweight comparison against a simple appearance baseline. revision: partial
Circularity Check
No significant circularity
full rationale
The paper describes an empirical method that applies standard normalizing flows to multi-class bounding-box trajectories for video anomaly detection, reporting direct benchmark results on ShanghaiTech and MSAD without any derivation steps, equations, or claims that reduce to self-definitions, fitted parameters renamed as predictions, or load-bearing self-citations. The central performance claims (e.g., 87.7% AP for TrajVAD-T) are presented as outcomes of the proposed pipeline rather than tautological restatements of inputs, and the approach remains self-contained against external datasets and comparisons.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We present TrajVAD, a framework that models multi-class bounding-box trajectories using normalizing flows to learn normal kinematic patterns.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
- [1]
-
[2]
Computer Vision and Image Understanding229, 103656 (2023)
Barbalau, A., Ionescu, R.T., Georgescu, M.I., Dueholm, J., Ramachandra, B., Nas- rollahi, K., Khan, F.S., Moeslund, T.B., Shah, M.: SSMTL++: Revisiting self- supervised multi-task learning for video anomaly detection. Computer Vision and Image Understanding229, 103656 (2023)
work page 2023
- [3]
- [4]
-
[5]
Density estimation using Real NVP
Dinh, L., Sohl-Dickstein, J., Bengio, S.: Density estimation using Real NVP. arXiv preprint arXiv:1605.08803 (2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
- [6]
-
[7]
IEEE TPAMI45(6), 7157–7173 (2022)
Fang, H.S., Li, J., Tang, H., Xu, C., Zhu, H., Xiu, Y., Li, Y.L., Lu, C.: AlphaPose: Whole-body regional multi-person pose estimation and tracking in real-time. IEEE TPAMI45(6), 7157–7173 (2022)
work page 2022
- [8]
-
[9]
Flaborea, A., di Melendugno, G.M.D., D’Arrigo, S., Sterpa, M.A., Sampieri, A., Galasso, F.: Contracting skeletal kinematics for human-related video anomaly de- tection. PR156, 110817 (2024)
work page 2024
-
[10]
YOLOX: Exceeding YOLO Series in 2021
Ge, Z., Liu, S., Wang, F., Li, Z., Sun, J.: YOLOX: Exceeding YOLO series in 2021. arXiv preprint arXiv:2107.08430 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
- [11]
- [12]
- [13]
- [14]
- [15]
- [16]
-
[17]
arXiv preprint arXiv:2207.02281 (2022)
Kanu-Asiegbu, A.M., Vasudevan, R., Du, X.: BiPOCO: Bi-directional trajectory prediction with pose constraints for pedestrian anomaly detection. arXiv preprint arXiv:2207.02281 (2022)
- [18]
-
[19]
Kingma, D.P., Dhariwal, P.: Glow: Generative flow with invertible 1x1 convolu- tions. NeurIPS31(2018)
work page 2018
-
[20]
Neurocomputing490, 482–494 (2022)
Li, N., Chang, F., Liu, C.: Human-related anomalous event detection via spatial- temporalgraphconvolutionalautoencoderwithembeddedlongshort-termmemory network. Neurocomputing490, 482–494 (2022)
work page 2022
- [21]
- [22]
-
[23]
Neurocomputing444, 332–337 (2021)
Luo, W., Liu, W., Gao, S.: Normal graph: Spatial temporal graph convolutional networks based prediction network for skeleton based video anomaly detection. Neurocomputing444, 332–337 (2021)
work page 2021
- [24]
- [25]
- [26]
- [27]
-
[28]
IEEE TCSVT18(11), 1544–1554 (2008)
Piciarelli, C., Micheloni, C., Foresti, G.L.: Trajectory-based anomalous event de- tection. IEEE TCSVT18(11), 1544–1554 (2008)
work page 2008
- [29]
- [30]
- [31]
-
[32]
Song, I., Lee, J.: Real-time traffic accident anticipation with feature reuse. In: ICIP (2025)
work page 2025
- [33]
- [34]
- [35]
-
[36]
Cluster Computing25(4), 2715–2737 (2022)
Wu, C., Shao, S., Tunc, C., Satam, P., Hariri, S.: An explainable and efficient deep learning framework for video anomaly detection. Cluster Computing25(4), 2715–2737 (2022)
work page 2022
-
[37]
Wu, R., Chen, Y., Xiao, J., Li, B., Fan, J., Dufaux, F., Zhu, C., Liu, Y.: DA-flow: Dual attention normalizing flow for skeleton-based video anomaly detection. IEEE TMM (2025)
work page 2025
- [38]
- [39]
-
[40]
Zhang, Y., Sun, P., Jiang, Y., Yu, D., Weng, F., Yuan, Z., Luo, P., Liu, W., Wang, X.:ByteTrack:Multi-objecttrackingbyassociatingeverydetectionbox.In:ECCV. pp. 1–21 (2022)
work page 2022
- [41]
-
[42]
Zhu, L., Wang, L., Raj, A., Gedeon, T., Chen, C.: Advancing video anomaly de- tection: A concise review and a new dataset. NeurIPS37, 89943–89977 (2024)
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.