BT-APE: A Computationally Light Backtracking Approach to Automatic Prompt Engineering for Requirements Classification
Pith reviewed 2026-07-02 09:10 UTC · model grok-4.3
The pith
BT-APE produces prompts for requirements classification that reach the accuracy of heavy automatic methods while using 72 percent fewer input tokens and 66 percent less time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
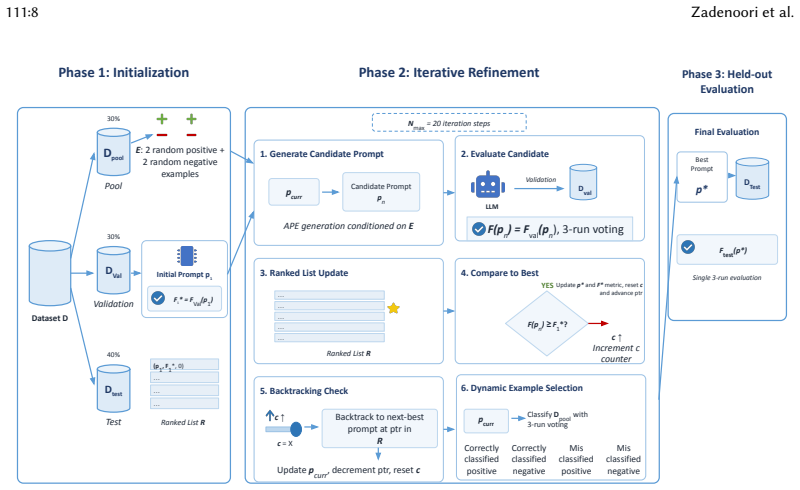
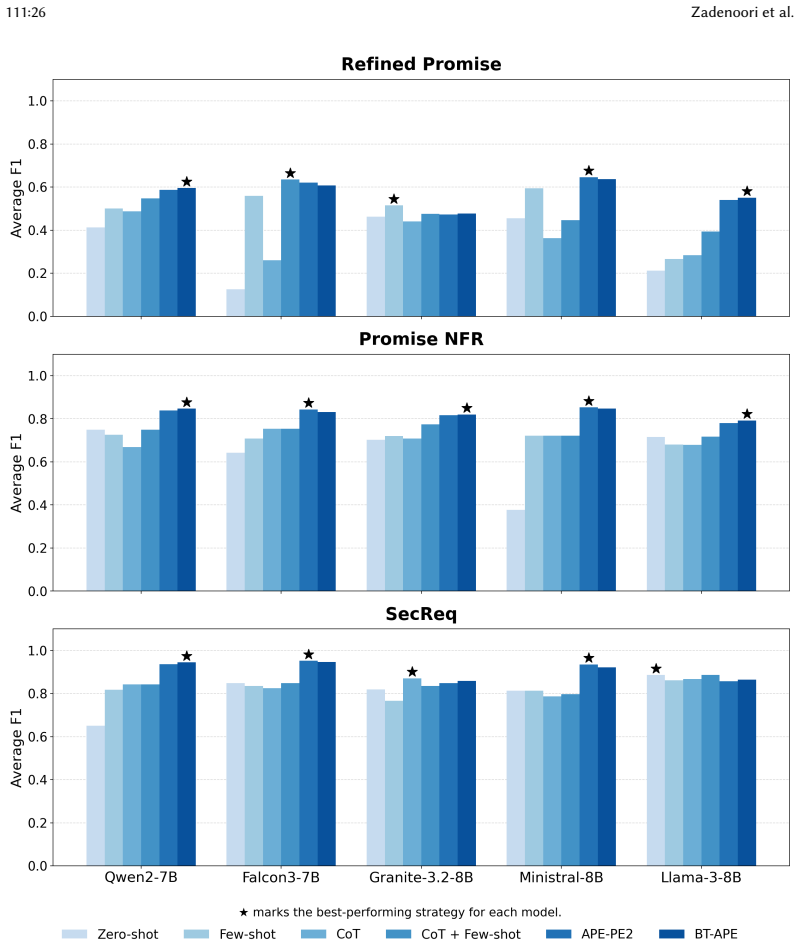
BT-APE iteratively refines prompts for requirements classification by having an LLM propose candidates, then applying backtracking search and dynamic example selection to identify high-performing prompts. Across three datasets and five LLMs it matches the accuracy of the resource-intensive PE2 method while consuming roughly 72 percent fewer input tokens and 66 percent less wall-clock time, and it substantially outperforms four classical prompting baselines with large effect sizes.
What carries the argument
Backtracking search over LLM-generated prompt candidates combined with dynamic example selection.
If this is right
- Requirements classification tasks can shift from manual trial-and-error prompt writing to an automated search process.
- Automated prompt engineering becomes viable under tighter compute budgets than those required by prior heavy methods.
- Performance advantages over zero-shot, few-shot, chain-of-thought, and combined baselines hold across multiple datasets and models.
- Class definitions supplied in the initial prompt influence how the search evolves later candidates.
- An open tool and replication package make the method immediately usable for other requirements engineering classification problems.
Where Pith is reading between the lines
- The same backtracking structure could be tested on related requirements engineering tasks such as traceability link recovery or ambiguity detection.
- Lower token consumption might allow the optimization loop to run repeatedly inside interactive development environments without noticeable delay.
- The observed interaction between class definitions and prompt evolution supplies a concrete starting point for studying how initial human-written constraints shape automated search outcomes.
Load-bearing premise
The combination of backtracking search and dynamic example selection will locate prompts that continue to perform well on datasets and models outside the three benchmarks and five LLMs examined.
What would settle it
Running BT-APE on a fourth independent requirements classification dataset or with a sixth LLM and finding that its accuracy falls materially below PE2 or fails to exceed the classical baselines.
Figures

read the original abstract
Large language models (LLMs) are increasingly applied to requirements engineering (RE) tasks, yet the prompts guiding them are typically designed manually through trial and error, yielding inconsistent and suboptimal results. Automated prompt construction remains largely unexplored in RE, leaving its effectiveness unclear. To address this, we propose a lightweight Automatic Prompt Engineering approach, Backtracking APE (BT-APE), and apply it to requirements classification. We frame prompt design as an optimization problem, iteratively refining prompts via LLM-generated candidates, backtracking search, and dynamic example selection. Evaluating BT-APE on three benchmark datasets with five instruction-tuned LLMs, we compare it against four classical prompting baselines (zero-shot, few-shot, chain-of-thought, CoT+few-shot) and a state-of-the-art but resource-intensive APE baseline (PE2). BT-APE and PE2 achieve nearly identical accuracy, both substantially outperforming the classical baselines with large effect sizes; however, BT-APE imposes a far lighter computational footprint, consuming roughly 72% fewer input tokens and 66% less wall-clock time at equivalent accuracy, making it better suited to resource-constrained deployment. Our contributions are threefold: (i) a lightweight APE framework with an open interactive tool and replication package; (ii) the first systematic comparison of APE against classical prompting for requirements classification; and (iii) insights into how class definitions and prompt evolution affect performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes BT-APE, a lightweight backtracking automatic prompt engineering method for requirements classification. It models prompt design as an iterative optimization using LLM-generated candidates, backtracking search, and dynamic example selection. On three benchmark datasets and five instruction-tuned LLMs, BT-APE matches the accuracy of the resource-intensive PE2 baseline while using ~72% fewer input tokens and ~66% less wall-clock time, and substantially outperforms classical baselines (zero-shot, few-shot, CoT, CoT+few-shot) with large effect sizes. Contributions include an open tool and replication package, the first systematic APE vs. classical prompting comparison in RE, and insights on class definitions and prompt evolution.
Significance. If the efficiency claims hold under broader testing, the work offers a practical advance for requirements engineering by enabling effective prompt optimization in resource-constrained environments, where full APE methods like PE2 are impractical. The open replication package and tool are positive for reproducibility.
major comments (2)
- [§4 Evaluation and Table 3] §4 Evaluation and Table 3 (results): The reported accuracy parity with PE2 and large effect sizes over baselines are presented without statistical tests, variance across LLM stochastic runs, or controls for prompt variability, leaving the robustness of the central performance claims unverified.
- [§5 Discussion and §6 Conclusion] §5 Discussion and §6 Conclusion: The claim that BT-APE is 'better suited to resource-constrained deployment' rests entirely on results from three specific datasets and five LLMs; no cross-dataset or cross-LLM generalization experiments are reported, which is load-bearing for separating the efficiency advantage from potential overfitting to the evaluation scope.
minor comments (2)
- [§3 Method] The abstract and method description should clarify the exact backtracking termination criteria and dynamic example selection heuristic with pseudocode or equations for reproducibility.
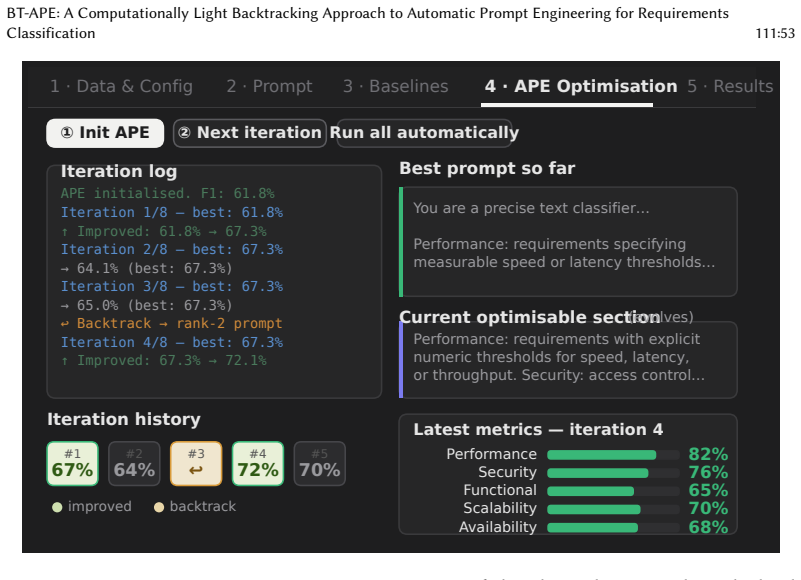
- [Figure 2] Figure 2 (prompt evolution example) would benefit from explicit annotation of backtracking steps and token counts to directly illustrate the claimed efficiency.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment below and note the planned revisions.
read point-by-point responses
-
Referee: [§4 Evaluation and Table 3] The reported accuracy parity with PE2 and large effect sizes over baselines are presented without statistical tests, variance across LLM stochastic runs, or controls for prompt variability, leaving the robustness of the central performance claims unverified.
Authors: We agree that the absence of statistical tests and variance reporting weakens the robustness claims. In the revised manuscript we will rerun all experiments with five random seeds per configuration, report means and standard deviations, and apply paired statistical tests (t-tests or Wilcoxon signed-rank) to the accuracy differences. These additions will be incorporated into §4 and Table 3. revision: yes
-
Referee: [§5 Discussion and §6 Conclusion] The claim that BT-APE is 'better suited to resource-constrained deployment' rests entirely on results from three specific datasets and five LLMs; no cross-dataset or cross-LLM generalization experiments are reported, which is load-bearing for separating the efficiency advantage from potential overfitting to the evaluation scope.
Authors: The current evaluation already spans three datasets and five LLMs with consistent efficiency gains. We acknowledge that additional cross-validation experiments would provide stronger separation from overfitting. In revision we will qualify the deployment claim in §5 and §6, explicitly state the evaluation scope as a limitation, and temper language to avoid implying broad generalization beyond the tested setting. revision: partial
Circularity Check
No circularity: independent search procedure evaluated on external benchmarks
full rationale
The paper presents BT-APE as a backtracking search algorithm with dynamic example selection for prompt optimization, evaluated directly against classical baselines and PE2 on three fixed benchmark datasets and five LLMs. No equations, fitted parameters, or self-referential derivations appear; performance claims rest on empirical comparisons rather than any reduction of outputs to inputs by construction. No self-citations are load-bearing for the central method or results. This is a standard empirical methods paper with no detectable circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2018. ISO/IEC/IEEE International Standard - Systems and software engineering – Life cycle processes – Requirements engineering.ISO/IEC/IEEE 29148:2018(E)(2018), 1–104. doi:10.1109/IEEESTD.2018.8559686
-
[2]
Waleed Abdeen, Michael Unterkalmsteiner, Krzysztof Wnuk, Alessio Ferrari, and Panagiota Chatzipetrou. 2025. Language models to support multi-label classification of industrial data. In2025 IEEE International Conference on Software Analysis, Evolution and Reengineering (SANER). IEEE, 45–55
2025
-
[3]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. 2023. Gpt-4 technical report.arXiv preprint arXiv:2303.08774 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Waad Alhoshan, Alessio Ferrari, and Liping Zhao. 2023. Zero-shot learning for requirements classification: An exploratory study.Information and Software Technology159 (2023), 107202
2023
-
[5]
Tawfeeq Alsanoosy. 2025. Large Language Model for Requirements Classification: An Ensemble Approach.Procedia Computer Science270 (2025), 3648–3657. doi:10.1016/j.procs.2025.09.490 29th International Conference on Knowledge- Based and Intelligent Information & Engineering Systems (KES 2025)
-
[6]
2024.Advancing Requirements Engineering Through Generative AI: Assessing the Role of LLMs
Chetan Arora and et al. 2024.Advancing Requirements Engineering Through Generative AI: Assessing the Role of LLMs. Springer Nature Switzerland, 129–148
2024
-
[7]
Sarmad Bashir, Muhammad Abbas, Alessio Ferrari, Mehrdad Saadatmand, and Pernilla Lindberg. 2023. Requirements classification for smart allocation: A case study in the railway industry. In2023 IEEE 31st International Requirements Engineering Conference (RE). IEEE, 201–211
2023
-
[8]
Manal Binkhonain and Reem Alfayez. 2025. Are prompts all you need? Evaluating prompt-based Large Language Models (LLM)s for software requirements classification.Requir. Eng.30, 4 (Sept. 2025), 423–443. doi:10.1007/s00766-025-00451-8
-
[9]
Fairley (Eds.)
Pierre Bourque and Richard E. Fairley (Eds.). 2024.Guide to the Software Engineering Body of Knowledge (SWEBOK) (version 4.0 ed.). IEEE Computer Society. https://www.computer.org/education/bodies-of-knowledge/software- engineering/v4 Available online: https://www.computer.org/education/bodies-of-knowledge/software-engineering/v4
2024
- [10]
-
[11]
Flavio Chierichetti and Ravi Kumar. 2015. LSH-Preserving Functions and Their Applications.J. ACM62, 5, Article 33 (Nov. 2015), 25 pages. doi:10.1145/2816813
-
[12]
Jane Cleland-Huang, Sepideh Mazrouee, Huang Liguo, and Dan Port. 2007. NFR Dataset. doi:10.5281/zenodo.268542
-
[13]
Jane Cleland-Huang, Raffaella Settimi, Xuchang Zou, and Peter Solc. 2007. Automated classification of non-functional requirements.Requirements engineering12, 2 (2007), 103–120
2007
-
[14]
Fabiano Dalpiaz, Davide Dell’Anna, Fatma Basak Aydemir, and Sercan Çevikol. 2019. Requirements classification with interpretable machine learning and dependency parsing. InRE’19. IEEE, 142–152
2019
-
[15]
V. De Martino, M. A. Zadenoori, X. Franch, and A. Ferrari. 2025. Green Prompt Engineering: Investigating the Energy Impact of Prompt Design in Software Engineering.arXiv preprint arXiv:2509.22320(2025)
-
[16]
Ernst and John Mylopoulos
Neil A. Ernst and John Mylopoulos. 2010. On the Perception of Software Quality Requirements during the Project Lifecycle. InRequirements Engineering: Foundation for Software Quality, Roel Wieringa and Anne Persson (Eds.). Springer Berlin Heidelberg, Berlin, Heidelberg, 143–157
2010
-
[17]
Alessio Ferrari, Sallam Abualhaija, and Chetan Arora. 2024. Model Generation with LLMs: From Requirements to UML Sequence Diagrams. InREW’24. IEEE, 291–300
2024
-
[18]
Alessio Ferrari, Felice Dell’Orletta, Andrea Esuli, Vincenzo Gervasi, Stefania Gnesi, et al . 2017. Natural language requirements processing: a 4D vision.IEEE Software34, 6 (2017), 28–35. J. ACM, Vol. 00, No. 0, Article 111. Publication date: January 2026. BT-APE: A Computationally Light Backtracking Approach to Automatic Prompt Engineering for Requiremen...
2017
-
[19]
Martin Glinz. 2007. On Non-Functional Requirements. In15th IEEE International Requirements Engineering Conference (RE 2007). 21–26. doi:10.1109/RE.2007.45
-
[20]
Charles Haley, Robin Laney, Jonathan Moffett, and Bashar Nuseibeh. 2008. Security Requirements Engineering: A Framework for Representation and Analysis.IEEE Trans. Softw. Eng.34, 1 (Jan. 2008), 133–153. doi:10.1109/TSE.2007. 70754
-
[21]
Tobias Hey, Jan Keim, Anne Koziolek, and Walter F Tichy. 2020. NoRBERT: Transfer learning for requirements classification. InRE’20. IEEE, 169–179
2020
-
[22]
Xinyi Hou, Yanjie Zhao, Yue Liu, Zhou Yang, Kailong Wang, Li Li, Xiapu Luo, David Lo, John Grundy, and Haoyu Wang. 2024. Large language models for software engineering: A systematic literature review.ACM Transactions on Software Engineering and Methodology33, 8 (2024), 1–79
2024
- [23]
- [24]
-
[25]
Barbara Kitchenham, Lech Madeyski, and David Budgen. 2022. SEGRESS: Software Engineering Guidelines for Reporting Secondary Studies.IEEE Transactions on Software Engineering49, 3 (2022)
2022
-
[26]
Eric Knauss, Siv Houmb, Kurt Schneider, Shareeful Islam, and Jan Jürjens. 2011. Supporting requirements engineers in recognising security issues. InRequirements Engineering: Foundation for Software Quality: 17th International Working Conference, (REFSQ 2011)(28-30). Springer, Essen, Germany, 4–18
2011
-
[27]
Eric Knauss, Siv Hilde Houmb, Shareeful Islam, Jan Jürjens, and Kurt Schneider. 2021. SecReq. doi:10.5281/zenodo. 4530183
-
[28]
Armin Kobilica, Mohammed Ayub, and Jameleddine Hassine. 2020. Automated identification of security requirements: A machine learning approach. InProceedings of the 24th International Conference on Evaluation and Assessment in Software Engineering. 475–480
2020
-
[29]
Zijad Kurtanović and Walid Maalej. 2017. Automatically classifying functional and non-functional requirements using supervised machine learning. In2017 IEEE 25th International Requirements Engineering Conference (RE). IEEE, Lisbon, Portugal, 490–495
2017
- [30]
-
[31]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. 2020. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks.Advances in Neural Information Processing Systems33 (2020)
2020
-
[32]
Manjeshwar Aniruddh Mallya, Alessio Ferrari, Mohammad Amin Zadenoori, and Jacek Dabrowski. 2026. From Online User Feedback to Requirements: Evaluating Large Language Models for Classification and Specification Tasks. In Requirements Engineering: Foundation for Software Quality - 32nd International Working Conference, REFSQ 2026, Poznań, Poland, March 23-2...
- [33]
-
[34]
Alessio Miaschi, Felice Dell’Orletta, and Giulia Venturi. 2024. Evaluating Large Language Models via Linguistic Profiling. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen (Eds.). Association for Computational Linguistics, Miami, Florida, USA, 2835–2848. doi:10.1865...
-
[35]
Thomas Olsson, Séverine Sentilles, and Efi Papatheocharous. 2022. A systematic literature review of empirical research on quality requirements.Requirements Engineering27, 2 (June 2022), 249–271. doi:10.1007/s00766-022-00373-9
-
[36]
Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, and Ryan Lowe. 2022. Training language models to follow instructions with human fee...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[37]
Jordan Peer, Yaniv Mordecai, and Yoram Reich. 2024. NLP4ReF: Requirements classification and forecasting: From model-based design to large language models. In2024 IEEE Aerospace Conference. IEEE, 1–16
2024
-
[38]
Kai Petersen, Sairam Vakkalanka, and Ludwik Kuzniarz. 2015. Guidelines for Conducting Systematic Mapping Studies in Software Engineering: An Update.Information and Software Technology64 (2015)
2015
-
[39]
Reid Pryzant, Dan Iter, Jerry Li, Yin Tat Lee, Chenguang Zhu, and Michael Zeng. 2023. Automatic Prompt Optimization with "Gradient Descent" and Beam Search. arXiv:2305.03495 [cs.CL] https://arxiv.org/abs/2305.03495
-
[40]
Yuman Qin and Rong Peng. 2025. ChatNRC: A Non-functional Requirement Classification Framework Based on a Generative and Discriminative Mechanism. In2025 32nd Asia-Pacific Software Engineering Conference (APSEC). 467–478. J. ACM, Vol. 00, No. 0, Article 111. Publication date: January 2026. 111:42 Zadenoori et al. doi:10.1109/APSEC66846.2025.00052
-
[41]
Gokul Rejithkumar and Preethu Rose Anish. 2025. NICE: Non-Functional Requirements Identification, Classification, and Explanation Using Small Language Models. In2025 IEEE/ACM 47th International Conference on Software Engineering: Software Engineering in Practice (ICSE-SEIP). 284–295. doi:10.1109/ICSE-SEIP66354.2025.00031
-
[42]
Alberto D Rodriguez, Katherine R Dearstyne, and Jane Cleland-Huang. 2023. Prompts matter: Insights and strategies for prompt engineering in automated software traceability. InREW’23. IEEE, 455–464
2023
-
[43]
Breaux, Thomas B
Sarah Santos, Travis D. Breaux, Thomas B. Norton, Sara Haghighi, and Sepideh Ghanavati. 2024. Requirements Satisfiability with In-Context Learning. InRE’24. IEEE, 168–179
2024
-
[44]
Md Shafikuzzaman, Md Rakibul Islam, Shuaib Zaman, Andrew Ma, and Anwarul Islam Sifat. 2025. On the Effectiveness of Zero-Shot and Few-Shot Pretrained Language Models for Software Requirement Classification.IEEE Access13 (2025), 159439–159453. doi:10.1109/ACCESS.2025.3607813
-
[45]
Guttorm Sindre and Andreas Opdahl. 2003. A Reuse-Based Approach to Determining Security Requirements. (05 2003)
2003
-
[46]
Hamed Taherkhani, Melika Sepidband, Hung Viet Pham, Song Wang, and Hadi Hemmati. 2026. Automated Prompt Engineering for Cost-Effective Code Generation Using Evolutionary Algorithms.ACM Trans. Softw. Eng. Methodol. (March 2026). doi:10.1145/3805704 Just Accepted
-
[47]
Maciej Tomczak and Ewa Tomczak-Łukaszewska. 2014. The need to report effect size estimates revisited. An overview of some recommended measures of effect size. 21 (01 2014), 19–25
2014
-
[48]
Jonathan Ullrich, Matthias Koch, and Andreas Vogelsang. 2025. From Requirements to Code: Understanding Developer Practices in LLM-Assisted Software Engineering. In2025 IEEE 33rd International Requirements Engineering Conference (RE). 257–266
2025
-
[49]
Vasily Varenov and Aydar Gabdrahmanov. 2021. Security requirements classification into groups using nlp transformers. In2021 IEEE 29th International Requirements Engineering Conference Workshops (REW). IEEE, Notre Dame, IN, USA, 444–450
2021
- [50]
- [51]
-
[52]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc V. Le, and Denny Zhou. 2022. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models.arXiv preprint arXiv:2201.11903 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
- [53]
-
[54]
Amin Zadenoori. 2026.aminzadenoori/Backtracking-enhanced-Automatic- Prompt-Engineering-APE-for-requirements- classification.: APE Classification Tool— Backtracking-enhanced Automatic Prompt Engineering for Requirements Classifi- cation. doi:10.5281/zenodo.20438927
-
[55]
{Mohammad Amin} Zadenoori, Liping Zhao, Waad Alhoshan, and Alessio Ferrari. 2025. Automatic Prompt Engineering: The Case of Requirements Classification. InRequirements Engineering: Foundation for Software Quality (REFSQ) (Lecture Notes in Computer Science, Vol. 15588). Springer Nature, United States, 217–225
2025
- [56]
- [57]
-
[58]
Liping Zhao, Waad Alhoshan, Alessio Ferrari, Keletso J Letsholo, Muideen A Ajagbe, Erol-Valeriu Chioasca, and Riza T Batista-Navarro. 2021. Natural language processing for requirements engineering: A systematic mapping study.ACM Computing Surveys (CSUR)54, 3 (2021), 1–41
2021
-
[59]
Xin Zhou, Martin Weyssow, Ratnadira Widyasari, Ting Zhang, Junda He, Yunbo Lyu, Jianming Chang, Beiqi Zhang, Dan Huang, and David Lo. 2025. Lessleak-bench: A first investigation of data leakage in llms across 83 software engineering benchmarks.arXiv preprint arXiv:2502.06215(2025)
-
[60]
Large Language Models Are Human-Level Prompt Engineers
Yongchao Zhou, Andrei Ioan Muresanu, Ziwen Han, Keiran Paster, Silviu Pitis, Harris Chan, and Jimmy Ba. 2023. Large Language Models Are Human-Level Prompt Engineers. arXiv:2211.01910 [cs.LG] https://arxiv.org/abs/2211.01910 J. ACM, Vol. 00, No. 0, Article 111. Publication date: January 2026. BT-APE: A Computationally Light Backtracking Approach to Automat...
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.